一种对抗社交网络链接作弊的算法
2015-11-26申华
申 华
(1.鞍山师范学院数学与信息科学学院,辽宁 鞍山 114005;2.大连理工大学软件学院,辽宁 大连 116620)
0 引言
社交网络在全世界范围内得到了迅猛的发展,但许多作弊用户(Social Spammer)却利用其开放性及传播性,发布了大量的垃圾信息,严重威胁用户的个人信息安全[1-3]。社交网络上的链接作弊[4](Link Spam)是指社交网络用户为了增加其影响力,与其他用户相互合作,故意构建链接关系的行为。该行为不仅增强了每个作弊用户传播垃圾信息的能力,而且最终构建生成的链接工厂将给社交网络带来极大的安全隐患。与针对搜索引擎的链接作弊不同,社交网络上的链接作弊成本更低,甚至一些正常用户也参与其中[5-6],这使该作弊行为更加复杂,从而使之难以检测。
近几年,有些研究者提出利用类似Anti-Trust Rank 算法思想来抵制社交网络上的链接作弊行为。Ghosh[4]等人分析了社交网络链接工厂的现象,发现有一些正常用户也参与构建链接工厂,于是提出一种基于非信任传播的算法对参与链接工厂的用户进行惩罚降级。Yang[7]等人提出从已知的作弊种子集出发,将语义协作强度加入到恶意分数传播的算法中,进而辅助检测社交网络中参与链接作弊的用户。Huang[8]等人利用类似PageRank 算法的思想,将社交活动的互动情况作为权重来影响信任分数传播的比重,并以此作为检测作弊者的特征。Shen[9]等人首先提出若干用户特征,然后利用图模型[10-11]计算用户关系强度,在进行非信任传播的过程时,再以用户关系强度影响非信任分数的分配。
以上的研究工作主要采用基于信任或非信任的单向传播算法,没有考虑用户既有可信任的一方面,也可能有不可信任的另一方面。如果将信任及非信任同时进行传播,对参与链接工厂的用户降级将更为准确,从而将更有利抵制这种链接作弊行为。从该想法出发,本文通过分析社交用户的行为提出一些新的特征,并利用前期提出的图模型计算用户之间的社交关系强度,同时提出一种基于信任与非信任双向传播的改进算法,既可以对作弊用户进行降级,也可以实现作弊用户的检测。
1 抵抗链接作弊的工作框架
图1 表示了本文提出的具有双向传播性能的社交网络链接反作弊的工作框架。
工作框架主要分为2 部分:
1)社交用户关系强度的计算。通过选择的特征以及统计的用户交互动作频率,采用概率图模型求解用户之间的关系强度。
2)利用信任与非信任双向传播算法STDR 计算用户的信任分数以及非信任分数,第1 部分求出的用户关系强度值作为影响每个用户分数传播的比重。
