基于大数据混沌特性的分区域异常数据挖掘
2015-10-10郑羽洁李茜
郑羽洁,李茜
(广西经济管理干部学院 计算机系,广西 南宁 530007)
0 引言
随着网络技术的快速发展,导致大数据环境下的网络犯罪活动逐渐增多,使得大数据环境下的异常数据量增加[1-3]。因此,寻求有效的大数据挖掘方法,对于确保大数据环境下相关系统的安全性具有重要意义[4-6]。当前的大数据挖掘方法大都依据已知的异常特征进行大数据挖掘,降低了大数据挖掘的可靠性和效率,使得处理大数据的开销增加,导致大数据总体的可用性和性能降低。因此,如何在不干扰大数据性能的情况下,分析不同区域大数据失效发生率、概率分析以及调整方案,成为当前大数据挖掘领域重点分析的方向[7]。
在大规模的数据挖掘中,海量数据对现有的异常数据挖掘效率带来较大困难。如何针对海量数据设计分区域挖掘算法[8]已经成为研究的热点。由于数据量过于巨大,为了减轻硬件的压力,当数据规模超过承载上限时,需要对大数据进行分区。在不具有容错特性的分布式集群环境下,大数据分区的效率与参与挖掘的硬件成反比。因此,海量数据的异常数据挖掘是一项具有挑战性的任务。传统的基于均值聚类的分区挖掘算法受到数据相似性的影响,这类分区挖掘算法在并行过程中会产生较高的通信负载,难以达到很高的并行度。因此,本论文提出了一种基于大数据混沌特性的分区域异常数据挖掘技术,首先证明了分区域异常数据挖掘下的大数据具有混沌特性,设计了混沌性特征提取,并根据混沌特征的聚类分区算法,实现大数据的分区域和异常数据的准确挖掘。
1 大数据中异常数据的混沌特性证明
大数据的来源通常由地理位置不同的运算节点的软件、硬件通过不同的采集方式产生。在相同的环境下,大数据中异常数据的出现会造成数据在分区过程出现异常特征循环等现象。一旦出现数据异常,现有的数据分区过程会被重试、替换、局部重构,导致大数据中的异常数据随机性成分增加。增加的异常数据在分区过程同正常数据间的对立性,形成数据之间的高度随机性纠缠,也就是伪随机过程,这种特征可通过数学中的混沌性来进行描述。
大数据在异常前期的混沌性产生原因如下:
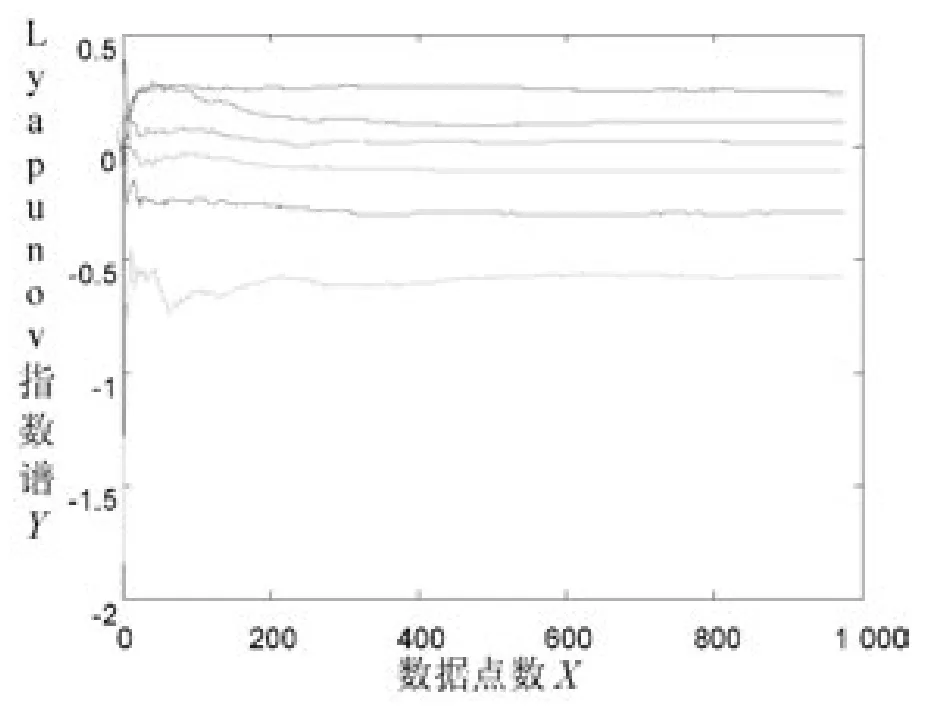
图1 大数据异常数据序列Lyapunov指数谱
(1)大数据之间本身具有确定性和独立性,如果数据突出出现异常会导致大数据呈现随机与非随机的特征,则出现混沌性;
(2)大数据出现异常数据时,数据在相关的区域中,同原始数据状态具有较强的关联性;
(3)数据混沌特征是大数据出现异常的先期评估标准。
证明大数据中出现异常数据有混沌性,可通过数据序列的最大Lyapunov指数是否大于0进行验证。大数据中出现异常数据时,采用Matlab对异常数据进行Lyapunov指数图仿真实验,X轴表示异常数据出现的点数,Y轴为计算的lyapunov指数,结果用图1描述。
分析图1可得,该异常数据序列的最大Lyapunov指数大于0,进而证明大数据中在出现异常数据时,具有混沌性。
2 异常数据存在时的混沌特征采集
混沌特征是大数据中存在异常数据的特征,并可作为挖掘异常数据的一个特征,该特征符合波动规范和数据内部关联性,可作为唯一区分特征进行提取,不必进行多次校验。因此,可在海量大数据序列中获取描述大数据异常特征的混沌数据特征关联,完成异常特征的采集,得到大数据异常分析的数据集,过程为:
将大数据中的异常数据映射成一组概率密度函数,将该组概率密度函数作为划分到不同分类频点内的使用概率。通过概率分析形成可描述数据显著混沌特征的随机数序列,采集混沌特征数据。
异常数据符合概率密度随机调频需求,如果大数据中的异常数据序列为x(n),τ表示分析误差。可对数据进行重构,重构映射的m维相空间中,可产生m维矢量,如式(1)所示:

