直接体绘制中增强深度感知的网格投影算法
2015-11-25冯晓萌吴玲达于荣欢
冯晓萌 吴玲达 于荣欢 杨 超
直接体绘制中增强深度感知的网格投影算法
冯晓萌*①吴玲达②于荣欢②杨 超②
①(装备学院研究生管理大队 北京 101416)②(装备学院复杂电子系统仿真实验室 北京 101416)
体绘制技术生成的图像中丢失了深度信息,已有的增强深度感知方法通常只针对某些结构区域,牺牲其它结构信息的同时又直接修改体绘制算法。面向光线投射体绘制算法,该文提出一种增强深度感知的方法,不直接修改光线投射算法。投影均匀网格到体数据表面,网格跟随表面变形后经光线投射绘制在结果图像中,用户根据变形网格能够感知图像中的深度信息。同时,为突显变形网格所反映的深度信息,对投影后的网格线进行深度相关的着色,并添加投影辅助线以连接不同深度表面上的投影网格。算法在统一计算设备架构下并行执行后,不仅能够实时生成图像支持用户的交互控制,且图像中增强深度感知的效果明显,特别是当体数据包含多个分离或者交叉物体时。
体绘制;深度感知;网格投影;并行执行;统一计算设备架构
1 引言
体绘制技术[1]将3维体数据映射为2维图像,而图像中丢失了深度信息,这对理解体数据是一种阻碍。针对这一问题,本文研究了增强体绘制结果中深度信息感知的方法。
已有的增强体绘制结果中深度感知的方法中,比较常用的是在生成图像中绘制提示信息[2],例如在某些结构周围绘制光环[3,4]和阴影[5,6]等,能较好地表现出这些结构区域的深度信息,但同时却遮挡了其它结构区域的信息[7]。计算景深效果的方法[8]在一定程度上增强了人对绘制物体的深度感知,但是其只增强了对焦点物体的感知同时还模糊了其它物体的显示。焦点与上下文[9]的可视化方法能够在一定程度上增强对焦点区域的感知,但其明显降低了对背景信息的显示。
上述方法均在牺牲其它信息的情况下增强了深度感知。Zheng等人[7]通过调整不透明度和亮度,对体数据中的十字交叉区域(X-junction areas)进行了深度重排序,增强了半透明状态下交叉物体间的深度顺序感知。但是,此方法不允许用户交互,无法按照用户的需求进行绘制。Bair等人[10,11]深入研究了网格纹理对表面形状的感知效果,虽有讨论应用于体绘制,但其侧重于同时表现两个相互遮挡表面的形状,未将网格纹理应用于表现体绘制中的相对深度信息,特别是不同物体或结构间的相对深度。
针对上述方法的不足,研究了在不牺牲其它信息的条件下可交互的增强体绘制中深度感知的方法:将均匀网格投影到体数据表面,根据均匀网格投影后的形变情况感知体数据表面的深度变化。研究表明,纹理是影响人眼对图像感知的因素之一[12],投影后的网格绘制到图像中即为网格纹理[13],影响人眼对图像信息的感知。为增强网格投影的深度感知效果,将网格投影线按深度进行着色,并添加了网格投影辅助线等。本方法不仅适用于单个物体表面,对体数据中包含多个物体的情况也有很好的增强深度感知的能力。
2 均匀网格投影
人能够根据先验知识理解图像中的信息,特别是当图像中存在提示信息时,能够更好地理解图像内容。本文研究的目标是在不牺牲其它信息和不改变原体绘制算法的情况下增强深度信息感知。图1显示了均匀网格投影在空间表面后不同视角下的观察效果,其中:侧视图能够提供一定的可视深度信息感知,显示出了表面的起伏及其延伸方向;俯视图则未表现出表面的起伏信息。
