基于CART的人力资源管理研究
2015-09-14吴丰,胡蕙,胡芳
吴 丰,胡 蕙,胡 芳
(1.湖北航天计量测试技术研究所,湖北 孝感 432000;2.航天重型工程装备有限公司,湖北 孝感 432000)
基于CART的人力资源管理研究
吴 丰1,胡 蕙1,胡 芳2
(1.湖北航天计量测试技术研究所,湖北 孝感 432000;
2.航天重型工程装备有限公司,湖北 孝感 432000)
未来是信息化的时代,对高技术人才的需求越来越紧迫,企业管理者所制定的企业发展战略的有效执行需要高素质人才的支撑,企业人力资源管理逐步从过去的开放式管理模式逐步向定量评价管理发展,本文根据Gini指数建立了人力资源分类树CART模型,为企业建立了一套信息评价、过滤和供给体系,通过量化评价的方式合理安排人员工作,提升了人力资源管理效率,促进企业战略的顺利实施。通过测试表明,该模型能以较简单的量化评价模式为人力资源管理者提供参考意见。
人力资源;数据挖掘;CART模型;发展战略
人力资源审核即是衡量企业对人力资源的掌握程度的重要标志,也是评估管理质量、水平和效率的重要依据。对于一个有近千人的企业来讲,人力资源数据量是庞大的,从表面上看这些数据只是些毫不相关的数字,但从这些海量的数据中,却可以提炼出存在的关系和规则,可根据现有的数据预测未来的发展趋势。
对于人力资源管理而言,一个企业人力资源管理是和一个企业的经营战略、组织结构体系与文化价值观紧密联系的,具有独特个性。一个成功企业的人力资源管理往往是最难复制和模仿的,如何通过人力资源管理来取得竞争优势成为了企业竞争的重要部分。
本文是以某企业人力资源数据为依据,建立人力资源数据仓库,利用决策树中的CART算法对所建立的数据仓库进行深入分析,得出有用结论。CART决策树算法是目前应用最广泛的预测技术,它主要由决策节点、分支和叶子3部分组成。对数据集合中具有最大信息字段创建决策树节点,并根据其节点字段的差值建立决策树分支。在每个分支中重复上述过程,逐步建立树的下层节点和分支,最终可以生成反映一定规则的决策树。
1 数据挖掘的发展历史及国内外现状
