面向复杂规范文本的基础评价本体构建及本体关系完善研究
2015-11-23顾铁军
●顾铁军,李 毅
(1.东华大学传播系,上海201620;2.公安部第三研究所检测中心,上海200031)
面向复杂规范文本的基础评价本体构建及本体关系完善研究
●顾铁军1,李 毅2
(1.东华大学传播系,上海201620;2.公安部第三研究所检测中心,上海200031)
规范;评价本体;本体关系;双向挖掘
为实现面向复杂规范文本的评价任务的有效知识表示和管理,从规范文本的特征分析出发,首先建立起基础评价本体架构,接着以评估数据为知识资源,提出基于双向关联挖掘和赋权计算的非分类本体关系的发现方法。最终,结合具体规范建立起相关的基础评价本体,并实施了本体关系挖掘实验,结果表明在有意义关系扩展方面具有较好的改善。
1 引言
面向复杂规范文本的评价通常是指建立在标准、规范,乃至法律法规等复杂文本基础上,由专业的评估机构遵循特定的评估方法,开展包含一定约束力和强制性的评估实践。随着全球化、标准化进程的推进,这种评价形式已成为产品质量监督、服务提供保证、商业流程管理、公共政策执行等活动中必不可少的方法和手段。然而,这类评价体系的应用常常存在以下问题:(1)规范文本的复杂性表现为多维度、多层次、多指标的评价体系结构,包含评价任务、对象及其环境的诸多术语和概念,且这些概念之间可能存在错综联系的知识关系,纯粹人工进行知识梳理有一定难度,对专业水平要求较高;(2)规范文本使用自然语言描述,形式呈现半结构化或非结构化,为对其进行严谨科学的知识表示增大了难度,导致评估过程易受测评人员的主观经验判断所影响;(3)评估所涉及的不同参与者,如评估体系制定者和评估实施者虽然都依托公开的规范,但理解的程度和层次不同,缺乏统一的评价知识表示参照基础,容易出现歧义和争议;(4)符合性检验为其主要的评价方法,建立在基本的满足符合与否的判断层次上,这种评价结果对评价决策指导的作用有限,大量原始的测评数据没有得以有效地利用,实际可能湮没了有价值的知识联系和规则。
对此,需要一种创新的方法将复杂规范文本评价体系所蕴含的知识结构化地描述出来,结合信息处理技术使其更好地支持评价过程,以充分利用该评价体系所蕴涵的内在知识特征,弥补其在表示和理解上的不一致所带来的不利影响。原先作为哲学概念的本体在知识表示方面展现出了蓬勃的生命力和契合度,它能够有效地描述评价概念以及概念之间的关系。本文提出一种较为通用的评价本体知识体系的理论框架,首先,构建面向复杂规范文本的基础评价体系本体,包括概念、概念间的分类关系以及一般规范语言的表示;进而,利用评估数据挖掘出潜在的非分类关系,实现对基础本体的补充和完善。
2 相关研究现状
面向复杂规范文本的评价与语义和本体的结合主要针对特定领域或特定规范,通用性研究不多。例如,Zhong B T等[1]就工程建设、建筑质量管理的本体语义建模做出了一系列的探究。Nash E等[2]讨论了基于标准的自我评估自动化的可行性,研究了农业产品标准如元数据、本体术语集和本体化规则的形式化表示,以及基于德国肥料使用规范的相关应用。Gábor A等[3]以高等教育的质量保证过程为案例,提出了过程本体、参考本体以及基于本体匹配的评价方法。Gong P[4]聚焦银行领域的应用,提出语义标注过程模型,以形式化逻辑形成一套集成商业控制流和数据流的规范评价理论。Ekelhart A等[5]构建了一种支持信息技术安全评估的通用准则的本体工具,能够给出通用准则的本体表示,并支持技术认证过程的评价。
