一种新的麦克风阵列自适应语音增强方法
2015-10-29徐进赵益波郭业才
徐进,赵益波,郭业才
1.南京信息工程大学电子与信息工程学院,南京210044 2.江苏省大气环境与装备技术协同创新中心,南京210044
一种新的麦克风阵列自适应语音增强方法
徐进1,2,赵益波1,2,郭业才1,2
1.南京信息工程大学电子与信息工程学院,南京210044 2.江苏省大气环境与装备技术协同创新中心,南京210044
在复杂的语音环境中,利用麦克风阵列语音增强技术能有效地拾取目标语音信号并消除噪声干扰,但传统的麦克风阵列波束形成的加权系数是固定的.为了能灵活地控制麦克风阵列波束的形成方向以及消除其波束旁瓣带来的残余噪声,提出了一种基于麦克风阵列的自适应语音增强技术.该技术将自适应滤波器和麦克风阵列相结合形成波束可控的广义旁瓣消除器,然后在广义旁瓣消除器后面续接一个改进的谱减法,并加入契比雪夫窗函数.仿真实验结果表明,所提出的语音增强方法能有效去除语音信号中的噪声干扰,相比于传统广义旁瓣消除器,信噪比大约提高了3.5 dB.
麦克风阵列;自适应滤波;改进广义旁瓣消除器;谱减法;语音增强
在语音通信过程中,实际环境中的干扰噪声会严重影响目标语音信号的获取,致使得到的信号不再是纯净的语音信号.如果干扰噪声的幅度过大,拾取的语音信号就变得模糊不清并夹有刺耳的噪声,从而影响听觉效果.这时可以利用语音增强方法来去除背景噪声和干扰,以获取较纯净的目标语音信号.
麦克风阵列能够充分利用语音信号的空域、时域和频域信息,同时具有高空间分辨率、高信号增益与较强的抗干扰能力等特点.目前,已经形成了较成熟的麦克风阵列语音增强技术,如固定波束形成法[1]、广义旁瓣对消法[2]等.在传统的麦克风阵列技术基础上引入自适应滤波[3]可灵活而有效地实现波束控制,进一步改善语音增强效果.自适应滤波是至今为止最广泛、最有效的语音增强方法之一,该方法只需要很少的或根本不需要任何关于信号和噪声统计特性的先验知识,仅凭观测信息就能实时估计信号和噪声的统计特性,自动调节权系数达到最佳滤波的要求.
在自适应滤波算法中,最小均方算法(least meansquare,LMS)是一种最典型的自适应算法,虽然较递归最小二乘法(rcursive least squares,RLS)的收敛速度慢,但是简单而便于实时实现.经自适应滤波后的语音信号还伴有背景噪声或其他难以去除的噪声,这些噪声可用谱减法加以消除.谱减法[4]作为一种单通道语音增强方法,因具有简单方便和计算量小等优点而在语音增强中很受欢迎,但在去除背景噪声的同时会产生刺耳的难以消除的“音乐”噪声.它的存在严重影响听觉效果,甚至造成语音内容的误解,故应避免用传统方法来估计噪声功率.文献[5]则利用改进谱减法估计噪声功率,减少了音乐噪声,改善了听觉效果.
本文提出一种基于麦克风阵列技术的语音增强方法,该方法结合自适应滤波与谱减法,同时加入了契比雪夫窗函数[6],对不同入射角度的期望信号实现波束控制,可以通过后续的谱减法进一步去除残余噪声,因此提高了信噪比,改善了语音质量.
1 麦克风阵列语音增强的主要方法
麦克风阵列对获取的多路信号进行分析处理,使阵列形成的波束主瓣指向期望信号的来波方向而在干扰信号方向形成零陷,于是在获取目标信号的同时又可以最大程度地抑制干扰,提高了信号输出信噪比.波束方向图与主瓣波束宽度、麦克风的间距、数目、摆放位置、声源的入射角度及采样频率有关.利用麦克风阵列波束形成技术不仅解决了在使用单个麦克风时需要人为不断调节麦克风指向性的问题,而且大大提高了输出信噪比,也不必人工干预调节麦克风,因此很容易获取纯净的目标信号[7].
1.1基于延时-累加的麦克风阵列语音增强
延时-累加方法实现语音增强是通过对目标声源到达每个麦克风的时间进行估计的,根据到达每个麦克风的时间差对各路信号进行时延补偿,经补偿后的各路信号是同步的.然后通过固定加权系数乘积累加得到输出,此时麦克风阵列形成的波束方向指向期望信号,对期望信号进行最大程度的获取,并削弱噪声和其他语音信号干扰的影响.
