基于工作流的科学数据分析系统*
2015-11-04李宏源贵州大学计算机科学与技术学院贵州贵阳550025贵州省先进计算与医疗信息服务工程实验室贵州贵阳550025
李宏源,陈 梅,李 晖(1.贵州大学 计算机科学与技术学院,贵州 贵阳 550025;2.贵州省先进计算与医疗信息服务工程实验室,贵州 贵阳 550025)
基于工作流的科学数据分析系统*
李宏源1,2,陈梅1,2,李晖1,2
(1.贵州大学计算机科学与技术学院,贵州贵阳550025;2.贵州省先进计算与医疗信息服务工程实验室,贵州贵阳550025)
随着科技的发展,科学领域的研究人员在观察和实验中产生的数据规模越来越大,科学分析任务也愈加复杂。新型的阵列数据库和工作流技术逐渐被应用到大规模科学数据的管理和分析中。结合阵列数据库系统SciDB,研究并实现了一种基于工作流的科学数据分析系统,用于满足基于大规模数据的复杂科学数据分析需求。
SciDB;工作流;科学工作流;科学数据分析;科学大数据
0 引言
近年来,随着科学观测工具和科学实验操作仪器的不断改进以及科学观测手段的不断进步,很多科学研究领域,尤其是一些基础学科领域,例如高能物理学、生物信息学、大气科学、天文学等,在实验过程中和实验后产生的可以用来分析的实验数据越来越多,其数据量越来越大;同时,科学过程也越来越完善,这意味着它变得越来越复杂,包含在其中的科学计算过程往往由成千上万个步骤构成。综上,目前的科学分析甚至是一个简单的科学实验都需要对TB甚至PB量级的数据进行分析查询,才能够对整个科学工程进行进一步的分析,从而找出规律,得出结论。因而,将大数据查询的处理方法应用到科学大数据,并将其做成一种简单、易上手的服务,对于提高科研人员的工作效率具有显著的作用。同时,科学过程产生的是数据,其运行的过程本身是由数据驱动的,对于科学领域学者来说,数据是最重要的,科学数据是数据密集型的。
采用工作流技术可以将复杂查询进行拆分,实现查询的可视化和动态修改,使得科学分析服务简单、易上手。但是由于科学分析其以数据作为驱动的特点,目前不能将传统的工作流系统,即目前应用在企业领域的BPM(Business Process Management),例如JBPM和Activiti直接应用于科学领域,因而采用科学工作流系统。
在国外,Kepler科学工作流系作为一种科学分析的手段,已经开始应用于医学数据分析领域和环境监测数据分析领域,但是Kepler本身只是一个工作流执行引擎,其所分析的科学过程中的每一个步骤经常采用Hadoop作为分析的工具,而Hadoop执行科学分析的效率不高,尤其在其所分析的科学数据的维度较大的情况下。同时,以SciDB作为科学分析工具的查询服务在国外目前还处于起步阶段。针对于Kepler,其所提供的可视化编辑是在软件界面上实现的,将之应用于网页形式还是比较困难的。
在国内,基于数据驱动的科学数据处理的科学工作流系统的研究还处于起步阶段,很多学者都只是提出了一个简单的仅仅应用于一项甚至几项相类似的科学研究的科学工作流框架,针对这些框架的实现较少,同时,这些框架基本上是基于关系型数据库设计的,对于数组数据库来说,不具有较好的数据可扩展性。
1 科学数据库系统SciDB
