维吾尔语名词词尾对维汉词对齐的影响研究∗
2015-11-02麦合甫热提麦热哈巴艾力阿孜古丽厦力甫
麦合甫热提,麦热哈巴·艾力,阿孜古丽·厦力甫
(1.新疆大学 教务处,新疆 乌鲁木齐 830046;2.新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046;3.新疆大学 人文学院,新疆乌鲁木齐830046)
0 引言
词对齐是指从对应的一对互译句子中找到互为译文的词对.为了得到大量正确的词对,可以使用词典,但词典往往有覆盖面不广、灵活性不强等缺点.对一些词语的灵活使用,特别是在不同上下文具有不同意思的情况下,词典很难提供帮助.
GIZA++是目前最常用的词对齐工具,因与语言无关并开源,深受使用者的青睐.但是GIZA++存在以下问题:对语料规模有一定的要求,当语料规模不足时其对齐结果会降低;对于句子结构不对称的语言对齐效果并不理想;在形态变化复杂的语言上得到的对齐结果远远不如其它语言[1−2].
对维汉词对齐而言,GIZA++除了受到以上所列的几点约束以外,维吾尔语词尾对词对齐的影响也是需要考虑的问题.因为词尾不仅构造维吾尔语词的不同形态而导致数据的稀疏,同时也携带一定的语义信息,传递某种意思.
本文分析了维汉词对齐中存在的问题,围绕着维吾尔语中某些词尾传递一定的意思,能够对齐到汉语句子中某些词的特点,提出(1)对维吾尔语句子进行词法分析使得词干和词尾分离;(2)选择性地保留词尾的方法即“分离—丢弃”方案,来提高维汉词对齐的正确率.本文将此方法应用到维吾尔语词性中词尾数量较多.但较固定的名词上,实验结果表明此方法对提高词对齐正确率以及机器翻译结果确实起到了积极的作用,可以将此方法扩展到维吾尔语中其它词性.
1 维吾尔语形态对维汉词对齐的影响
维吾尔语属于阿尔泰语系突厥语族,是典型的粘着性语言,这意味着维吾尔语一个词可以连接多个词尾而且可以多层缀接,表示同一个词干的不同语法功能.所以,经常出现一个维吾尔语词对应到一个汉语短语的情况,有时这个汉语短语甚至是不连续的.如图1和图2是一对维汉句子在形态分析前后进行词对齐的结果.
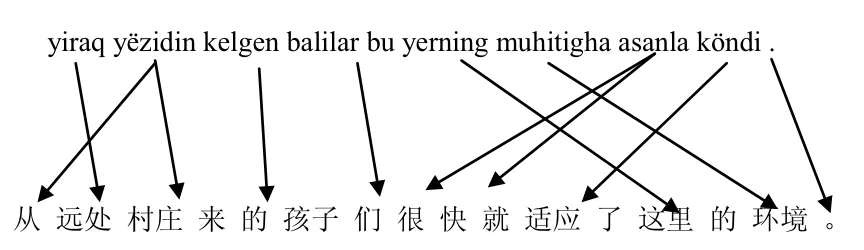
图1 维汉词对齐一例(词级别)
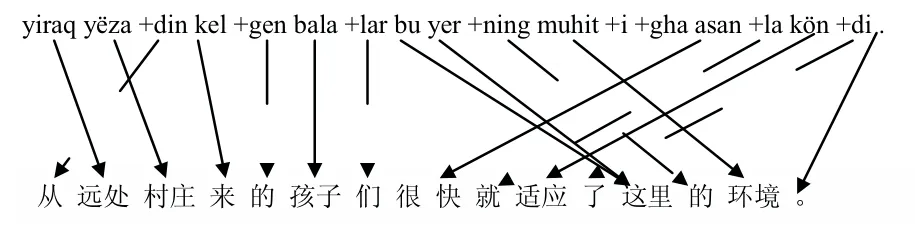
图2 维汉词对齐一例(经过形态分析)
图1中可以看出,yezidin对齐到“从···村庄”,而balilar对齐到“孩子们”.很显然,这将导致很多汉语词找不到对应的维语译文,特别是当语料规模不是很大的时候此问题尤为突出.对于同一个例子,如果对维吾尔语句子进行形态分拆即词干与各词尾分离,则得图2所示的对齐结果,其中虚线表示通过形态分析后分离出来的词尾以及与其对齐的汉语词.显然,进行形态分析后,原来没能准确对齐的汉语词差不多都对应到了维语部分.
