Apriori算法在个性化教学辅助系统中的应用
2015-10-25樊妍妍
樊妍妍
(安徽商贸职业技术学院电子信息工程系,安徽芜湖241000)
Apriori算法在个性化教学辅助系统中的应用
樊妍妍
(安徽商贸职业技术学院电子信息工程系,安徽芜湖241000)
以个性化教学辅助系统为研究对象,采用Apriori关联规则算法,以挖掘学生某门课的作业成绩为例,找出章节知识点之间的易错关联规则,从而对学生需要巩固复习的知识点加以提示,实现因材施教。
数据挖掘;Apriori算法;个性化教学辅助系统;易错关联
随着信息技术和网络技术的飞速发展,网络在线教学辅助系统已经彰显出优越性,成为对传统课堂教学的有效辅助和拓展手段。学生作为教学的主体,在接受能力等方面有着显著的个体差异,这要求教学辅助系统能向学生提供个性化的建议和指导。本文提出了一种基于Apriori关联规则算法的个性化在线教学辅助系统。该系统通过挖掘学生某门课程的作业成绩中的有价值信息,找到各章节知识点间的易错关联规则,并在页面中提示学生未掌握的知识点,以智能导航的方式提醒其继续学习巩固,体现以学生为中心、实施因材施教的思想。
1 Apriori关联规则算法
关联规则挖掘是一种非常重要又简单实用的数据挖掘技术。它可将隐含在大量数据中的那些用户感兴趣的、未知又有价值的信息提取出来,用以预测一个事物同其他事物之间的关系。在关联规则挖掘算法中,Apriori算法是一种最经典、最有影响力的算法。
1.1Apriori算法的基本思想
Apriori算法是Rakesh Agrawal和Ramakrishnan Srikant在1994年提出的一种单维、单层的布尔关联规则算法[1],包括找频繁项集和产生强规则两部分,其中找频繁项集为核心,包括连接、剪枝两步操作。
1.2Apriori算法的实现
1.2.1找频繁项集
这部分的思想为:创建一个候选项集,通过多次逐层迭代,最终找出频繁项集[2]。图1为描述该算法的伪代码。

图1 找频繁项集的伪代码
其中连接和剪枝由apriori_gen函数实现,实现思路如下。
(1)连接
为产生频繁k-项集的集合Lk,需通过Lk-1与自己连接,产生一个候选k-项集的集合Ck。集合Lk-1中元素是可连接的,即其前k-2个项是相同的。
(2)剪枝
Mannila、Toivonen和Verkamo根据Apriori算法中频繁k-项集的子集一定不可能是某个非频繁的(k-1)-项集这一性质,将剪枝操作描述为:如果Ck中的一个(k-1)子集不在Lk-1中时,那么Ck一定不是频繁的,即将其从Ck中删除[3]。
连接和剪枝的操作描述如图2所示。对has_infrequent_subset函数的算法描述如图3所示。

图2 apriori_gen的算法描述

图3 has_infrequent_subset的算法描述
1.2.2产生强规则
(1)由于频繁项集的所有子集都是频繁项集,故可以先找出k个子集(要求它们都只含1项),再通过连接这些子集得到另一些子集,所得到的子集都含有2项,以此类推,直到产生有k-1项的子集,从而找出频繁k-项集的所有非空子集。

2 在线教学辅助系统的优化
Apriori算法已被广泛应用于医院、银行、学校等多个领域。通过该算法,各系统可挖掘自身数据之间的关联性,分析得到有参考价值的结果,并将该结果用在决策的制定过程中。
本文研究的个性化在线教学辅助系统的原始实验数据是安徽商贸职业技术学院计算机多媒体技术131班的图形图像处理课程的成绩。我们记录学生各章节作业情况,利用Apriori算法分析作业成绩间的潜在联系,找出任一章各节知识点之间的偏序关系,如当学生对某一知识点未掌握时,则他对其他某些知识点有可能也不能很好掌握。系统根据对关联结果的分析,找出学生在该章学习中未能掌握的知识点,并通过在系统学习页面中添加“推荐复习”的链接将信息反馈给学生,使学生能够有针对性地学习。
利用关联规则对系统进行优化的整个数据挖掘过程分为四步,即数据收集阶段、数据预处理阶段、数据挖掘阶段和结果分析阶段。系统在数据收集阶段收集和整理学生该科的作业成绩,得到作业成绩信息库;在数据预处理阶段从作业成绩信息库中找出要挖掘的信息并加以编码,再把关系表转换为事务数据库;在数据挖掘阶段从事务数据库中找到频繁项集;在结果分析阶段从频繁项集中找出关联规则。
2.1数据收集阶段
数据收集工作是数据挖掘中一个基础而重要的步骤。在本阶段,系统首先收集学生的作业成绩,选择学生的Photoshop课程第二章学习结束后的3次作业,并从中随机抽取18名学生的成绩,结果如表1所示。表1中,学生作业成绩被分为A、B、C、D和E五个等级。