随着科学学科领域观测手段的不断进步,在很多科学领域产生的数据都开始呈现出爆炸性增长的趋势。为了满足针对这些数据的多种多样的复杂分析操作,基于数组模型的数据管理和分析成为了科学数据管理和分析的趋势。传统的数组管理和分析软件如MATLAB的基本思想是在主存中处理可以放在内存中的少量数据,但是对于海量数据的处理比较困难。同时,对于科学家来说,使用传统的关系型数据库如SQLServer、Mysql、Oracle等来存储和分析数组类型数据的过程过于复杂且低效,这是因为传统的关系型数据库是基于关系数据模型来分析数据的,本身没有针对数组类型科学数据的存储和分析进行优化。进一步说,传统关系型数据库的扩展能力也制约着它们的海量科学数据处理能力[1-2]。
为了解决上述问题,以STONEBRAKER M为首的数据库专家在收集并且深入探究了当前领域学者对于科学数据的分析需求的基础上,在列存储的基础上,结合科学研究所产生数据的结构特点,在Paradigm4公司的赞助下研发了一套科学数据管理和分析的系统软件,其社区免费版本名为SciDB[3]。
SciDB不同于传统的关系数据库软件,它侧重于科学数据的分析操作,设计目标是与R、MATLAB以及IDL等科学分析软件结合来分析管理科学数据。
SciDB是一个开源的数据管理系统,主要为科学领域中的超大规模阵列数据而设计,其设计初衷旨在解决科学研究中数据量大、数据世袭等科学问题。与传统DBMS不同的是,SciDB能够为科学应用领域提供大规模的复杂分析支持,用以满足其日益增长的需求。它采用阵列数据模型(一种具有数学中数组特性的数据模型),支持多维数据。其基本组成单元是cell,各个cell有相同的值类型。cell的值可以是一个或多个标量值,也可以是一个或多个数组。
SciDB的基本架构如图1所示。在SciDB集群中有两种类型的节点:Coordinate节点参与查询执行并且协调查询行为;Worker节点是直接参与查询执行的节点,查询后的结果会传输到Coordinate节点上输出。在SciDB集群中,使用Postgresql数据库(Postgresql数据库,PG)作为集群元数据的存储。
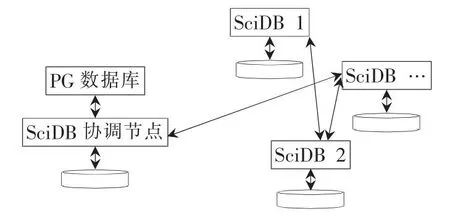
图1 SciDB架构图
SciDB具有如下特性:
(1)SciDB事物的作用领域是一条SQL语句。每一条语句都涉及针对一个或者多个数组的很多操作。最后,事务结束后得到的结果存储到目的数组中。
(2)SciDB实现了数组级锁。在事务一开始,锁就被获取,该锁在查询执行中一直处于活跃状态。数组锁在查询执行之后被释放。如果取消了某个查询,该查询所涉及的数组的相应操作在所有节点上都被取消,从而使得数据库可以返回到初始状态。
(3)SciDB支持追加操作。它使用不覆盖存储机制,每一次更新现有的数组中的数据,SciDB都会创建一个新的数组版本。这意味着如果往现有的数组中插入一系列的新数据,这些数据以及数组中原有的数据必须全部重新分布到SciDB节点中。如果数据量比较大,上述过程会花费额外的大量时间。
2 科学工作流及其代表Kepler系统
工作流(Workflow),指业务过程的部分或整体在计算机应用环境下的自动化,是对工作流程及其各操作步骤之间业务规则的抽象、概括描述。
工作流管理联盟(WfMC)对工作流的定义为:一类能够完全或者部分自动执行的经营过程,根据一系列过程规则、文档、信息或任务能够在不同的执行者之间传递、执行。
工作流其实是一个直接有向图,它的执行是有序的,目前一般将工作流的执行信息存储在扩展标记语言(eXtensible Markup Language,XML)文档中[4]。
