基于SPCE061A单片机的嵌入式语音识别系统设计
2015-10-22帅晓勇陶黄林吕敬祥
帅晓勇,陶黄林,吕敬祥
(1.井冈山大学电子与信息工程学院,江西,吉安 343009;2.井冈山大学数理学院,江西,吉安 343009)
基于SPCE061A单片机的嵌入式语音识别系统设计
*帅晓勇1,陶黄林2,吕敬祥1
(1.井冈山大学电子与信息工程学院,江西,吉安343009;2.井冈山大学数理学院,江西,吉安343009)
设计一款嵌入式语音识别系统,该系统硬件平台以凌阳公司的SPCE061A为核心。采用离散隐马尔科夫模型识别算法对非特定人的孤立词语音识别。实验结果表明,该系统对非特定人孤立词识别率达90%以上,性价比高,可应用于许多场合,有一定的市场前景。文章阐述了该系统各个电路模块及软件流程图的设计。
SPCE061A;语音识别;离散隐马尔科夫模型;非特定人;孤立词
0 引言
语音识别[1-2]ASR(Automatic Speech Recognition)是人类交流的主要方式,主要研究让机器能准确地识别人所说的话。其产品广泛应用于英汉翻译系统、智能玩具控制、智能手机、语音拨号、智能家居系统、工业控制等领域。因此迫切需要进行语音识别系统设计和理论方法的研究。上世纪50年代美国研制了第一个语音识别系统(Audry系统),进入21世纪,苹果、三星、微软等大公司大力投入了语音识别系统的研究。然而语音识别系统仍然存在几个研究的难点,如:识别算法的改进和优化,识别系统的准确性和实时性等等。因此,为了提高人们的生活质量,有必要解决语音识别自身系统的难点。