此外,维吾尔语中词尾数量很多,对名词而言达到将近50个,某个类型的词尾往往有不同的变体,如第一人称单数就有四种变体-m,-im,um,m,它们形式不同但表达的意思相同.不同形态对计算机而言就是不同的词.同一个词尾的不同形式对词对齐起一定的不利影响.我们随机抽出了3万个维汉句对,对xizmet(工作)一词常用的不同形态出现的频率做了统计(用斜体表示了其词尾),其统计结果为表1所示.
从表中数字可看出:同一个词干派生出来的不同形态对应到了汉语中以”工作”为中心的词或短语.第3行和第10行的词尾”-te”和”-de”是一个词尾的不同变体,表示“在”;第4行和第11行的词尾”-tin”和”-din”也是一个词尾的不同变体,表示”从”.它们虽然表达相同的意思,但因形式不同,被计算机认为是不同的词,没能统计到一起.显然,维吾尔语的这种派生能力很容易导致数据稀疏问题,毫无疑问也影响Giza++的对齐结果.
为解决以上问题,可采取:(1)对维吾尔语句子进行词法分析,使得词干和各词尾分离,来对齐更多的词;(2)对属于同一个词尾的变体采取统一化形式,从而降低因形态不同产生的数据稀疏问题.因此,文献[3]中提出对维吾尔语词进行词干、词尾分离,保留词干的同时保留词尾且对同一范畴的词尾采用统一表示的方法,不仅一定程度上克服了数据稀疏问题,同时利用了词尾携带的语义,对齐了更多的汉语词.文献[3]提出的方法中因为词尾被看成是一个独立的token,虽然可以提高对齐准确率及召回率,但导致句子长度变得过长.有些本身词数较多的句子,因token数量变得过多,Giza++进行对齐之前被过滤掉.同时,我们注意到虽然维吾尔语的词尾带着一定的语义信息,但是由于维吾尔语和汉语言的不同特性,维吾尔语词尾对应的译文并不是每次都是明文显示,有时候需要通过上下文或者通过标点符号(表示语调)的形式表现出来.为了既保证降低数据稀疏以及让更多的词得到对齐,又克服句子长度变得过长的问题,本文采取了选择性的保留词尾的方法.
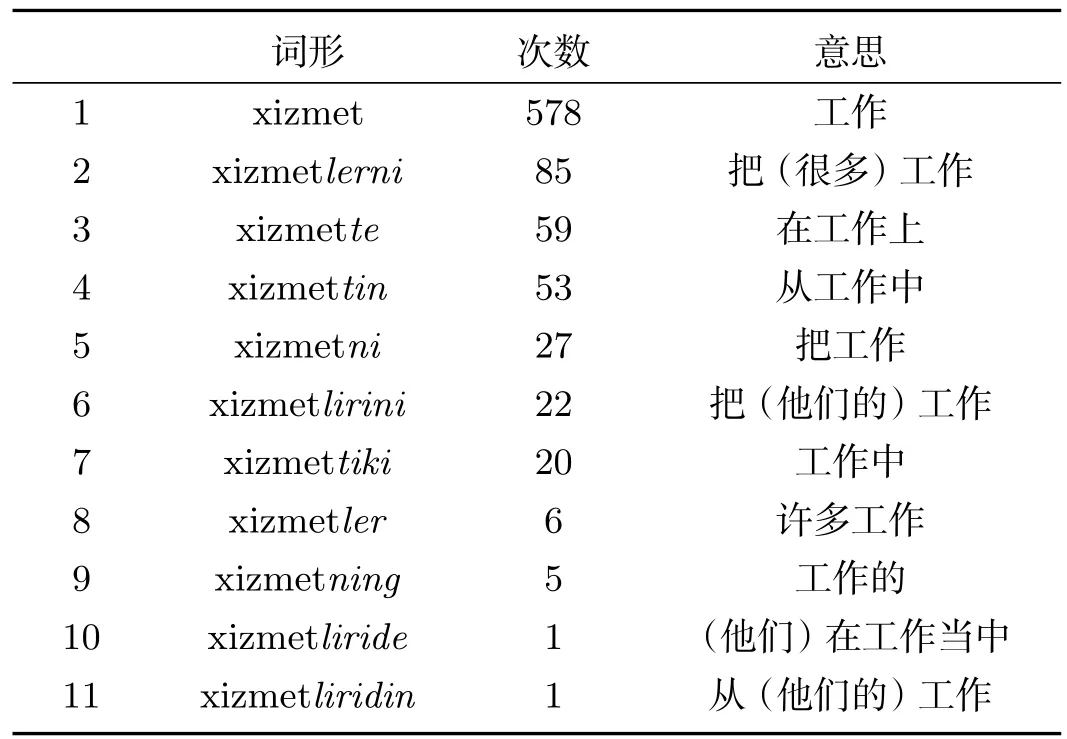
表1 xizmet(工作)一词的不同形态以及出现频率
2 统计分析维吾尔语词尾
上一节分析结果让我们进一步研究到底词尾粒度怎样制定对词对齐有更大的贡献?是不是所有的词尾都需要分离?或者应该选择性的分离?甚至是否丢弃?