与传统的工作流不同,科学工作流是以数据作为驱动的,它也是由一系列的小的工作流程组成的,但是制约整个工作流程执行的不仅仅是顺序,同时还与数据有关,假如整个工作流程没有需要的数据,该工作流便不能执行;相反,假如存在数据,则整个工作流程可以重复执行,这意味着科学工作流的执行逻辑与传统的工作流有些不同。同时,以SciDB作为科学分析的执行引擎,这意味着需要针对SciDB单独设计工作流执行逻辑[5-7]。总体来说,科学工作流是获取科学数据,并对所获取到的数据执行复杂分析的灵活的工具。
Kepler[8]主要面向科学家、分析专家以及计算机程序员,提供了一系列可以通用的科学分析框架。它可以操作不同格式、不同地区、不同介质中的数据,同时提供了一系列可以扩展的接口用于扩展R或C语言用户。Kepler的图形界面允许用户使用拖拽的形式来创建一个工作流,此时的工作流即以数据为驱动的科学工作流。
Kepler是一个以Java作为主要开发语言的软件,这意味着Kepler的api可以具有很好的跨平台特性。一个简单的Kepler工作流如图2所示。
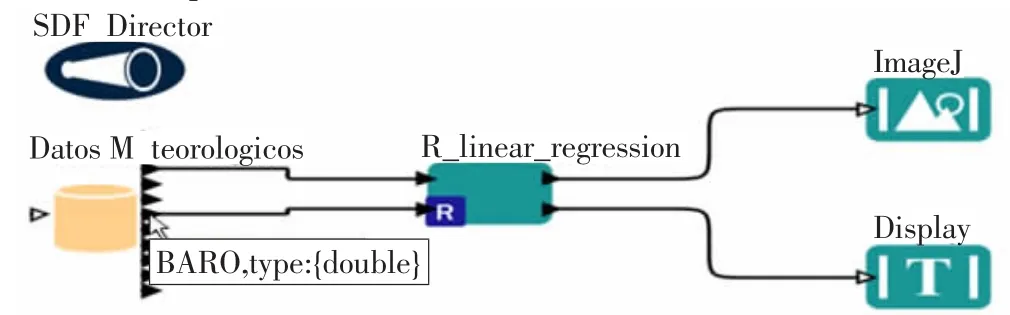
图2 一个简单的Kepler工作流
其中,SDF Director是流程控制器,Display是不同的actor组件,其功能类似于JBPM中的Process。
3 基于工作流的科学数据分析系统
本文提出的基于工作流的科学数据分析系统是云平台上工作流作为服务(Workflow As a Service,WAS)系统的一部分,WAS架构图如图3所示。
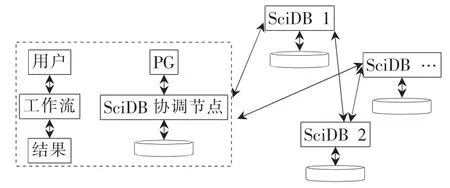
图3 WAS系统架构图
WAS系统分为两个主要的部分,即应用部分和SciDB集群系统部分。
应用部分是基于集群系统部分构建的,目前主要由本文中提到的科学数据分析系统、WAS系统用户管理、WAS系统用户资源管理以及WAS系统负载均衡部分组成。针对第1节中提到的SciDB系统的相关特性,科学数据分析系统做了相应的处理。WAS系统用户管理、WAS系统用户资源管理以及WAS系统负载均衡部分目前还只是处于初步阶段,管理的用户是WAS系统的全部用户,这部分相应的数据是存储在关系型数据库之中的,而且只有系统管理员才有相应的管理和查看权限,实现了一定的数据保密性。
集群部分是基于SciDB构建的分布式集群,相比关系型数据库以及传统的MATLAB等数据分析工具,该分布式集群具有较好的科学数据分析功能。
用户登录到WAS后,可以通过工作流系统执行科学分析,并查看科学分析的执行结果,并且可以同时从界面中导出。WAS系统同时实现了负载均衡和用户使用过程中系统资源利用率的实时监控。本文中的工作流系统是图3中的工作流中的一部分,这部分系统的架构图如图4所示。
该工作流系统由两个部分组成,即Web客户端界面以及工作流执行引擎。
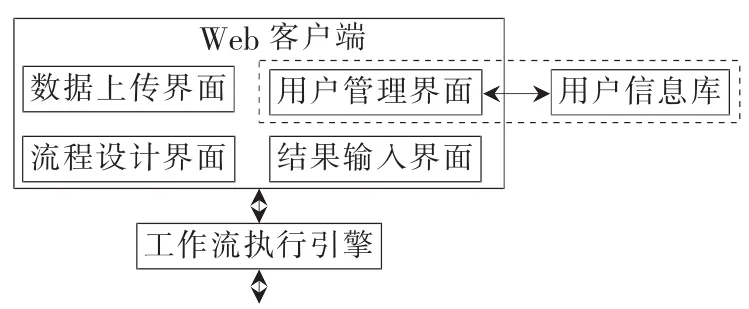
图4 科学分析系统架构图
在Web客户端界面中,用户通过用户管理界面与用户信息库之间的接口查看本账户中已经执行的科学工作流的执行情况以及执行过程中的资源占用率(如CPU占用率、主存的占用率、主存的占有量、磁盘的读写以及本帐户所使用的集群的网络数据传输速率)。其中的用户管理与WAS系统的用户管理不同。
