基于可变形部件模型及稀疏特征的行人检测
2015-11-26甘鹏坤
甘鹏坤,陶 凌,龙 伟
南昌大学信息工程学院,南昌330000
随着科学技术的发展,计算机逐渐能够帮助甚至是替代人类完成一些以前看似只能由人类完成的任务,如何让计算机更好的服务于人类生活成了近年研究的热点.其中,让计算机分析及理解摄像头捕捉到的图像,就像人类通过眼睛获得信息一样,是当前研究的重点,而行人检测是这个研究领域的显著代表.
行人检测就是利用智能化手段,从图像或视频中自动识别行人,通过计算机视觉、数字图像处理等技术,在计算机上实现行人自动识别的过程.这种技术可以对静态图像或视频中的行人进行检测.由于行人所处背景的复杂性及不确定性,受光照而产生的明暗变化,服饰各异,行姿多变,以及由摄像机位置造成行人在图像上的不同等,使得行人检测是一项极具挑战的任务.
行人检测主要涉及两方面内容,包括图像特征提取和模型训练.稀疏编码直方图的方法是在方向梯度直方图(histogram oforiented gradient,HOG)[1-2]检测模型的基础上,计算以每个像素为中心块的稀疏编码,对得到的稀疏编码值进行插值计算,以此形成图像的特征,该方法在一定程度上提高了检测精度.PASCAL VOC挑战赛数据集合中的训练数据通常指定了标签,但这些标签没有标明各个部件,是一种弱标签,现引入一种具有判别能力的弱标签学习方法,对该弱标签数据集合进行训练得到部件模型,再选择级联检测的方法,可使行人检测的准确率和速率得到显著提高.
1 图像特征的提取
稀疏编码直方图(histograms of sparse codes,HSC)[3]特征算子类似于HOG特征算子,但不同的是,基于稀疏编码技术用稀疏的码字来表示图像的局部特征.这种稀疏的字典通过一种无监督的学习从数据中获取.计算出每个像素的稀疏编码后,通过聚类使其成为有规律的单元,就可用它们取代HOG特征.
1.1 局部图像稀疏表达
采用K-SVD进行字典学习[4],通过无监督字典学习产生K-means.给出一组图像块Y=[y1,y2,…,yn],K-SVD算法将通过最小化公式(1)重构误差找到一个字典 D=[d1,d2,…,dn],以及一个相关的稀疏矩阵 X=[x1,x2,…,xn].
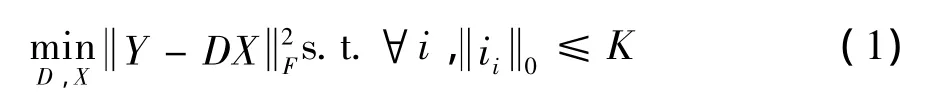
其中,xi是X的列,零范数计算稀疏编码x中非零值的个数,K是预先定义的稀疏等级.K-SVD通过迭代选择X和D来解决优化问题.当给出一个字典D时,可通过贪婪匹配追踪算法高效地解出稀疏编码X;当给出编码X,字典D可通过奇异值分解来更新.当字典D学习完成时,可通过正交匹配追踪算法计算稀疏码.
1.2 稀疏编码直方图提取
稀疏编码X,其尺寸等于字典的大小.对于非零项xi∈ X,通过软分级的方式来分派绝对值到细胞单元中的4个像素单元中.对于每个平均稀疏编码使用L2范数对特征向量F进行归一化处理,最后对F中的每个元素进行指数变换