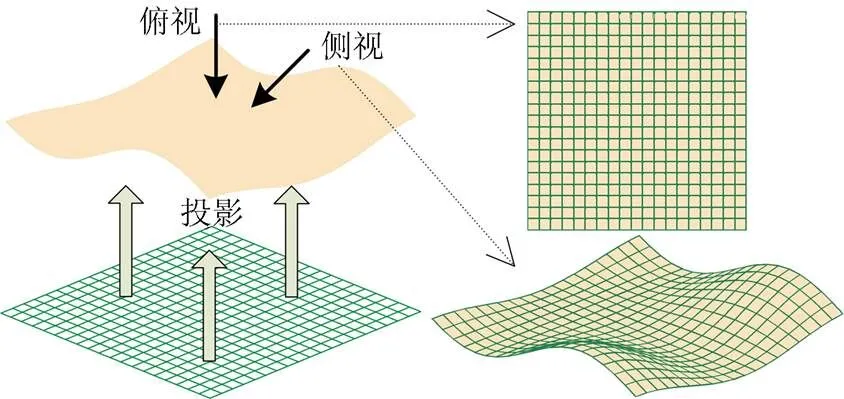
图1 不同视角下的网格投影效果
对比图1中的两个视图,说明观察网格在表面的投影时需要一定的观察视角。文献[13]通过在绘制的物体表面映射纹理显示表面的形状信息,使用了网格纹理,但是其观察视角固定为俯视,没有较好地抓住网格所能表现的深度信息。同时其研究使用的体数据为一个简单物体,未对更复杂的情况进行研究。本文则充分利用了网格对表面深度信息的感知作用,使用均匀网格投影对体数据中的物体表面以及物体间的相对距离等进行了感知增强。
2.1 网格投影流程
光线投射算法[14]是绘制质量最好的体绘制算法[15],其是从一定角度对体数据的观察。由图1可知,光线投射方向与网格投影方向不能平行,对体数据进行均匀网格投影与光线投射的关系如图2所示。这里定义光线投射算法中使用的体素为有效体素,即光线对有效体素进行了数据采样、颜色转换等操作,网格只投影到其遇到的第1个有效体素上,即投影到参与绘制的体数据表面。

图2 均匀网格投影示意图
算法流程如图3所示,其虚线框中是网格投影与光线投射的并行。光线投射算法中,每条光线的操作都相同,因此图3的虚线框中只显示了一条光线的投射操作流程。虚线框外的网格投影信息来自所有截止的光线,投影辅助线生成阶段独立于光线投射,将在3.3节进行介绍。
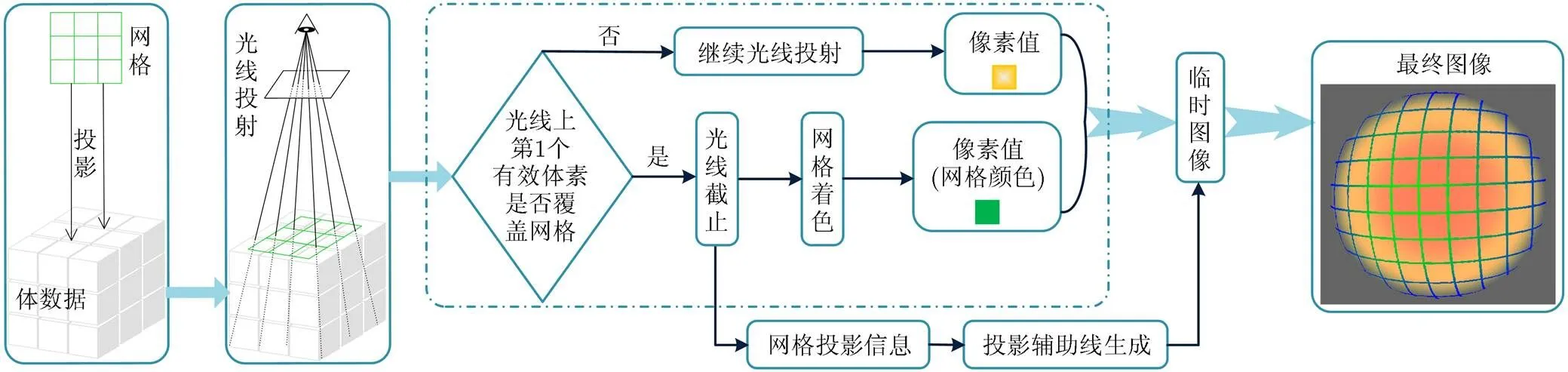
图3 网格投影算法流程
将均匀网格投影到其遇到的第1个有效体素上,若此体素同时又是某条光线投射时遇到的第1个体素,则截止此光线并将其对应的像素设置为网格着色后的颜色,否则网格投影对光线投射无任何影响。被截止的所有光线对应网格的投影点,根据所有网格投影点的信息生成投影辅助线并绘制到光线投射生成的图像中,即获得算法最终的生成图像。最终生成图像中,根据均匀网格投影后的变形情况能够观察出网格所投影到的表面的起伏变化,增强对绘制结果的深度感知。
2.2 网格着色
根据网格变形情况感知深度信息的同时,为投影后的网格进行深度相关的着色有利于增强深度对比。每个网格点的投影距离如图4所示,是网格上点到其投影点之间的距离且不同的距离对应不同的深度。网格的颜色根据投影距离进行变化,在颜色上对网格的深度进行对比显示,使体数据的深度信息更加突显。
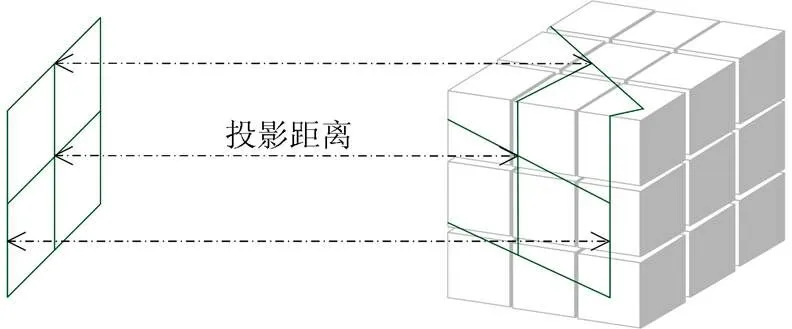
图4 网格投影距离

一般情况下,光线投射体绘制算法会用到许多颜色值,为避免颜色冲突导致网格线不明显的情况发生,网格着色时函数式应该保持颜色值与体绘制使用颜色不同。因此,网格颜色应尽量在3个分量上与绘制体数据使用的颜色保持较大差异,以便设置颜色值与投影距离的函数关系。
2.3投影辅助线
