基于Hadoop的电力大数据技术体系研究
2015-12-02张晓佳高一丹
岳 阳,张晓佳,高一丹
(国网苏州供电公司,江苏 苏州 215004)
目前,国外已有先行者尝试将大数据技术应用到电力行业。美国加州大学研究者利用用户用电信息和地理位置等数据制作电力地图,展示每个街区实时用电量。德国的电力公司利用大数据预测客户的用电习惯和电力需求,以此制定成本最低的购电计划[1]。
随着智能电网的大规模建设,智能电表、智能插座等终端部署,智能变电站、电动汽车充换电站等项目投运以及风能、光伏等间歇性能源的接入,电力行业的信息时代正处于关键转折点,电网产生的数据将更多、更复杂。数据规模每年将以指数级增长,且数据中包含大量的半结构化和非结构化信息。与此同时,智能电网要求做到对电网故障的快速响应、短期负荷的准确预测以及数据处理的实时性,这些关键问题很难再用传统技术解决[2]。一方面,数据规模的庞大导致原有系统难以存储和管理;另一方面,大数据的复杂关联性导致传统算法失效。
为此,加快推进大数据技术在电力领域的应用十分必要。本文结合大数据最新技术与实际应用需求,对电力行业所需的大数据技术体系进行了系统性研究,给出了电力大数据技术架构,并对大数据存储和大数据处理等核心技术进行了详细分析。
1 电力大数据
1.1 电力大数据的定义及特点
根据麦肯锡的描述,大数据是指无法在一定时间内用传统数据库软件工具对其内容进行抓取、管理和处理的数据集合[3]。大数据的显著特征是数据规模大(Volume)、数据类型多(Variety)、处理速度快(Velocity)、价值密度低(Value)[2],简称4V。
电力大数据一般是指通过传感器、智能设备、视频监控设备、音频通信设备、移动终端等各种信息获取渠道收集到的,海量的,结构化、半结构化、非结构化的,且相互间存在关联关系的业务数据集合[4,5]。
电力大数据亦具有4V特征。
(1)数据规模大
电网的数据采集覆盖发、输、变、配、售每个环节,仅就售电侧的用采数据而言,一个省网按3000万用户,每天采集一次,一年的用电数据就有100余亿条,若实现15分钟采集间隔,数据量将再增加96倍。
(2)数据类型多
电力数据从结构分,包括常规结构化数据和系统日志、表计等半结构化数据,以及文件、图片、视频等非结构化数据。从内容分,包括测量数据、监控数据、设备台账、日志文件、地理信息、气象数据等。
(3)处理速度快
电力系统对数据的采集、处理及分析有严格的时间限制,许多业务如电量实时查询、电网故障快速响应等多是以秒为目标的准实时处理[4]。
(4)价值密度低
电网中的数据每时每刻都在产生,但真正有用的数据不多。如设备状态监测数据,绝大部分都是正常数据,异常数据占比极少,而后者才是设备状态分析的关键[2]。
2.2 电力大数据的来源
电力数据产生于发、输、变、配、售多个环节,根据业务内容可划分为三类:电网运行、公司运营和营销服务。
电网运行类数据主要为电网运行和设备状态监测数据:
(1)电网运行数据来自D5000调度平台中的能量管理系统(Energy Management System,简称EMS)、调度管理系统(Operational Management System,简称OMS)和数据采集与监控系统(Supervisory Control And Data Acquisition,简称SCADA)。主要包括线路电压、电流、功率、继保装置信息、保护故障录波数据、开关状态、报警信息、新能源分布、无功补偿等数据。随着矢量测量装置的部署,还将获得大量更精确的相角数据。
(2)设备状态监测数据来源有SCADA系统和生产管理系统(Production Management Sys-tem,简称PMS),主要包括设备台账、工作票、家族缺陷、不良工况、检修试验、带电检测、在线监测等数据。目前这些数据的价值尚未被挖掘,需要深度分析以实现设备状态综合评价。
营销服务类数据主要来自营销业务系统、用电信息采集系统、计量运营管理平台、EMS、95598平台等。包括营销设备管理、用户档案及用电信息、配变电能计量、用电关口电量、网供负荷、发电量和95598业务等数据。这些数据可深入挖掘,用于负荷预测、用电量预测、负荷特性分析及经济形势分析等方面。