其中,α是维度指数,通常0<α<1,指数变换使得F值的分布更具一致性,提高了辨别率.对于行人目标检测,仅使用值是不够的,还需在线性聚类之前增加半波调整值,使每个经过字典学习的码子 i在稀疏直方图中有3个值,为[,max(xi,0),max(-xi,0)].
将所有归一化后的平均单元块,按照先行后列的顺序展开成向量,所得到的向量即为对应的HSC特征直方图.图1是稀疏特征算子可视化结果.
2 可变形部件模型建模
星型模型[5-6]可定义成简单的目标检测语义模型,实际上就是由一系列滤波器组成星型结构的模型,包括根滤波器和部件滤波器.
在行人检测问题中,针对可分部件,可分为两种情况:①该部件不能再分解,在此定义为终端,用T表示;②部件还可往下分解,称为非终端,用N表示.为增加根滤波器,创建终端符号A与滤波器F0关联.对于星型模型包含N的部分,用Y1,Y2,…,Yn来表示.因此,混合模型Q由根滤波器和多个部件滤波器组成
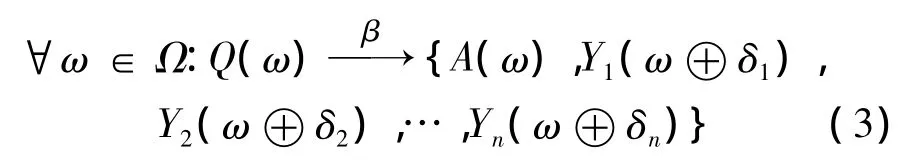
其中,Ω表示一组实例化的参数,如图像的坐标以及尺度;ω∈Ω;A(ω)是一个模型指定的终端部件;Yi∈N∪T,结构规则中所对应的每个部件有一个偏差β和规范化的锚点补偿.每个锚点补偿的形式为 δ=[δx,δy,δl],操作 ⊕ 表示由[x,y,l]×[δx,δy,δl]∈ Ω×Δ 映射到(x+2δlδx,y+2δlδy,l+ δlλ).(x,y,l)表示在图像金字塔中的位置和尺度.其中,(x,y)是一个数组;l表示所在图像金字塔中的层数,是为了获得某一层的分辨率而需要在金字塔中向下走的层数.约束部件滤波器在根滤波器的下一层中,因此,对于每一个δl可固定δl=1.

图1 稀疏编码直方图特征Fig.1 Histograms of sparse codes features
为指定模型的每个部件,创建终端符号B1,B2,…,Bn,将其与对应的滤波器F1,F2,…,Fn关联起来.为完成语义模型,将每个部件终端Bi(ω)与其对应的非终端部件Yi(ω)通过如式(4)的变形规则连接起来.
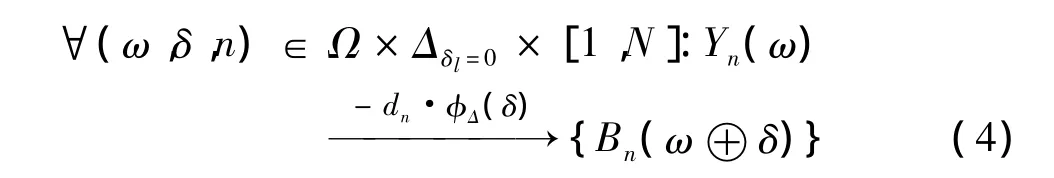
其中,φΔ为变形特征函数;Δ为相对于理想位置的偏移,由变形规则产生的结构允许部件滤波器相对根滤波器有一定位移,限制位移偏差δ,本研究设Δδl=0={(δx,δy,δl)∈ Δδl=0}.dn为部件n的变形花费.直观地说,针对每个子部件相对根部件的位置,这个参数分配了一个非常大的负偏差.将这些规则组合起来,组成语义模型,它定义了星型结构的可变形部件模型.
3 特征训练
3.1 弱标签隐藏变量结构化SVM算法(weak label latent variable structured support vector machine algorithm,WL-SSVM)[7-8]
设C={c1,c2,…,cn}为输入训练数据集合,G={g1,g2,…,gn}为标签集合,S={s1,s2,…,sn}为输出,即训练得到的模型.从训练样本{(c1,g1),(c2,g2),…,(cn,gn)}集合中得到学习函数f:C→S,其中(ci,gi)∈C×G.为构造函数方便,用x和y代替c和g,分别表示输入的训练数据,标签数据.
构造一个损失函数L:y×s→R≥0用于将标签与输出关联起来,其中R为规则集合.函数L(y,s)计算标签y∈Y时其对应预测输出为s∈S时的花费.设M为c×y上固定但未知的概率分布,本研究的目标是找到一个函数f(x),使得预期的损失函数所得花费低于期望值EM[L(y,f(x))].
设f模型参数由向量w来表示,它通过最大化图像特征映射ψ(x,s)的线性函数得到.

