基于树状结构的语义相似度算法改进
2015-09-26王朕陆能枝
王朕,陆能枝
(上海海事大学信息工程学院,上海 201306)
基于树状结构的语义相似度算法改进
王朕,陆能枝
(上海海事大学信息工程学院,上海201306)
0 引言
概念相似度在信息检索、信息抽取、机器翻译、词义排歧、文本聚类、文本映射等方面都有着广泛的应用,因其突破了传统信息检索思想的束缚,对信息进行语义匹配[1]。在大数据背景下,语义检索在各类电子商务平台的应用也愈加广泛,避免出现“信息孤岛”[2]。语义检索对用户输入的信息进行语义分析、推理和扩展,并形成扩展后的语义查询,最终获得相应的信息反馈。在上述过程中需要进行语义相似度计算,来提高信息查询的准确率。本文在分析传统语义相似度计算方法的基础上,进行了改进,并验证了该算法的有效性。
1 基本概念
本体(Ontology)是一个五元组的结构O={C,R,Hc,Rel,Ao}。其中C指概念的集合,R指关系的集合,Hc指概念间的分类关系,Rel指概念间的非分类关系,Ao指本体公理。
如果两个实体概念所拥有的相同属性越多,则说明它们的语义相似度越高,同样对于两个概念的某一个相同属性,如果其拥有越多的相同属性值,其语义相似度也越高。
对于两个实体元素A,B,用sim(A,B)表示,之间的语义相似度,形式上,语义相似度计算应满足[7]:
(1)语义相似度的值为[0,1]区间中的某个实数,即sim(A,B)∈[0,1];
(2)如果两个概念是完全相似的,则语义相似度为1,即sim(A,B)=1,当且仅当A=B;
(3)如果两个概念没有任何共同特征,那么语义相似度为0,即sim(A,B)=0;
(4)相似关系式对称的,即sim(A,B)=sim(B,A)。
2 传统的语义相似度计算模型
概念结点间的距离与语义相似度具有很大的关系,在本体中,两个概念结点之间的语义距离越大,它们之间的相似度就越低;相反,两个概念结点之间的语义距离越小,它们之间的相似度就越大。假设两个概念结点为A,B。sim(A,B)表示两个概念结点之间的相似度,sim(A,B)为0表示两个概念结点不相似;为1表示两个概念结点完全相似,因此,0≤sim(A,B)≤1。dis(A,B)表示两个概念结点之间的距离。由于两个结点之间的距离与它们的相似度存在反比关系,所以可得到下列公式。其中,为调节因子。