复杂规范文本的评价体系蕴藏了大量的非分类关系,而非分类关系的发现是目前本体学习中的重要和较新的研究问题。主要的研究方法包括针对领域文本、语料库的语言学分析和数据挖掘方法,或是两者的结合。例如,Wong M K等[6]提出了从非结构化文本中抽取非分类关系的多阶段关系搜索框架,包括跨多个句子抽取概念等若干创新性工作。Villaverde J等[7]通过从领域文档中抽取链接特定概念对的、且被频繁使用的动词的方法来发现和标注非分类关系。刘萍[8]等结合形式概念分析(FCA)和关联规则挖掘,识别领域核心概念、概念间的等级关系和相关关系。谷俊等[9]利用基于上下文的术语相似度计算获得术语间的相似度权重,加入术语间可能存在修饰词等情况的考量,使得关联规则挖掘更适合于本体关系获取研究。刘巍等[10]提出通过SKOS叙词表转化方法构建本体,以关联规则挖掘作为概念间关联属性的本体补充,并基于本体实现语义化检索的应用功能。
3 面向复杂规范文本的基础评价本体构建
在若干具体情境实证的基础上,通过对评价规范文本以及测评过程中与之密切关联的活动及结果信息的分析和总结,本文建立了面向复杂规范文本的基础评价本体,分解为三层,即顶层本体、面向规范的评价体系框架本体和面向具体评估对象的评价内容实例。通过这三层结构,可以构筑出评价知识构成元模型,作为基础提供对特定领域的规范评价体系本体的构建支持,进而纳入实际产品或服务展开评价应用情境,从而形成面向复杂规范文本的评价本体知识体系。
(1)顶层评价本体。顶层评价本体,通过对规范化文本的表述形式进行分析,可抽取出顶层本体所概括的评价体系的通用知识结构和内涵,结合测评活动的规律特征,从而形成面向复杂规范文本的评价体系本体构建的通用知识表示基础,即评价知识构成的元模型。顶层评价本体的主要概念包括评价标准条目、评价条目关系、测评结果和符合性评价结果、评价对象、评价内容、评价条件、符合性描述形式和预期结果。结合测试或检验以及评价过程,顶层评价本体的概念框架如图所示。

图顶层评价本体的结构
(2)面向规范的评价体系框架本体。面向规范的评价体系框架本体是基于顶层评价本体构建的通用知识表示方法,可实现对一类复杂评估对象的评价体系的本体建模表示。该层本体针对特定领域的评估体系制定者,支持领域内知识共享的评价体系描述。
(3)面向评估对象的评价内容实例。评估对象可以是产品、服务、人员、组织等,该层最接近具体的评估对象,它针对不同评估对象的需求,从面向规范的评价体系框架本体衍生出本体的实例形式,针对遵循评价规范的评估实施者,可借助语义技术支持提供依据评价体系本体获得的、具备互操作性的自动或半自动的评价结果。
4 基于本体关系挖掘的评价本体完善
4.1 面向复杂规范文本的评价本体的知识特征
面向复杂规范文本的评价本体围绕评价标准条目概念、将其分解为评估对象、评估内容、评估条件等若干子概念,对以评估为目的赋予特征的相关概念及关系进行提取和表示。在细粒度层次上,规范文本的特定表述形式,如泾渭分明的主客体关系、具有明显要求性、强制性特征的检验特征词汇等,使得基本规范性知识较为适合使用规则的方式描述,这种规则类似于逻辑理论中的蕴含式,其前件和后件取自于规范评价本体所界定的相关概念。而在粗粒度层次上,本体中评价条目之间表现出丰富的合取、析取、对等、充分或必要条件、时间序列等内在逻辑性知识关系,这类特殊的本体概念关系可归入非分类关系的扩展。显见,本体概念、概念间的分类关系应用复杂规范文本评价体系和专家经验较容易发现,然而,概念间的非分类关系,尤其是上述的逻辑性关系具有一定的隐性知识特征,难以直接发现,或人工经验判断的代价过高。
另一方面,评价本体本质上是一种任务本体,不同于领域本体,后者在本体学习上使用的数据主要来源于本体特征概念描述的领域相关文档;而评价本体所描述的评价体系相对较为统一、是专业人士智慧和经验的结晶,具有高度的认同性、甚至是唯一性,可挖掘的规范性内容有限,但据此体系产生的大量的评估数据却蕴涵了丰富的评价知识关系资源,因此,对评价任务本体所蕴涵的知识关系挖掘应来源于遵循规范文本的评估结果数据。