为了得到词尾在维汉词对齐中起到的作用,我们对语料做了一系列统计及分析.语料为新疆电视台提供的每日新闻联播为主的新闻语料,维吾尔语小说《故乡》(总3册)以及维吾尔语小说《苏醒的大地》(共2册)等.新闻联播可体现与当今国内、国外以及百姓生活的方方面面且具有一定的实时性;文学领域一般都被认为能够体现某种语言的表达能力及特色,对于各种词的不同形态以及词尾的出现具有一定的概括能力,这是我们为什么选择这些语料作为统计对象的原因.语料规模及相关数据可参见表2.
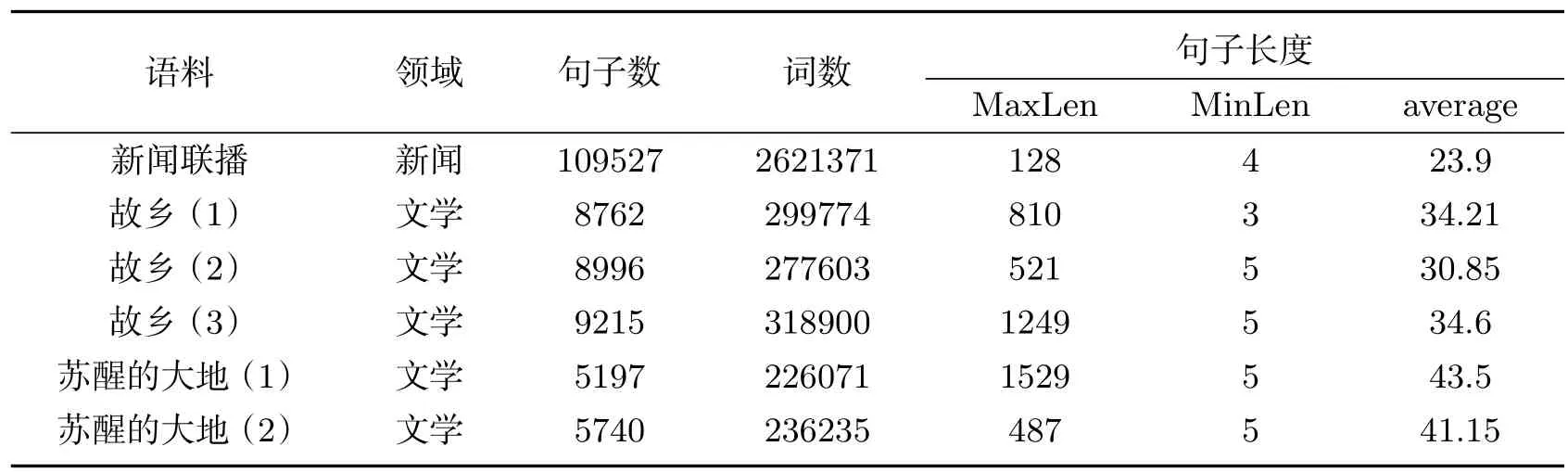
表2 不同语料统计信息
我们对以上语料做了词法分析,即词干和各词尾分离,后统计了每一种词尾的出现频率,表3为出现频率最高的10个词尾的信息,从表中数据可看出,虽然语料不同,但出现频率最高的词尾几乎相同.下一步,我们对已做词法分析后的句子用Giza++做了词对齐,并统计了每一种词尾在汉语词对齐后的结果,见表4.表分为两栏,左栏显示的是正确对齐次数高于错误对齐次数的词尾,其中正确对齐次数用下划线表示;右栏显示的是正确对齐次数少于错误对齐次数的词尾.统计结果显示,有些词尾正确对齐到相应汉语的频率远高于错误对齐的情况(大部分体现为介词、连词等).还有些词尾从汉语句子中根本找不到对应的译文,结果导致错误的对齐结果,比如:所有的语料中出现频率最高的词尾+i表示第三人称单数的词尾,但在汉语句子中往往没有一个词于其对齐.经分析后发现,这些词尾虽然在维吾尔语句子中有一定的语义信息,但汉语句子中往往通过上下文或者标点符号等不同方式表达出来或忽略.