网格投影时若相邻两点分别投影到了深度不同的两个表面,由图2所示的光线投射与网格投影的关系可知,最终生成的图像中此两点将不相邻从而导致投影网格间断。投影网格间断将影响其对表面深度的感知效果,因此,应该尽量避免此现象。将网格上相邻而投影后不相邻的两个网格投影点使用虚直线连接,此条直线定义为投影辅助线。投影辅助线最终显示在绘制图像中,避免网格线投影的间断现象。当投影后的网格点与视点之间存在有效体素时,此网格点将被遮挡。同理,一些投影辅助线也可能会被遮挡,在生成图像中只绘制两端均不被遮挡的投影辅助线。
3 算法执行
光线投射算法易于并行实现,而图3所示的本算法流程并未改变光线间的独立性。因此,算法依然能够并行实现,在其具体执行中应保持其可并行性。
3.1 光线投射
图3中,网格投影附加在光线投射过程中,通过对光线投射路径上第1个有效体素的判断,决定对光线投射的影响。并行执行过程中,所有光线均需对其遇到的第1个有效体素进行网格投影的判断,判断过程分为以下几个步骤:
步骤7 结束判断过程。
经过上述步骤后,若光线未被截止,将继续完成其投射过程并生成对应的像素值。网格投影只影响部分光线,而不影响光线投射过程中的具体操作,因此保持了原光线投射算法的生成效果,只是在其基础上覆盖了网格。
3.2 着色函数设置
估计的投影距离值域有冗余,分布在值域两端。因此,设置式(1)中的函数时,保持的自变量值域固定,且对应此值域的两端函数变化缓慢而中间部分则变化明显。根据投影距离着色是为了增强网格投影后的深度感知,无精确要求,可以进行粗略估计和设置,以能够看到投影后网格线的颜色变化为佳。图5所示为一个示例函数的曲线,下方是对应曲线值的颜色条带,颜色取值对应于投影距离值域。

图5 网格线着色示例
3.3投影辅助线生成
图像中的每个网格投影点均对应一条光线,所有光线投射结束后处理投影点生成投影辅助线。如图6所示,经过像素点和的光线分别对应网格投影点和,记录这两个投影点在网格平面的对应点和。与记录和两点的原理相同,在光线投射完成后获得所有图像中的网格投影点在网格平面的对应位置点集。在点集中若存在相邻两点对应的投影距离差别较大,则此两点对应的网格投影点之间存在投影辅助线:以图6为例,和为相邻网格点时,由于到的投影距离与到的投影距离差别较大,投影点和之间存在投影辅助线,直接在图像中使用虚直线连接和两个像素点以绘制此投影辅助线。中两点是否相邻由两点间的距离决定,距离不大于则视为相邻;两点的投影距离差大于时视为差别较大。默认值为2,默认值为光线采样步长,执行时均可进行调整。
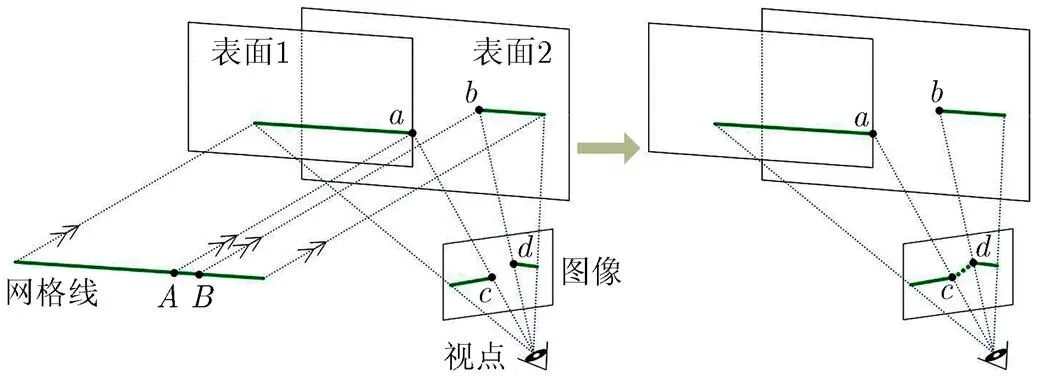
图6 生成投影辅助线示意图
为保持算法的可并行性,投影辅助线需并行生成,将网格均匀离散为个点,保证在网格的4个角和所有网格线的交叉点处均有离散点,各离散点对应的处理过程均为:(1)判断此离散点的临域内是否存在中的两个以上点,若存在则继续下一步,否则结束此过程;(2)将这两个以上点两两组合,判断每个组合中的两点和对应的投影距离是否差别较大,是则生成和对应的投影辅助线。
3.4交互设置
算法中,拖动鼠标可以使网格中心点在以体数据中心为中点半径为的球面上移动。如此,图2所示的光线投射和网格投影的方向均可交互控制,便于用户根据需要调节两者的角度从而达到更好的增强深度感知的效果。同时,算法中还允许用户对网格自身的参数进行交互设置,可以控制网格中网孔的大小,以及整个网格的大小。