4.2 基于双向挖掘和赋权计算的本体关系发现方法
针对上述评价本体的知识特征,本文提出了一种本体关系的自动发现方法,其核心是关联规则挖掘算法。它通过在数据集中不同元素的同时发生频率等统计性信息中发现它们之间的特定的关系规则。市场购物分析的商业决策应用中首先引入了这种数据挖掘技术,可用于分析和预测消费者的购物行为和习惯。
在本文所讨论的上下文中,经典关联规则算法,如Apriori中的交易对应于满足特定评价结果的、基础评价本体所建立的评价条目概念项的数据子集。由于面向规范文本的评价结论首先为布尔型的符合性判断结果,因此适合关联规则挖掘的基本问题描述背景。但由于评价数据结果集的特殊性,如不同的结果都占据一定的比例、不同的结果都具有评价的意义性以及噪声干扰,如符合性结果居多,导致本文的评价本体关系的挖掘场景有所不同,如果直接依照Apriori算法仅对符合性结果数据集进行扫描,将会产生较多的冗余频繁项集,这些项集所涉及的评价项目可能并不是真正存在相关关系,而仅仅因为易满足评价条件而表现为同时出现的频繁性。反之,如果针对不符合结论的评价数据结果集进行挖掘能适度减少冗余问题,但其所产生的评价项目之间的频繁关系不具有反推性,即同样受限于上述的同构性问题。为了解决这一问题,本文设计了基于双向挖掘的本体关系发现方法,将正反挖掘结合起来,以提升本体关系的强度,从而增加结果的准确性和合理性。
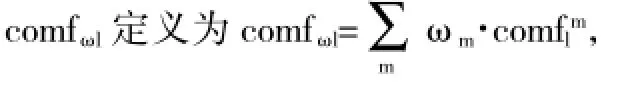
该算法的相关定义和过程描述如下:


正向挖掘的支持度阈值为min_sup1,逆向挖掘的支持度阈值为min_sup2,算法的可信度阈值为min_conf。双向挖掘所获得的频繁项集和强关联规则分别设为Lp和RP(正向)、LNE和RNE(逆向)。双向挖掘的项集可信度权重分别为ω0、ω1。综合获得的关联规则集设为R。
输入:评价数据集E,min_sup1,min_sup2,min_conf,ω0,ω1。
输出:强关联规则,也即本体关系R。
过程(包含部分伪码形式):
*从中抽取候选数据集Ep,则,使其满足,对于每一个候选事务及其对应可评价项目概念来说,都有Eij=1。
*执行关联规则挖掘算法,基于min_sup1、min_conf,获得正向挖掘的Lp和Rp。
*从E中抽取候选数据集ENE,则,使其满足,对于每一个候选事务及其对应可评价项目概念来说,都有Eij=0。
*执行关联规则挖掘算法,基于min_sup2、min_conf,获得逆向挖掘的LNE和RNE。
*For each Rpxin Rp(其中,x=1,2,…,k,k是Rp中的规则数)
For each RNEyin RNE(其中,y=1,2,…,q,q是RNE中的规则数)
针对Rpx计算逆规则Rpx,并在RNE中进行搜索,如果匹配发现Rpx同时也是RNE的子集成员RNEy,那么则将放入综合的关联规则集R中,即将放入规则集中R,即
End For
End For
*For eachin RD(其中,z=1,2,…,n,n是RD中的规则数)
于Lp或LNE中确定所对应的频繁项集,分别取该项集在两个挖掘方向上的可信度,并结合权值ω0、ω1,计算赋权可信度
End For
5 实验和评价
考虑到数据收集的客观性和完整性,本文选取了某测评中心关于防火墙技术的实际评估数据,规范文本取自国家标准《信息安全技术防火墙技术要求和测试评价方法》(GB/T20281-2006)。[11]该文本涵盖了功能、性能、安全、保证不同的侧面,三种安全级别的分类,包括上百项细目评价技术指标和要求。
5.1 防火墙技术标准的基础评价本体及规范关系的推理规则构建
