基于社交网络服务位置的用户相似性计算方法
2015-11-26魏静
魏 静
(中国人民银行马鞍山市中心支行,安徽 马鞍山 243000)
0 引言
近年来,随着移动设备的普及,在线网络社交服务如Facebook、Twitter、Foursquare 等飞速发展,并且与智能手机等移动设备完美融合,如今大多数智能手机的使用者在任何时间、任何地点都能与其他使用在线社交服务的用户进行分享和交流。此外,全球定位系统(GPS)的出现使得智能手机为在线社交网络服务带来了又一次巨大的机遇。智能手机可以通过GPS 传感器获取用户当前的位置信息[1],然后在他们生成的内容中标记出设备获得的位置。例如,当一个用户写了一篇文章或者照了一张照片,一部智能手机可以在文章或者照片的信息后面标记上用户的位置,如果这篇文章是关于用户当前的位置或是这个照片是用户所在位置的一处风景,位置信息将成为在线社交网络的一笔巨大财富。而对于在其他在线社交网络里试图获得精确位置信息的用户来说,这个标记的位置信息可以被用来提高搜索结果的质量。
在社交网络服务中,由于可以把相似的用户作为朋友推荐给一个新的用户,并且推荐相似用户的搜索经历、喜好等[2],所以寻找相似用户是一个至关重要的环节。用户的相似性计算受很多因素的制约,比如位置、兴趣爱好以及性别等。位置是其中一个非常重要的部分,因为用户几乎一整天都携带移动设备,特别是智能手机,智能手机的位置往往是用户当前的位置,并且能映射出用户的兴趣及生活习惯。
传统的在线社交网络服务中通常使用用户的物理位置信息来计算用户相似性,但这并不能够捕获用户的真正意图[3]。因此,本文使用位置语义来计算用户的相似性,比如用地点的名称或者位置的类型来判定一个精确的位置并且捕获用户的意图。如果一个用户频繁地访问一个电影院,可以合理地推断出这个用户喜欢看电影;如果一个用户频繁地访问一个大学,可以推断出这个用户是这个大学的学生或者教职工。本文模仿人类的感觉设计了相似性计算方法,即根据用户对当前所在位置的兴趣度计算出对另一个位置的兴趣度,并且设计了一种有效地使用位置语义计算用户相似性的新方法。方法中,位置和其所在的类别形成一个层次图形结构,并且只根据相关节点来计算必要节点的相似性。
目前,已经有许多关于计算用户相似性方面的研究,而相似用户之间的相互推荐是其最终目的。Guy等人提出了一种基于不同用户聚合信息的方法[4],但是该方法只是聚焦于互相熟识的人群,因此不能用于计算不认识的用户之间的相似性并且在社交网络上找到新的朋友。范超然等提出一个名为Socialmaching 的框架[5],该框架旨在对使用物理位置的人进行相似性计算,不能捕获用户的真正意图。McDonald 等推荐专家提出了一种专家位置系统来推荐在一个工作地点的人们尽可能地合作[6]。同样文献[7]中也提到了类似的专家搜索引擎,专家搜索引擎根据查询关键词发现相关的人,这些方法在推荐同事以及专家时是有用的,因为推荐的同事及专家研究领域通常和自己一样,但是他们的生活习性可能大不相同,因此该方法不能用来计算普通用户的相似性。Nisgav 等人提出了一种在社交网络中发现用户相似性的新方法[8],即利用用户输入的查询计算出用户之间的相似性,然而,基于社交网络的位置主要取决于智能手机,考虑到基于社交网络中位置信息的重要性,用户输入的查询并没有多大的价值。