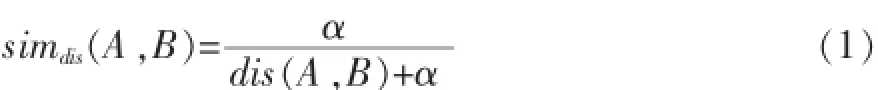
概念深度是指概念结点在树状结构中所在的层数,即与根节点最短路径所包含的边数。在树状结构中,每一层的概念都是上一层的细化,即概念结点所在层数越大,它的概念就越详细。所以,深度较深处的概念结点之间的相似度比层数较低的结点之间的相似度大。也就是说,两个概念结点的深度之和与概念之间的相似度成正比。而两个概念结点之间层数相差越大,它们之间细化程度的差异越大,则概念结点之间的相似度越小。根据上述可得到以下公式[3]。
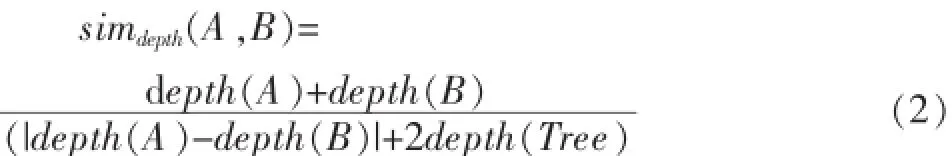
其中,depth(i)表示结点所在深度。depth(i)=depth (parent(i))+1。假设根节点的深度为1,且depth(parent (i))是的父节点的深度。

结点密度是指概念结点所拥有的兄弟结点的个数。某个结点的分类越细,密度越大,该结点分类越具体,它的直接孩子之间的语义距离越小,相似度就越大。所以两个结点的共同祖先结点的孩子结点越多,它们之间的相似度就越大。因此得到如下公式。

其中wid(B)表示结点i的兄弟结点的个数。LCN表示最小公共结点(Least Common Node)。
(1)语义重合度是指两个概念结点所具有的相同概念的个数。表示概念在其祖先结点上的相似程度,如果两个概念结点所具有的相同的信息越多,它们之间的重合度就越大,语义相似度也越大,反之亦然[4]。从而得到如下公式。
由于年轻时对事业的追求和奋斗,当人们进入中老年时期后,身体各方面机能都在逐渐衰退,骨骼逐渐僵硬、灵活性差。人们可能刚从忙碌、快节奏的生活中解放出来,此时打乱了身体机能的运行规律和节奏,不利于身体健康,进而诱发中老年人的消极情绪。而舞蹈的出现,则能驱散中老年人的消极、负面情绪,有益身心,通过运动排汗的形式锻炼身体,提高身体的灵活性,还能消磨中老年人的无聊时光,养成积极、乐观的心态。

其中,U(i)表示结点到根节点所有结点的集合。
(2)还有一种方法是,在实际中两个结点不同的概念越多说明它们之间的相似度越小,所以两个结点不同概念与其相似度成反比[5]。所以有如下公式。