嵌入式语音识别系统虽然运算速度和存储容量有限,但具有体积小、功耗低、便携性好、价格低、可靠性高等特点,因此嵌入式语音系统更具有使用价值。本文设计一种基于凌阳SPCE061A单片机为核心的嵌入式语音识别系统[3-5],包括预处理技术、硬件设计、软件设计、算法实现。在预处理方面采用动态端点检测算法;识别算法采用DHMM;硬件设计上实现了语音信号的采集、语音信号的存储、语音信号处理、语音播报等功能,以c语言编程最终通过实验验证本系统的实用性。
1 系统主要硬件设计
该系统电路主要由凌阳SPCE061A、串口通信模块、USB模块、存储扩展模块、语音输入输出模块、LCD显示模块等组成,如图1所示。凌阳SPCE061A单片机集成度高,具有16位*16位的乘法运算和内积运算功能,CPU时钟最高可达到49MHz,因此,可代替一般的DSP,但其价格比专业的DSP芯片廉价很多;该单片机具有较强的中断处理能力,支持10个中断向量,具有双通道的10位ADC和DAC,内置自动增益控制功能(AGC)的语音输入方式,可构成一种高性价比的语音识别系统,故本系统采用该单片机做核心。

图1 系统硬件框图Fig.1 The system hardware block diagram
1.1 语音输入电路
SPCE061A单片机内置有8个通道的A/D转换器,其中有1个通道是MIC_IN输入,专门用于语音信号采集。语音信号经MIC转换成电信号,然后输入至单片机内部的前置放大器进行放大处理。电路如图2所示。
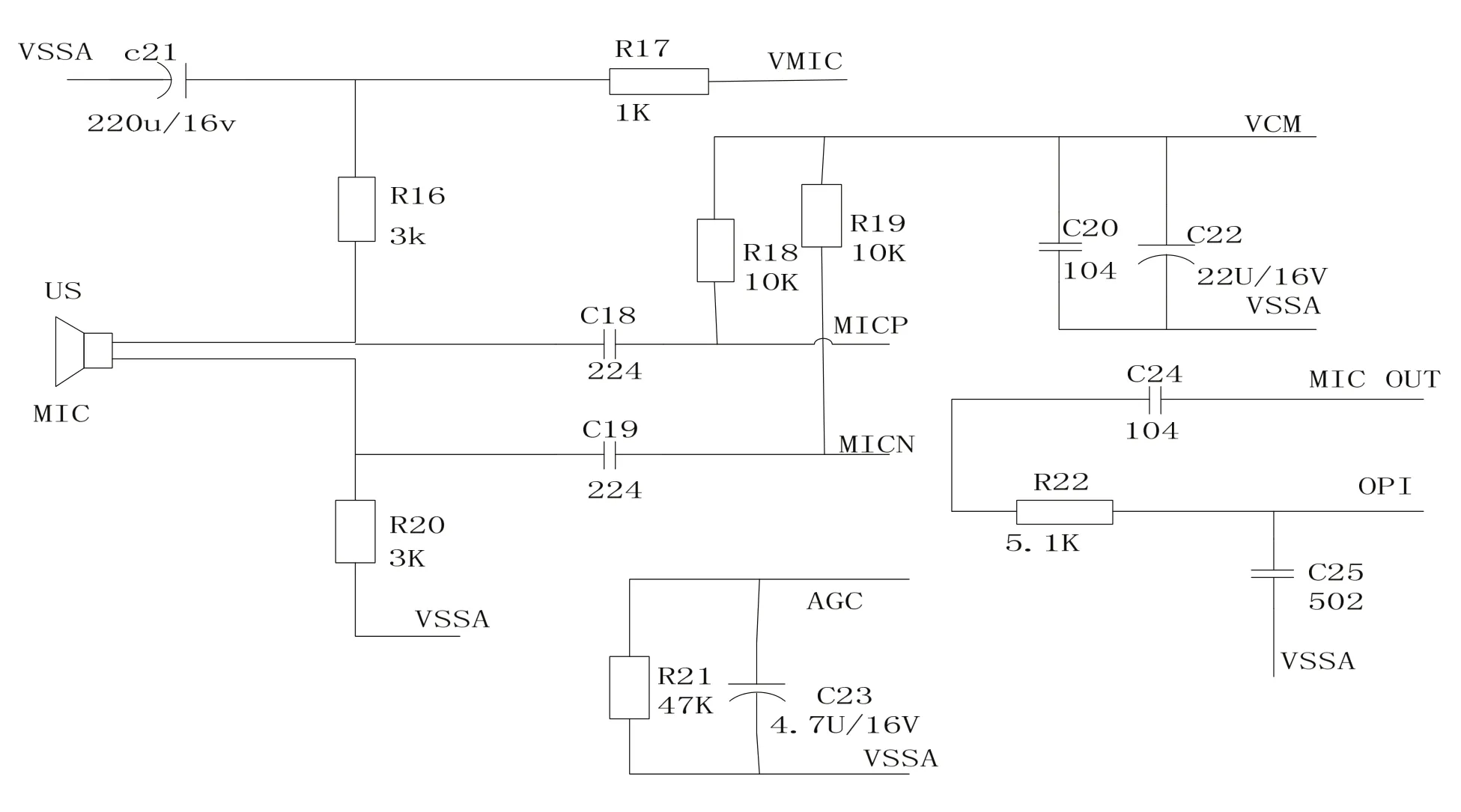
图2 语音输入电路Fig.2 Speech input circuit
1.2语音输出电路