随着位置获取技术越来越普遍,GPS 和Wi-Fi 等已经获取了大量的位置信息,并且对于这些位置信息的使用也已经有了许多尝试。一些研究人员通过对个人位置数据的使用提取出了有用的信息,Chen 等人为基于社交网络服务的位置提出了raw-GPS 轨迹简化方法[9],他们考虑了GPS 轨迹的外形轮廓以及语义含义,然而并没有将GPS 的语义含义公示。Krumm 等人提出了一种使用GPS 驾驶历史数据在一次旅程中预测目的地的方法[10]。Gonotti 等人则提出了一种顺序模式的最小化范例的扩展[11],分析了移动物体的轨迹。与这些方法技术不相同的是,Li 等人提出了一种通过探索用户的行为来挖掘2 个用户之间联系的框架[12],用于最小化基于历史位置的用户相似性。
1 位置语义
本文使用位置语义来计算不同位置的用户之间的相似性,位置语义的研究主要包括以下几点。
1.1 位置分类
为了使用位置语义,首先必须构造位置类别层次图,以供后续阶段使用。由于实验使用的是Foursquare 数据,因此本文从Foursquare 中提取出位置类别。位置类别层次图的一部分如图1 所示。
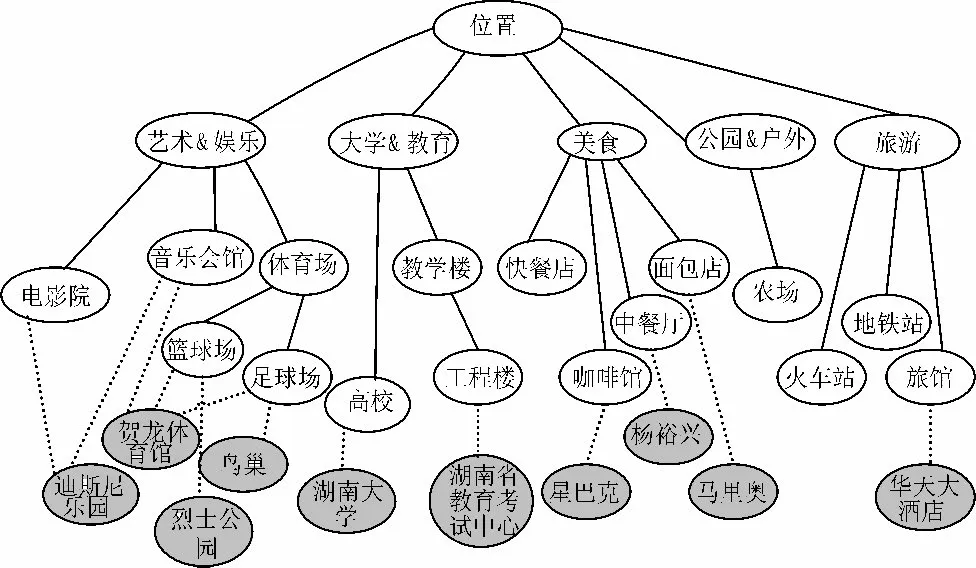
图1 位置类别层次图(部分)
位置类别层次图由2 种类型的节点组成,位置节点和类别节点。一个位置节点代表一个独一无二的位置,例如烈士公园、迪斯尼乐园、星巴克等。一个类别节点则代表一种位置类别,例如一个电影院、一个宾馆或者一个体育馆。
1.2 权重
权重SigSn(u)是指用户u 对位置节点n 的喜爱程度,它的计算如下:

Visitn(u)是用户u 访问位置节点n 的次数,TotalVisit(u)是用户u 访问的所有位置节点的总次数。
用户访问过的位置可能有很多,但是频繁访问的位置只是其中的一小部分。将一个用户频繁访问的k 个位置标记为用户的top-k 位置,由于用户对某个位置的访问频率能直接反映该用户对这个位置的喜爱程度,进而反映出该用户的个性化需求,因此,为了避免实验过程太耗时,只需使用每个用户的top-k 位置来计算相似性[13]。
1.3 相似性大小
如果2 个用户在同一个节点都有自己的权重,则可以由此计算出2 用户在该节点处的相似性(标记为配对节点)。用SimSn(u,v)表示用户u 和用户v 在配对节点n 处的相似性大小。为了计算SimSn(u,v),本文采用用户u 和v 在配对节点n 处的最小权重:
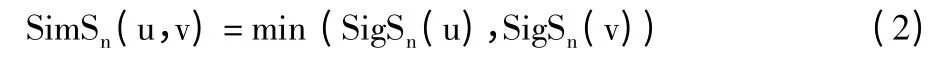
因为最小值可以直观地反映出2 个用户在配对节点处的共同兴趣爱好。
1.4 权重传播
为了得到更精确的相似性,更应当考虑2 个用户间的不匹配节点。例如,2 个都喜欢看电影的用户,一个经常去“A 电影院”,另一个经常去“B 电影院”,人们会很直观地认为这2 位用户是相似的,并且可以推断出他们的爱好都是看电影。也可以反映出这2 个用户的相似性比去同一个电影院的用户相似性弱。