3.5并行执行
上述算法执行中保持了可并行性,算法能够并行实现从而提高执行效率。现有的绘制技术研究中,统一计算设备架构[16](Compute Unified Device Architecture, CUDA)是使用最多的并行实现基础。本算法同样使用CUDA并行实现,充分利用CUDA对通用计算的支持,提高算法的执行效率,为用户交互提供时间支持。在4节的基础上,加入网格投影后光线投射的具体执行伪代码如表1所示。
表1中,函数isCoverGrid(pos)根据有效体素的位置参数pos判断网格是否能够投影到此位置,具体步骤见3.1节;函数getGirdColor(pos)根据参数pos对应的有效体素的投影距离进行网格着色,并返回此颜色值;函数rayCasting(pos)对参数pos处的有效体素进行光线投射的相关计算,并返回光线投射到pos位置时获得的当前像素值。表1中生成的图像还需要进行投影辅助线生成,具体操作步骤见3.3节,其较简单不再列出其伪代码。在CUDA架构下投射光线时,为提高光线对体数据的采样效率,将体数据绑定到3维纹理,利用纹理采样器实现对数据场内数据点的高效插值采样。
表1光线投射内核函数伪代码

内核函数:网格投影下光线投射的执行线程 pixX = blockIdx.x*blockDim.x + threadIdx.x; //像素X坐标pixY = blockIdx.y*blockDim.y + threadIdx.y; //像素Y坐标IF (pixX, pixY) is in the Image THEN pixValue = {0,0,0,0};// 初始化像素记录值为零 theRay = genRayforPix (pixX, pixY); //生成对应光线WHILE theRay not terminate DO//计算当前循环中光线在数据场中遇到的有效体素位置rayPos = getRayPosition(theRay, dataVolume); IF rayPos is out of the data volume BREAK WHILE;IF rayPos is the first THEN IF isCoverGrid(rayPos) is true THEN //被网格覆盖 pixValue = getGirdColor(rayPos); //网格着色ELSE pixValue = rayCasting(rayPos); //执行光线投射END IFELSE pixValue = rayCasting(rayPos); //执行光线投射END IFEND WHILEImage [pixX, pixY] = pixValue; //获得对应的像素值END IF
4 具体应用与分析
算法未改变光线投射的操作,因而无需对光线投射算法进行限定。实验中,为检验算法的实际效果,实现了一个简单的光线投射算法(DVR算法),在其基础上进行网格投影并生成最终图像。使用多个体数据进行绘制,对使用和未使用网格投影两种情况所得到的绘制效果进行了对比展示。同时,统计了实验中的算法执行时间,以说明算法并行执行的高效性。