1.2后置维纳滤波的麦克风阵列语音增强
为了进一步消除经固定波束形成法处理后语音中的非相干噪声,文献[8]提出了在波束形成器后增加后置维纳滤波的结构.维纳滤波器的权系数是根据各麦克风接收信号间的自相关和互相关得到的,即维纳滤波器的权系数随接收信号的变化而变化.
1.3麦克风阵列自适应语音增强
基于麦克风阵列自适应语音增强方法依据阵列接收到的信号统计特性的变化来自适应地调整滤波器权系数,使得麦克风阵列的波束主瓣始终对准期望信号方向,“零点”指向干扰噪声的方向.自适应方法的应用提高了麦克风阵列的适应性,能够实现时变语音环境下纯净语音信号的提取.
利用自适应波束形成方法来实现语音增强是目前最常用的一种方法.最早的自适应波束形成算法是由文献[9]提出的线性约束最小方差(linearly constrained minimum variance,LCMV)波束形成器,其基本原理是在一些约束条件下(目标信号为单位增益约束,其他干扰信号方向形成零陷)使阵列的输出功率最小,即输出信号中干扰噪声的功率最小.在此基础上,文献[10]提出了广义旁瓣抵消器(generalized sidelobe canceller,GSC),其结构原理如图1所示.
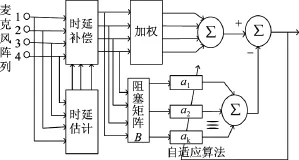
图1 GSC系统框图Figure 1 System block diagram of GSC
2 改进的GSC语音增强
利用广义旁瓣抵消器结构来实现多通道目标语音信号增强是目前使用较广泛的一种方法,很多现有的自适应阵列语音增强技术都是基于此结构进行改进的.图2为本文提出的改进型广义旁瓣抵消器,主要由延时-累加波束形成器、阻塞矩阵、改进的多通道噪声抵消器和谱减法组成.
延时-累加波束形成器对期望方向的目标语音信号进行增强,而对其他方向的干扰噪声进行抑制.阻塞矩阵对目标信号进行阻塞使其输出为干扰和噪声信号的组合,并为延时-累加波束形成器输出信号中的残余噪声提供参考信号.改进的多通道噪声抵消器根据噪声参考信号估计出延时-累加波束输出信号中的噪声信号,以此获得较纯净的目标语音信号.改进的谱减法可以进一步去除期望方向上残余的干扰噪声信号,以实现目标信号的增强.
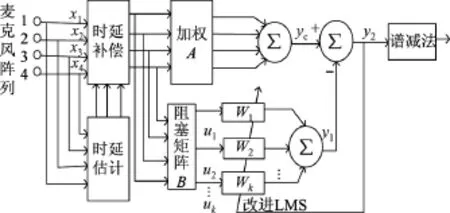
图2 改进GSC系统框图Figure 2 System block diagram of the improved GSC