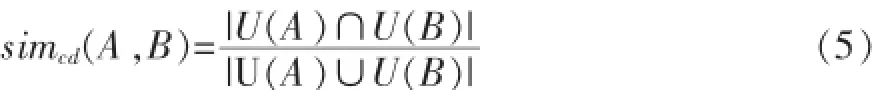
3 改进的语义相似度计算算法
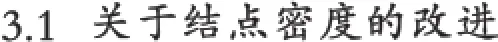
公式(3)具有的缺点:在有些极端情况可能出现simdensity(A,B)>1的情况。不符合上面所提到的语义相似度的条件。
例如,在如图1中,节点w12和w13中logwid (w12)和logwid(w13)都为0,所以,相似度就是无穷大,因此不符合0≤sim(A,B)≤1。
因此,为了避免上述问题,本文将计算方法改为如下公式所示。
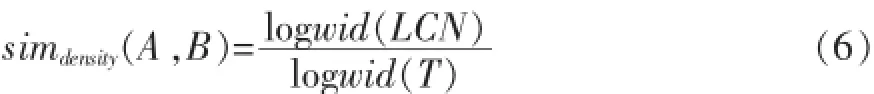
其中,wid(T)=max(wid(i)),表示在此树中宽度最大的结点的宽度,即兄弟节点个数。利用本文的此方法可得,处于区间[0,1],计算结果符合条件。w12和w13的相似度计算结果为simdensity(w12,w13)=0.625。
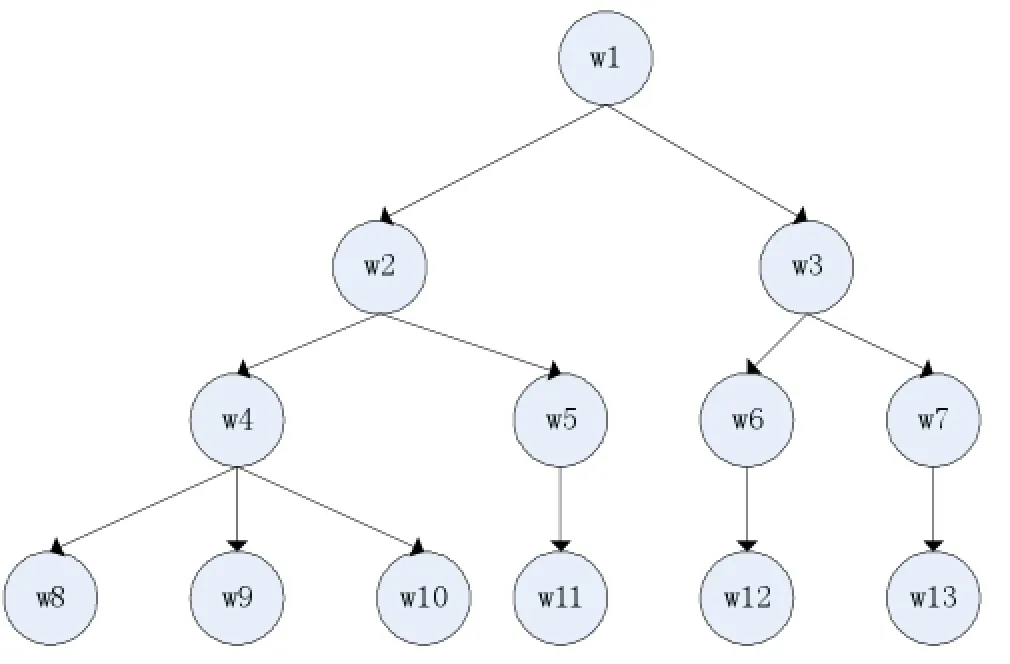
图1 一个树状图例
在公式(4)中,缺点是|U(A)∩U(B)|相同的情况下,无论它们属于哪一层,结果都是一样的,这是不符合常理的。
(2)在公式(5)中也体现出问题。针对图1,每个概念结点之间的相似度计算结果如下表格1所示。
然而在这个计算方法中,
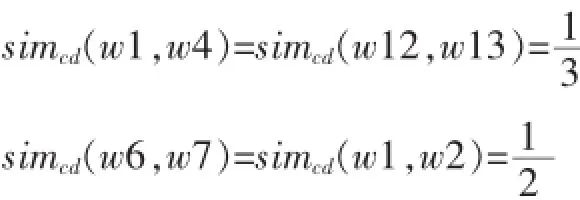
这明显不符合常理,也就是说有比较大的误差,实际中,应该是:
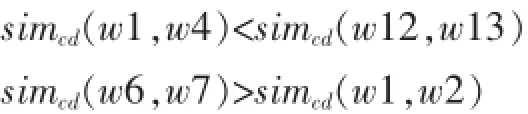
所以,现本文结合上诉两种情况的公式得到如下公式。
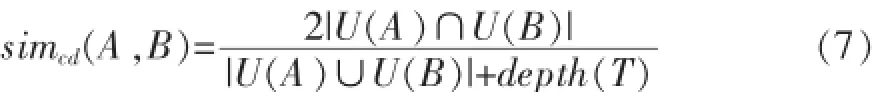
而新公式得到的结果为如表2所示:
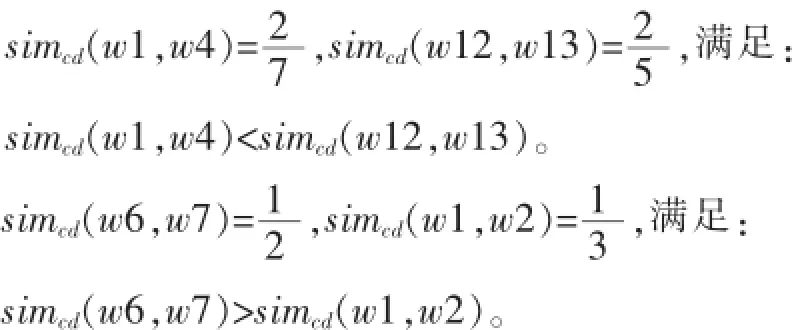
这两个计算结果都与主观观点一致,符合实际。所以,在重合度相似度计算算法中新的公式更适合实际。

表1 根据图1使用传统算法得到的每个结点之间的相似度

针对以上四种考虑因素:路径距离、结点深度、结点密度、语义重合度,综合计算得到如下公式。