为了模仿这种的人类直觉,本文设计一种方法,即计算位置类别层次图中属于同一祖先节点下的2个不同节点之间的相似性大小,例如,属于同一电影院类别节点下的“A 电影院”和“B 电影院”。
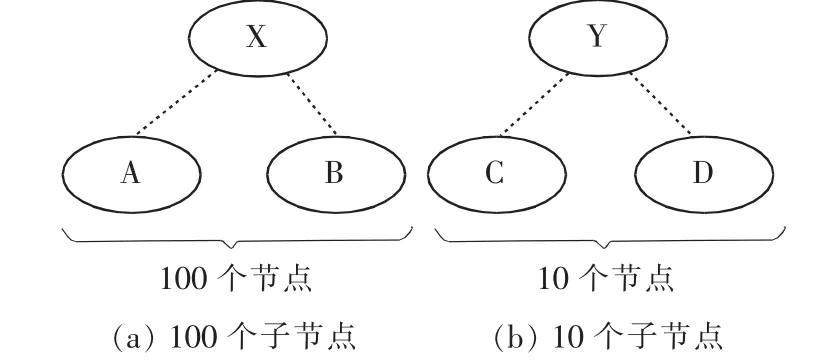
图2 孩子节点数量不同时的传播率
如图2 中2 种情形所示,图2(a)中2 个用户中的一个访问位置A,另外一个访问位置B,节点A 和节点B 都是节点X 的子节点,代表类别X,X 有100个孩子;同样,图2(b)中2 位用户中的一位访问节点C,另一位访问节点D,节点C 和D 都是节点Y 的子节点,代表类别Y,Y 有10 个孩子。由于节点A 和B包含在100 个节点之中,节点C 和节点D 包含在10个节点之中,因此,从概率的角度来看,图2(a)中节点A 和节点B 之间的相似性大于图2(b)中节点C与节点D 之间的相似性。
由于每个位置类别有不同数量的子节点,本文介绍一种用于减小不同数量孩子节点影响的算法。其中,PR(N)是节点n 的传播率,它的计算如下:
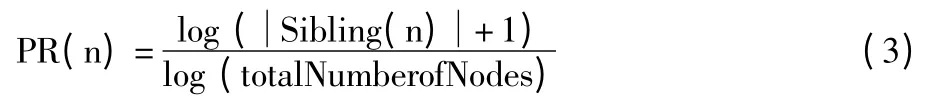
其中,Sibling(n)是节点n 的兄弟节点集,包括节点n。本文给|Sibling(n)|加上1 是为了防止出现被除数为0 的情况。使用totalNumberofNodes 是因为PR(n)通常是一个很小的数,而totalNumberofNodes一般大于|Sibling(n)|,并且很容易获得。当节点n的权重传播到父亲节点时,节点n 处的权重将要乘以传播率(PR(n))。
2 用户相似性计算
用户相似性计算是推荐过程中的重要步骤,也是本文的研究重点,只有更精确地计算出用户之间的相似性,才能更好地进行推荐。
2.1 整体过程
用户相似性计算的过程如下:
1)计算出用户u 和用户v 每一个访问过的位置的权重(见公式(1))。
2)得到用户u 和用户v 的top-k 位置,为每一位用户构造一个top-k 权重表。
3)使用仅被2 个用户访问过的位置节点以及它们的祖先节点来构造一个位置类别层次图。
4)使用算法MatchNorder()来得到配对的节点以及其计算顺序。
5)使用算法Similarity()计算用户u 和用户v 之间的用户相似性。
其中,MatchNodeOrder()算法将在2.2 节介绍,Similarity()算法将在2.3 节介绍。
2.2 配对节点的顺序
计算用户相似性有2 个难点。首先如图1 所示,类别节点是一个树形构造,然而因为某些位置不止隶属于一个类别,也就是说这些位置节点拥有多个父节点,而这样的话,应当挑选其中的一个父节点来传播权重。其次,位置节点的多样层次使得在2 个用户的权重传播直到遇到对方的过程中发现配对的节点变得相当困难。
关于第一个问题,本文按照父亲节点的数量分离出一个位置节点,并且将权重平均分配给被拆分的节点。正如图1 所示,只有一些位置节点不止隶属于一个父节点,所以这个步骤的工作量并不大。关于第二个问题,为了有效地计算与一个配对节点的相似性,本文找出那些需要计算相似性分数的配对节点以及它们的计算顺序。如果没有配对节点顺序,则需要递归地计算相似性分数。关于拆分位置节点、寻找配对节点和配对节点顺序的算法如下。