4.1算法应用效果
图7是算法应用于体数据的绘制结果。图7(a)中绘制的是Sphere体数据,图7(a1), (a2)和图7(a3), (a4)均对比显示了使用和未使用网格投影的绘制结果:没有网格投影的两幅图无法获得其表面的深度信息;而有网格投影的两幅图,体数据表面的起伏情况能够被网格的变形情况反映出来,辅助用户感知体数据的表面深度信息。对比图7(a2)和图7(a3),根据网格变形及其着色情况可以看出:图7(a2)中部的9个网格颜色一致且形状无变形,可以判定其覆盖区域为平面,即中间部位是平面周围是曲面;图7(a3)中则不存在此种情况,根据网格的变形情况可判定其覆盖的表面是曲面。根据图7(a)中的实验结果可以看出,网格投影能够反映出体数据表面的深度信息,特别是根据网格变形及着色情况的对比能够得出较详细的表面深度信息。
图7(b)是BackpackScan体数据的绘制结果,对某些区域的对比进行了细节展示:竖框中显示了体数据中的线束和圆柱形物体两者的遮挡关系不明,而进行网格投影后,线束所在区域的网格投影波动较大,可以判定此区域网格投影在了线束上而非圆柱体表面,说明网格投影后可知线束在前;横框中同样显示出圆柱形物体和另一个物体间存在遮挡关系,网格在另一物体的对应像素区域未按其形状进行改变,说明网格投影在圆柱形物体表面,圆柱形物体遮挡另一物体。
图8是Neghip体数据的绘制结果,在没有网格投影的绘制图像中,用数字标识了6个区域,这6个区域的相对位置在绘制结果中无法辨识。但是,加入网格投影后,这6个区域的相对深度及相对位置较易辨识:网格投影线从绿色到蓝色表示深度从浅到深。对比标号“4”和“5”的两个区域,虽然投影的网格间没有相连,但是根据两个区域的网格线颜色可以得知区域“5”的深度较浅。在区域“1”,“2”和区域“2”,“4”之间均存在投影辅助线,通过这些投影辅助线很容易区分其两端连接的不同结构表面的深度:深度由浅到深依次为区域“1”,“2”,“4”。与图7(b)中相同,在图8中标号为“1”的区域处,存在遮挡情况,根据网格的投影情况很容易判断两个物体的遮挡关系。
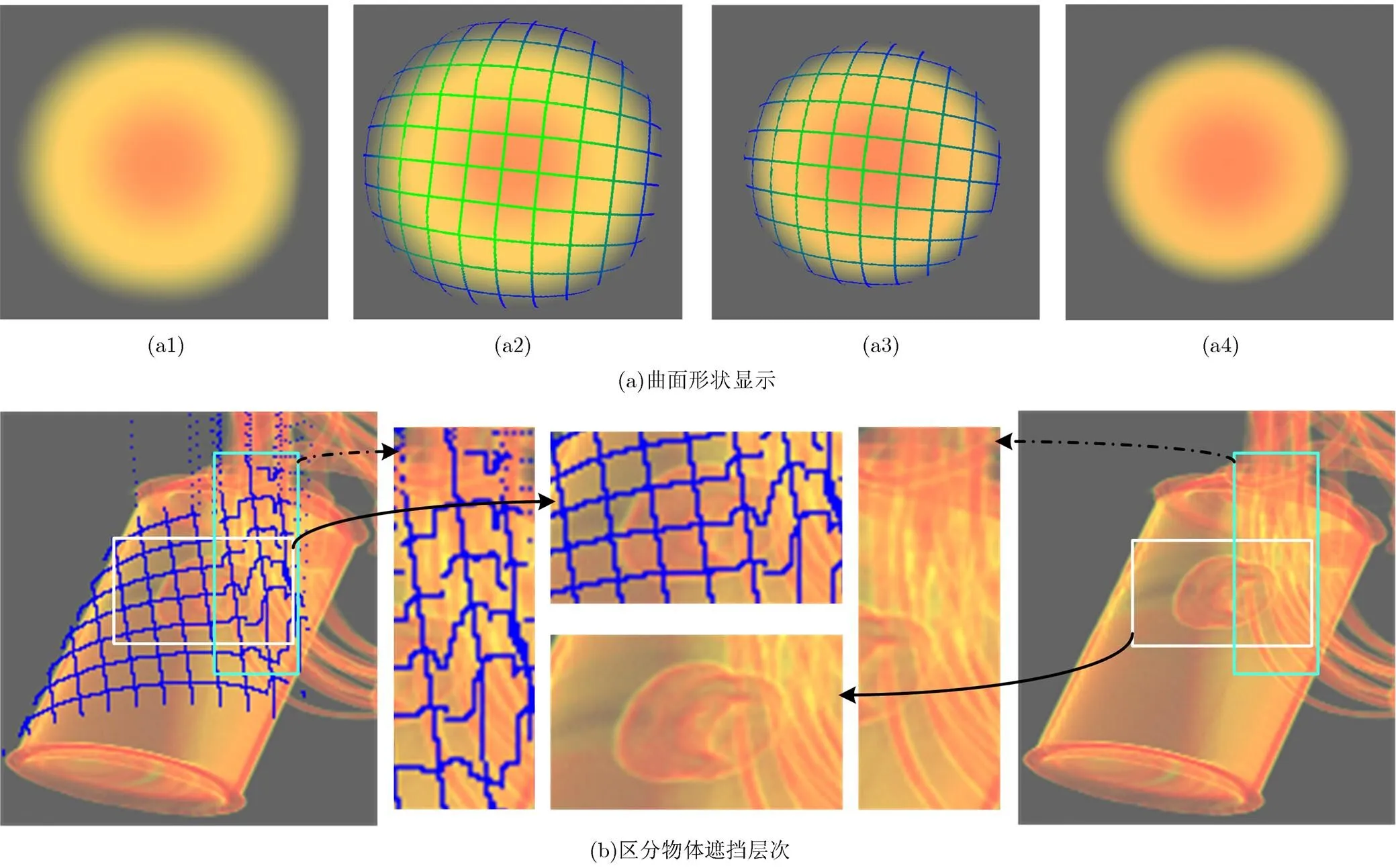
图7 算法应用效果
由图7和图8中网格投影的对比效果可知,使用网格投影后的绘制结果能够显示出很多体数据中原有的深度信息,便于用户对体数据的观察和深度感知。算法中使用了3种辅助手段增强绘制结果中的深度感知,分别是投影变形后的网格、网格投影线的颜色以及投影辅助线,以投影变形后的网格为主,另外两种对其进行补充:变形网格提示其所覆盖表面的起伏信息,网格投影线颜色区分网格所在的不同深度区域,投影辅助线连接不同区域的网格并增强这些区域的深度对比。获得深度感知效果的同时应注意,当投影网格密度过大时(比图7和图8中的密度大很多),网格的存在将严重影响绘制图像的显示效果。因此,进行网格投影时,为获得较好的显示效果应避免投影密度过大的网格。
