网络安全应急响应新常态
2015-12-03
应急因为有“急”
近年以来,高等级的安全应急响应活动越来越频繁,例如2014年发生的心脏滴血、破壳、沙虫、Poodle等几次重要应急响应事件。一方面因为对快速响应市场需求的追求,开源和商业组件获得更大规模的应用,导致任何一个底层组件出现重大安全漏洞都会影响数千万甚至数亿设备和用户;另一方面国家网际空间安全能力的争夺导致漏洞挖掘和利用能力的研究不断深入,更新的挖掘和利用方法被发掘出来。相信这个趋势在可预测的时间内还将继续发展。
当一个严重漏洞,尤其是某种新的利用工具(POC)被披露后,通过各种社交网络和网络媒体,在小时级的时间尺度上将会获得迅速传播,响应的攻击行为迅速增加。在心脏滴血漏洞利用披露后IBM监视到的网络攻击行为中可以看到4月10日开始有大规模攻击,然后高位持续了10天左右时间。换句话说,72小时更像是安全应急响应的“黄金时间窗口”,在这个时间内成功完成响应活动,将会有更大的概率避免被“攻陷”。
但是,令人遗憾的是,当前从整个网络角度看,安全应急响应的时效性(也直接影响了有效性)很不理想。这给了我们启发和思考,大规模的安全应急响应活动是一个系统工程,对于国家整体、或某个地区、某个行业而言,其成功与否,或整体的安全性,并不只取决于少数安全专家“高精尖”的技术研究活动;及时有效地大规模实施一系列“响应”活动、从而获得(或者恢复保持)整体安全性的战略动员和自动化部署能力,可能更为关键。
有效应急响应的成功要素
图1是笔者尝试对大规模应急响应活动建立的一个工程模型,用以识别其中的关键成功要素,从而能够对国家、地区、行业、大型企业组织等层面的应急响应活动提供一些参考。
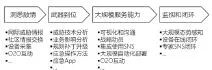
图1 有效应急响应的成功要素
1.洞悉敌情
从近年的安全实践来看,威胁情报(TI)或网际威胁情报(CTI)的重要性无论怎么强调都不过分。洞悉敌情,也即在第一时间了解自身信息资产所面临的新漏洞(老漏洞新攻击方法)、新攻击工具和方法、威胁环境变化等,这是安全活动和决策的重要依据。
在“敌情”发现后,安全专家就其原理、影响进行分析发现,研究其检测和防御方法,判定是否需要启动紧急“响应”,推荐适当的“防御”活动。因为所有的“防御”活动都意味着成本,“时效性”要求本身也意味着额外的成本。“不惜一切代价”、“消除所有漏洞和威胁”、“确保万无一失”是口号,而不是真正的战斗。
2.武器到位
掌握威胁情报并及时研究出有效的防御方法只是“长征”的第一步。将相应的“防御”方法及时有效地部署并使之产生最终的“防御”效果是个更大的挑战。这个过程就是“武器化”的过程。这里的武器包括用以沟通动员的各种分析报告、通告、微博、微信、短信等,用以升级安全系统的各种补丁、插件、规则、快速App等,用以指导系统管理员进行手工操作的快速判断方法、检测方法、修复和规避方法等。
3.大规模服务能力
在小时时间尺度内,对成千上万的设备系统等进行安全升级和修复,并不是一件容易的事情。应急响应可能需要业务中断、额外的资源投入(例如加班)、以及相关联的其它业务延迟等。因此,大规模的安全应急响应首先应该取得管理层、业务等部门的理解和支持,需要将“急”和“后果”讲清楚,需要有良好的可视化和沟通能力。
战略动员能力是指整个组织范围内调动各种资源(人、物、财、信息等)、在非常有限的时间内达成应急响应目标的能力。安全团队需要通过沟通提高管理层对网络安全应急响应活动的重视、以及网安团队自身在组织内的影响力、部署能力等。
形成决策后,有必要系统地使用社交网络技术以提高沟通效率、组织动员“应急响应”团队、发布指令、同步各种响应活动的信息等。
通过不同形式的“软件定义”架构,逐步建设大规模的自动化部署能力,例如规模化地升级系统配置、对系统服务进行重新编排。
此外,线上线下(O2O)安全专家的互动在安全应急响应活动中也非常重要。“线上”或“云中”掌握最新的威胁情报和全局动态,“线下”拥有第一手的数据和实际操作能力,例如实际业务影响判断、现场取证分析等。将线上线下能力“集成”起来、相互补充才是最有力的战斗。
4.监视和闭环
监视和闭环是指监视“急”和“应急”活动的最新进展,并对“应急”活动的效果进行评价,以便针对性地做出相应调整。监视和闭环需要大范围的数据获取能力和处理分析能力。
应急响应的能力建设