随着数据库技术的日益成熟,以及在相关领域的应用,人们收集了海量的数据。面对大数据的挑战,传统的数据分析方法难以应对海量数据的挑战。为了有效的对数据隐含的信息进行分析,需要有新的数据分析手段。与此同时,人工智能技术取得了跨越式的发展。经历了博弈时期、自然语言理解、知识工程等阶段的探索与发展,人工智能在机器学习领域取得了重大成就。因此,利用机器学习的方法来对数据库的数据进行高效分析,发现大量数据背后隐含的知识,称为知识发现(Knowledge Discovery in Databases,KDD)。数据发现涉及机器学习、模式识别、高性能计算、统计学等多个领域。将海量数据中提取有效的、具有潜在价值的知识应用于信息管理,科研等领域,为企业的发展提供决策。
知识发现(KDD)这个术语最早出现在美国召开的第十一届国际人工智能联合会议。随着人工智能领域的飞速发展,会议的连续召开,原本的专题讨论会已经发展成为国际性的学术会议。通过多学科之间的互相融合,从原本的多策略多技术转变为策略与技术之间的集成,发现方法转向了系统应用。
2 CART算法
分类回归树(Classification And Regression Tree,CART)算法,它采用自上而下的递归方法对数据进行归纳,从无次序、无规则的数据中获得相应的分类规则,尤其对非数值性数据有着较好的处理能力。本文将CART算法应用于人力资源分析中,起到辅助决策者分析的作用。CART算法是一种二分递归分割技术,将新样本划分为两个子样本,并使得生成的每个非叶子结点都有两个分支,因此CART决策树是结构简洁的二叉树。由于CART算法构成的二叉树在每一步的决策时只有2个分支,即使一个分段取有多个值,也只能把数据分为两部分。而构建CART决策树主要分为两个步骤。
3 将样本递归划分进行建树过程
3.1用验证数据进行剪枝
3.1.1CART模型建立
CART算法核心是对每个节点上要测试的属性进行选取,其划分点是一对连续变量属性值的中点。假设M个样本的集合一个属性有m个连续的值,那么则会有m-1个分裂点,每个分裂点为相邻两个连续值的均值。每个属性根据能减少的杂质的量来进行排序划分,而减少量为划分前减去划分后的每个节点的杂质质量所占比率之和。而杂质度量方法常用Gini(Gini Coefficient)指标,假设一个样本共有C类,则一个节点A的Gini不纯度可定义为:
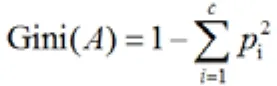
其中Pi表示属于i类的概率,当GiniA=0时,所以样本属于同类,所有类在节点中以等概率出现时,Gini(A)最大化,此时:
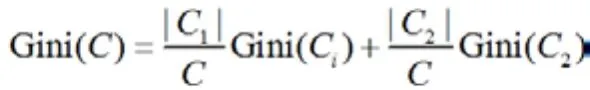
如果当前节点的所有样本都不属于同一类或者只剩下一个样本,那么此节点为非叶子节点,所以会尝试样本的每个属性以及每个属性对应的分裂点,尝试找到杂质变量最大的一个划分,该属性划分的子树即为最优分支。
3.1.2CART树剪枝
通过CART刚生成的决策树记为T0,然后从T0的底端开始剪枝,直到根节点。在剪枝的过程中,计算损失函数:
Ca(T)=C(T)+a|T|
a≥0,C(T)为训练数据的预测误差,|T|为模型的复杂度。对于一个固定的a,在T0中一定存在一颗树Ta使得损失函数Ca(T)最小。将a在其取值空间内划分为一系列区域,在每个区域都取一个a然后得到相应的最优树,最终选择损失函数最小的最优树。其中CART剪枝算法步骤如下。
(1)设K=0,T=T0,a=+∞
(2)自下向上地对各内部节点进行遍历,计算C(Tt),|Tt|及g(t),得到:
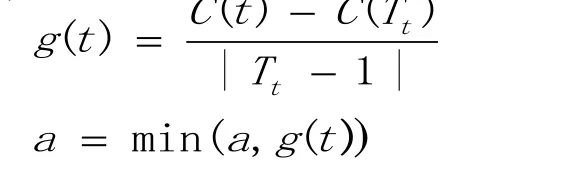
(3)自上向下访问各内部节点t,若g(t)=a,则进行剪枝,并对t以多数表决的方式决定其类,得到树T。
(4)若T不是由根节点单独构成的树,则重复步骤(3)得到一系列的子树。
(5)最后使用交叉验证的方式从子树序列中选取最优子树。
3.2人力资源数据测试研究
3.2.1数据选择
数据选择是指从数据本身和发现目标出发,寻找依赖于发现目标特征数据的过程。通过数据选择有利于减少数据量,缩小目标数据范围,从而在保证数据原貌的前提下对数据进行筛选。通过数据抽取使得数据具有更加明显的规律和特征。通过对人才综合能力定性分析,构成了由知识水平、思想个性、基本素质、个人能力和业绩成果5个基本要素组成的人才评价指标。经过选取有用的数据,去掉原数据其中噪声数据和一些无关的数据,建立相对应的数据表(见表1)。
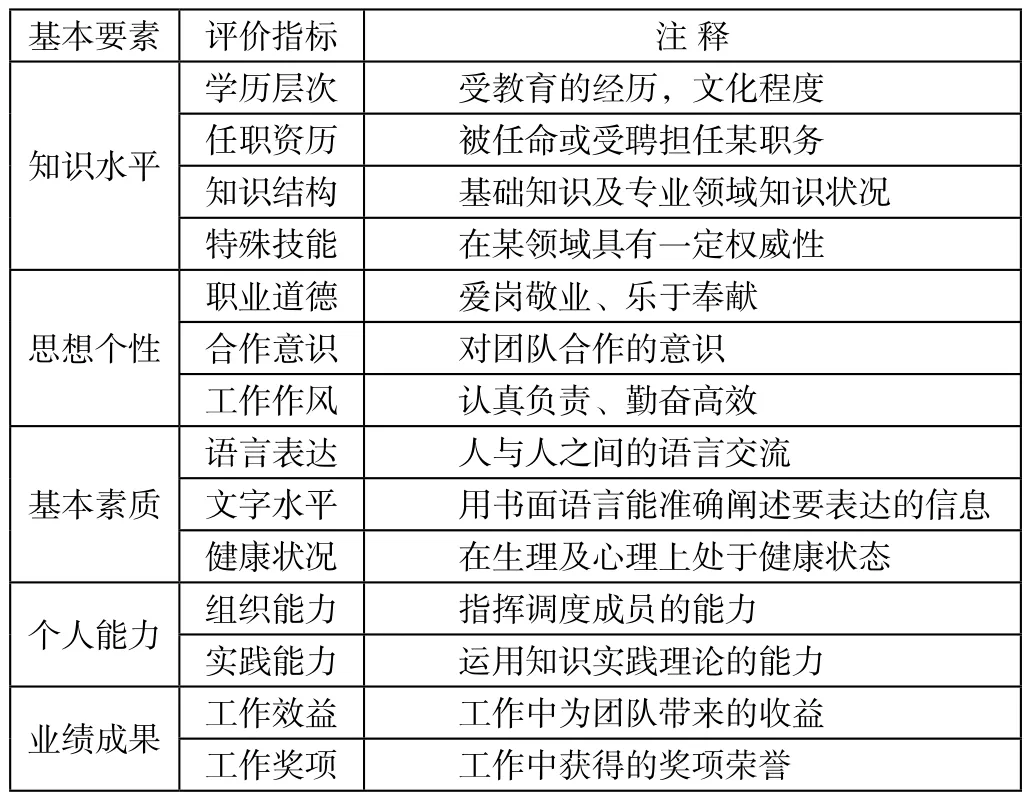
表1 人才标准评价指标表
3.2.2数据规范
针对异构数据源中数据的不规范性、重复性和不完整性等问题进行清理,达到将数据去除噪声和纠正错误的目的,提高数据质量,符合分析要求。因此,数据规范需要对数据做出以下操作。