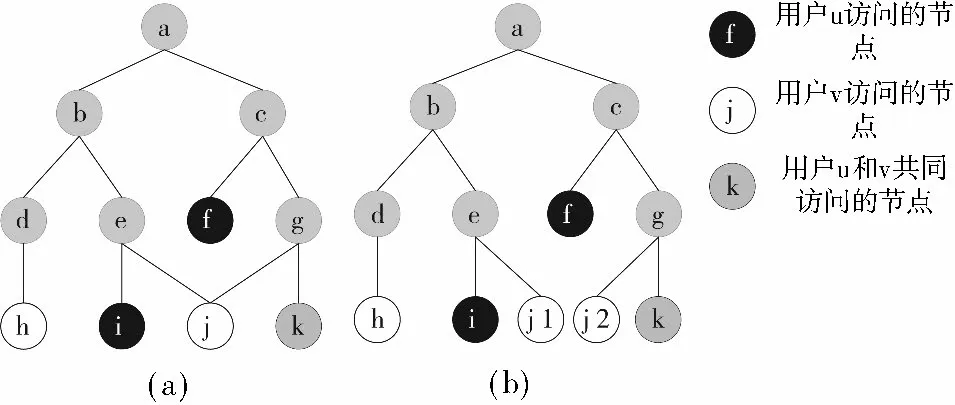
图3 发现配对节点以及其计算顺序的例子
图3(b)表示寻找配对节点以及计算顺序的例子。黑色的节点代表用户u 访问的位置,白色的节点代表用户v 访问的位置,深灰色的节点表示用户u 和v 共同访问过的节点。那些底部有数字的节点表示配对的节点,数字指的是算法输出时的计算顺序。本文用图3 中的例子解释算法的细节。
如图3(a)所示,节点j 有2 个父亲节点e 和g。分离节点j 为j1、j2,使它们分别为节点e 和g 的孩子,如图3(b)所示,再将初始的节点j 的权重平均地分给节点j1、j2,将分离的节点存储在STu 表中。本文为每一个用户构造一个空集:ancestorU 和ancestorV。对于用户u,添加所有访问节点的所有的祖先节点(a,b,c,e,g)以及所有访问节点(f,i,k)到ancestorU。同样,对于用户v,也添加所有访问节点的所有的祖先节点(a,b,c,d,e,g)以及所有的访问节点(h,j1,j2,k)到ancestorV。然后将匹配节点集作为ancestorU 和ancestorV 的交集。在本例中,配对节点集是{a,b,c,e,g,k}节点元素,其后序链表排列为m,作为这个算法的输出返回,如图3 所示,计算顺序是链表<e,b,k,g,c,a >。

2.3 相似性计算
当决定了配对节点集以及其计算顺序后,就可以有效地计算用户的相似性。计算用户相似性的算法如下:
为了提高效率,本文设计基于公式(3)的多重传播率,用来将一个节点的权重通过多重层次传播给它的祖先节点。MPR(n,v)表示从节点v 到祖先节点n的多重传播率,它的计算如下:
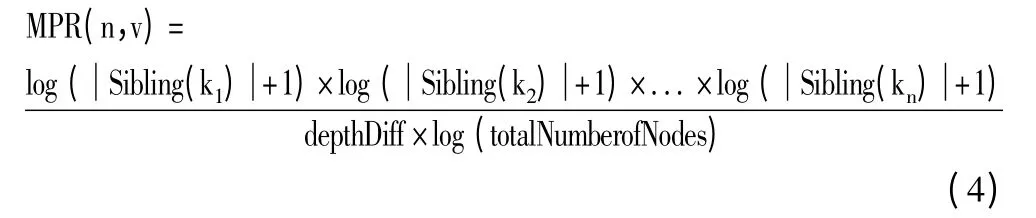
其中,depthDiff 是节点n 和节点v 之间的层次差。k1是节点v,k2是节点v 的父亲节点,以此类推,因为depthDiff 是节点n 和节点v 的层次差,所以节点kdepthDiff即节点n。

算法Similarity()利用配对节点顺序链表m 作为其输入,计算用户相似性。首先初始化SimScore 为0,并且列举访问链表m 中的每一个节点n,让descendants 作为节点n 的子孙节点集。对于用户u,如果STu中有节点v,并且STu中没有节点n,则为节点n做一个空表项目来存储子孙节点的传播分数。然后使用公式(4)将节点v 处用户u 的权重传播给配对节点n,计算节点n 的相似性分数并将相似性分数添加到SimScore,然后从2 个用户的权重中减去SimSn(u,v),并且返回SimScore 作为算法输出。
3 实 验
本文使用Foursquar 用户的数据作为数据集来评估提出的方法。在讨论实验的结果之前,先简短介绍一下该数据集。
3.1 数据集
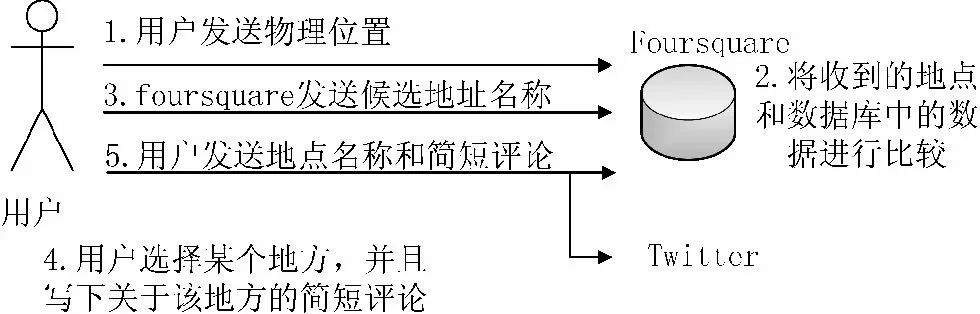