相比文献[7]中的方法,本文算法通过投影后网格的变形情况感知物体间的遮挡层次,不必调整物体结构的不透明度,较简单且保持了光线投射体绘制算法的独立性。相比Bair等人[10,11]的方法,本文算法深入研究了网格投影在体绘制中增强深度感知的效用,不仅能够感知表面形状,还能够辨明物体间的遮挡关系等,针对分离物体使用投影辅助线能够较好地感知物体之间的相对深度。算法中,网格显隐可以控制,当不绘制网格投影时即为光线投射算法的绘制结果,网格投影能够辅助用户增强对绘制结果中的深度感知。同时,网格的参数可以被用户交互控制,便于观察绘制结果中的不同区域及其深度细节。

图8 相对深度感知效果
4.2算法执行效率
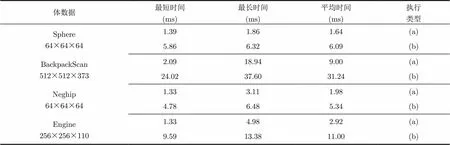
算法并行执行的硬件环境为:Intel Core i5-2400 CPU 3.10 GHz、4 GB内存、NVIDIA GeForce GTX 470显卡;软件环境为集成NVIDIA GPU Computing SDK 4.2的Microsoft Visual Studio 2005。为验证算法的执行效率,在交互改变网格参数、投影方向及光线投射方向的情况下,连续统计了算法执行500次的时间。交互过程中,网格大小为图像大小的整数倍(从1到6任意调整),格孔宽度在10到100个像素之间变化,3.1节中的阈值为0.5倍的单像素宽度,3.3节中的设置为2,设置为光线采样步长即数据场中同一维度上相邻两数据点之间的距离。由于执行过程伴有交互控制,执行时间会随之变化,表2中只列出了这500次执行的平均时间及其中的最短时间和最长时间。实验使用了4个体数据,生成图像分辨率为800×800。表2中统计了两种执行类型的绘制时间,分别是:(a)只执行投影网格的操作,不进行光线投射,即不执行图3中判断为“否”的分支;(b)完全按照图3所示流程执行并生成最终图像。
通过表2中列出的500次执行时间的值域及均值可以看出,基于CUDA架构并行执行后算法的效率完全能够达到实时。因此,算法在交互控制下能够实时更新绘制结果,便于用户观察其交互结果从而获得更佳的深度感知效果。对比表2中(a)和(b)两种类型的执行时间,不进行光线投射时的执行时间明显较短,说明网格投影算法的执行效率很高,不仅为其实时应用于其它光线投射算法提供了时间裕度上的支持,还可以添加其它操作等。
算法在CPU中串行执行时,绘制表2中4个体数据的最短时间均在1 s以上,基本不可用,因此不再列出算法的串行执行时间统计。同时,这也说明算法设计时保持其可并行性是非常必要的,能够最大限度地提高执行效率,保证其可用。
表2算法执行时间统计
体数据最短时间(ms)最长时间(ms)平均时间(ms)执行类型 Sphere64×64×641.391.861.64(a) 5.866.326.09(b) BackpackScan512×512×3732.0918.949.00(a) 24.0237.6031.24(b) Neghip64×64×641.333.111.98(a) 4.786.485.34(b) Engine256×256×1101.334.982.92(a) 9.5913.3811.00(b)
5 结束语