产生这种结果的原因在于维汉两种语言属不同语法范畴.其不同之处主要体现在以下两种情况:
(1)一个语言所拥有的语法范畴在另一种语言中可能不存在.如:维吾尔语名词有数、领属及格范畴,但汉语没有;而汉语有补足语范畴,但维吾尔语则没有.俄语有性别范畴,但维吾尔语、汉语都没有;
(2)有些范畴虽然不同语言都拥有,但其表达的意思则不同.如:维吾尔语、俄语等都有动词的语态,但俄语中没有被动语态、相互共同态等.
总之,每种语言都有自己的语法范畴,不能将某个语言的语法范畴强行对应到另一种语言的语法范畴.语法范畴的不同,导致两种语言对同一内容的不同表示方法,进而导致某些语法范畴漏翻、增翻等现象.
从以上分析不难看出,对维吾尔语词尾采取选择性的保留,即:保留被明文翻译可能性大的词尾,舍去明文翻译概率低的词尾,这样既能保证对齐数量的增长,又能克制由于词法分析导致的句子长度过长的问题.
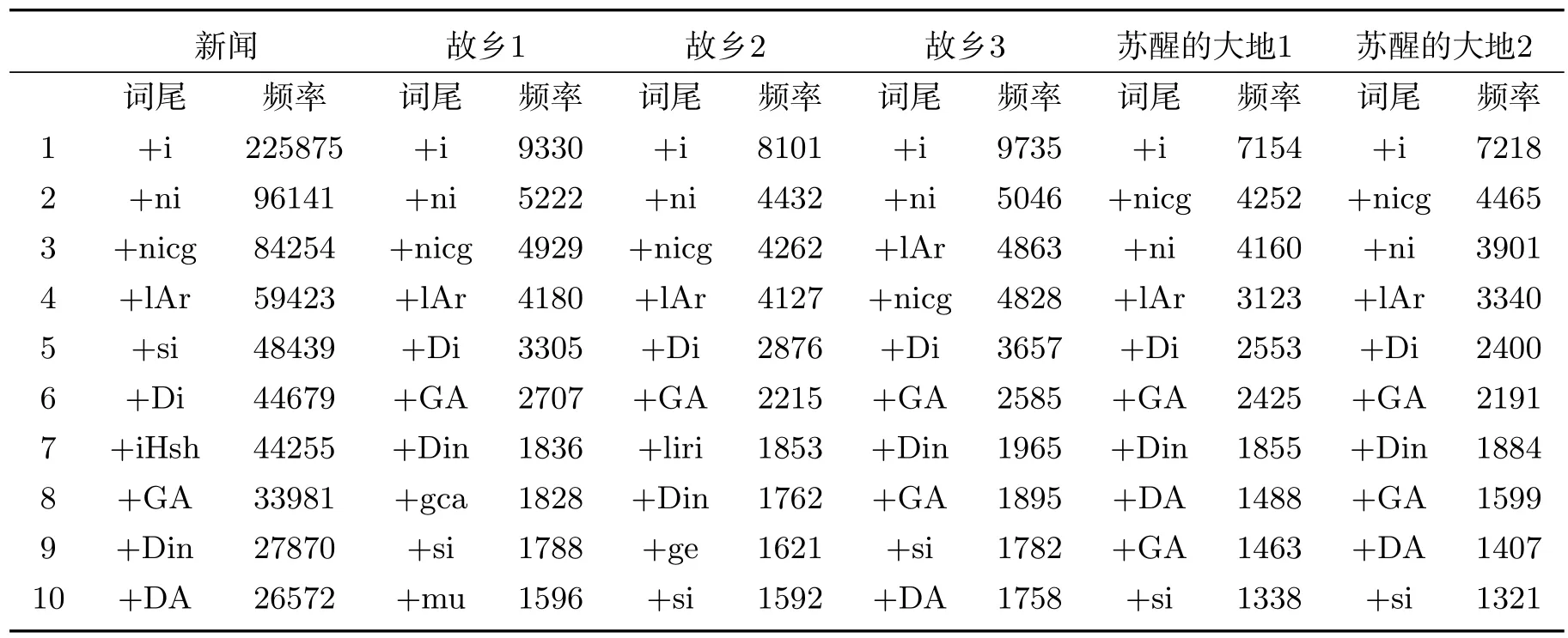
表3 不同词尾的统计结果
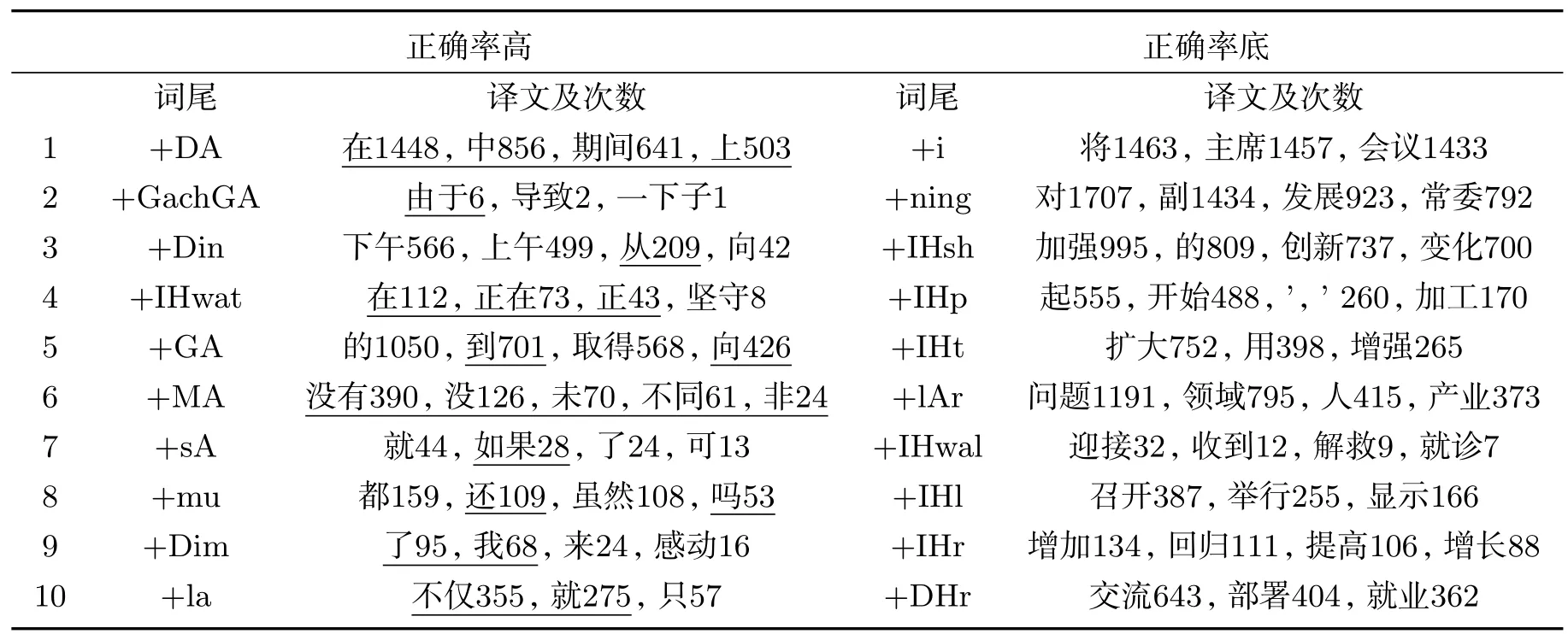
表4 词对齐后各词尾的对齐情况统计
3 构造不同词尾粒度的模板
为了验证我们的结论,我们尝试了对维吾尔语词尾的选择性保留方案,本文将其称为“分离—丢弃”方案.其中,分离是指对汉语中有译文的可能性高的词尾进行词尾与词干分离;丢弃是指对汉语中译文出现的可能性低的词尾进行丢弃.不管是分离,还是丢弃,都是在统计分析及语言特征基础之上进行,没有绝对的对或错之别,其目的是尽可能地发挥词尾对词对齐的正面影响.同时,通过丢掉翻译概率较低的词尾来克服句子长度问题.