图4 Foursquar 的服务图示
Foursquare 是一种最关注基于位置服务的社交网络服务。为了评估本文提出的方法,笔者从Foursquar 收集了大量数据。图4 展示了Foursquare 的“check-in”特点。当一个用户试图“check-in”一个确定的地点时,用户发送一个用户所在的真实物理地址,然后Foursquare 将收到的位置信息与其地点数据库进行对比,并且以距离的远近列出一小部分地点的名称,用户选择某个地点的名称作为其当前的位置,用户还可以写一个简短的关于这个位置的评论。最后用户将选择的地点名称以及评论上传到Foursquare 和Twitter 上。因此,通过使用Foursquare APIS[14]可以将物理地址转换为位置语义。由于用户同样会发送“check-in”信息给他们的Twitter 账户,因此可以通过Twitter 页面收集用户访问过的位置信息。笔者收集了17 863 个用户访问过的1 358 287 个位置信息,然而大多数用户并不愿意将他们的记录作为数据集以供使用,因此本文只选择了比较活跃的591 个用户以及他们访问世界各地的251 053 个位置。
3.2 相似用户选择

图5 本文方法选择的2 位相似用户例子
图5 展示用本文提出的方法选择出来的2 位相似用户的例子。用户A 和用户B 住在2 个不同的地方,但是他们都是学生并且喜欢购物,如果仅仅从物理地址来考虑,用户A 和用户B 的相似性分数几乎为0。然而本文的方法使用位置语义,因此可以发现他们之间的相似性。
3.3 本文方法性能
笔者用真实数据集的实验评估了本方法,发现与某位用户最为相似的其他用户。通过将本方法与一个利用位置语义来计算相似性的方法—Jaccard 索引进行比较,证实了本方法的有效性。
为了寻找到与某个用户最相似的用户,本文首先计算了591 位用户两两间的相似度,然后对比每个用户访问过的位置和其最相似用户访问过的位置。
本文通过比较2 种方法推荐的最相似用户访问过的位置信息,计算精确值、recall 以及F-measure。
1)精确值计算如下[15]:

其中,f(u)表示用户u 的top-k 位置类别集,ur是2 种方法选择出来的最相似用户。
2)Recall 的计算方法如下[16]:

3)F-measure 的计算方法为[17]:

然后,为每个用户计算出精确值、recall 以及Fmeasure 的平均值。

图6 对于top-k 位置为5、10、20、30 的实验结果
如图6 所示,对于每一个不同的top-k 位置集,本方法都优于Jaccard 索引方法,比Jaccard 索引方法的精确值高84%、recall 高62%、F-measure 高72%。由于Jaccard 索引方法对于一个位置的访问频率是用一个二进制数来表示,因此本文中不使用相对权重而使用绝对访问频率来与Jaccard 索引进行比较(图6 中本文方法的修改),可以看出,该方法依然优于Jaccard 索引的方法。
3.4 Top-k 位置
本文的实验证明了只考虑某个用户的top-k 位置得到的结果优于考虑该用户所有访问过的位置。因此仅使用某个用户的top-k 位置计算相似性。