表1 学生作业成绩数据表一
2.2数据预处理阶段
在本阶段,要对表1进行分析转换,原来成绩为“A”的转换成“Y”(优秀);原来成绩为“B”“C”“D”“E”的转换成“N”(不优秀),得到学生作业成绩数据见表2。在表2中,三次作业分别用ZY0101、ZY0102、ZY0103三列表示。
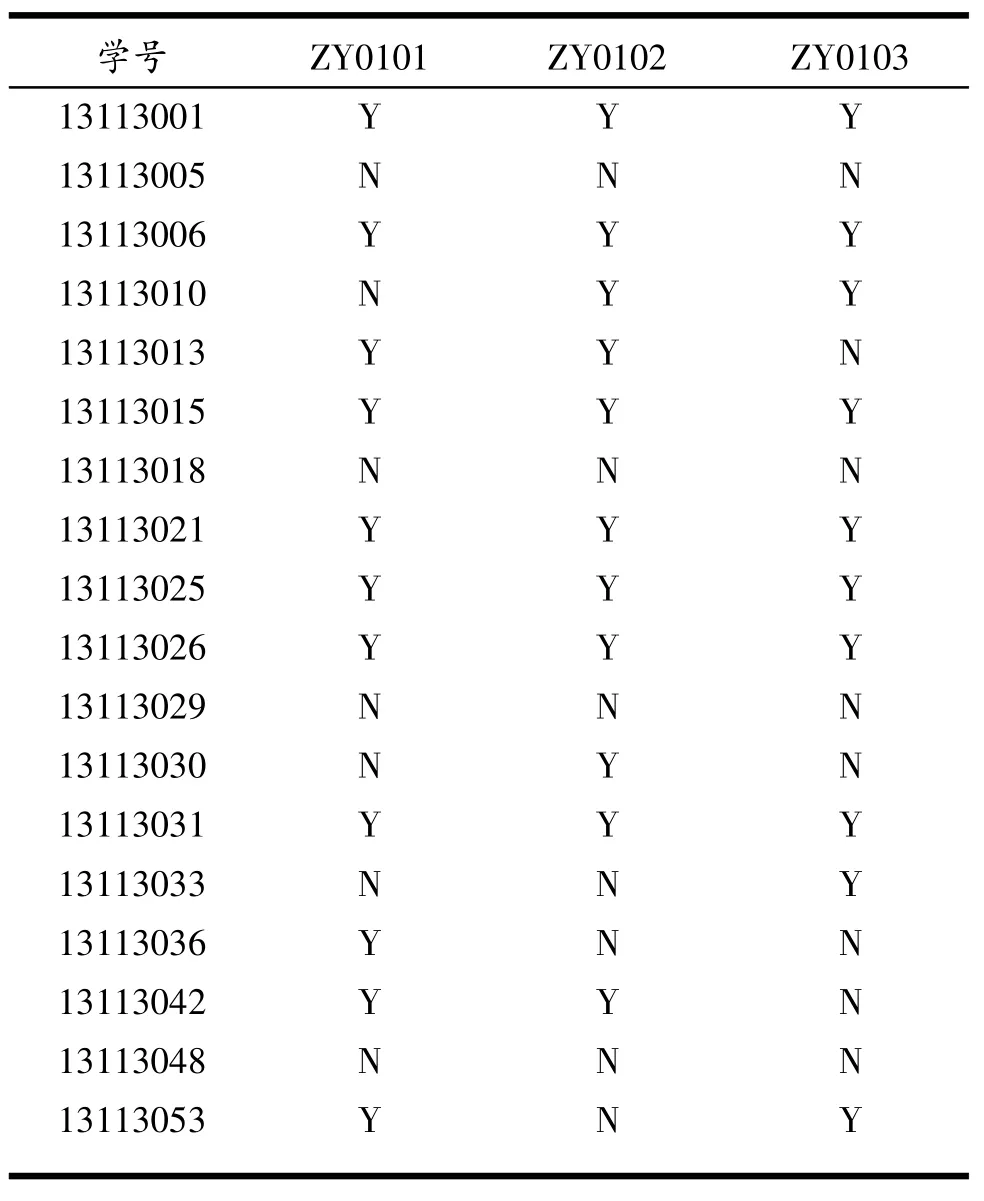
表2 学生作业成绩数据表二
2.3数据挖掘阶段
在本阶段,要根据Apriori算法找到频繁项集。笔者假设给定的最小置信度阈值为50%、最小支持度计数为3。
2.3.1使用候选项集找出所有频繁项集
(1)表2中的每个项都是候选1-项集集合C1的成员,即C1={ZY0101,ZY0102,ZY0103},然后统计每个项中N出现的次数,结果如表3所示。