员工信息由唯一编号代替。分别对5个基本要素进行评价,其中知识水平对应A-D(A学历层次,B任职资历,C知识结构,D特殊技能),思想个性对应E-G(E职业道德,F合作意识,G工作作风),基本素质对应H-J(H语言表达,I文字水平,J健康状况),个人能力对应K-L(K组织能力,L实践能力),业绩成果对应M-N (M工作效益,N工作奖项)。
每项要素每当达成一个评价指标便累计加一,最后合计当前要素点的总分。
分为三种类型的人才,分别为类型ω1、类型ω2和类型ω3。
通过对企业提供的数据进行抽样,选取其中20名员工进行测试,按照数据规范及评价指标表的要求进行,得到测试数据表如表2所示。
利用Matlab软件,构建人力资源分类树CART模型,利用训练样本所得到的决策树见图1。
4 结 语
本文以某企业为例,提出了利用数据挖掘技术来克服在当前的人力资源管理中遇到的问题,提高管理质量。在具体应用中,主要利用的是数据挖掘中的CART算法,详细介绍了CART算法在人力资源分析挖掘中的全过程。在CART树模型的建立过程中,应用算法对不同类型的人力资源进行分析,找出影响的潜在因素,为企业管理者有针对性提高管理质量提供有利的数据支持,使员工能够较好地保持良好的工作状态,从而为企业管理者提供了决策支持信息,促使更好地开展管理工作,提高管理质量。
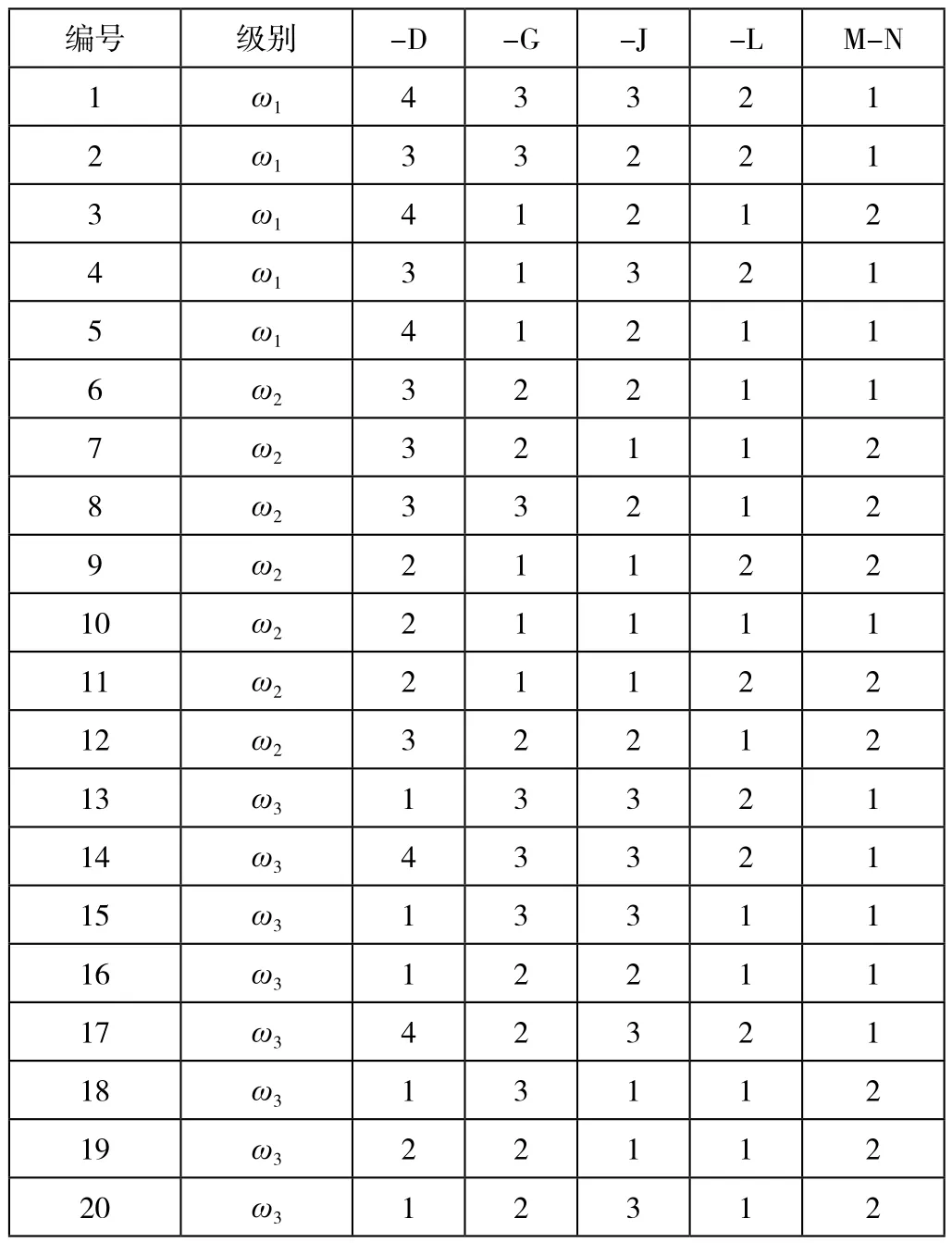
表2 测试数据表
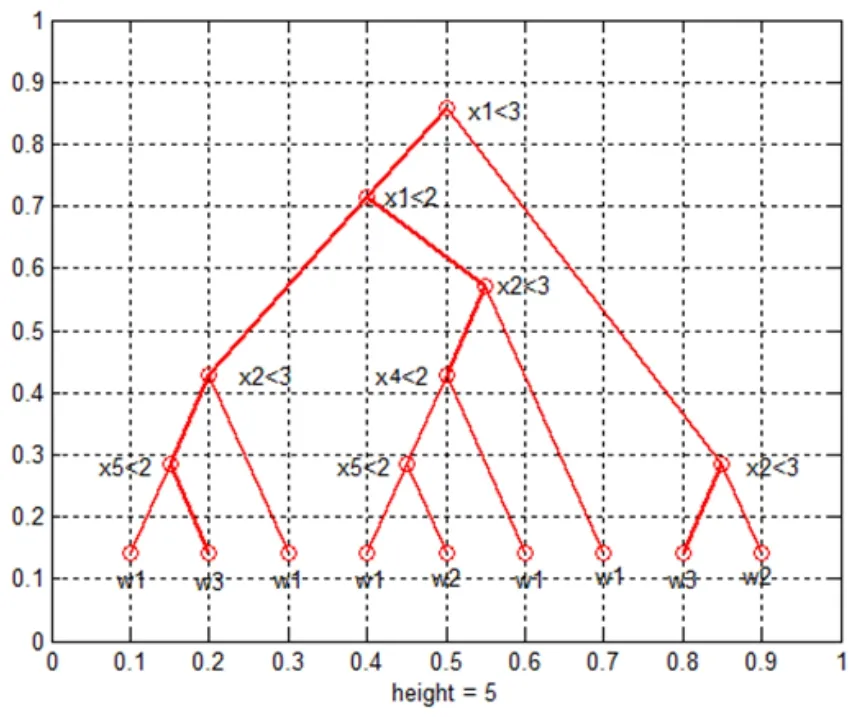
图1 生成的CART树
主要参考文献
[1]王董雨.如何构建企业人力资源发展战略模型[J].上海汽车,2005(3).
[2]陶宇.人力资源管理团队绩效评价与对策——基于人力资源审核模型[J].企业经济,2013(3).
[3]韩起云.一种基于CART算法的移动通信客户流失预测模型[J].科技通报,2012(2).
[4]骆盈盈,王柯玲,陈川,等.结合递增式学习的CART算法改进[J].计算机工程与设计,2007(7).
[5]邢周凌.高绩效人力资源管理系统的演变与形成——基于中国创业板上市公司的案例研究[J].企业经济,2012(8).
10.3969/j.issn.1673 - 0194.2015.24.101
F272.92
A
1673-0194(2015)24-0123-02
2015-11-19