为了显性的表示参数,将 f(x)写成 fw(x).S∈S(x),x为其中一个实例.
由于M分布情况未知,在训练集合中通过最小化规范风险来训练参数w.WL-SSVM定义为
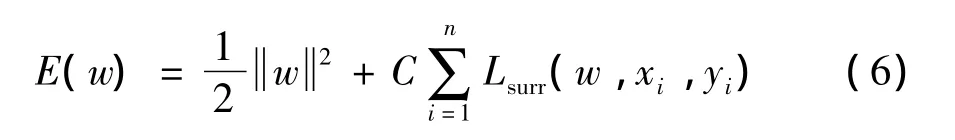
其中,Lsurr由两部分增广预测损失组成
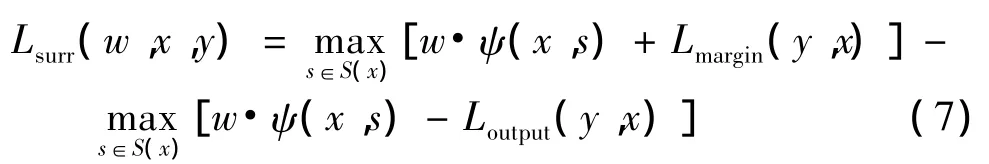
在式(7)等号右边第1项中,Lmargin鼓励高损失输出,因此会促使得分下降;而第2项中Loutput抑制高损失输出,因此低损失预测得分将被拉高.当Lmargin=Loutput时,Lsurr成为了一种斜坡损耗,可见,Loutput的选择对于训练问题的计算难度有重大意义.
3.2 目标检测
级联检测算法的核心内容是通过阈值修剪来简化检测模型,在不损失检测精度的基础上,提高行人检测效率.算法步骤为:
1)通过使用主成份分析(principal component analysis,PCA)系数矩阵[9]将标准模型内的特征向量降维,把所有32维滤波器映射为12维滤波器并保存起来,原模型继续保持32维滤波器;
2)将所有滤波器重新排列,再写入模型,形成简化模型;
3)读取非PCA分数统计信息,并对分数进行裁剪;
4)读取PCA分数统计信息并对分数裁剪;
5)将统计分数按方差值递减排序;
6)计算阈值.从第0个部件开始不断累加分数,然后取所有正样本在此累加过程中的最小值,再加上偏移权重,形成该级的级联检测阈值.
通过以上步骤标准模型转换为级联模型.将根滤波器与特征金字塔进行卷积并计算分数响应,通过对目标预先假设和形变阈值进行裁剪,从而完成对目标的级联检测[10-11].
4 实验数据分析与处理
本研究使用INRIA Person行人检测以及PASCAL VOC挑战赛数据集合,采用PASCAL VOC挑战赛协议对系统进行评价,这些评测集是公认的目标检测中难度很大的测试,该数据集合都包含数千张真实世界场景的图片.在数据集合中,已标注了行人目标的区域边框,测试目标是预测图像中行人边框.在实际应用中,系统会输出一系列带评分的区域边框,研究人员通过在不同点对这些分数进行阈值化处理,从而获得一个包含测试集合中所有图片的准确率-查全率(precision-recall,PR)曲线.
4.1 评判规则
在PASCAL VOC挑战赛中,常用PR曲线替代计算精度的平均得分.设TP为真阳性,表示输出的预测是p而真实的结果也是p;FP为假阳性,表示输出的预测是p而真实的结果是n;TN为真阴性,表示输出的预测是n而真实的结果也是n;FN为假阴性,表示输出的预测是n而真实的结果是p.PR曲线的准确率(Precision)定义为检测到样本中属于正确目标样本的数量除以所有检测到目标的样本数量的商,即