不失一般性,我们将此方案应用到维吾尔语名词词尾.因为,维吾尔语词性大致可分为静词和动词,维吾尔语中动词词尾最多,形态变化既丰富又复杂;静词包括名词、形容词、副词等词性.其中名词的词尾数量位居动词之后,但数量稳定、形态变化不像动词复杂,易分析,具有一定的代表性.
维吾尔语名词的形态构形形式:词干+[数]+[人称]+[格],(方括号表明可选).如:
名词不同范畴有不同的词尾,总数达到50个.根据不同范畴分析,名词的分离—丢弃方案实施为如下:
数范畴(Number)
数范畴表示名词的单数和复数.单数没有词尾,复数词尾为-lar,-ler,但汉语中复数除了人名后加“们”外,常常通过上下文来区分,这一点与维吾尔语不同.所以对数范畴采取了丢弃方案.如:
Nurghun(很多)kitab(书)+lar很多书;Jiq(许多)Alma(苹果)+lar许多苹果.
人称范畴(Person)
维吾尔语属于主语可省略(pro-drop)型语言,被省略的主语可以从人称词尾知道.属于维吾尔语名词人称范畴的词尾个数达到20个,其中第三人称单、复数词尾-i,-si出现在N+N结构中的次数最多,因为维吾尔语中名词修饰名词时,被修饰名词以第三人称单、复数形式出现.如:
这种情况下,第三人称单(复)数在目标(汉语)语往往没有对应的译文.因此,对其采用丢弃方案.而第一、第二人称单、复数词尾分别对应到汉语的“我、我们、你、你们、您、您们”,采用分离方案;
根据以上分离—丢弃方案,我们构造了不同词尾粒度的模板.为了找到最有效的词尾粒度方案,我们对不同模板赋予了序号,序号大者包括序号小的模板方案,如:模板MN2包含了模板MN1采用的方案以外,又增加了新的方案.以下为不同模板的标示符及采用的规则:
MN1:采用了名词格范畴的方案;MN2:在MN1的基础上增加了名词人称范畴的方案;MN3:在MN2的基础上增加了名词数范畴的方案.
4 实验分析及结论
为了验证维吾尔语名词的分离—丢弃方案对维汉词对齐的影响,我们设置了两种实验:实验一着重分析此方案对AER(对齐错误率)的影响,实验二分析了此方案对机器翻译的影响.
实验一:分离—丢弃方案对AER的影响
实验中使用了CWMT2013提供的维汉新闻领域平行语料,包含11万条句对,并使用GIZA++做词对齐.为了评价词对齐的结果,仍然采用了AER(对齐错误率)[4]评价标准.
为了发现不同词尾粒度对维汉词对齐的影响并找到最理想的词尾粒度,我们将以上模板依次应用到维吾尔语句子上,并与汉语语料构成平行语料,总共构成了3对训练语料.为得到AER的结果,还从每种训练语料中随机挑出100条句子做手工对齐做为标准答案.同时,对维吾尔语句子做词法分析后词干词尾分离并保留所有词尾的情况做为基线,依次计算每一个模板的AER值并与其做比较.实验结果见表5.
分析实验数据,首先注意到语料中标记数(token)的变化.每采用一种模板,token数都有所下降,说明通过模板的使用丢弃了一些无用的词尾,降低了句子长度.AER的值都是下降的趋势,说明丢弃分离方案对词语对齐起的作用是积极的.