相应于第三部分的基础评价本体构建体系,鉴于顶层评价本体的抽象化特点,本节聚焦于建立面向防火墙技术规范的评价体系框架本体和面向不同防火墙产品的评价内容实例。在领域专家、标准制定者、测评人员的共同推动下,本文建立起防火墙技术评价体系框架本体,其中包括了相关概念及其属性,概念间的分类关系、形如part-of的显性非分类关系以及基于SWRL描述的规则及推理的规范知识。
5.2 基于评估数据的本体关系挖掘实验及评价
本次实验选取了近五年来参与测评的1652款防火墙产品的基于规范文本(GB/T20281-2006)的原始评估数据作为待挖掘数据集。使用4.2节所述的本体关系发现方法对评估数据集进行挖掘,经试验调整,设min_sup1为0.4,min_sup2为0.2,min_conf为0.6。考虑到本体关系中两项关系的典型性,本实验仅对包含两项评价标准条目的可能本体关系进行了实现和记录。双向挖掘所获得的部分规则情况如表1所示。

表1 双向挖掘后所获得的部分规则结果
表1中列出了5组相对的规则形式,依据本文提出的算法,规则5、7、8、9、10为挖掘出的潜在关联结果。其中,规则5位于双向挖掘结果的重叠区域,属于典型的有意义规则。规则7和规则8属于逆向单向强关联规则,经赋权计算的结果超出可信度阈值得以保留;规则9和规则10属于正向单向强关联规则,同样赋权计算后得以保留。相应的本体关系可作领域解释为,负载均衡与DNAT之间存在技术基础关系、支持VRRP和支持STP之间存在功能共性关系,端口支持与协议类型之间存在双向蕴含关系,体现出评价的对等性。显然,这些关系通过预先定义或推理的方式都很难获取。由规则结果,结合领域专家的关系类型归属解释,所获取的部分本体关系概括如表2所示,其中概念名称为5.1节基础评价本体所定义的元评价标准条目的原始描述简称。
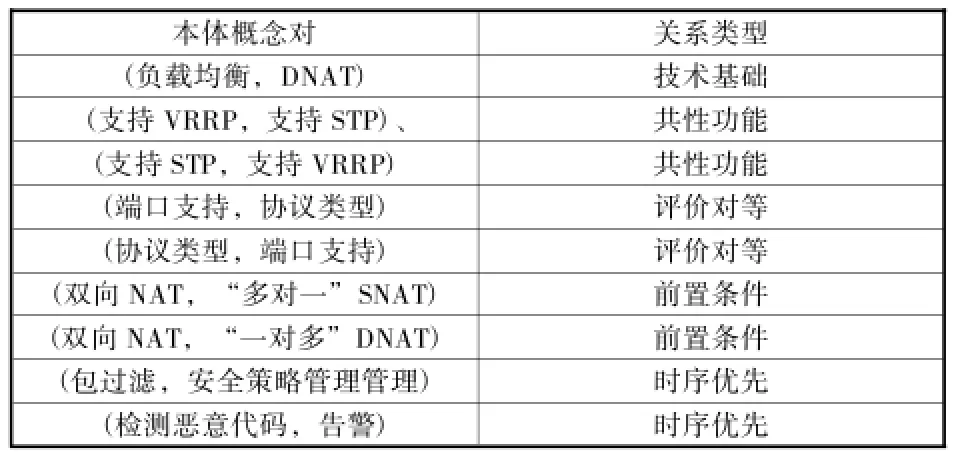
表2 获取的部分本体关系
由于缺乏标准的对比参照,本实验以专家评判为基准,将本文提出的评价本体知识关系的发现方法、与仅实施正向或逆向挖掘的结果进行对比性分析,以评估本文提出方法的效果。考虑到获取完整的本体关系较为困难,本文主要就方法效果的查准率分别与单次单向挖掘进行了计算和比较,如表3所示。

表3 与单次单向挖掘的关系数和查准率比较
从表2中可以看出,正向挖掘结果的查准率相对较低(79.17%),可见由于符合性评价结果居多,使得针对正面评价数据集的抽取产生了较多的冗余。逆向挖掘由于相对冗余度较小,查准率达到了87.80%。经双向挖掘和赋权计算处理后,本文提出的本体关系挖掘算法的规则集结果的正确关系数和查准率分别提升到了41条和91.11%,验证了本方法能够有效地改进单次抽取的准确性。
6 结论
当前本体构建主要聚焦于领域本体,而任务本体由于可能存在复杂的目标对象、处理流程和特定表示关系等也不应被忽视。本文首先面向复杂规范文本和评价流程建立起由三层结构构成的基础评价本体,形成本体概念、分类关系和规则定义的框架,继而针对评价本体蕴含隐性非分类关系的特征,提出基于双向挖掘和赋权技术的方法实现对这种特定关系的自动发现,并通过针对评价实例数据的实验及对比评估验证了该方法的有效性,从而丰富和完善了前期形成的评价本体。同时,本文提出的面向评价任务本体的构建方法,能够适用于不同规范指导下的评价活动,具有一定的普适性。未来的发展方向可考虑由两项评价条目关系扩展到多项,并囊括更多的实验性能评估的着力点,同时可以将评价本体与相关领域知识及领域本体结合起来,研究相互推动的构建或完善的方法。
[1]Zhong B T,et al.Ontology-based semantic modeling ofregulationconstraintforautomatedconstructionquality compliancechecking[J].AutomationinConstrution,2012(28):58-70.