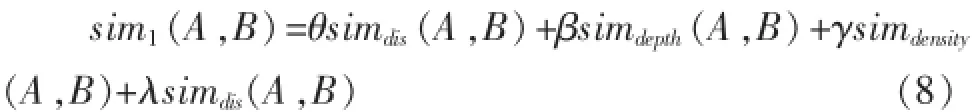
其中,θ+β+γ+λ=1,是四个调节因子。
4 实验及分析
选取文献[8]中使用的例子如图2,提取其树状结构中的一部分进行计算验证。
选取该树状结构中的“4主机”概念结点来计算与该树状结构中其他概念结点之间的语义相似度值,假设参数值为α=3,θ=0.25,β=0.25,γ=0.25,λ=0.25,计算得到的部分结果如表3所示,在原计算方法中sim(主机,软件)=sim(主机,系统软件),这是不符合常理的,而在本文算法的结果是sim(主机,软件)≠sim(主机,系统软件),这是符合常理的,所以本文算法具有优越性。
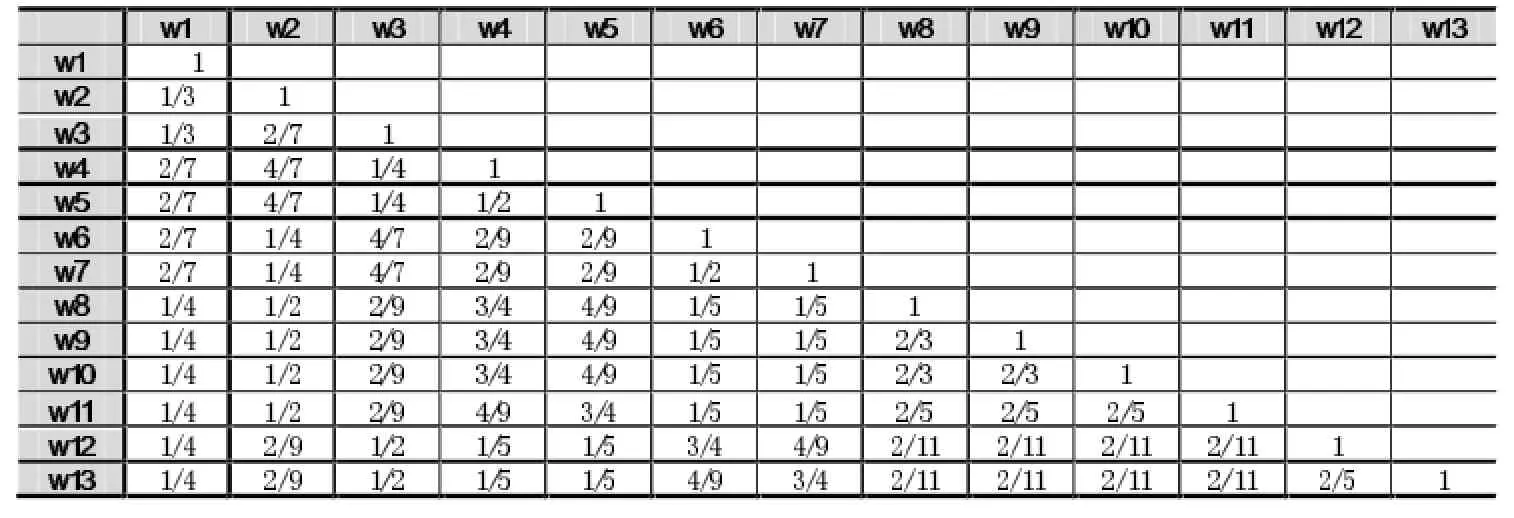
表2 针对图1使用改进的算法得到的每个结点之间的相似度
5 结语
本文针对树状结构的本体领域,利用树状结构的各种特点,提出了概念之间的语义相似度计算。其中不仅考虑到路径距离、结点深度、结点密度、语义重合度等因素,并在其中的密度和语义重合度进行了改进,还添加了一些调节因子。通过实验证明,该算法更符合实际且更严谨。
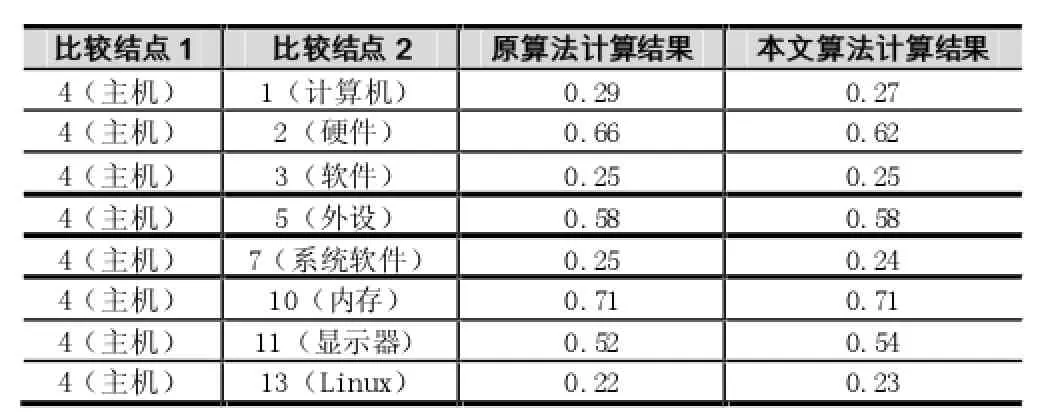
表3 概念结点4(主机)与其他结点的语义相似度实验结果比较
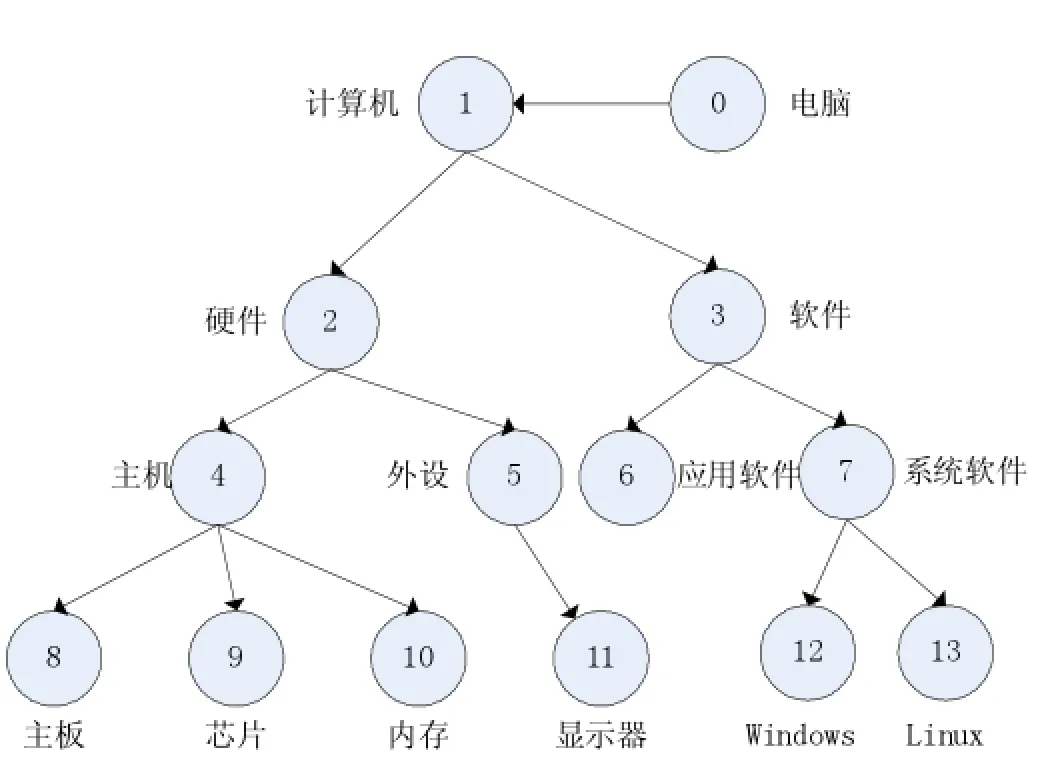
图2 一个简单的计算机树状结构图
[1]安建成,武俊丽.基于语义树的概念语义相似度计算方法研究[J].微电子学与计算机,2011
[2]刘双印.电子商务智能推荐系统中基于领域本体的案例检索算法[J].计算机应用,2010
[3]周书锋,陈杰.基于本体的概念语义相似度计算[J].情报杂志,2011
[4]蒋溢,丁优,熊安萍,王化晶.一种基于知网的词汇语义相似度改进计算方法[J].重庆邮电大学学报,2009
[5]丁健,范太华.一种综合的概念语义相似度计算方法[J].电脑知识与技术,2011
[6]杨春龙,顾春华.基于概念语义相似度计算模型的信息检索研究[J].计算机应用与软件,2013
[7]赵捧未,袁颖.基于领域本体的语义相似度计算方法研究[J].科技情报开发与经济,2010