SPCE061A单片机DAC是电流输出,必须选用电流驱动芯片,因此选SPY0030音频放大器,电路如图3。
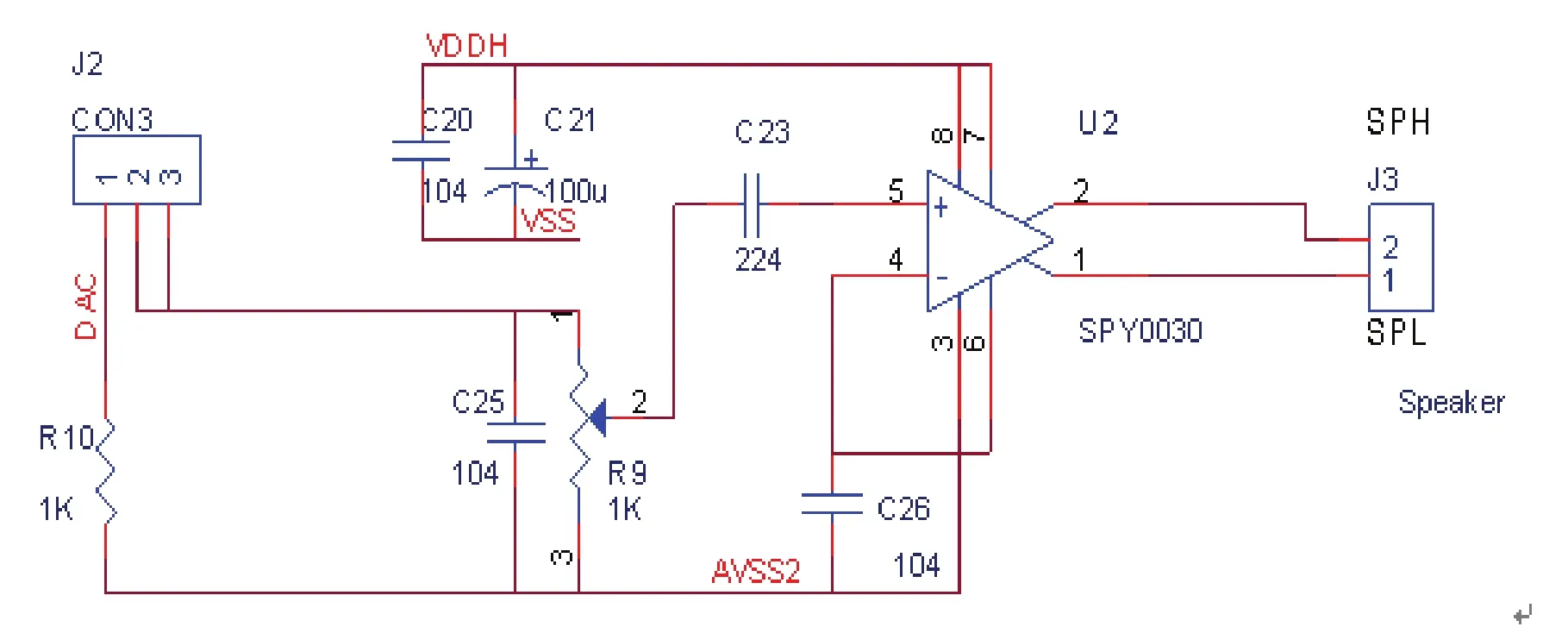
图3 语音输出电路Fig.3 Speech output circuit
1.3串口通信电路
SPCE061A集成的串口UART模块提供了一个全双工标准接口,用于SPCE061A与外设之间的串行通信。借助于IOB端口的特殊功能和UART IRQ中断,可以同时完成UART接口的接收与发送过程。本系统的串口通信电路如图5所示。由MAX232CP芯片和SUB-D9接口等器件组成,使用3.3V数字电源供电,MAX232将TTL电平转换为RS-232电平,经SUB-D9接口连接串口线或PC机等具有串行接口的设备进行数据传输,使用TXD、RXD接SPCE061A的IOB10、IOB7引脚,Tx、Rx连接MAX232和SUB-D9来实现。
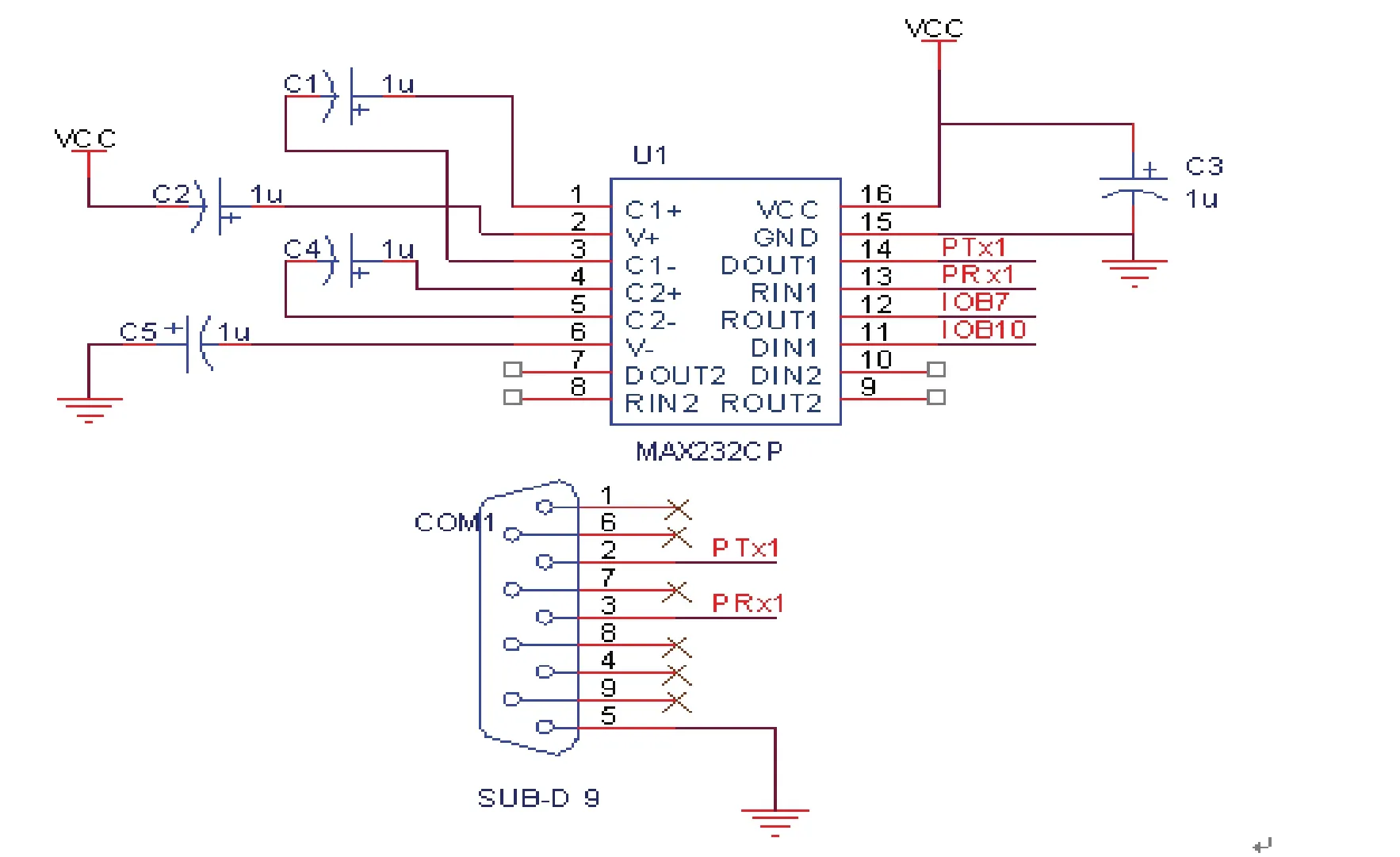
图4 串口通信电路Fig.4 Seria communication circuit
2 系统软件设计
由于凌阳单片机主要用于语音处理,因此,系统硬件设计较为简单。系统功能的实现在很大程度上取决于其强大的软件设计。
2.1语音识别软件设计框图
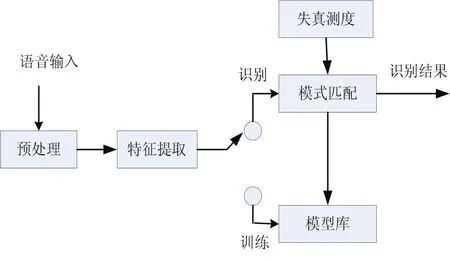
图5 语音识别系统的原理图Fig.5 Block diagram of the speech recognition system