[2]Nash E,et al.Towards automated compliance checking based on a formal representation of agricultural production standards[J].Computers and Electronics in Agriculture,2011(78):28-37.
[3]Gábor A,et al.Compliance Check in Semantic Business Process Management[C]//OTM 2013 Workshops. SpringerBerlinHeidelberg,2013:353-362.
[4]GongP.Compliance checkingforsemanticallyannotatedprocess model[J].International Journal of Digital Content Technology and its Applications(JDCTA),2012,6(21):670-679.
[5]Ekelhart A,et al.Ontological Mapping of Common Criteria’s SecurityAssuranceRequirements[C]//Proceedings of the IFIP TC-11 22nd International InformationSecurityConference.Boston:SpringerUS,2007: 85-95.
[6]Wong M K,et al.A multi-phase correlation search framework for mining non-taxonomic relations from unstructured text[J].Knowledge and Information Systems,2014,38(3):641-667.
[7]Villaverde J,etal.Supporting thediscovery andlabeling of non-taxonomic relationships in ontology learning[J].Expert Systems with Applications,2009,36(7):10288-10294.
[8]刘萍,胡月红.基于FCA和关联规则的情报学本体构建[J].现代图书情报技术,2012,216(2): 34-40.
[9]谷俊,等.基于改进关联规则的本体关系获取研究[J].情报理论与实践,2011,34(12):121-125.
[10]刘巍,等.利用转化SKOS和关联规则挖掘创建本体及其检索应用[J].现代图书情报技术,2013,235/236(7/8):22-27.
[11]中国国家标准化管理委员会.GB/T 20281-2006信息安全技术防火墙技术要求和测试评价方法[S].北京:中国标准出版社,2006.
G254.29
A
1005-8214(2015)11-0053-05
顾铁军(1978-),女,东华大学副教授,研究方向:信息管理、知识组织与传播;李毅(1978-),男,公安部第三研究所副研究员,研究方向:网络安全与测评。
2015-05-27[责任编辑]王岗
本文系教育部人文社会科学研究青年基金项目“质量评价领域中复杂指标体系的本体化建模与实证支持平台研究”(项目编号:12YJCZH059)的研究成果之一。