[8]韩欣,攀永生,马春森,杨和平.基于树状结构的语义相似度计算方法分析[J].微电子学与计算机,2012
[9]李昊迪.语义相似度的混合计算方法[M].哈尔滨工业大学,2012.
[10]张永攀,毕福伟等.电子商务个性化推荐系统的应用[J].辽宁石油化工大学学报,2013.
Semantic Similarity;Tree Structure;Node Density;Semantic Coincidence Degree
Improvement of Semantic Similarity Algorithm Based on Tree Structure
WANG Zhen,LU Neng-zhi
(College of Information Engineering,Shanghai Maritime University,Shanghai 201306)
1007-1423(2015)17-0027-04
10.3969/j.issn.1007-1423.2015.17.006
王朕(1991-),男,安徽阜阳人,硕士研究生,研究方向为电子商务与信息系统
2015-04-16
2015-05-25
在计算基于本体领域的树状结构的概念语义相似度时,从路径距离、结点深度、结点密度、语义重合度等角度讨论语义相似度计算方法,其中针对结点密度的影响和语义重合度的影响部分进行改进。
语义相似度;树状结构;节点密度;语义重合度
陆能枝(1959-),男,工学博士,研究方向为决策支持及其在港航信息工程中的应用、电子商务、地理信息及物流信息化技术等
Based on tree structure of domain ontology,discusses the traditional semantic similarity calculation method from the path distance,the density of nodes depth,concept overlap degree,and makes improvement including the node density and semantic coincidence degree.