表3 支持计数一
(2)根据最小支持度计数为3,可确定频繁1-项集集合L1为{{ZY0101},{ZY0102},{ZY0103}},如表4所示。

表4 支持计数二
(3)候选2-项集集合C2由L1⊗L1(⊗表示连接)产生,对C2每个候选项集中同时出现N的次数进行计数,即C2={{ZY0101,ZY0102},{ZY0101,ZY0103},{ZY0102,ZY0103}},如表5所示。
(4)由于最小支持度计数为3,可确定频繁2-项集L2为{{ZY0101,ZY0102},{ZY0101,ZY0103},{ZY0102,ZY0103}},如表6所示。

表6 支持计数四
(5)由L2L2可得到候选3-项集集合C3,即C3={ZY0101,ZY0102,ZY0103},对C3每个候选项集的出现次数进行计数,如表7所示。

表7 支持计数五
(6)根据最小支持度计数的值3得到最大频繁集L3={ZY0101,ZY0102,ZY0103},如表8所示。

表8 支持计数六
2.3.2根据频繁项集找出强关联规则
利用Apriori关联规则生成算法,可对Li(i=1,2,3,…)进行计算,得到它们的置信度,具体做法如下:

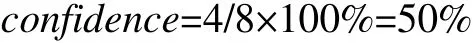
这里,Li可以是各种可能出现的非空子集。本文先将这些非空子集作为关联规则中的前件,然后再对前件进行判断,如果某条规则的置信度大于预设最小置信度的50%,则认为该规则为强规则。
2.4结果分析阶段
按照上述规则分析,可以得到如下结论:
1)如果ZY0101和ZY0102同时出错,则ZY0103出错的可能性为80%;
2)如果ZY0101和ZY0103同时出错,则ZY0102出错的可能性为80%;
3)如果ZY0102和ZY0103同时出错,则ZY0101出错的可能性为80%;
4)如果ZY0101出错,则ZY0102和ZY0103同时出错的可能性为57%;
5)如果ZY0102出错,则ZY0101和ZY0103同时出错的可能性为57%;
6)如果ZY0103出错,则ZY0101和ZY0102同时出错的可能性为50%。可以看出,三次作业成绩的优秀级之间存在一定的关联性,也就是,如果学生三次作业中有一次不是优秀,即该生还没有很好掌握该次作业中涵盖的知识点,
那么可能会存在其他某些知识点该生也不能很好掌握,即其他次作业成绩也未达到优秀。同理可知,如果学生没掌握好某一章的知识点,则其他章节相关的知识点该生也可能没有掌握好。通过分析结果,教师可以及时发现某个学生在某章学习中未能掌握的知识点,
通过在系统学习页面中添加“推荐复习”链接来告知该生需要强化的学习内容,从而实现有针对性的施教。
3 结束语
个性化在线教学辅助系统不仅是对课堂教学的辅助和拓展,同时也为每个学生提供个性化指导。本文以实现辅助教学的个性化为目标,将Apriori关联规则算法引入教学辅助系统的优化设计中,为学生提供了个性化的学习界面,使进入系统学习的学生能够得到适合自己的学习内容及良好的用户体验,但要全面实现系统的个性化服务,可能涉及更多的领域和技术,那么研究的内容也更广泛、复杂。因此,今后的研究需用数据挖掘技术挖掘教学中多方面的信息,产生更合理的教学规则,并将智能Agent技术、流媒体技术等多种理论技术综合应用,从而提供更智能化的辅助教学服务,使系统更加完善。
[1]AGRAWAL R,SRIKANT R.Fast Algorithms for Mining Association Rules in Large Databases[R].San Jose:IBM Almaden Research Center,1994.
[2]HAN J W,KAMBER M.数据挖掘概念与技术[M].2版.北京:机械工业出版社,2007:352-353.
[3]MANNILA H,T0IV0NEN H,VERKAM0 A I. Proceedings of AAAI’94 Workshop on Knowledge Discovery in Database(KDD’94),Washington D C,1994[C].Seattle:AAAI Press Publisher,1994.
[4]杨洁霞.使用Apriori算法确定学生所选课程间的关联关系[J].中山大学学报论丛,2004(1):180-184.
【责任编辑梅欣丽】
Research of Apriori Algorithm in the Application of Personalized Teaching Assistant System
FAN Yanyan
(Department of Electronic Information Engineering,Anhui Business College,Wuhu 241000,China)
Because the students in the ability to accept,and degree of foundation and study hard there is a big difference,so can provide students with personalized advice and guidance in the teaching assistant system has become an important auxiliary tool of classroom teaching.In this paper,individualized teaching assistant system for the study,using Apriori association rules algorithm to tap student achievement in a course of work,for example,to identify error-prone sections of the association rules between knowledge,thus consolidating the knowledge students need to review the point to suggest that to achieve individualized
data mining;Apriori algorithm;individualized teaching-aided system
TP391
A
2095-7726(2015)09-0036-04
2015-06-11
安徽省高校省级自然科学研究项目(KJ2013Z087);安徽省示范性高等职业院校合作委员会(A联盟)项目(皖高示范〔2012〕4号)
樊妍妍(1980-),女,安徽芜湖人,讲师,硕士,研究方向:网站开发及图形图像处理。