在图2中,上支路输出为

式中,A=C(CHC)-1f为权系数向量,C为约束矩阵,f为对应的约束响应向量.权系数向量A随目标信号方向的变化而变化.下支路结构中含有一个阻塞矩阵和一个自适应K阶FIR滤波器.经过时延补偿后,每个通道中的信号在时间上是同步的,要实现阻塞矩阵输出信号中不含期望信号,只要保证阻塞矩阵中每一行元素之和为0即可.经阻塞矩阵处理后的输出信号为

式中,bm为阻塞矩阵B中的第m列元素向量,对于所有的m值,满足式(3)

式中,bm是相互线性独立的,阻塞矩阵输出信号U(n)最多由M-1个线性独立的元素组成.经阻塞矩阵处理后的输出信号再经自适应FIR滤波器处理,得到输出信号
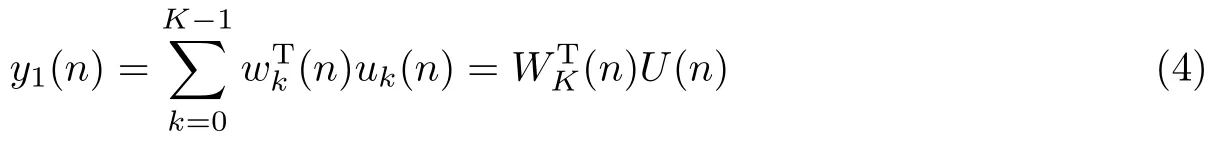
式中,WK=[w1(n),w2(n)···wK(n)]T,U(n)=[u1(n),u2(n)···uK(n)]T.上支路的输出减去下支路的输出,便可以得到处理后较纯净的语音信号为

由于y1(n)中不含期望信号而只是干扰和噪声信号的组合,麦克风阵列结构对语音信号的处理都集中在yc(n)中.于是寻找合适的滤波器权系数Wk(n),使得最终的输出功率最小.改进的LMS自适应滤波算法的权矢量按式(6)和(7)进行调整
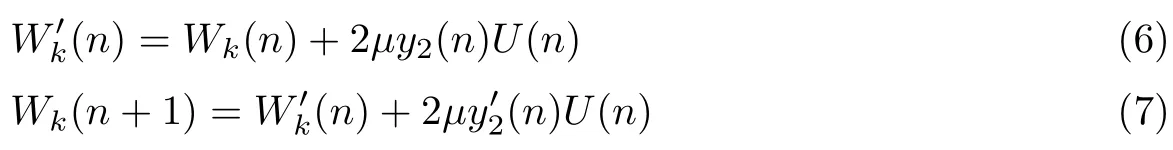
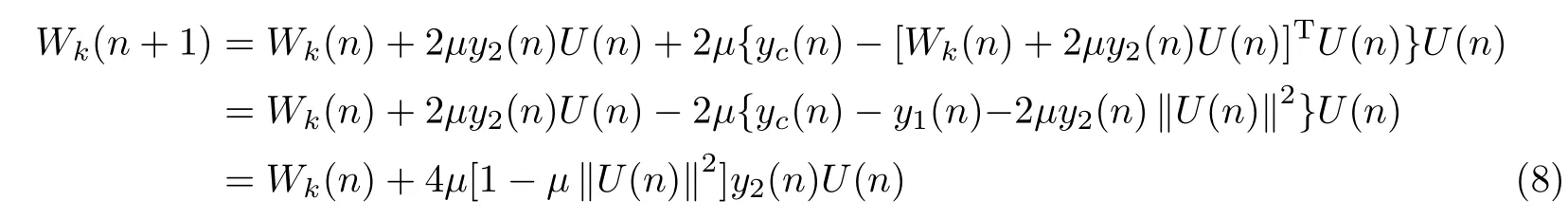
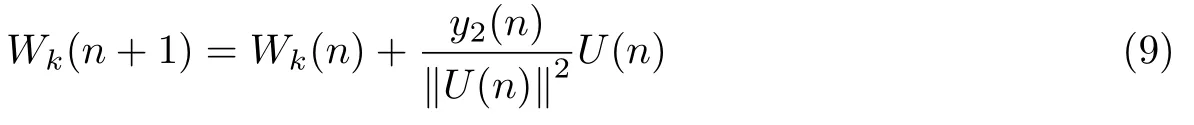
图2中改进的LMS算法由式(4)~(9)给出,相比于图1中固定步长的传统LMS算法,本文提出的改进LMS算法不但具有更快的收敛速度,而且兼顾了稳态失调信号,从而使最终的去除噪声效果更好.处理随机噪声时,改进的LMS算法可以快速更新权系数来实时跟踪随机信号,并不断对带噪随机信号进行滤波,即改进的LMS算法在一定程度上适用于非平稳随机信号的去噪处理.
为了进一步去除残余噪声,在提取的输出信号y2后续接一个谱减法.谱减法基于短时平稳假定对带噪语音信号进行傅里叶变换和重叠分帧处理,将每帧信号功率减去估计的噪声功率得到纯净语音信号功率,并根据人耳对语音信号的幅度比较敏感而对语音的相位不敏感这一特性,就可以用含有噪声的语音信号的相位代替纯净语音信号的相位;然后对纯净语言信号进行傅里叶逆变换即可得到增强后的语音信号,具体实现框图见图3.