公司运营类数据来源有运监、计划统计、ERP等系统,包括业务指标、电网规划、建设管理、财务数据、物资需求等数据。深入挖掘分析这些数据,可以提升电网公司管理水平,降低运营成本。
其他还有气象信息监测系统、雷电监测系统、地理信息系统(GIS)等系统提供的气象环境、地理信息等数据。这些数据与电网运行和设备状态监测数据密切相关,需要进行深入关联分析。
2 Hadoop生态系统
(1)Hadoop
Hadoop的核心是Google在2003至2004年发 表 的 MapReduce[6]、Google File System(GFS)[7]和 BigTable[8]三篇论文,其中 MapReduce是分布式计算框架,GFS是分布式文件系统,BigTable是基于GFS的数据存储系统,这三大组件构成了全新的分布式计算模型。随后Yahoo对其进行了开源实现,即 Hadoop[9],并根据GFS开发了HDFS,根据BigTable开发了HBase。同时其他众多开源项目如Hive、Pig等围绕Hadoop构成了完整的生态系统[10],如图1所示。

图1 Hadoop生态系统
Hadoop具有高可扩展性和高容错性等优点,基于分布式思想,利用HDFS和MapREduce实现海量异构数据的低成本高效处理。
(2)HDFS
HDFS(Hadoop Distributed File System)是一个分布式文件系统,采用主从结构(如图2)。每个Hadoop集群包含一个名字节点(Namenode)和大量数字节点(Datanode),名字节点存放文件的名称、目录结构等元数据,而数量众多的数据节点则存放具体的文件内容[10]。存储在HDFS中的每个文件将被划分成一个或多个数据块(block),每个数据块有多个副本,每个副本分散存储在不同的数据节点上,数据块有多个冗余,以解决硬件故障导致的数据丢失问题[11]。

图2 HDFS架构
HDFS可采用X86服务器作计算节点,易于扩展,为低成本存储海量非结构化数据及分布式计算提供了可能。
(3)MapReduce
MapReduce是一个分布式计算软件框架,用于大规模数据集的并行计算。通过高并发的处理方式,同时管理多个大规模计算过程,实现数据处理能力从TB级到PB级的突破。
简单的MapReduce主要由三部分构成:Map函数、主控制器和Reduce函数。MapReduce对大规模数据采用并行处理策略,将大量重复的数据记录处理过程总结成Map和Reduce两个抽象操作,并为其提供一个统一的并行计算框架,把并行计算所涉及到的诸多系统层细节交给计算框架去完成[10-12]。其执行过程如图3所示。
过去大规模并行化计算都使用昂贵的专业并行计算机。随着分布式文件系统和并行计算的应用,这些计算可由数以千计的普通计算机集群完成,成本大大降低[12]。
3 大数据关键技术
3.1 大数据技术体系
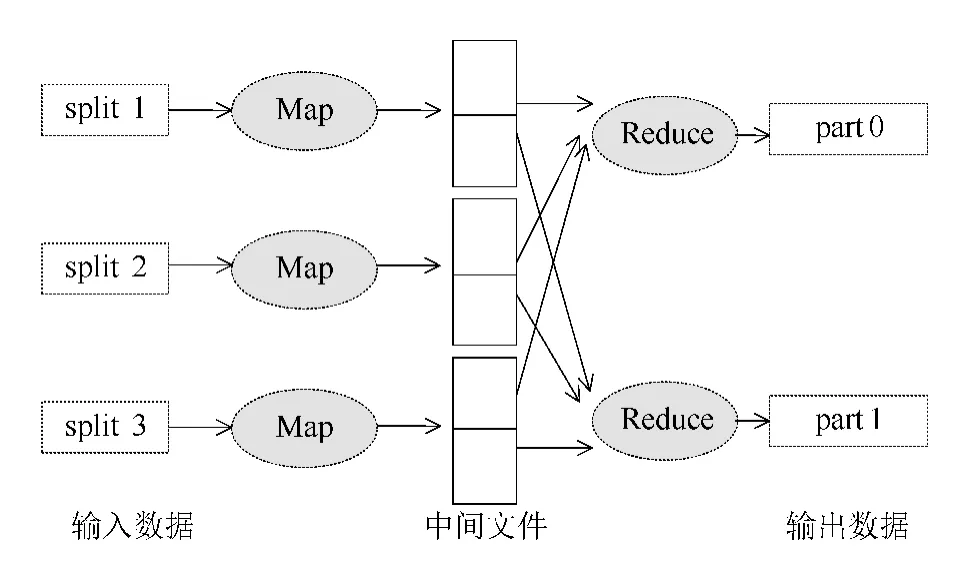
图3 MapReduce执行过程示意图
大数据不是某一种技术,而是多种技术的融合。完整的技术体系应包括数据整合、数据存储、数据处理、数据应用和安全管理等关键技术。以Hadoop为核心的开源产品是目前主流的大数据开源解决方案。基于Hadoop的电力大数据平台结构框架如图4所示。
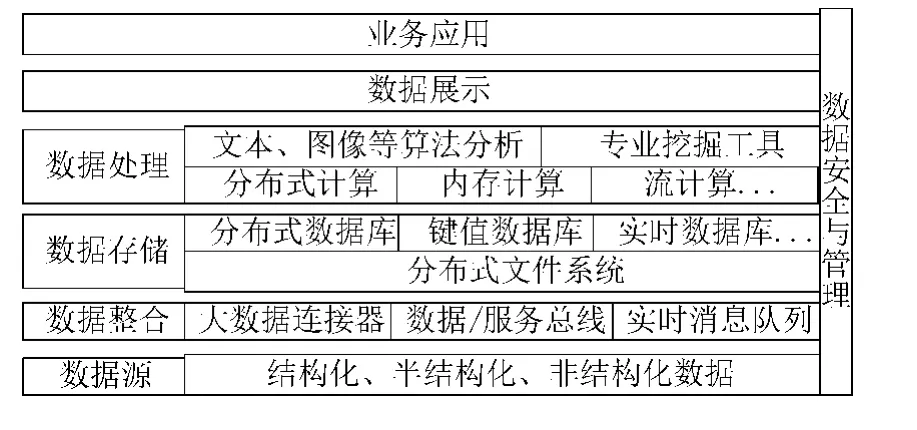
图4 大数据平台架构
Hadoop提供分布式文件系统和并行计算,解决大规模数据存储和处理问题;在其基础上搭建上层应用实现SQL、实时计算、流式计算、内存计算、数据挖掘、数据可视化等功能[10-13]。
3.2 大数据整合技术
大数据整合技术需要融合传统ETL技术和数据连接器、实时消息队列、平台服务接口等新技术,从数据中心、业务平台、终端等多种外部数据源导入海量多样化数据并按照统一的数据规范进行标准化处理后,放入大数据存储系统中。
(1)大数据连接器
大数据连接器为一种关系型数据集采集技术,用于关系数据库等传统数据源与分布式存储系统之间传输数据,实现不同存储机制下数据的相互转换。相关产品有Sqoop、DataX等。
(2)数据/服务总线
