维吾尔语韵律调节研究∗
2015-11-02努尔买买提尤鲁瓦斯吾守尔斯拉木
宋 洋,努尔买买提尤鲁瓦斯,吾守尔斯拉木
(新疆大学 信息科学与工程学院,新疆 乌鲁木齐830046)
0 引言
语音韵律(Rhythmic Voice)具有三个特征参数,即音高、音长和音强[1].三者在全句中随着发音过程动态变化形成动态的超音段特征(Super Segmental Feature).语音合成的自然度与语音信号上述的韵律特征有着直接的关系.新疆大学语音实验室对维吾尔语音合成技术进行了长期的研究,首先是以语料库为基础的波形拼接技术[2],其显著特征是依赖于大容量的波形存储,但是可以得到较优的音质;其后的开发以语音特征参数为基础的建模技术[3,4],其不足是缺乏自然度,基于HMM可训练的语音合成技术是这一阶段的代表成果.现阶段的维吾尔语音合成技术的重点是语音的自然度和韵律.与中文语音韵律的合成相比较,维吾尔语韵律调节[5]的关键之处在于对韵律特征的有效调节并结合维吾尔语自身的特点恰当的加入重音、停顿等独特语言现象.本文从这三个方面着手,对维吾尔语的韵律进行调节,首先应用ANN对维吾尔语句中的停顿做预判,ANN构建的依据是维吾尔文的词性和句法;接下来应用维吾尔语的重音规则,将Fujisaki模型应用在单词的层面上,得以准确的调节重音音节的位置;最后对LPC(线性预测倒谱)作改进,得到LPCAP(LPC with Adjusting Parameters),调节基音频率曲线形成多种情感语调.
1 维吾尔语音韵律特征
汉语的韵律可以通过对音高、音长、音强等韵律特征来调节.汉语中有多音字的现象,即同一个字会有多个发音,不同的发音将表示不同的含义.所以,汉语对声调的控制要求更精确[6],包括词声调、短语声调、句声调都要综合考虑.同样对于维吾尔语来说,维吾尔文的单词需要合适的重音、停顿.在维吾尔语中,重音发生在单词的音节中,其中有些词在出现重音时改变了原来的词义,对这一部分的词汇收集整理了21个,并制成“重音异义词本”.维吾尔语的重音规则相对简单,多音节的单词重音出现在最后一个音节上,如果单词添加了后缀,重音的位置要相应后移,使得重音产生在最后一个音节.停顿有单词内部的停顿、单词间的停顿,停顿出现的位置需要训练数据进行特征学习,而且两种停顿的时长也存在着明显的差异,单词内部音节间的停顿时长小于单词间的停顿,而且大部分情况下出现在重音音节前部.再者,描述全句基频曲线的特征可以表达出自然的语句韵律.
2 韵律调节实现
2.1 韵律标注
标注是研究工作的基础部分,后续的工作都要以标注的内容为依据.本文对标注的操作有所不同,主要分为五层标注,分别是音素层(ph)、音节层(sy)、词性层(cx)、语法层(gr)、词域层(ciyu)、重音层(tn)和两种停顿标记词内停顿(silw)及词间停顿(sils).经过标注得到的是TextGrid格型文件,为了便于后续的操作,本文编制了预处理的程序,用来读取不同层次的标注内容,并存储为TXT格式的文件.
2.2 ANN预判停顿
人工神经网络(ANN,Artificial Neural Networks)[7−9]是人工智能学科中对人类智能的信息化描述方法.利用大脑对信息的概括、特征的提取、知识的学习等特点去解决传统方法所不能解决的问题.
本文利用ANN的特点对维吾尔语音的停顿进行建模.采用含有隐含层的前馈网络的架构4—N—1(即输入层有4个节点,有N个隐层,输出层有1个节点),网络的构成要充分考虑数据的处理与分类,表1显示出在隐含层不同结构的情况下,对ANN性能的影响.

表1 ANN隐层节点数目与层数对网络性能的影响
以输入层的4个节点为例,其主要功能就是要接收输入维度为4的停顿上下文环境向量,以句子(bvgvn qiraying anqa yahxi amas turidu)为例,对每一个词间隔处做停顿预判计算,如在qiraying和anqa间存在停顿,为该间隔建立上下文环境向量如表2,各语法成分的特征取值在表3中给出.经过ANN网络的计算预判,在输出层的节点给出停顿与否的数据,本例中的输出是0.518即判断出现停顿.