其中,n=1,2,…,N,在重构数据映射的m维相空间内,采集一维数据矢量Xn,其在相空间内用点描述,与其距离最小的点用Xη(n)描述,将欧氏距离当成两点的距离尺度。
在大数据异常数据序列映射相空间内,随着m增加到m+1时,相空间内点同与其距离最小点间的距离用式(2)描述:

设置分类异常数据为Qs,原数据为Q0,对比分析两种数据的差异S,评估异常概率分析映射分类是否正确,且有:
对比2组患者生活质量以及身体功能,研究组生活质量(42.45±5.45)分,身体功能(43.85±5.89)分,参照组生活质量(33.45±4.89)分,身体功能(34.12±5.01)分,数据对比t值为6.9530,p值为0.05、t值为7.1181,p值为0.05,研究组评分高于参照组患者,组间对比具有显著性差异(P<0.05)。

其中,〈Qs〉表示N批概率分析映射数据的评估统计量值均值,σs表示N批概率分析映射数据的判别统计量值的标准差,则有:

通过Sigma检验S取何值时原数据是随机的,设置不同概率分析映射异常数据的Qs值的概率分布为正态分布,则有:

优化异常数据分类模型概率分析置信区间与拒绝区间,也就是p(Qs)~(Qs)曲线,要否定概率分析映射分类,应确保S足够大,使Qs的分布远离Q0。当置信度为96%时,拒绝概率分析映射分类的机会为α=4%,通过相关判断可得:
(1)S≥1.50概率分析映射分类按照95%概率不成立,原异常数据为具备混沌数据特征;
(2)S<1.50概率分析映射分类成立,原异常数据不是混沌特征数据。
混沌性特征采集的源代码如下:


3 挖掘算法的设计
3.1 大数据的聚类分区过程
在准确提取了混沌特征后,可将大数据集分成合理的数据分区,增强大数据的异常数据挖掘能力。先从全部序列中采集原始的n个数据序列,将其划分成n个簇{P1,P2,…,Pn},其中n表示大数据应划分的区域数,初始化全部簇质心Cj(j=1,2,…,n),运算各项关联权值,将其序列依次划分到n个簇内,运算序列Si到各簇质心Cj的相似函数Sim(Si,Cj),将Si分配到Sim(Si,Cj)值最小的簇Pj内,分配后应调整新簇Pj、簇质心Cj和各项的关联权值。
3.2 异常数据挖掘
对大数据进行分区域和异常数据的混沌相关特征进行提取后,运用优化的BP神经网络方法,结合遗传算法设计挖掘模型。该挖掘算法的具体过程如下:
(1)初始化数据集,通过二进制的方法,对大数据分区域的混沌特征进行权值编码。大数据分区域中的个体混沌特征可以用相应类别的权值表示,设某一原始权值集及其最大进化次数。
(2)设计适应度函数,在该函数中获取最小值。
(3)解码混沌特征的权值,获取混沌特征的权值,如果权值满足规范要求或者权值等于最大进化次数,则转向过程(7);否则,转向过程(4)。
(4)通过遗传算法的交叉与变异功能,获取神经网络的新个体。
(5)标识具有最优适应度的个体,避免这些个体进行交叉与变异操作。
(6)利用优化的BP神经网络方法对拥有最优适应度的个体进行操作,同时运行步骤(2)。
(7)算法结束,得到神经网络中拥有最优权值的个体,也就是待挖掘的大数据中的异常数据。源代码如下[9]:


4 实验分析
为了对本文方法的性能进行测试,需要进行相关的实验分析。分别在两种不同的大数据集上,对本文方法与传统方法(循环迭代分区挖掘算法)进行对比实验。下面给出本实验所涉及到的两个大数据集,Set是模拟数据集,包括两个大小为25.2 MB的分区,Cslogs为实际数据集,包括两个大小为6.22 MB的分区。
当输入数据量一定时,依据最小支持度的改变量,对本文方法与传统方法的性能进行比较。随着支持度的减小,符合条件的频繁模式逐渐增加,挖掘频繁模式所耗费的时间也随之增多,对于频繁模式挖掘算法而言,支持度的适应能力是一个重要指标。
图2描述的是本文方法和传统方法在Set数据集上运行时间的比较结果,最小支持度从0.03降将至0.01。从运行效率的角度分析,本文方法所需的运行时间明显低于传统方法。
图3描述的是本文方法和传统方法在Cslogs数据集上运行时间的比较结果,最小支持度从0.1降至0.05。从运行效率的角度分析,本文方法的性能明显优于传统方法。实验结果表明,本文方法可以有效解决传统方法在大数据集上进行挖掘时出现的内存消耗大的问题。
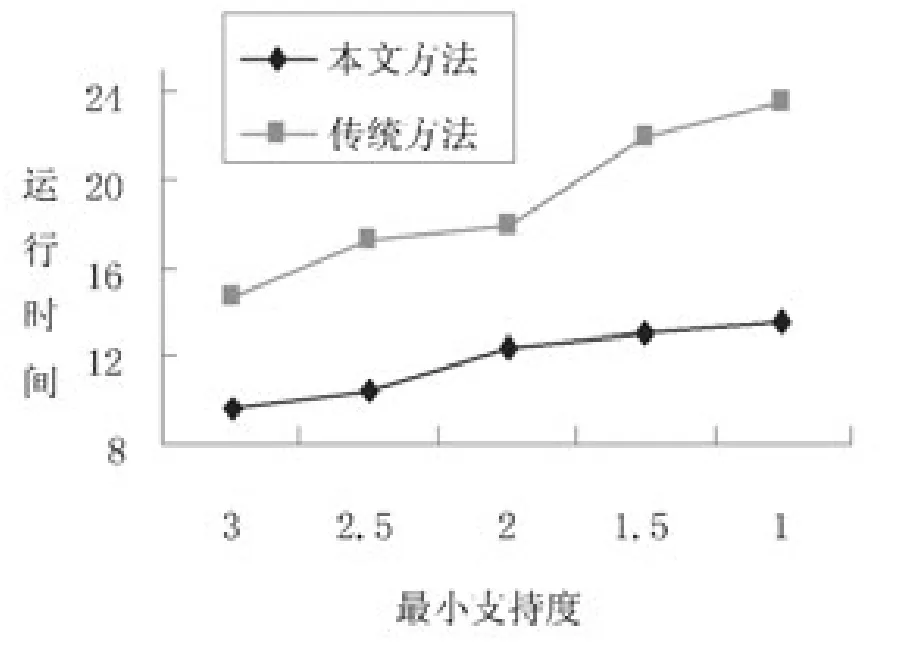
图2 在Set数据集上两种方法的运行时间比较
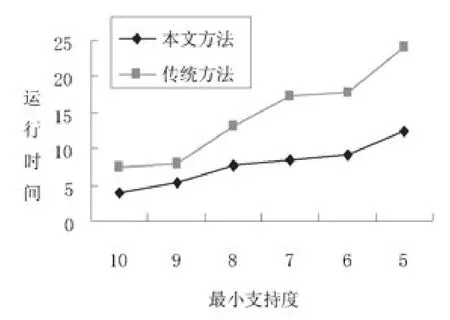
图3 在Cslogs数据集上两种方法的运行时间比较
图4描述的是本文方法和传统方法在不同数据集大小下测试的结果。分析图3可知,两种方法的运行时间曲线均随数据量的增加逐渐增加,但较传统方法而言,本文方法的曲线增长较为缓慢,同时随着数据量逐渐增加,与传统方法运行曲线之间的距离越来越远。说明本文方法能够更好的适应大数据集。
图5描述的是本文方法和传统方法在不同维数下的测试结果,当前数据量取6000。分析图5可知,本文方法运行时间曲线比传统方法增长缓慢。在低维状态下,数据点相对集中,通过微单元可高效完成数据的处理;在高维状态下,数据点相对分散,稀疏单元相对较多,与传统方法相比,本文方法可更加有效地增强算法的运行效率,更好地适应高维大数据的挖掘。
5 结论
本文提出了一种基于大数据混沌特性的分区域挖掘技术,证明了分区域异常数据挖掘下的大数据混沌特性,对分区域异常数据挖掘下的大数据混沌特性进行分类和采集,获取大数据在异常早期的数据特征、波动规范和数据内部关联性,在随机性数据序列中获取描述大数据异常特征的混沌数据特征关联,完成大数据混沌特征的采集,采用聚类分区算法实现大数据的分区划分,得到可降低局部频繁序列的大数据分区结果,提高大数据分区效率,通过改进BP神经网络检测方法,实现大数据分区域异常数据的准确挖掘。实验结果说明,所提方法可对不同大数据集进行准确挖掘,具有较高的鲁棒性和效率。