而数据上传界面、流程设计界面以及结果输入界面都是通过接口与工作流执行引擎交互的。用户通过数据上传界面将上传文件的相关信息发给工作流执行引擎,之后,工作流执行引擎通过接口与SciDB集群通信,并将数据文件加载到SciDB数据库中,再将加载后状态信息返回给用户。流程设计界面是一个Web版的流程设计器,用户通过拖拽可以设计一个科学工作流,最后保存为XML文件交给工作流执行引擎处理。结果输入界面显示出分析结果。一个简单的科学工作流如图5所示。其中,左边的圆点代表科学分析任务开始,右边圆点代表科学分析任务结束,task1代表一个简单的科学分析过程。当然,复杂的科学分析过程是由一系列的图中的基本的科学分析子过程组成的。
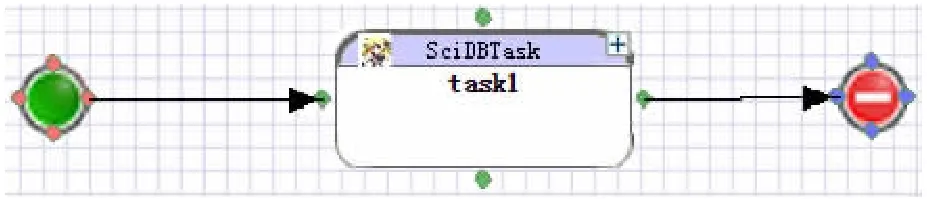
图5 一个简单的科学工作流
本文中提出的科学分析系统的执行过程如下:
(1)工作流引擎在启动后进行初始化,加载afl.properties文件,该文件中有SciDB的AFL函数相关信息。这部分信息可以用于在工作流执行过程中的检测。
(2)该系统的用户在流程设计界面使用拖拽的方式拖拽基本组件,并连接这些组件组成类似于图5的工作流。执行这个工作流可以完成用户需要的科学分析操作。用户通过点击保存按钮将该工作流保存到XML和数据库中。
(3)解析XML文件,并执行该工作流完成用户需要的科学分析操作。这部分操作的流程图如图6所示。
(4)用户可以分别在结果输入界面和用户管理界面查看最终结果及系统执行分析操作过程中的一系列系统参数变化情况。
以SciDB作为科学分析执行引擎,其本质上是针对SQL语句或类SQL语句的处理。
4 结论
本文设计并实现了一个基于工作流的科学数据分析系统,该系统是基于SciDB独立设计的执行逻辑科学分析工作,具有较好的可扩展性和可复用性,适用于科学数据分析,同时该系统与Kepler不同,该系统允许用户在Web端使用。
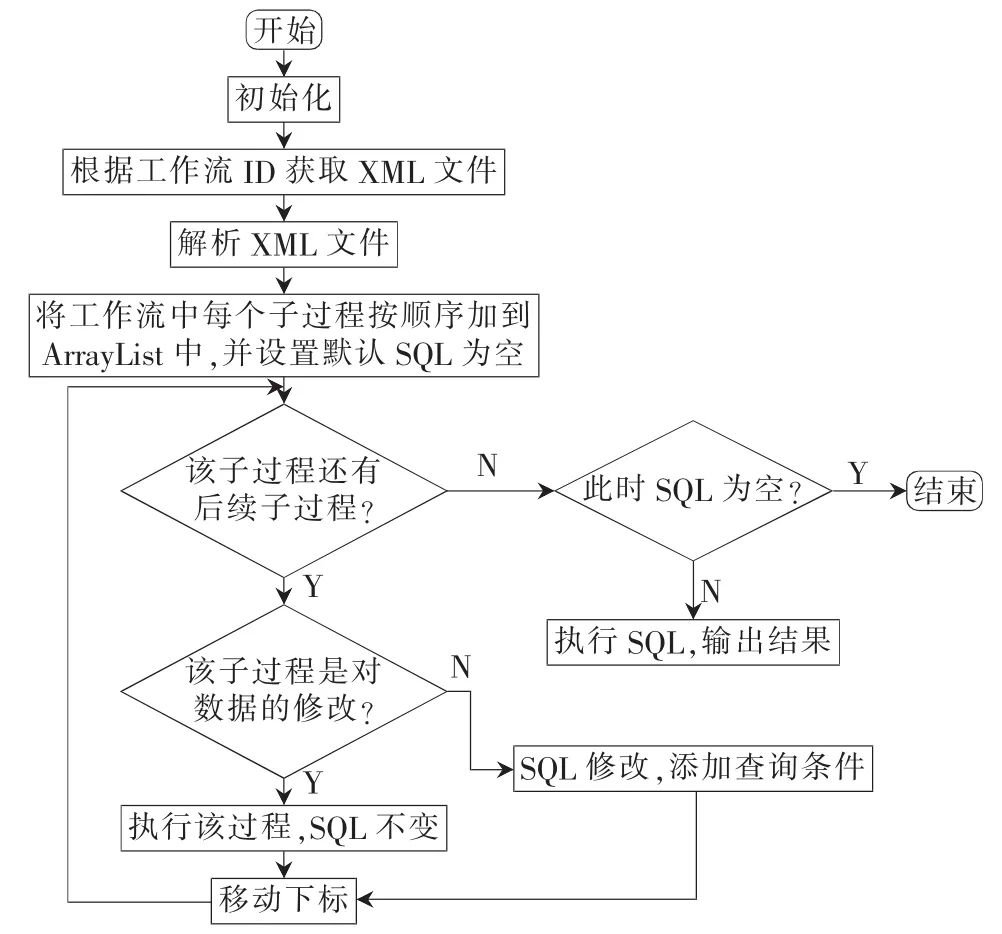
图6 执行引擎操作流程图
[1]DOBOS L,SZALAY A,BLAKELEY J,et al.Array requirements for scientific applications and an implementation for Microsoft SQL Server[EB/OL].(2011-10-11)[2015-03-01].www.docin.com/p-379013760.html.
[2]WIDMANN N,BAUMANN P.Efficient execution of operations in a DBMS for multidimensional arrays[C].Proceedings of SSDBM′98,Capri,Italy,1998,7:155-165.
[3]THAKAR A R,SZALAY A S,KUNSZT P Z,et al.Migrating a multiterabyte archive from objectto relational databases[J].Computing in Science&Engineering,2003:16-29.
[4]罗海滨,范玉顺,吴澄.工作流技术综述[J].软件学报,2000,11(7):899-907.
[5]肖飞,张为华,王东辉.面向科学过程的工作流技术研究现状与趋势[J].计算机应用研究,2011,28(11):4013-4019.