表2 停顿上下文环境

表3 词性分量取值

表4 成分环境值
本文中的ANN要结合数据准备中的标注数据,以词性,语法成分作为构建网络的依据.以名词词性的维吾尔语单词为例,根据维吾尔文语法规则,可以将其作为句子中的主语、宾语、定语、补语等成分,而且在复合句中也可以作相同的句子成分,在不同的场合下都可能产生停顿现象.要以语料标注为基础,尽可能让实验数据覆盖全面的情况.ANN的停顿预判过程可以由图1描述.
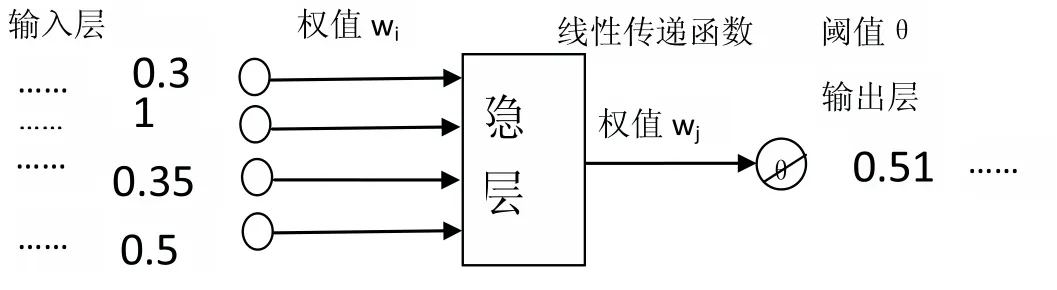
图1 停顿预判过程
对于ANN隐含层的神经元的节点数目和隐含层的层数的增加虽然会提高计算预判的准确度,但同时也会增加计算的复杂度,需要的迭代次数与计算时间复杂度也将增加.试验中训练过程的参数调节方式采用共轭梯度法,参数优化的原理如式(1),求得每一次优化的搜索步长λ.

应用共轭梯度法[10]对搜索方向d的确定方式采用传统的方式,即在达到n次迭代后重新按照初始起点的负梯度方向进行搜索d=−�f(x),否则计算方向因子β,修正搜索的方向为d=−f(xj+1)+β×dj.方向因子的确定可以参考(2)式.这样可以在训练结果不收敛时重新调整搜索方向,与有着“锯齿”现象的最速下降法,与对初始节点选取较为依赖的牛顿法相比,共轭梯度法使得计算向最优值收敛速度较快.

需要进一步说明的是停顿在单词的音节内部和单词间都存在的情况,在单词音节中的停顿必然会小于单词间的停顿,两种停顿的时长经过对单词的标注分析,计算得到两种停顿的时长均值分别为0.06s,0.11s.
2.3 重音调节
Fujisaki模型[11]对基频曲线的刻画原理是在基频曲线的基准值Fb之上,再次叠加上音节调节命令Gp(t)和短语调节命令Gt(t),以此实现在局部和全局的范围内调整基音频率曲线的走势,这种方法就好似在合唱时,多个高低音声部的共同协作一般,其数学的描述形式如式(3).
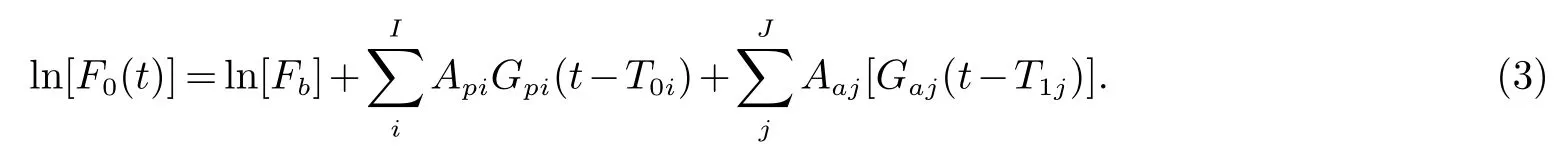
式(3)中,I为短语命令数目,J为音节命令数目,Api为短语命令的幅度,Aaj为音节命令的幅度,T0i为短语命令的时间,T1j为音节命令的时间,Gpi,Gaj分别为短语命令、音节命令的脉冲响应.
本文将Fujisaki模型应用在单词的音节层面上,应用于重音位置的准确调节.省略Fujisaki中的短语命令,只应用音节命令在音节处调节重音强弱的增、减,同时为了提高重音调节的准确度,还要结合维吾尔文的词法规则,提出在单词语义的相关性做计算.本文总结了维吾尔文中常用的“重音异义词本”,其中包括21个维吾尔文单词,它们的特点是在重音移位后改变了原来的词义,甚至是词性,但是词型却不变.为了解决这个问题,在处理重音时首先将单词与“重音异义词本”进行查找,“潜在的重音异义词”与前后词表示成向量的形式(词性,成分,词域),计算重音出现与否两种不同情况的关联性,即计算两个向量间的夹角余弦值cosφ.当关联性接近时,cosφ靠近1,反之则向0靠近.接下来,按照维吾尔文重音规则在单词中添加重音,多音节单词的重音一般出现在最后一个音节上,如果单词加了各种后缀时,重音将随之后调使得最后一个音节出现重读.调整Fujisaki模型如式(4).
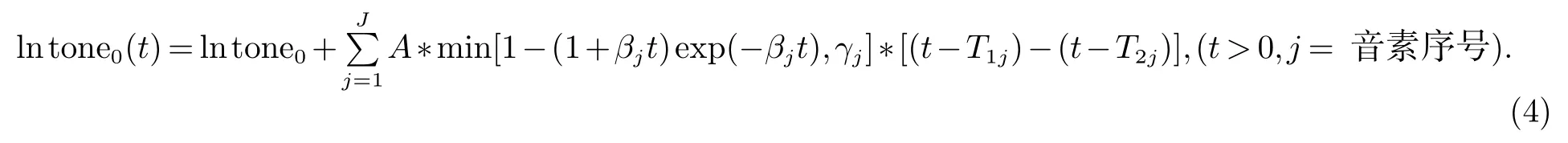
Fujisaki模型的参数β值按照重音分布曲线的升降的平均斜率;γ的计算是重音峰值与平稳处振幅的比值.应用均方误差最小化为目标优化参数,参数的优化过程采用共轭梯度算法,如式(5)、(6)、(7),得到参数A,F.