为了证明top-k 位置的访问量占了总访问量的绝大部分,本文使用TopKCover(k)标记top-k 位置的访问量在总的访问量中所占的比例:

其中,U 是所有用户的集合,TopkVisitk(u)是用户u访问top-k 位置的数量,TotalVisit(u)是用户总共访问的位置数量。
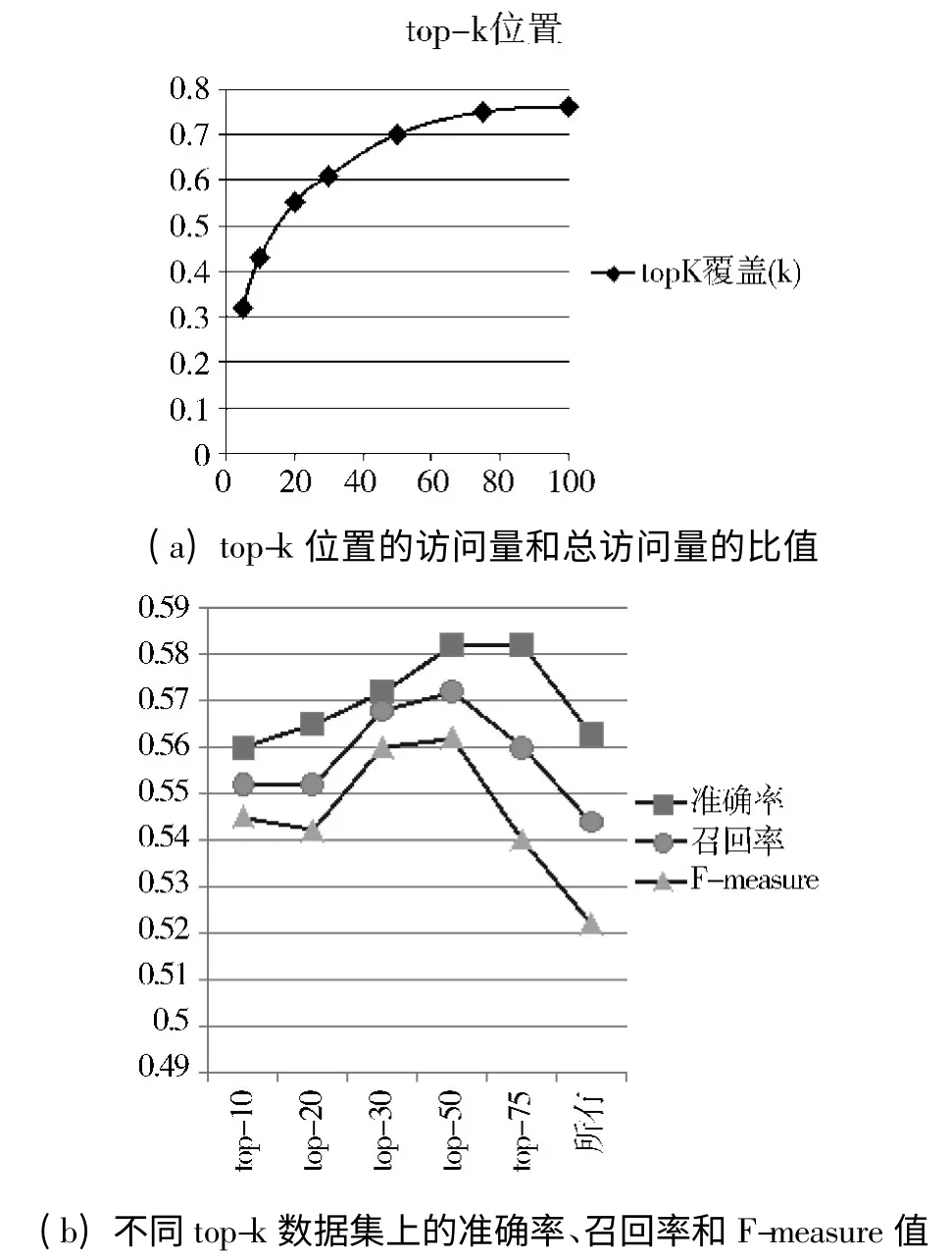
图7 选择适当的top-k 的2 个实验
从图7(a)显示的结果来看,使用超过100 个被访问位置来描述一个用户的特征是没有意义的,即使是覆盖了大量访问量的少数top-k 位置也不行。top-5 位置覆盖32%,top-10 覆盖43%,top-20 覆盖55%,top-30 占据62%。
图7(b)表明只考虑一个用户的top-k 位置的结果好于考虑用户所有访问过的位置的结果,3 个评估值都在top-50 下降。
4 结束语
本文提出了一种精确有效的用户相似性计算方法。即使用位置语义和位置类别层次,在语义上匹配位置,而其他已有的研究都仅聚焦于物理位置。同时,实验结果表明了本文的方法优于Jaccard 索引方法,实验也精确地证明了究竟多少数量的位置对于一个用户来说是有意义的,在了解用户行为上很有帮助。在以后的研究中,应当在位置语义上加上其他的信息,比如用户产生的标记等,以此来获得更精确的结果。
[1]李晓静,张晓滨.基于LCS 的用户时空行为兴趣相似性计算方法[J].计算机工程与应用,2013,49(20):251-254.
[2]袁书寒,陈维斌,傅顺开.位置服务社交网络用户行为相似性分析[J].计算机应用,2012,32(2):322-325.
[3]朱立超,李治军,姜守旭.基于位置的社交网络研究综述[J].智能计算机与应用,2014,4(4):60-64.
[4]Guy I,Ronen I,Wilcox E.Do you know?:Recommending people to invite into your social network[C]// International Conference on Intelligent User Interfaces.2009:77-86.
[5]范超然,黄曙光,李永成.微博社交网络社区发现方法研究[J].微型机与应用,2012,31(23):67-70.
[6]McDonald D W.Recommending collaboration with social networks:A comparative evaluation[C]// Proceedings of the Conference on Human Factors in Computing Systems.2013:598-600.
[7]Ehrlich K,Lin C Y,Griffiths-Fisher V.Searching for experts in the enterprise:Combining text and social network analysis[C]// Proceedings of the International ACM SIGGROUP Conference on Supporting Group Work.2007:117-126.