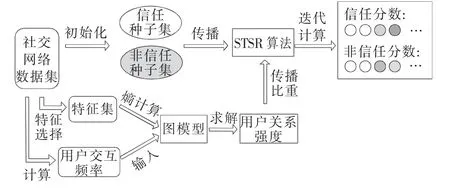
图1 抵抗社交网络链接作弊的工作框架
2 社交网络用户的关系强度
2.1 关系强度的基本思想
在社交网络上建立链接关系的成本很低,即任意用户都可以去关注其他用户,而一些正常用户出于社交礼节或者社交资本累积的原因也容易去响应作弊用户的关注。也就是说,即使建立了社交链接关系的用户也不能保证是同一类用户。
在前期研究[11]中发现,社交网络用户更愿意与自己兴趣爱好相近的其他用户建立链接关系,这与文献[12]提到的同质性是相符的。同时,用户之间的社交活动的互动频率越大,说明2 个用户属于同一类用户的可能性就越高。即用户间的关系强度可由用户间的相似度及交互频率共同决定。
从这个思想出发,本文首先利用前期提出的概率图模型计算用户之间的关系强度。
2.2 计算用户之间的特征熵
本文深入分析了社交网络上用户发布的内容、行为以及社交关系,并提出了4 类特征,如表1 所示。
利用信息熵[13]的理论,上述提出的特征采用熵函数H(xi,xj)计算用户的相似度,该熵函数定义为:
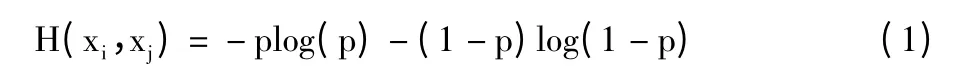
其中,xi,xj分别表示用户i,j 的相应特征,
通过公式(1),计算2 个用户i,j 的若干特征熵,可以得到相似度向量,其中F为24。
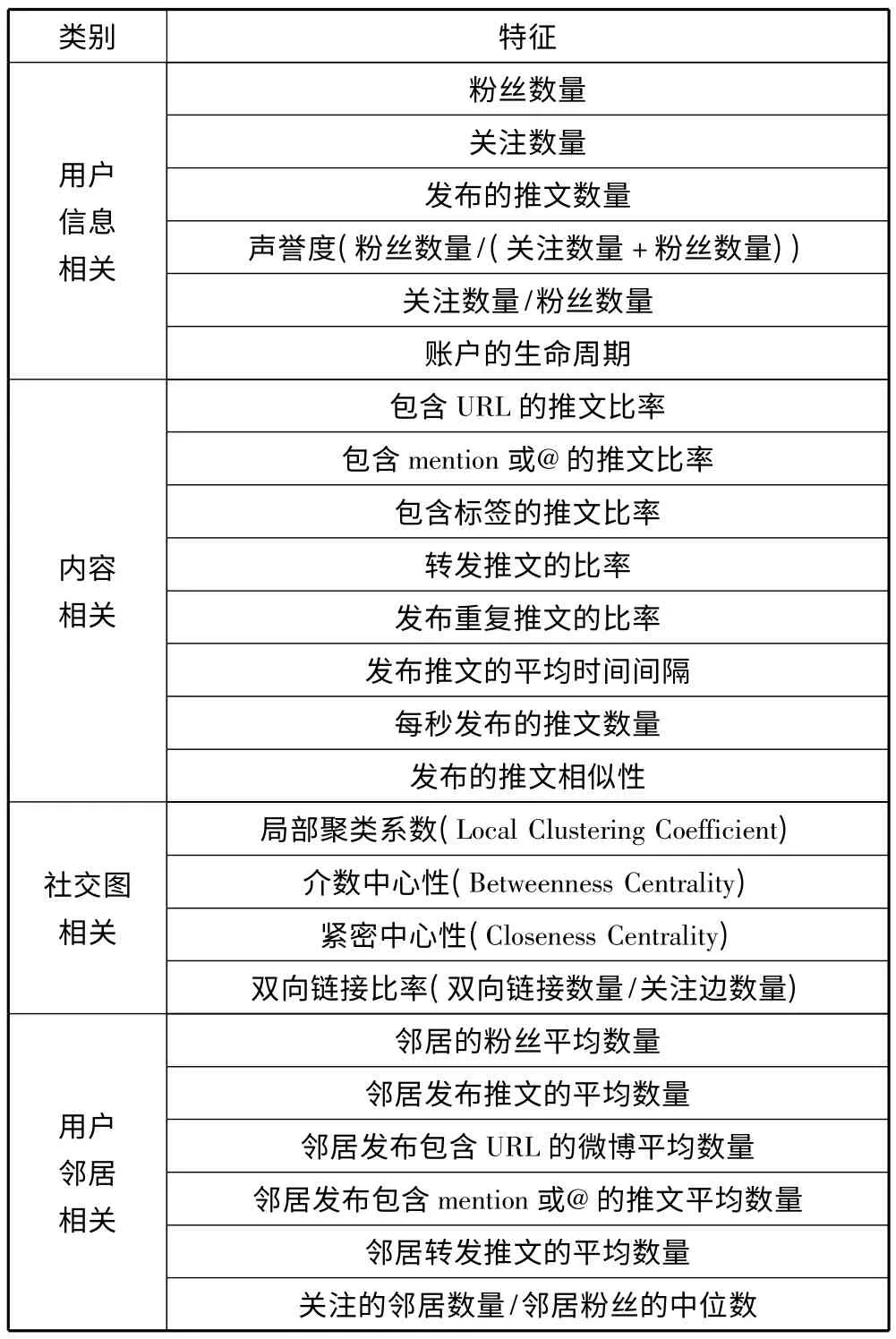
表1 社交网络用户特征
2.3 计算用户的关系强度
前期已提出一个计算关系强度的图模型[11],如图2 所示。
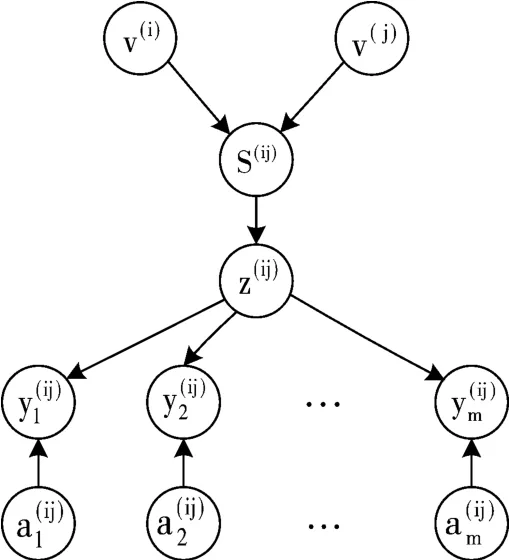
图2 关系强度的图模型
该模型中的S(ij)为2.2 节中求得的用户v(i),v(j)的相似度向量,表示用户v(i),v(j)之间m 个不同的交互动作次数,表示交互动作的辅助变量,z(ij)表示该模型最后求得的用户v(i),v(j)的关系强度。
这个图模型可看作是由判别模型和生成模型构成的,其联合分布为:
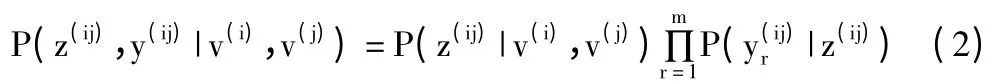
计算出相似度向量S(ij)后,并输入已知的交互动作次数,通过对公式(2)的求解,得到用户关系强度。
由于篇幅有限,对于该模型的详细讨论、推导过程及算法可参见文献[11]。
3 基于信任和非信任的反链接作弊算法STDR
3.1 信任和非信任双向传播的基本思想