词域的设置是根据《中图分类法》做选取和修改,表5将部分词域摘取做说明.摘取部分是《中图分类法》中D类政治中的几个子项,类作整数位,子项作小数位.如果将词域划分得太细化,不易于对计算结果的分类,所以每个类中的子项设20个.

表5 部分词域分量取值
2.4 基音频率曲线的调节
实验中录制了兴奋、愤怒、悲伤三种情感特征的语音语料,通过线性预测误差的倒谱法[12]检测语音语料的基音频率.一方面,线性预测方法利用过去若干个采样值的线性组合来估算下一帧的抽样值,将实际语音的抽样值与线性预测抽样值的均方误差最小化,来唯一的确定一组线性预测系数.另一方面,倒谱是在语音的频域中对音频参数进行估计,这样的好处是可以进一步采用Mel(梅尔)频率,基于人的听觉机理来分析语音的频谱特征,以此得到精确的语音基频特性.通过对基音频率的检测,可以清楚地观察到不同情感下,同样的语句(bvgvn qiraying anqa yahxi amas turidu)其基频曲线的走势有着明显的差异[13,14],如下图2所示.

图2 不同情感韵律下的基音频率曲线
在图2中可以观察出悲伤的韵律特征是基音周期的延长、声音的音调降低,反映在子图d中所显示的效果是基因频率的间断明显,整体的基因频率的值域下调;对于兴奋的韵律,可以看出语速的加快,语音的音调域与常态语音接近,反映在子图c中所显示的效果是基音频率曲线的连贯性增加,并维持音调;愤怒的韵律明显的特征就是整体的音调的提高、基音频率曲线的间断增多,反映在子图b的效果是基频曲线的连续性下降、基频曲线整体上升.
本文提出基音频率曲线调节方法LPCAP(LPC with Adjusting Parameters),对原有的LPC[15](Linear Predict Cepstrum)引入幅度调节系数A,和基频调节系数F,两者对基音频率曲线的幅度和连续性进行调节,LPCAP算法可由图3描述.实验中应用LPC方法分别提取100组人工录制的语音资源的基频曲线,每组数据含有同一语句的三种情感陈述式语句与无情感陈述式语句.
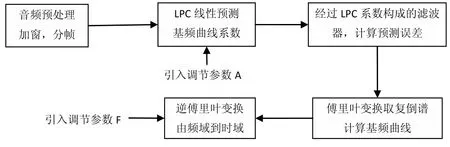
图3 LPCAP描述
LPCAP的特点是将可靠的参数提取的过程改进为参数转换的过程,与Fujisaki在全句范围上描述基音频率曲线的方法相比,减少了大量的计算,而且可控制性得到提高.
3 实验与分析
3.1 实验准备
试验中采用的维吾尔语语料全部是应用Cool Edit Pro进行录制,格式选择为Windows PCM(WAV)格式,单声道,采样频率16000Hz.陈述式情感音频100组,每组包含同一语句的兴奋、悲伤、愤怒、无情感四种表述,共计400句.另外录制无情感陈述式音频300句,共计700句人工录制音频.实验语料库中录制的语句都是陈述式复合句,词汇量平均在20个单词左右,单词至少含有一个音节,所以可以计算的停顿数据约为11400个,可以计算的重音数据可以达到20000个.其中600个音频作为训练数据,另取100个陈述式音频作为开放式测试数据.在音频文件中剪切出单音节单词,多音节单词共计1000个,用于单词重音实验.在录制完成后,应用Cool Edit Pro对音频进行简单预处理,剪切掉音频中过长的前静音和后静音部分,这是由于录制时操作不当引起的冗余.准备的数据还包括整理得到的重音异义词本,其中包含45个重音较为特殊的常用维吾尔文单词,和一个参考《中图分类法》概括的词域分类本.接下来对音频文件做标注,首先采用自动标注的方式,但是存在偏差,需要人工调整,共计得到标注文件1100个,标注的效果如下图4所示,例句:今天你的脸色不好(译文).
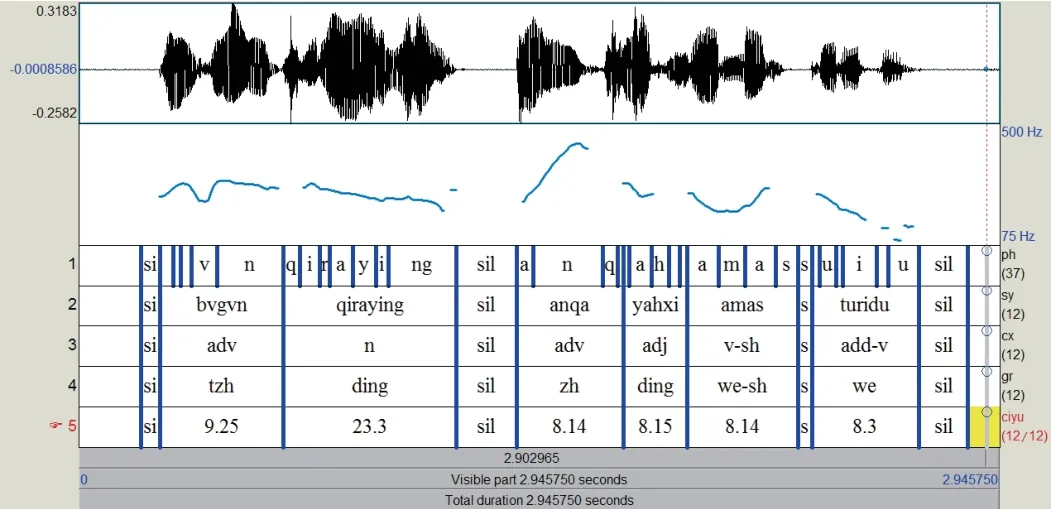
图4 六层标注效果
3.2 实验结果分析
3.2.1 ANN停顿预判实验分析
试验中对ANN中隐含层节点数目,隐含层数目两个方面进行了考虑,选取了不同层次、不同神经元节点数目对网络性能的影响做了比较,相关结果如下图5所示.试验中根据实验数据的标注文件,将句中词间隔的上下文环境向量作为输入,经过ANN做出停顿的预判结果,判断的过程由图1所描述,结果的准确检验依据标注,对50句测试数据的预判准确度可以达到71.2%.