从上面的要素中可以看到,能够成功的实施应急响应,都关乎到应急响应的能力建设。2014年,工业和信息化部发布了《关于加强电信和互联网行业网络安全工作的指导意见》,意见明确指出,需要提升突发网络安全事件应急响应能力,制定和完善各单位网络安全应急预案,健全大规模拒绝服务攻击、重要域名系统故障、大规模用户信息泄露等突发网络安全事件的应急协同配合机制。
其中无论是洞悉敌情、武器到位,还是大规模服务能力及监视闭环,都需要一个多方参与的生态链才能共同打造完成,这里面需要用户单位、主管单位、行业机构、安全服务商、产品供应商等多种角色进行协作。绿盟科技作为安全服务商及产品供应商,长年关注威胁情报获取,并着力完善应急响应体系建设及能力提升。
绿盟科技威胁情报服务体系包含了威胁监测及响应、数据分析及整理、业务情报及交付、风险评估及咨询、安全托管及应用等各个方面,涉及研究、产品、服务、运营及营销的各个环节,覆盖了有效应急响应的各个要素,这些要素让绿盟科技得以不断提升应急响应的能力。其中,
全球客服中心(Service):结合在全球设立的多个分支机构,覆盖美国、日本、英国、荷兰、新加坡、澳大利亚、马来西亚、韩国、阿联酋、中国等多个国家,能够在客户面临紧急安全事件的时候,及时响应客户的请求;
威胁响应中心(Response):实时监控互联网安全威胁,并形成闭环跟踪,用户可以在第一时间通过各服务通道获知并接收到这些威胁情报;
云安全运营中心(Operation)及云端客户自助系统(portal):让用户在安全事件发生时,尽快在线进行安全威胁检查,从而获得及时的安全威胁应对方法;
互联网广谱平台(Broad Spectrum): 收集、分析及可视化呈现各类互联网安全威胁数据,通过这些可视化的数据,可以更为直观的描述当前事件发展态势;
产品在线升级系统(update): 用户可以紧急事件发生后的1天内获得产品升级包;
攻防研究团队(Research):与各行业各领域的组织充分协作,深入分析各类安全事件,并长年跟踪研究威胁发展态势,用户及社会各界可以通过研究报告,为提升自身的应急响应能力获取理论及数据支撑。
无独有偶,在今年RSA 2015的三大主题中也提到了威胁情报(Threat Intelligence),正是基于这个“知道”的前提,才能实现有效的应急响应,才有可能让安全实现智能(Security Intelligence),进而有能力应对高级威胁(如APT),未知攻焉知防?这里也充分体现了一个快速响应能力的建设问题。另一方面,在与历届RSA与会者的交流中可以感受到,越来越多的用户从关注已知威胁过渡到针对未知威胁的预警及防御,而这一能力也需要基于威胁情报的不断积累,并结合大数据分析、多组织协作等方式方法,进而将之变得稳定可用,才有可能从已知向未知的跨越。
所以,在如今安全事件日益趋向0day,日益趋向高级的大环境下,应急这个“急”显得尤为重要,那么确定应急响应中的成功要素,不断建设及提升应急响应的能力,应该成为各单位及组织安全工作的新常态。每一次的“应急响应”活动都是对安全组织的一次考试。获取敌情、武器到位、大规模“服务”、监视和闭环等要素活动,也将不断对安全组织的应急能力提出挑战。
新常态
如前所述,成功的安全应急响应要求多种不同职责、技能的团队依托多种系统和情报密切协同,“云地人机”代表着四大类基本资源要素,类似于安全应急响应的“风林火山”。
“云”代表着线上、集中远程提供服务、弹性密集计算、大数据能力等;“地”意味着分布、线下或线上的远端;“人”代表着专家、专业领域知识等;“机”意味着系统、设备、代码、自动化等。“云”中有“人”、有“机”,“地”同样也有“人”、有“机”。“云地”配合意味着线上线下、集中与分布的协同;“人机”配合意味着“机”需要面向安全决策、安全专家DrillDown、取证、根源分析来设计建设、安全专家需要有能力掌握有效使用各种安全系统等。“云”专家和“地”专家需要闭环,“云”设备和“地”设备也需要闭环,机—机结构化信息交换、人机信息交换和可视化、人—人之间的信息同步等是“闭环”的重要基础机制。这两年来,以STIX为代表的机器可读威胁情报交换技术在美国获得了迅速发展,表征着美国政府和工业界在大规模安全应急响应能力方面的快速提升。
笔者希望本文提出的四阶段应急活动、四类应急协同资源等可以为不断出现的大规模安全应急响应活动提供一个简单的参考模型,得到同行专家和各位读者的讨论和批评指正。