一般来说语音识别主要由预处理、特征提取[6-7]、语音模板库、模式识别等主要模块组成,如图5所示。预处理主要是对信号进行预加重、加窗、分帧等处理;特征提取去除语音信号中所包含的冗余信息提取用以表征语音信号的一系列参数;训练模型库主要通过说话者不断重复语音,将所获得的语音特征参数按一定规则进行聚类,形成待识别的语音模板库;模式匹配对待识别的语音信号提取特征参数,然后按一定准则计算其与模型库之间的相似度以判断输入语音的语意信息。
2.2语音识别算法
本系统采用DHMM(离散隐马尔科夫模型),特征参数提取采用Mel倒谱系数进行特征提取。2.2.1特征参数提取
一般来说,语音特征参数提取必须满足以下两个条件:1)特征参数需反映语音的本质特征,也就是其必须是语音所包括的一般特性,本文针对非特定人语音识别,因此不能包括说话人特征信息。2)特征参数各个分量之间的耦合必须尽量小,这样能达到压缩数据的目的。目前较为常用的特征参数提取包括线性预测分析倒谱(LPCC)、对数倒谱(LSF)、线性预测分析频谱(LPC)、Mel倒谱系数(MFCC)等。本文针对MFCC存在的不足,提取了IMFCC方法。
MFCC提取过程如图6所示,MFCC特征参数提取有很好的识别性能和抗噪性能,但实践表明MFCC参数各分量对识别率的贡献不同。对识别率贡献小的分量会降低识别率,因此仍有较好的改进空间。本文提出的改进方法如下:
1) 特征分量加权
针对特征参数各个分量对识别率的影响可知,不同的分量对语音的表征能力不同,如果简单地将各维分量组合起来不能满足要求,因此可给各维分量相应地加权之后再组合。
2) 特征分量求差分
对加权后的特征分量求一阶或者二阶差分,一阶差分的目的是求特征分量变化的速度,二阶分量可以认为是特征分量变化的加速度。这样可较好地体现说话人语音的变化。
3) 主成分分析