图5 异构ANN预判准确度
从图5中可以看到不同ANN隐含层结构得到的测试结果,当隐含层数目确定时,隐含层神经元的数目对ANN的影响体现在y坐标方向;当隐含层神经元数目确定时,隐含层数目对ANN的影响反映在x坐标方向.其中,具有1隐含层,隐含层分布10节点时,得到了较为理想的准确度.试验中构建ANN网络的依据是维吾尔文的词性与语法成分间的关联,各种情况下的关联度会在一定的训练数据量下达到收敛,所以节点数目和隐含层的数目对ANN网络的性能都产生影响.具体情况按照ANN网络的架构方式不同,或依据的语法规则的扩充与缩减对结果都会产生影响.
图6是对音频数据经过ANN计算预判后加入停顿调节效果,实验中静音语段使用的是白噪声余弦信号并用低信噪比的滤波器滤波,频率取值为采样频率.
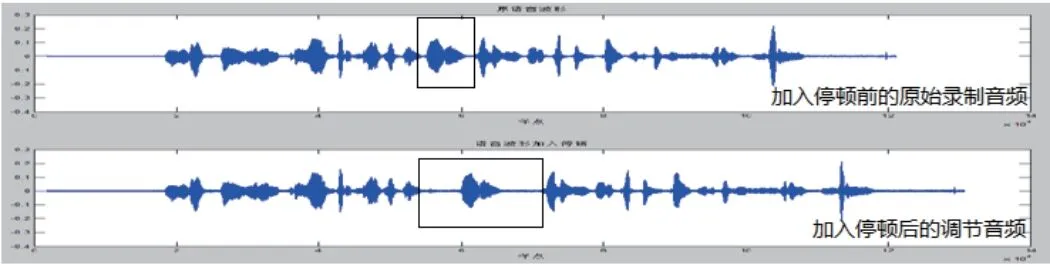
图6 语音加入停顿效果
3.2.2 重音调节实验分析
试验中统计1000个维吾尔文单词的音节振幅能量,利用praat工具中Intensity命令提取的录制单词音频中的声音强度曲线,其中C表示辅音,V表示元音,表6描述的曲线作为单词重音的基础强弱曲线strb.可以看出重音出现的位置较为固定,一般出现在后端元音音节中.

表6 音节的音强分布
Fujisaki模型中的β,λ是调节全句基频曲线的常量,当Fujisaki模型应用在单词音节层面上的重音强弱走势曲线时,参数需要调整.计算实验数据中单词的重音曲线的升、降平均斜率,和重音与平稳的振幅比值,得到表7的数据.
取100个单词做测试,根据音节类型确定strb音节命令调节个别音节,结合重音异义词本计算重音异义的关联性,最后确定重音发生位置,调节结果依据标注文件,重音调节的准确度可以达到86.7%,加入重音的调节效果由图7所示.