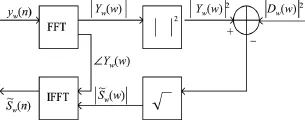
图3 谱减法系统框图Figure 3 System block diagram of the spectral subtraction
在利用谱减法对y2进行进一步去噪时,最重要的是估计每一帧噪声功率.最常用的估计方法是假设带噪语音信号的前几帧是只含有噪声而不含期望信号的.对这几帧信号取功率平均作为整个语音段的噪声功率,但最终的实验效果并不好,会产生“音乐”噪声,影响听觉效果.利用一阶低通滤波器得到噪声的功率为
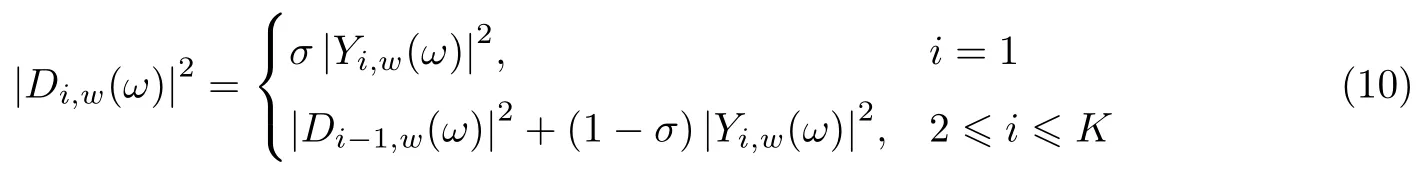
式中,0<σ<1,K为带噪语音总帧数.通过估计得到每帧噪声功率后便可求得每帧纯净语音功率

式中,α>1,β?1.在噪声段保留一定的噪声,可以取得较好的降噪及抑制纯音噪声的效果,改善听觉效果.
3 仿真实验
仿真实验是在MATLAB7.10.0环境中进行的.为了验证本文方法的有效性和优越性,比较本文方法与经典GSC语音增强算法.仿真实验时,内容为男生朗读的“第1课认识新同学”,加入方向性干扰噪声的同时还考虑接收过程中的随机噪声.假设期望信号方向为10◦,干扰方向为60◦,得到的仿真结果如图4~10所示.其中,图4~6分别给出了纯净语音信号、方向性干扰信号和麦克风接收信号.图7和8分别为GSC与改进GSC处理后的信号.图9和10分别为GSC与本文方法波束比较图和本文方法处理后的方向图(加入契比雪夫窗函数).
由仿真实验结果可以看出,纯净的语音信号进入麦克风阵列时会受到方向性干扰和噪声的影响,同时还伴有来自麦克风的随机噪声,因此麦克风阵列接收到的语音信号受到了很大干扰.从图7中可以看出,GSC虽然去除了方向性干扰噪声,但是还有残留的背景噪声无法去除,而本文改进的GSC结构不但去除了方向性干扰噪声信号,同时还进一步去除了背景噪声和与期望信号同方向的干扰噪声.对比图7和8可以明显看出,本文改进的GSC结构去噪能力比传统GSC提高了很多,降噪效果更好.加入的契比雪夫窗函数可以进一步降低旁瓣.从图9和10中可以看出,10◦方向的目标信号可以完全接收,而其他方向的信号增益很小或几乎为零.
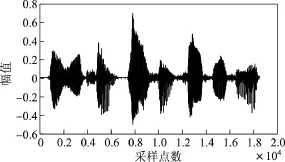
图4 纯净语音信号Figure 4 Pure speech signal
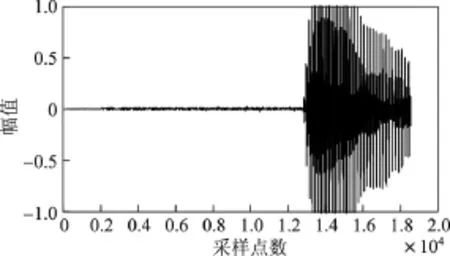
图5 方向性干扰信号Figure 5 Directional interference signal
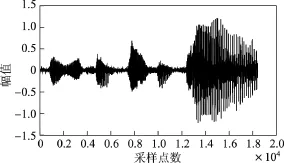
图6 麦克风接收信号Figure 6 Received signal of the microphone
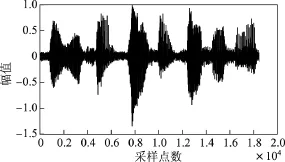
图7 GSC处理后的信号Figure 7 Processed signal via the GSC
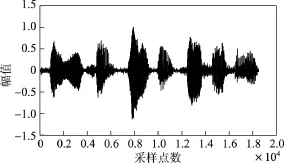
图8 改进GSC处理后的信号Figure 8 Processed signal via the improved GSC
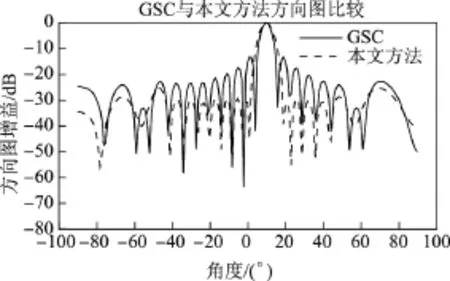
图9 GSC与本文方法波束比较图Figure 9 Beam comparison graph between GSC and the proposed method
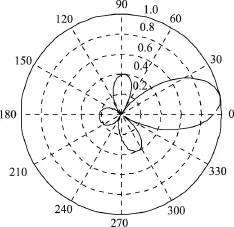
图10 改进后的方向图Figure 10 Improved pattern
4 结语
本文研究了麦克风阵列自适应语音增强方法,在麦克风阵列技术基础上引入自适应滤波和谱减法,相比于传统麦克风阵列GSC噪声消除法,本文方法可以针对任意角度信号,后续谱减法可以进一步去除残余噪声提高了系统整体去噪能力.仿真结果表明,本文方法比传统GSC方法更优越,信噪比提高了大约3.5 dB.