针对搜索引擎的链接作弊,有些研究者提出过一些基于信任和非信任的反作弊算法。Zhang[14]等人提出了TDR 算法,Liu[15]等人提出了GDR 算法。这些算法的基本思想是:一个网页既具有价值的一面,也具有作弊的一面。为避免单向传播信任(或非信任)时无法区别对待2 种情况,从好种子集及坏种子集出发,并分别沿着链接或反向链接的方向同时传播信任以及非信任。一个页面的信任传播将受到该页面当前的非信任值的惩罚,反之亦是[16]。最后得到的信任值可作为作弊的降级,非信任值可用来检测作弊。
在这个思想基础上,本文提出一个针对社交网络链接作弊的双向传播信任及非信任的抵抗算法STDR(Social Trust and Distrust Rank)。由于社交网络上的用户不同于搜索引擎的网页,用户间关系的亲疏不仅依赖链接关系,更可以通过关系强度来体现。因此,与前期工作不同的是,STDR 算法在双向传播的同时,还要考虑按用户之间的关系强度分配信任和非信任值,即不是按出链数(或入链数)平均分配分数,而是利用关系强度来影响每次传播信任及非信任的分配比重。
3.2 STDR 算法
算法的框架中,每个社交网络用户拥有2 个分数,即信任分数t(p)以及非信任分数d(p),对应的形式化如公式(3)和公式(4)所示。

其中,st(p)及sd(p)分别由好种子集和坏种子集决定,以好种子集为例,若p 属于在好种子集st中的用户,则;反之,st(p)=0;β 是一个惩罚因子,表示信任与非信任在相互传播过程中的作用;参数αt,αd分别是正向、逆向的衰减因子;z(pq)表示用户p 对于用户q 的关系强度。公式(3)中的(1 -β)·d(p)和公式(4)中的β·t(p)分别用来惩罚信任分数以及非信任分数的传播。
具体算法如下:
Step1输入:社交网络G;好种子集st;坏种子集sd;衰减因子αt,αd;惩罚因子β;关系强度矩阵Z。
Step2初始化G 中用户节点的初值t(p)和d(p),即:
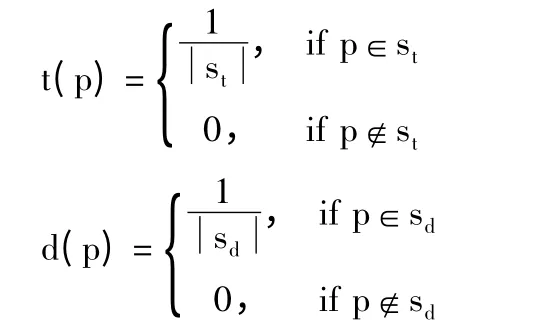
Step3根据公式(3)和公式(4),迭代计算t(p)和d(p)分数,直到收敛;
Step4输出:信任分数矩阵向量t;非信任分数向量d。
4 实验与分析
本文采用真实的UDI Twitter 数据集[17]。该数据集包括14 万条用户信息、2.84 亿个用户间的链接关系以及5 千万条用户发布的推文。通过数据的选取以及多个志愿者的人工投票标记,最后在本实验中用到的Twitter 数据包括约12 079 个用户,其中有1 224个作弊用户,10 855 个正常用户。正常用户中参与链接作弊的有982 个用户。用户关系有近74 万个以及近108 万条推文。