表7 Fujisaki描述重音下的参数调整
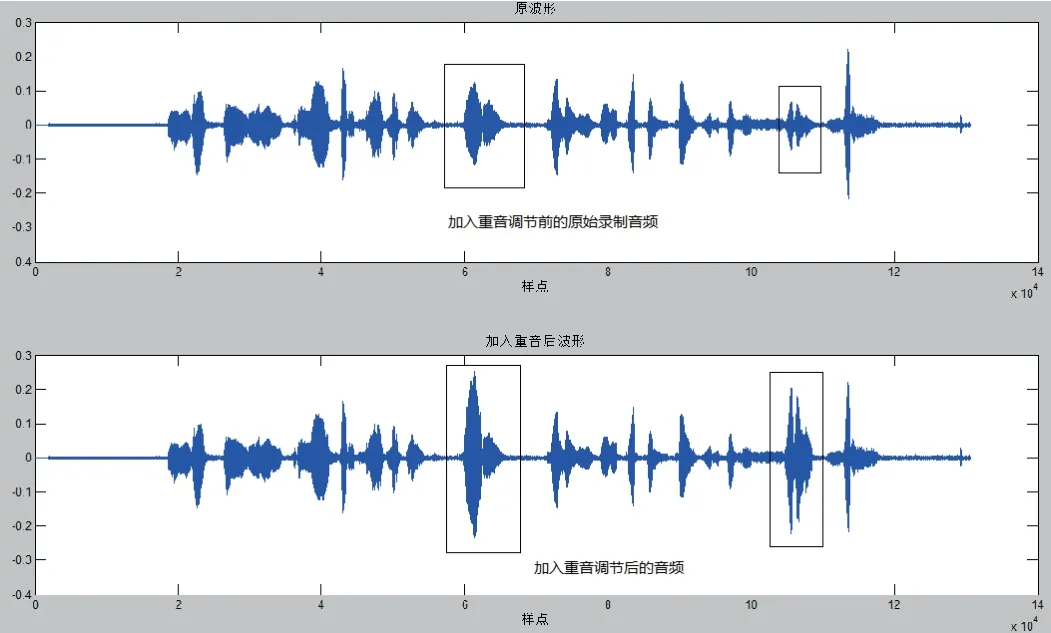
图7 语音重音修改效果
3.2.3 基音频率曲线调节实验分析
LPCAC方法中涉及的两个关键参数A(Amplify Adjusting Parameter振幅调节参数),F(Frequency Adjusting Parameter,频率调节参数)的确定是利用曲线均方误差最小化的方式确定,如公式(5)、(6)、(7),参数的优化的方法按照传统的共轭梯度法,如公式(1)、(2),参数A、F的计算结果见表8.
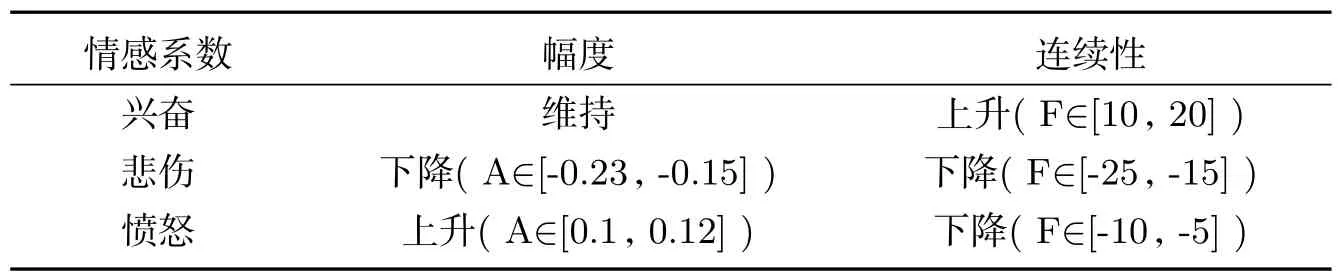
表8 LPCAP系数调节值
图8是对录制的无情感音频做三种情感韵律调节的效果,基音频率曲线的在A、F的调节作用下,曲线连续性,曲线的升、降幅度都有明显的调节效果.
对于韵律调节的效果测试中,邀请没有参与过本文工作的20位维吾尔族学生作为试听人员.他们将听到人工录制的原始音频和对人工录制音频文件作韵律调节后生成的三种情感语音,并对听到的语音作上述三种情感的判断和效果评判,测试结果如图9所示,调节的效果可以得到明显区分.
4 结束语