[8]Nisgav A,Patt-Shamir B.Finding similar users in social networks:Extended abstract[C]// Proceedings of the 21st Annual ACM Symposium on Parallel Algorithms and Architectures.2009:169-177.
[9]Chen Yukun,Jiang Kai,Zheng Yu,et al.Trajectory simplification method for location-based social networking services[C]// Proceedings of the International Workshop on Location Based Social Networks.2009:33-40.
[10]Krumm J,Horvitz E.Predestination:Inferring destinations from partial trajectories[C]// Proceedings of the 8th International Conference on Ubiquitous Computing.2006:243-260.
[11]Giannotti F,Nanni M,Pinelli F,et al.Trajectory pattern mining[C]// Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.2008:330-339.
[12]Li Quannan,Zheng Yu,Xie Xing,et al.Mining user similarity based on location history[C]// Proceedings of the 16th ACM SIGSPATIAL International Symposium on Advances in Geographic Information Systems.2008:134-136.
[13]吴大愚.社交网络服务发展与现状研究[J].科技创新与应用,2013(18):76-77.
[14]高永兵,杨红磊.基于内容与社会过滤的好友推荐算法研究[J].微型机与应用,2013,32(14):75-77.
[15]刘分,汤红波,葛国栋.基于移动网络位置信息的群体发现方法[J].计算机应用研究,2013,30(5):1471-1473.
[16]张利军,李战怀,王淼.基于位置信息的序列频繁模式挖掘算法[J].计算机应用研究,2009,26(2):529-531.
[17]刘旭,易东云.基于局部相似性的复杂网络社区发现方法[J].自动化学报,2011,37(12):1520-1529.