为了验证STDR 算法在对作弊用户以及参与链接作弊的其他用户降级的有效性,本文选择Collusionrank 算法[4]、ATRS 算法[9]进行比较。
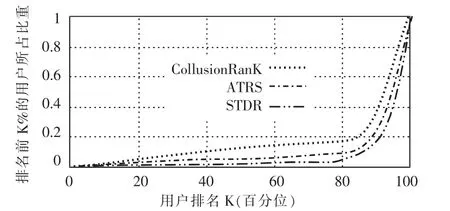
图3 参与链接作弊的其他用户排名
从图3 可见,利用CollusionRank 算法,有接近78%的作弊用户排名在所有用户的后20%;采用ATRS 算法,有超过80%的作弊用户被排在所有用户排名的15%之后。本文提出的STDR 算法,有接近80%的作弊用户被排名在所有用户的后10%,说明更多的作弊用户被排名在后面。
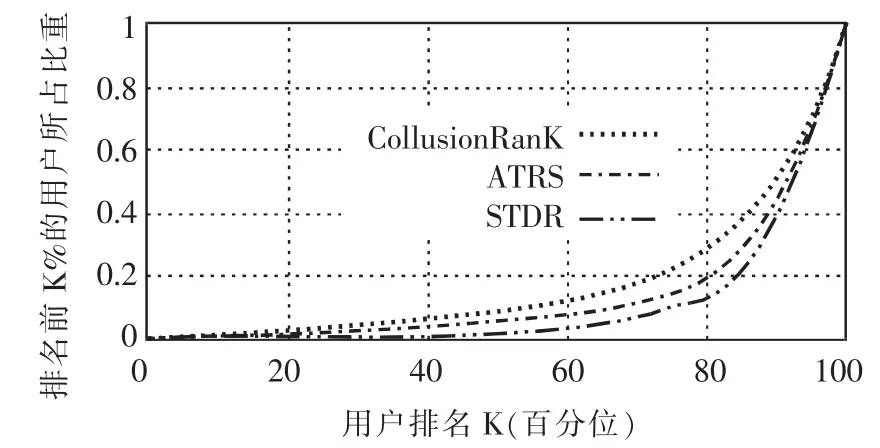
图4 作弊用户的排名
图4 为对参与链接工厂的其他用户降级结果,可分析出,有超过80%的用户被CollusionRank 算法排名在后30%,说明这部分用户通常是那些拥有一定的社会资本的用户,但是却因为处于礼貌或者其他因素而关注作弊用户,即参与了链接工厂的构建。采用ATRS 算法,可以将超过80%的这部分用户排名在后20%。本文提出的STDR 算法能够将接近84%的这部分用户排名在所有用户排序的20%之后。
从上述实验结果可见,与CollusionRank、ATRS 算法相比,基于信任和非信任的传播算法STDR 能够有效地将作弊用户及参与链接工厂的其他用户合理进行降级,即尽可能多地将这些用户的影响力排名降低,从而极大减少了他们的行为产生的不良影响。
5 结束语
针对现有的社交网络链接反作弊算法中没有考虑信任与非信任双向传播的问题,本文首先提出一个抵抗社交网络链接作弊的工作框架,然后介绍了利用用户的4 类特征及用户间的交互频率计算用户关系强度的过程,最后重点阐述了信任和非信任同时传播的思想,并提出针对社交网络的反链接作弊改进算法。实验证明,本文提出的算法与早期相关算法相比,对作弊用户的降级效果更有效,增强了对抗链接作弊的力度。
[1]Yang Chao,Harkreader R,Gu Guofei,et al.Empirical evaluation and new design for fighting evolving twitter spammers[J].IEEE Transactions on Information Forensics and Security,2013,8(8):1280-1293.