查全率(Recall)为检测到样本正确目标样本的数量除以所有正确目标样本的数量的商,即

4.2 行人检测的实现及结果分析
基于可变形部件模型的行人检测[12-13]主要分为训练和检测两个阶段.
4.2.1 模型训练阶段
训练是指根据提取好的人体目标特征来训练相应的分类器,并构造模型滤波器,以便在检测阶段得到很好的利用.训练结果的好坏会直接影响以后检测的效果,所以要在训练阶段进行大量的训练,以获得最小的误差.采取HOG特征对样本图像进行特征提取并生成特征金字塔,本研究中训练时金字塔层数取10,图像块大小为8×8像素.利用WL-SSVM算法对特征进行训练和分类,经过大量的正负样本训练以及不断更新滤波器来获得最佳的检测模型.训练好的混合模型如图2.

图2 混合模型中的根滤波器和部件滤波器模型的训练结果Fig.2 Training results of root and part filters in the mixed model
针对于行人语义模型,可将数据集合中的目标按照长宽比分成6组,训练一个包含6个组件的混合模型.主要覆盖行人上肢部分的有5个必选部件,其余为可选部件.检测时,根据目标被遮挡的情况,选择对应合适的模型与之匹配.模型训练结果如图3.

图3 语义模型中的根滤波器模型和部件滤波器模型的训练结果Fig.3 Training results of root and part filters in the semantic model
4.2.2 人体目标检测阶段
利用训练好的多部件模型滤波器对输入的目标图像进行检测,若检测到目标,则标出目标在图像中的位置.
图4是单个目标检测的结果.其中,图4(a)是使用混合模型检测得出的结果;图4(b)是使用行人语义模型检测得出的结果.观测两者可以看出,两种模型检测的结果有略微区别,与其对应的模型结构相似,图4(b)中人体下肢部分由可选部件组成,检测结果两者并无多大差异.
由于混合模型不存在可选部件,其部件数量在模型训练时确定,而每个组件之间相互独立,有时会出现组件之间的竞争关系.如图5,目标图像只包含一个行人目标,但是图5(b)显示检测出两个行人,外层目标对应的是混合组件模型检测的结果,而里面的框图只包含行人上一部分,显然是组件模型检测的结果.当使用行人语义模型检测时就不会出现这种现象.
针对遮挡问题,行人语义模型体现出更好的性能.如图6,对同一幅图像,图6(a)是使用混合模型检测出的结果,图6(b)是使用行人语义模型检测出的结果.在使用混合模型时,图中左边的下半身被遮挡的行人目标未被检测出来.
本研究检测时使用的测试数据集为INRIA Person测试数据集[14-15],该测试数据集合包含了741张图像,其中正样本288张,负样本453张.检测结果如图7.其中,实线表示使用混合模型检测的结果,点线表示的是使用行人语义模型检测的结果,虚线表示混合模型加级联检测结果.

图4 单个目标的检测结果Fig.4 Detection results of a single target

图5 混合模型与行人语义模型检测结果Fig.5 Test results of the mixed model and pedestrian semantic model
由图7可见,检测性能曲线都突破了(0.8,0.9)点,表明准确率以及查全率较高.其中使用级联检测算法的PR曲线[16]基本上与一般检测方法相似,但其速度却大大提高了.
设待检测窗口有1 300个,缩放比例为0.9,为了对图像中大小不同的人体目标进行有效检测,以8为扫描步长分别在x方向和y方向上遍历扫描图像,在相同硬件条件下,对大小为320×240像素的图像采用上述3种模型进行检测.表1给3种模型的检测耗时,并通过统计测试数据集检测所花费的平均时间,发现使用级联检测算法的耗时仅是采用其他检测算法的平均耗时倍.