本文提出了一种使用网格投影增强体绘制中深度感知的方法,该方法在保持光线投射体绘制算法独立性的同时能够很好地辅助用户增强对绘制结果中深度信息的感知,使用户能够更好地理解体数据。算法与光线投射算法一样可并行执行,在CUDA架构下并行实现后能够达到实时绘制,便于用户交互使用。在图7和图8所示的实验结果中,网格投影线在某些区域不够平滑,将在以后的研究中进行改进。同时,体数据表面起伏会影响网格投影线的视觉效果,当表面起伏剧烈到一定程度后将导致网格投影线的视觉混乱以至于无法显示深度信息。该方法是一种新的增强体绘制中深度感知的方法,存在的上述不足将在未来的工作中进一步研究和完善。
[1] Zhang Q, Eagleson R, and Peters T M. Volume visualization: A technical overview with a focus on medical applications[J]., 2011, 24(4): 640-664.
[2] Kersten-Oertel M, Chen S J, and Collins D L. An evaluation of depth enhancing perceptual cues for vascular volume visualization in neurosurgery[J]., 2014, 20(3): 391-403.
[4] Everts M H, Bekker H, Roerdink J B,.. Depth-dependent halos: illustrative rendering of dense line data[J]., 2009, 15(6): 1299-1306.
[5] Soltészvá V, Patel D, and Viola I. Chromatic shadows for improved perception[C]. Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Non- Photorealistic Animation and Rendering, Vancouver, Canada, 2011: 105-116.
[6] Ament M, Sadlo F, Dachsbacher C,.. Low-pass filtered volumetric shadows[J]., 2014, 20(12): 2437-2446.
[7] Zheng Lin, Wu Ying-cai, and Ma Kwan-liu. Perceptually- based depth-ordering enhancement for direct volume rendering[J]., 2013, 19(3): 446-459.
[8] Schott M, Grosset A V P, Martin T,.. Depth of field effects for interactive direct volume rendering[C]. Proceedings of the Eurographics/IEEE Symposium on Visualization 2011, Bergen, Norway, 2011: 941-950.