[2]Hu Xia,Tang Jiliang,Gao Huiji,et al.Social spammer detection with sentiment information[C]// IEEE International Conference on Data Mining.2014:180-189.
[3]Hu Xia,Tang Jiliang,Liu Huan.Online social spammerdetection[C]// Proceedings of the 28th AAAI Conference on Artificial Intelligence.2014:59-65.
[4]Ghosh S,Viswanath B,Kooti F,et al.Understanding and combating link farming in the twitter social network[C]//Proceedings of the 21st International Conference on World Wide Web.2012:61-70.
[5]Ahmed F,Abulaish M.A generic statistical approach for spam detection in online social networks[J].Computer Communications,2013,36(10-11):1120-1129.
[6]胡俊.在线社会网络上SPAM 行为检测方法研究[D].武汉:华中科技大学,2011.
[7]Yang Chao,Harkreader R,Zhang Jialong,et al.Analyzing spammers’social networks for fun and profit:A case study of cyber criminal ecosystem on twitter[C]// Proceedings of the 21st International Conference on World Wide Web.2012:71-80.
[8]Huang Junxian,Xie Yinglian,Yu Fang,et al.SocialWatch:Detection of online service abuse via large-scale social graphs[C]// Proceedings of the 8th ACM SIGSAC Symposium on Information,Computer and Communications Security.ACM,2013:143-148.
[9]Shen Hua,Liu Xinyue.Propagating anti-trustrank with relationship strength for fighting link farming on twitter[C]//International Seminar on Computation,Communication and Control.2015:9-12.
[10]马凤龙.Twitter 话题影响力用户分析[D].大连:大连理工大学,2013.
[11]Liu Xinyue,Shen Hua,Ma Fenglong,et al.Topical influential user analysis with relationship strength estimation in twitter[C]// IEEE International Conference on Data Mining Workshop.2014:1012-1019.
[12]McPherson M,Smith-Lovin L,Cook J M.Birds of a feather:Homophily in social networks[J].Annual Review of Sociology,2001,27(1):415-444.
[13]Adali A,Sisenda F,Magdon-Ismail M.Actions speak as loud as words:Predicting relationships from social behavior data[C]// Proceedings of the 21st International Conference on World Wide Web.2012:689-698.
[14]Zhang Xianchao,Wang You,Mo Nan,et al.Propagating both trust and distrust with target differentiation for combating link-based web spam[C]// Proceedings of the 25th AAAI Conference on Artificial Intelligence.2011:1292-1297.
[15]Liu Xinyue,Wang You,Zhu Shaoping,et al.Combating Web spam through trust-distrust propagation with confidence[J].Pattern Recognition Letters,2013,34(13):1462-1469.
[16]王友.基于信任和非信任传播的搜索引擎反作弊研究[D].大连:大连理工大学,2011.
[17]Li Rui,Wang Shengjie,Deng Hongbo,et al.Towards social user profiling:Unified and discriminative influence model for inferring homelocations[C]// The 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining(KDD’12).2012:1023-1031.