主成分分析,简而言之就是寻找并保留最有效、最重要的数据而去掉不重要的数据。刚好符合改进MFCC的场景,对MFCC参数进行主成分分析,可以选取那些最能代表语音特征的部分,而舍弃那些表征能力弱,这样可以减少数据量存储,降低计算复杂度。可以归纳主成分分析的计算步骤如下:
A.计算相关系数矩阵
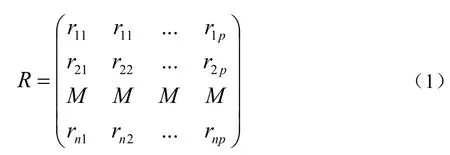
B.计算特征值与特征向量
首先解特征方程λI-R=0,求出特征值λi(i =1,2,…,p),并使其按大小顺序排列,即λ1≥λ2≥…≥λp≥0;然后分别计算出对应特征值的特征向量。
C.计算主成分贡献率及累计贡献率
主成分贡献率:
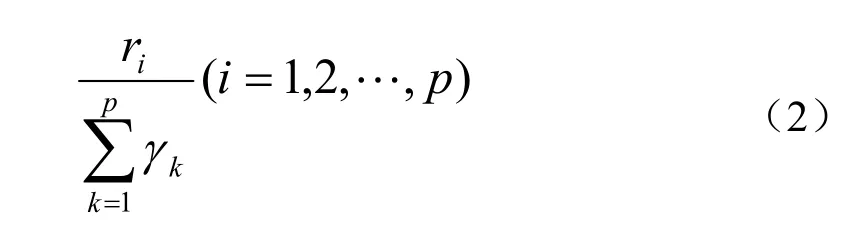
累计贡献率:

一般取累计贡献率达85-95%的特征值λ1,λ2,…,λm所对应的第一,第二,第m个主成分。
D.计算主成分载荷
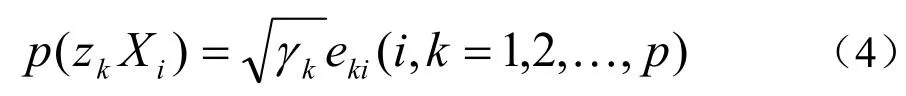
由此可以进一步计算主成分得分:
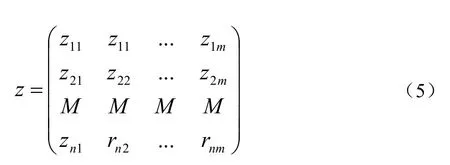
即z=(z1,z2…zm),这里z1为最能表现声音特征,以此类推。

图6 MFCC特征参数提取过程Fig.6 Feature extraction of MFCC
2.2.2DHMM算法
主要的语音识别算法有动态时间规整算法、隐马尔科夫模型、人工神经网络模型。本文实现的是嵌入式语音识别系统,因此采用离散隐马尔科夫模型。该模型具备非特定人、大词汇量的优点,可在PC机上实现模板训练功能的软件架构,简化嵌入式系统的复杂性,针对SPCE061A单片机的特点,通过优化viterb算法能较好的解决系统实时性指标。