[9] Berge C S Z, Baust M, Kapoor A,.. Predicate-based focus-and-context visualization for 3D ultrasound[J]., 2014, 20(12): 2379-2387.
[10] Bair A S, House D H, and Ware C. Texturing of layered surfaces for optimal viewing[J]., 2006, 12(5): 1125-1132.
[11] Bair A and House D. A grid with a view: optimal texturing for perception of layered surface shape[J]., 2007, 13(6): 1656-1663.
[12] 蒋刚毅, 朱亚培, 郁梅, 等. 基于感知的视频编码方法综述[J]. 电子与信息学报, 2013, 35(2): 474-483.
Jiang Gang-yi, Zhu Ya-pei, Yu Mei,.. Perceptual video coding: a survey[J].&, 2013, 35(2): 474-483.
[13] Interrante V, Fuchs H, and Pizer S M. Conveying the 3D shape of smoothly curving transparent surfaces via texture[J]., 1997, 3(2): 98-117.
[14] Xie Jin-rong, Yu Hong-feng, and Ma Kwan-liu. Interactive ray casting of geodesic grids[C]. Proceedings of the Eurographics Conference on Visualization 2013, Leipzig, Germany, 2013: 481-490.
[15] 马千里, 李思昆, 白晓征, 等. CFD非结构化网格格心格式数据高质量体绘制方法[J]. 计算机学报, 2011, 34(3): 508-516.
Ma Qian-li, Li Si-kun, Bai Xiao-zheng,.. High-quality volume rendering of unstructured-grid cell-centered data in CFD[J]., 2011, 34(3): 508-516.
[16] NVIDIA. About CUDA[OL]. https://developer.nvidia.com/ about-cuda, 2015.
[17] Rosen P. A visual approach to investigating shared and global memory behavior of CUDA kernels[C]. Proceedings of the Eurographics Conference on Visualization 2013, Leipzig, Germany, 2013: 161-170.
[18] Zhang Yu-bo, Dong Zhao, and Ma Kwan-liu. Real-time volume rendering in dynamic lighting environments using precomputed photon mapping[J]., 2013, 19(8): 1317-1330.
[19] 曾理, 倪风岳, 刘宝东, 等. 计算机统一设备架构加速外部计算机断层图像重建[J]. 电子与信息学报, 2011, 33(11): 2665-2671.
Zeng Li, Ni Feng-yue, Liu Bao-dong,.. Image reconstruction of exterior computed tomography accelerated by computer unified device architecture[J].&, 2011, 33(11): 2665-2671.
Enhanced Depth Perception Grid-projection Algorithm for Direct Volume Rendering
Feng Xiao-meng①Wu Ling-da②Yu Rong-huan②Yang Chao②
①(,,101416,)②(,,101416,)
The depth information in volume data is lost in the image rendered by volume rendering technique. The existing methods of depth perception enhancement only enhance some structures in the volume data at the cost of other structures details, and they directly edit the volume rendering algorithm. For ray-casting algorithm, a method of depth perception enhancement is presented, and it does not directly edit the algorithm. Specifically, an inerratic grid is projected to the surface of volume data, and then the grid changing along surface is rendered in the final image. Users can apperceive the depth information of surface from the changed grid. Meanwhil, two methods are used to enhance the depth information of the grid projection lines, one is coloring the grid lines based on the depth, and the other one is adding accessorial lines to join the grid lines on two surfaces with different depths. When implemented using compute unified device architecture, the image is rendered in real-time under user interaction. The effect of depth perception enhancement in the final image is obvious especially when the volume data contains some disjunct or intersectant objects.
Volumerendering; Depth perception; Grid-projection; Parallel implementation; Compute unified device architecture
TP391 献标识码: A
1009-5896(2015)11-2548-07
10.11999/JEIT150303
2015-03-13;改回日期:2015-06-29;
2015-08-27
冯晓萌 130123feng@163.com
国家自然科学基金(61202129)资助课题
The National Natural Science Foundation of China (61202129)
冯晓萌: 男,1986年生,博士生,研究方向为科学计算可视化.
吴玲达: 女,1962年生,教授,研究方向为虚拟现实与可视化、多媒体技术.
于荣欢: 男,1983年生,助理研究员,研究方向为科学计算可视化、集群计算.