数据/服务总线为一种文件采集与处理技术,可将大量来自非传统数据源、结构混乱、无法有效处理的非结构化文件采集存储到大数据平台。相关产品有Flume、Scribe等。
(3)实时消息队列
实时消息队列为一种实时数据采集技术。由于传感器等终端产生的数据规模大、变化快,需要实时采集并处理,为此需要分布式海量流数据采集技术,用于收集实时流数据,并对其简单预处理。相关产品有Kafka等。
3.3 大数据存储技术
大数据存储技术需要针对全类型数据存储和多样化计算需求,使用中低端存储设备,以分布式文件系统为基础,综合基于分布式文件系统的各类数据库,实现高效低成本的大数据存储及面向NOSQL的数据访问。
(1)分布式文件系统
文件数据存储在分散的低成本存储介质上,对外提供一致的文件访问接口,具有良好的容错性和安全性,用于PB级以上规模的半结构化、非结构化数据存储。主流产品有HDFS、FastDFS等。
(2)列式存储数据库
以数据列为单位进行存储,使得数据规模可被高效压缩,提供海量规模数据快速检索和查找功能。用于大批量数据处理和即时查询。主流产品有HBase等。
(3)分布式关系型数据库
以行为单位进行存储,由分散的多个节点组成的大型数据库,用于大规模结构化数据的存储和查询。主流产品有GreenPlun等。
(4)键值数据库
一种非关系型数据库模型,按照键值对的形式存储,有更好读写性能,用于高性能半结构化数据查询。主流产品有Redis等。
(5)实时数据库
专用于处理具有时间序列特性的数据库模型,用于实时或准实时高频采集数据的存储和查询。主流产品有RealTimeBase等。
(6)内存数据库
将结构化数据放在内存中直接操作,读写速度极快,用于高性能实时查询和分析。主流产品有TimesTen等。
3.4 大数据处理技术
大数据处理技术需要针对海量数据多样化处理的需求,以分布式计算为核心,融合其他先进计算模式,构成可适应多种计算场景的计算框架。
(1)分布式计算
分布式计算针对海量规模数据,采用 Map Reduce分布式计算框架,实现数据处理能力从TB级到PB级的突破,用于实时性要求不高的大批量计算。
(2)流计算
流计算是一种针对流数据的高实时性计算模式。对于系统产生的源源不断的海量音视频等流式数据,不长期存储,直接将其导入内存进行实时计算,从中提取有价值的信息。适用于动态流数据的实时计算。主流产品有Storm、Spark Streaming等。
(3)内存计算
内存计算指数据存储和计算全部存在于主内存中,利用CPU和内存的优势,结合并行计算技术,实现高性能计算。适用于需要实时响应的实时统计和交互式分析。主流产品有SAP HANA等。
3.5 大数据分析技术
大部分的电力数据直接使用价值不太。需要利用合适的挖掘算法去深入分析,才能从中提炼出高价值信息。
传统挖掘算法有:聚类分析、关联分析、演化分析、文本语音分析、图像和视频分析等。这些算法在用于分布式数据和分布式处理时有一定局限性。目前,基于开源技术的数据挖掘技术如R语言、Mahout等能够支撑大数据条件下的数据分析和挖掘,其综合各类分析算法、开发工具和可视化控件,通过分布式算法对分布式文件系统中的各类数据进行挖掘。
3.6 大数据可视化技术
大数据可视化技术将大规模、多维度、关系复杂的数据结果以直观的图形化等形式展现给用户,有助于用户快速理解并作出准确判断。
典型的大数据可视化技术有:网络图、旭日图、区域图、树状图、和弦图、平行坐标图、索引图、日历表、标签云、填料圈等。
3.7 大数据安全技术
电力大数据具有多源异构、分布广泛、动态增长、跨业务等特点,与传统数据管理迥然不同,导致其安全风险大大增加。基于大数据的这些特点,需要重点加强权限管理、隐私保护、存储安全、接入安全等安全技术以及相应的安全管理制度,实现大数据采集到应用的全过程安全监控。
4 典型应用场景
大数据技术在电力领域有广泛的用途,本文分析了几种具有高开发价值的典型应用场景。
(1)新能源发电预测和管理
通过对海量的气象数据进行模拟,结合风机及光伏发电出力曲线及历史发电信息,分析新能源出力与风速、光照、温度等气象因素的关联关系,实现对新能源发电能力的精确预测,优化新能源调度管理。
(2)检修策略优化