[6]张卫民,刘灿灿,骆志刚.科学工作流技术研究综述[J].国防科技大学学报,2011,33(3):56-65.
[7]宋琳琳.E-Science发展情况简介[J].图书馆学研究,2005(7):21-23.
[8]Wang Jianwu,CRAWL D,ALTINTAS I.Kepler+hadoop:a general architecture facilitating data-intensive applications in scientific workflow systems[C].Proceedings of the Fourth Workshop on Workflows in Support of Large-Scale Science(WORKS09)at Supercomputing 2009(SC2009)Conference,ACM 2009.
Workflow-based scientific data analysis system
Li Hongyuan1,2,Chen Mei1,2,Li Hui1,2
(1.College of Computer Science and Technology,Guizhou University,Guiyang 550025,China;2.Guizhou Engineering Laboratory for Advanced Computing and Medical Information Services,Guiyang 550025,China)
With the development of scientific technology,the data generated during scientific observations and experiments becomes huge.In order to facilitate the massive scientific data management and analysis,array database system and workflow are often combined in corresponding areas.In this paper,we study the critical issues and focus on describing how to design the scientific data analysis system by combining array database system SciDB with workflow techniques.
SciDB;workflow;scientific workflow;scientific data analysis;big data
TP319
A
1674-7720(2015)10-0016-04
2015-03-06)
李宏源(1987-),男,硕士研究生,主要研究方向:分布式数据库、工作流。
陈梅(1964-),女,教授,主要研究方向:数据库新技术、应用系统开发。
李晖(1982-),通信作者,男,博士,副教授,主要研究方向:大规模数据管理与分析,高性能数据库,云计算。E-mail:cse.HuiLi@gzu.edu.cn。
国家自然科学基金(61462012);贵州省应用基础研究重大项目子课题(黔科合JZ字[2014]2001-05);贵州大学研究生创新基金(研理工2014010)