DHMM孤立词识别步骤如下[8-11]:
1) 读入某个词所有参加训练的样本。
2) 使用Baum-Welch算法及Viterbi算法计算输出概率。
3 )计算概率的相对变化,设置一个阈值,若小于这个阈值则存储模版,否则回第二步。
3 实验结果及分析
系统选用400词的小系统词表,在进行识别前,对每个待识别的词进行训练,参加训练的人数20人。识别时选20个人,有10人未参加训练,对简单的语音词语进行识别,结果如表1所示。
从下表数据可以看出,该系统对非特定人的简单语音识别率超过90%,识别时间在0.7 s左右,具有较高的识别率,系统响应时间也较快,满足实时性的要求。对未参加训练的样本识别率较低,因此可以通过增大训练样本数和进一步改进识别算法来提高识别率。目前已有较多的学者在从事这方面的研究工作,相信不久的将来,识别算法一定有较好的改观。
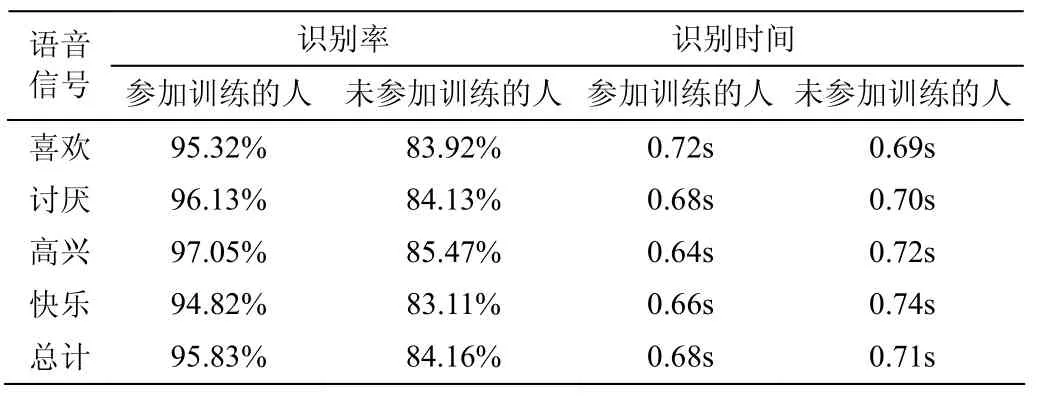
表1 语音识别实验结果Table 1 Experimental results of speech recognition
4 结束语
该系统实现了以凌阳SPCE061A单片机为核心的嵌入式语音识别系统,运用以DHMM为识别算法对非特定人的孤立词的语音识别。提出了一种改进的MFCC算法,运用主成分分析,对语音特征参数进行分级评定,有效地减少了数据存储量,降低了算法的复杂度。系统运行可靠、经济、运算速度能满足要求,可用于孤立词汇的命令识别系统,具有较好的市场前景。
[1] 赵力.语音信号处理 [M].北京:机械工业出版社,2003.