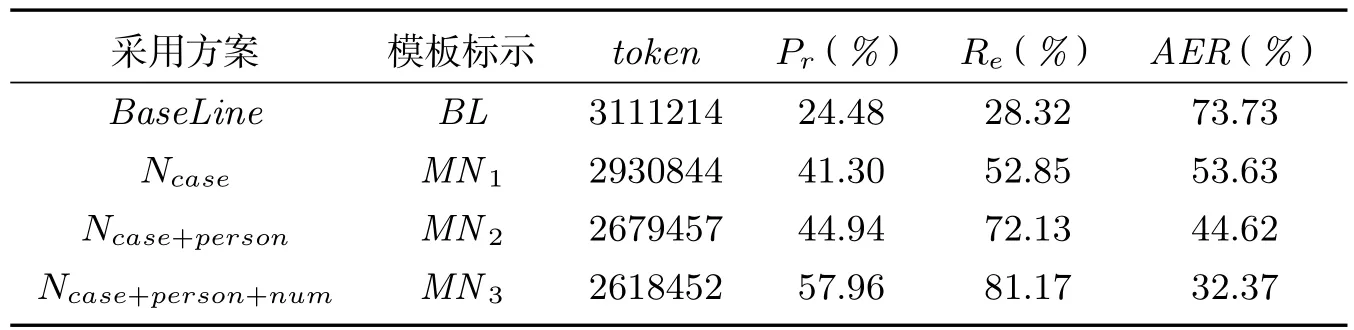
表5 不同模板AER值比较
实验二、分离—丢弃方案对机器翻译的影响
实验目的是考查此方案对机器翻译的影响,语料仍然是CWMT2013提供的面向新闻领域的维汉训练语料,规模与实验一相等,开发集为700条句子,测试语料为1000条句子构成.实验中,我们仍使用了开源工具Moses(摩西)作为解码器.为了分析不同模板对机器翻译的影响,我们按每一种方案重新构造训练语料、开发集及测试集并分别进行了翻译.实验中,把新疆多语种信息技术重点实验室参加CWMT2013新闻领域维汉机器翻译评测结果作为基线实验,基线实验使用的语料与我们使用的语料相同,但语料中做词法分析后只保留词干并把所有的词尾丢弃.对翻译结果评价标准使用基于词的BLEU[5]值.系统中,语言模型是利用工具SRILM[6]训练的三元模型,而训练数据是相应训练集的中文部分,其他参数都没改变,采用默认值.实验结果为表6所示.
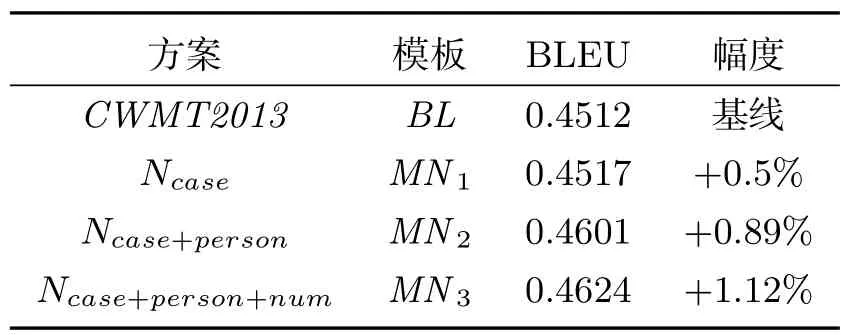
表6 不同模板对机器翻译的影响
表中可以看出,不同模板对机器翻译的影响不同,但都是向BLEU值提高的趋势发展,特别是MN3的影响最明显,提高幅度达到了1.12%.
综上所述,分离—丢弃方案,对于形态复杂、词尾携带一定语义信息的维吾尔语而言是可行的,通过分离方案尽可能地保留有意义的词尾,同时通过丢弃方案将在汉语中不被翻译的或不被表示的词尾丢弃,从而降低句子长度,最终提高机器翻译的质量.目前的方案对BLEU值的影响虽然是正面的,但幅度不高,这说明此模板的选择有待进一步改善,进一步统计分析后提出更合理的模板也是我们进一步研究的目标.同时,目前我们只考虑了名词,下一步将其扩展到维吾尔语中词尾数量最多、形态结构最复杂的动词以及副词和形容词.