[1]耿慧慧.基于麦克风阵列语音增强研究[D].邯郸:燕山大学,2013:13-15.
[2]SEUNGHO H,JUNGPYO H,SANGBAE J.Robust GSC-based speech enhancement for human machine interface[J].IEEE Transactions on Consumer Electronics,2010,56(2):965-970.
[3]CHIH C Y.Adaptive microphone array based flter in the speech enhancement[C]//Networked Computing and Advanced Information Management,7th International Conference on IEEE,2011,23(3):237-242.
[4]KULDIP P,KAMIL W,BELINDA S.Single-channel speech enhancement using spectral subtraction in the short-time modulation domain[J].Speech Communication,2010,52(5):450-475.
[5]TAKAHSHI Y,AKATANI T,OSAKO K.Blind spatial subtraction array for speech enhancement in noisy environment[J].IEEE Transactions on Audio,Speech and Language Processing,2009,17(4):650-644.
[6]杨国裕.线性相位契比雪夫数字滤波器的时窗函数[J].数据采集与处理,1995,29(4):12-19. YANG G Y.Window function of linear phase Chebyshev digital flter[J].Journal of Data Acquisition&Processing,1995,29(4):12-19.(in Chinese)
[7]ADAM B.Signal subspace approach for psychoacoustically motivated speech enhancement[J]. Speech Communication,2010,53(2):210-219.
[8]GANNOR S,COHEN L.Speech enhancement based on the general transfer function GSC and post-fltering[J].IEEE Transactions on Speech and Audio Processing,2004,12(6):561-571.
[9]HABEST E A P,BENSETY J,GANNOT S.On the application of the LCMV beamformer to speech enhancement[J].IEEE Applications of Signal Processing to Audio and Acoustics,2009,10:18-21.
[10]HAN S,HONG J,JEONG S,HAHN M.Robust GSC-based speech enhancement for human machine interface[J].IEEE Transactions on Consumer Electronic,2010,56(2):965-970.
(编辑:王雪)
Adaptive Speech Enhancement for Microphone Array
XU Jin1,2,ZHAO Yi-bo1,2,GUO Ye-cai1,2
1.School of Electronic&Information Engineering,Nanjing University of Information Science and Technology,Nanjing 210044,China 2.Jiangsu Collaborative Innovation Center on Atmospheric Environment and Equipment,Nanjing 210044,China
In a complex speech environment,microphone array speech enhancement techniques can efectively extract target speech signals and eliminate noise.In a conventional microphone array,the beam forming weighting coefcients are fxed.To fexibly control the beam forming direction of the microphone array and eliminate residual noise due to side-lobes,this paper presents an adaptive enhancement technique for microphone array speech.A microphone array with an adaptive flter is used to form a controllable generalized sidelobe canceller(GSC),followed by improved spectral subtraction with a Chebyshev window function.Simulation results show that the proposed method can efectively remove noise,improving the performance by about 3.5 dB with respect to the ordinary GSC.
microphone array,adaptive flter,improved generalized sidelobe canceller(GSC),spectral subtraction,speech enhancement
TN912
0255-8297(2015)02-0187-07
10.3969/j.issn.0255-8297.2015.02.008
2014-10-08;
2014-12-06
国家自然科学基金(No.51077057);江苏高校优势学科建设工程项目基金;江苏省高校自然科学基金(No.14KJB120007);南京信息工程大学基金预演项目基金(No.2013x007);优秀博士论文作者专项资金(No.27122)资助
赵益波,博士,讲师,研究方向:非线性电路系统与自适应信号处理.E-mail:yibozhaodn@163.com