[2] Rabiner L,Juang B.Fundamentals of Speeeh Recognition[M].Englewood Cliff, NewJersey:Prentiee-Hall,1993.
[3] 薛均义,张延斌,虞鹤松,等.凌阳16位单片机原理及应用[M].北京:北京航空航天大学出版社,2003:72-89.
[4] 荆嘉敏.基于HMM的语音识别技术在嵌入式系统中的应用[J].电子技术应用, 2003(10): 12-14.
[5] 李玉贤.基于 SPCE061A 单片机的语音识别系统的研究[D].哈尔滨:东北农业大学, 2004.
[6] Yujian Li, Hidden Markov models with states depending on observations[J].Pattern Recognition Letters, 2005,26(7)-984.
[7] S.E.Levinson.Continuous speech recognition by means of acoustic-phonetic classification obtained from a hidden Markov model[J].in Proc.ICASSP’87(Dallas TX),1987.
[8] 魏星,周萍.语音识别系统及其特征参数的提取研究[J].计算机与现代化,2009(9):228-243.
[9] Cheng O, Abdulla W, Salcic Z, et a.l Speech recognition system for embedded real-time applications[C].2009 IEEE InternationalSymposium on.Signa Processing and Information Technology ( ISSPIT), 2009: 118-122.
[10] Wang D.Zhangliang.Embeded speech recognition system on 8-bit MCU core[C].IEEE international Conference on Acoustics Speech and Signal Processing, 2004.
[11] Furui S.50Years of Progress in Speech and Speaker Reeognition Researeh[J].ECTIT ransactionS on ComPuter and Information Teehnology,2005,l(2):64-74.
THE HARDWARE DESIGN OF SPEECH RECOGNITION BASED ON SPCE061A
*SHUAI Xiao-yong, TAO Huang-lin, LV Jing-xiang
(1.School of Electronics and Information Engineering, Jinggangshan University, Ji’an, Jiangxi 343009, China;2.School of Mathematics and Physics, Jinggangshan University, Ji’an, Jiangxi, 343009, China)
We design an embedded speech recognition system.The system was centered SPCE061A of Sunpluse company.It was realization of speaker-independent’s isolated word recognition through DHMM.The experiment confirms that its speech recognition accuracy reaches 90 percent for speaker-independent and short vocabulary.The system has advantages of high rate of quantity and price.It can be used in some special situations and has much marker potential.We also elaborate the circuit modules and software flow diagram of the system.
SPCE061A; speech recognition; DHMM; isolated word
TN108.1
ADOI:10.3969/j.issn.1674-8085.2015.02.012
1674-8085(2015)02-0048-06
2014-01-08;修改日期:2014-12-10
井冈山大学科研计划项目(JZ10006)
*帅晓勇(1977-),男,江西新干人,讲师,硕士,主要从事信息处理、语音识别等方面的研究(E-mail: shuaixiaoyong@jgsu.edu.cn);
陶黄林(1981-),女,湖北黄梅人,讲师,主要从事最优化理论研究(E-mail:jgsxythl@126.com);
吕敬祥(1977-),男,湖南邵阳人,讲师,硕士,主要从事射频识别、无线传感器网络等方面的研究.