本文应用的录制语料来源是近年的维吾尔文的新闻文段,并安排发音准确的维吾尔族录制人员,虽然语句数量不多,但是语料可以提供大量可计算的重音和停顿数据,可以保证数据的覆盖率.语音的韵律范畴很广泛,情感的语音只是作为韵律的特殊或极端地表现形式.本文从维吾尔语音的特征出发在重音、停顿、基音频率三个方面来调节语音韵律,以期语音得以自然,去除“机器味”.本文所做的工作依然存在不足之处,下一阶段的工作重点是:
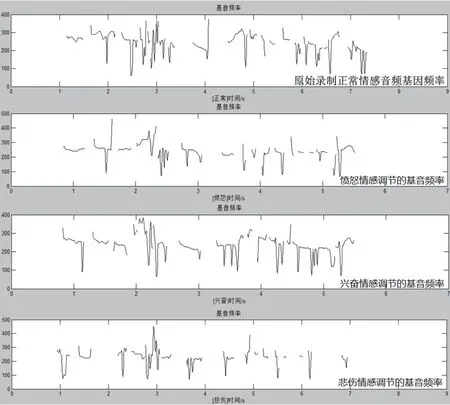
图8 基音频率的调节效果
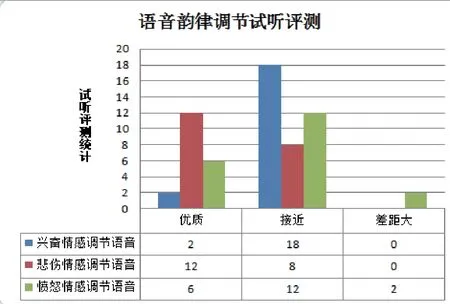
图9 情感调节试听测评
(1)优化ANN的构建,提高停顿的预判准确度;
(2)整理、完善维吾尔文中重音异义的词本(见表9),以及更多的维文语言独特语法点,并应用在语音处理领域中;
(3)丰富并完善由《中图分类法》改制的词域词本,以此更好地应用于词汇关联性的计算中;
(4)建立多样情感的涉及范围更全面的维吾尔语音语料资源;
(5)本文涉及的语音缺少对疑问式、否定式等语言特点的研究,是需要不断补充的工作;
(6)维吾尔文的句法、词法规则对合成、识别具有启发的意义,逐步使得维吾尔语音的韵律控制可以达到自然、流畅、真实的效果.

表9 重音异义词本