图4 在不同数据集大小下两种方法的运行时间比较
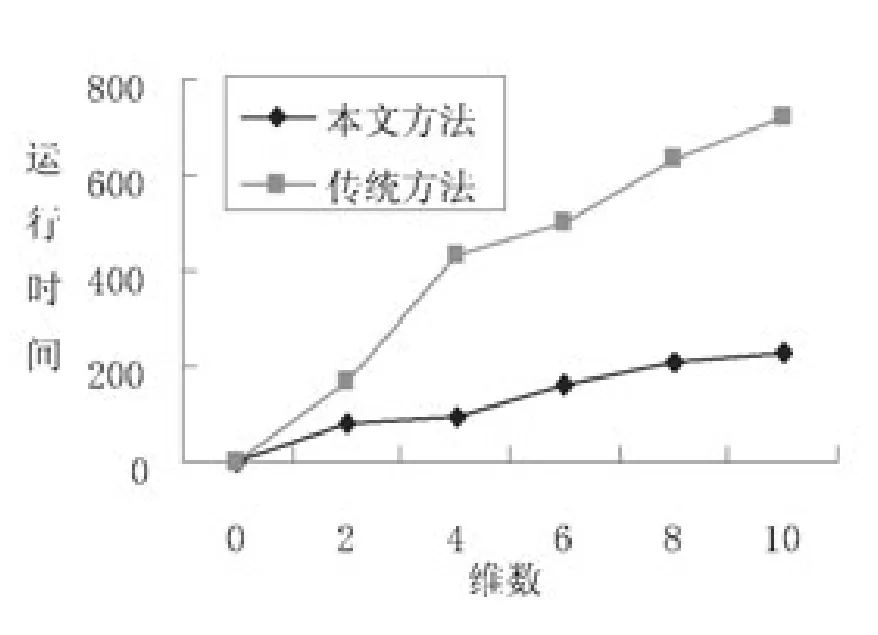
图5 在不同维数下两种方法的运行时间比较
[1]李志云,周国祥.一种基于MFP树的快速关联规则挖掘算法[J].计算机技术与发展,2007,17(6):94-96.
[2]相征,张太镒,孙建成.基于混沌吸引子的快衰落信道预测算法[J].西安电子科技大学学报,2006,33(1):145-149.
[3]刘芳.基于离散反馈控制的TCP-RED网络混沌特性研究[J].西安电子科技大学学报,2005,32(6):977-981.
[4]刘兴涛,石冰,解英文.挖掘关联规则中Apriori算法的一种改进[J].山东大学学报(理学版),2008,43(11):67-71.
[5]罗赟骞,夏靖波,陈天平.网络性能评估中客观权重确定方法比较[J].计算机应用,2009,29(10):2624-2626.
[6]刘曲明,顾桔.网络性能分析评价方法及其计算机仿真方法讨论[J].计算机仿真,2000,17(1):53-57.
[7]周水庚,周傲英,曹晶.基于数据分区的DBSCAN算法[J].计算机研究与发展,2000,37(10):1153-1159.
[8]Yang Jingrong.ZhaoChunyu.Study on the Data Mining Algorithm Based on Positive and Negative Association Rules[J].Computer and Information Science,2009,2(2):103 -106.
[9]赵鹏.海量高维数据下的频繁项目集挖掘算法研究[J].计算机应用与软件,2012,29(7):150-153.