图6 遮挡目标的检测结果Fig.6 Detection results of occluded targets

图7 检测结果PR曲线Fig.7 Test results PR curve

表1 级联检测与一般检测耗时比较Table1 Comparison of time consume between cascade detection and general detection s
结 语
本研究通过对大量人体检测方法的学习研究,采用特征学习方法提取合适的人体特征,用图像语义模型对行人检测问题进行建模,并使用改进的机器学习算法隐藏变量SVM(latent support vector machine,LSVM)以及弱标签隐藏变量SVM来训练模型滤波器,最后结合级联检测算法实现对人体目标的检测,大幅提高了检测效率.
本研究尚存在一些亟待解决的问题.如稀疏直方图特征算子计算复杂度较大,使整体检测速度较慢,基于目前的硬件条件,实时性很差;在复杂的环境下,如人群拥挤,人与人之间相互遮挡时出现误检概率较大,人体语义模型只能解决下肢被遮挡的情况,而无法检测到左右半身被遮挡的情况.
/References:
[1]Dalal N,Triggs B.Histograms of oriented gradients for human detection[C]//International Conference on Computer Vision and Pattern Recognition.[S.l.]:IEEE,2005:886-893.
[2]Lin Zhe,Davis L S,Doermann D S,et al.Hierarchical part-template matching for human detection and segmentation[C]//IEEE 11th International Conferenceon Computer Vision.Rio de Janeiro(Brazil):IEEE,2007:1-8.
[3]Ren Xiaofeng,Ramanan D.Histograms of sparse codes for object detection[C]//IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Portland(USA):IEEE,2013:3246-3253.
[4]Elad M,Aharon M.Image denoising via sparse and redundant representations over learned dictionaries[J].IEEE Transactions on Image Processing,2006,15(12):3736-3745.
[5]Fergus R,Perona P,Zisserman A.Object class recognition by unsupervised scale-invariantlearning[C]//Proceedings of IEEE Computer Society Conference on ComputerVision and Pattern Recognition.Madison(USA):IEEE,2003,2:II-264-II-271.
[6]Weber M,Welling M,Perona P.Towards automatic discovery of object categories[C]//Proceedings of Computer Vision and Pattern Recognition.Hilton Head Island(USA):IEEE:101-108.
[7]Tsochantaridis I,Joachims T,Hofmann T,et al.Large margin methods for structured and interdependent output variables[J].The Journal of Machine Learning Research,2005,6:1453-1484.
[8]Lecun Y,Chopra S,Hadsell R,et al.A tutorial on energy-based learning [J].Predicting Structured Data,2006.
[9]Zhang Chuang. Human cascade detection based on deformable component model[D].Dalian:Dalian Maritime University,2014.(in Chinese)张闯.基于可变形部件模型的人体级联检测 [D].大连:大连海事大学,2014.
[10]An Ping.The construction of cascade detector based on linear SVM and its application in target detection[D].Changsha:National Defense Science and Technology University,2007.(in Chinese)安平.基于线性SVM的级联检测器的构造及其在目标检测中的应用 [D].长沙:国防科学技术大学,2007.
[11]Li Tongzhi,Ding Xiaoqing,Wang Shengjin.The human detection method based on cascade[J].SVM Chinese Journal of Graphics,2008(3):566-570.(in Chinese)李同治,丁晓青,王生进.利用级联SVM的人体检测方法 [J].中国图象图形学报,2008(3):566-570.
[12]Yin Xuecong.Research on face detection method based on deformable component model[D].Xi'an:Xi'an Electronic and Science University,2012.(in Chinese)尹雪聪.基于可变形部件模型的人脸检测方法研究[D].西安:西安电子科技大学,2012.
[13]Guo Jie,Zhang Honggang,Chen Daiwu,et al.Object detection algorithm based on deformable part models[C]//Proceedings of the 4th IEEE International Conference on Network Infrastructure and DigitalContent.Beijing:IEEE,2014:90-94.
[14]Everingham M,Van Gool L,Williams C K I,et al.The pascal visual object classes(VOC)challenge [J].International Journal of Computer Vision,2010,88(2):303-338.
[15]Everingham M,Ali Eslami S M,Van Gool L,et al.The pascal visual object classes challenge:a retrospective[J].International Journal of Computer Vision,2015,1111(1):98-136.
[16]Everingham M,Van Gool L,Williams C,et al.Pascal visual object classes challenge results[J].Machine Learning ChallengesEvaluating Predictive Uncertainty Visual Object Classification&Recognising Tectual Entailment,2006,93(12):117-176.