对在线监控数据实时分析,自动识别输变电设备故障缺陷,并与设备台帐、运行状态、检修记录等数据进行关联分析,找出故障成因。结合数据挖掘技术,建立设备状态综合评价模型,实现设备状态风险评估和故障预判,优化检修策略。
(3)中长期负荷预测
基于海量用采数据、GIS数据,结合外部的人口信息、地区规划、经济形势等数据,分析输变电设备的负载情况,预测中长期电力需求分布和变化趋势,指导公司的设备扩容更换、配电网升级改造以及电网线路规划。
(4)用采数据实时查询和用电行为分析
利用大数据高效存储和高速处理能力,实现用户用电数据高频率实时快速采集存储,提高用电量快速统计和实时查询能力。基于用户历史用电数据,分析社区或大客户用电行为特征,预测客户短期用电需求,实现个性化用电管理。
5 结语
随着技术发展,未来的电网将更加智能、安全、可靠,低成本、高效率、高可靠的大数据技术将为此提供坚实的技术支撑。为进一步提高电网安全运行能力,向客户提供优质供电服务,积极推进大数据技术在电力领域的应用势在必行。
[1] 维克托·迈尔·舍恩伯格,肯尼斯·库克耶.盛杨燕,周涛,译.大数据时代[M].杭州:浙江人民出版社,2013.
[2] 宋亚奇,周国亮,朱永利.智能电网大数据处理技术现状与挑战[J].电网技术,2013,37(4).
[3] McKinsey Global Institute.Big data:the next frontier for innovation,competition,and productivity[R].2011.
[4] 中国电机工程学会信息化专委会.中国电力大数据发展白皮书[M].2013.
[5] Mladen Kezunovic,Le Xie,Santiago Grijalva.The Role of Big Data in Improving Power System Operation and Protection[C]//2013IREP Symposium-Bulk Power System Dynamics and Control-IX(IREP),2013.
[6] Dean J,Ghemawat S.MapReduce:Simplified data processing on large clusters[C]//Proc of the 6thSymposium on Operating System Design and Implementation,2004:137-150.
[7] Ghemawat S,Gobioff H,Leung S T.The google file system[C]//Proc of the 19thACM Symposium on Operating System Principles,2003:29-43.
[8] Chang F,Dean J,Ghemawat S,et al.Bigtable:A distributed storage system for structured data[C]//Proc of the 6thSymposium on Operating System Design and Implementation,2006:205-218.
[9] Apache.Apache Hadoop core[EB/OL].2012-08[2013-02].http://hadoop.apache.org/core.
[10] 陈吉荣,乐嘉锦.基于Hadoop生态系统的大数据解决方
案综述[J].计算机工程与科学,2013,35(10).
CHEN Ji-rong,YUE Jia-jin.Reviewing the big data solution based on Hadoop ecosystem[J].Computer Engineering &Science,2013,35(10).
[11] 赵刚.大数据技术与应用实践指南[M].北京:电子工业出版社,2013.
[12] 拉贾拉曼,厄尔曼.王斌,译.大规模数据挖掘[M].北京:人民邮电出版社,2012.
[13] 坎塔尔季奇著.王晓海,吴志刚,译.数据挖掘:概念、模型、方法和算法[M].北京:清华大学出版社,2013.
