基于眼动实验的显著目标检测图像库构建
2015-09-11杨开富尧德中李永杰
高 鑫 杨开富 尧德中 李永杰
(电子科技大学生命科学与技术学院, 成都 610054)
基于眼动实验的显著目标检测图像库构建
高 鑫 杨开富 尧德中#李永杰*
(电子科技大学生命科学与技术学院, 成都 610054)
构建一个合理的显著目标检测标准图像库,探讨图像分割对于显著目标检测的重要意义。首先以Berkeley的BSDS500图像库为基础,通过使用眼动仪记录10位被试观看图片时的眼动轨迹,并结合手工勾画的标准分割图像,构建了一个显著目标检测图像库(含500幅自然图像)。其次,基于gPb-UCM图像分割算法结果,同时引入中央偏置和图像边界先验作为后处理,建立了一个简单的显著目标检测方法。实验结果显示,与以往的二值显著目标图像库不同,本研究为多目标图像提供了每个目标的相对显著水平,可作为更为符合人类感知经验的显著目标检测参考图像。另外,研究发现,基于已有的图像分割算法,并结合简单的后处理就能有效地实现复杂图像中的显著性目标检测(和标准图像的相关系数为0.53),其效果接近现有最优算法的水平(相关系数为0.54),证明了图像分割在显著目标检测中的重要作用。
眼动; 显著目标; 图像分割;图像库
引言
视觉注意是视觉系统感知和处理外界信息的一个重要手段。通过选择性注意机制,视觉系统能够快速地从复杂的自然场景中提取重要信息,从而提高信息处理效率。目前,大量的研究致力于建立计算模型模拟视觉系统的选择性注意过程,并建立类似于视觉系统的目标搜索模型。在图像处理领域,选择性注意模型对于高级的计算机视觉任务(例如目标识别[1]、图像压缩[2]等)具有重要意义。同时,显著性计算模型也被广泛用于医学图像处理[3]。
目前关于视觉显著性的模型研究主要包括两个方面。第一,预测人眼注视点分布。该类研究大多基于底层特征检测和特征整合理论[4-6],建立自底向上(bottom-up)的计算模型。通过提取低分辨率的显著图来预测图像的显著性区域,例如著名的ITTI模型[6]。第二,显著性目标检测。该类任务要求从图像中精确地分割出显著性目标。对于这些模型性能的评价,通常是将模型预测的结果和标准图像库做对比。尽管目前已经有许多可用于测试显著性计算和显著目标检测算法性能的图像库,然而,显著性图像库只提供人眼注视点分布的数据,而没有提供目标信息(如形状);相反,显著性目标检测数据库一般是通过手工勾画得到二值的目标模板作为参考标准,不能表达多个目标或多个区域之间的相对显著性差别[7]。因此,构建一个多目标、多层次的标准图像库将对评价复杂场景的显著性检测算法有重要意义。
此外,目前大多显著性目标检测的方法都是基于局部区域对比。常规的计算方法是首先对图像进行过度分割,然后计算各个小区域之间的特征对比[8]。这些方法强调显著性计算过程,而弱化了图像分割在显著目标检测中的重要性[9]。实际上,图像分割作为一个基础的研究领域,已经提出大量性能优越的分割算法,但这些方法却很少被用到显著性检测中。因此,探讨图像分割在显著目标检测中的作用将为这一领域提供新的思路。
本研究主要包含两方面的内容:一方面以Berkeley的BSDS500标准分割图像库[10]为基础,同时使用眼动仪记录人眼自由观看自然场景时的注视点分布,构建一个同时包含各个目标(或区域)的精确信息以及相对显著程度的标准显著分割图像库,并提供了相关的评价方法。另一方面为证明图像分割在显著性检测中的作用,设计了一个算法,与大多数复杂的显著性检测算法不同,使用效果较好的图像分割算法并结合简单的显著性计算过程来实现显著目标检测的任务。
1 材料与方法
1.1 构建显著目标检测图像库
1.1.1 眼动实验材料和装置
采用Berkeley的BSDS500图像库中的500幅自然图像作为实验材料[10]。对于每幅图像,BSDS500图像库提供了多人手工勾画的图像分割结果。在自行设计的眼动实验中,实验被试者为10名在校大学生,其中男6名,女4名,年龄为22~26岁。被试均签署知情同意书。实验采用Eyelink 2000型眼动仪(SR Research Ltd.,加拿大)记录被试的左眼眼动轨迹。采样频率为1 000 Hz。显示器的分辨率为1 024像素×768像素。实验过程中,被试眼睛正对屏幕中心,离屏幕的距离为71 cm。为减少头动引起的记录误差,被试的下颚和前额放在特制的支架上。实验的刺激程序由Matlab的心理学工具箱编写(Psychotoolbox)[11-12],注视位置由眼动仪自带软件导出,并用Matlab做离线分析。
1.1.2 实验流程
实验一共呈现500幅图片,对于每个被试,图片呈现的顺序是随机的。每幅图片呈现时间为5 s,在这期间,实验者要求被试双眼自由观看图片。在每张图片呈现之前会出现一个“十”字目标,并要求被试注视这个目标。每呈现30幅图片,被试可以有一定的休息时间,按任意键可以继续进行随后的实验。在实验开始和每次休息过后,会启动标准九点矫正程序,以保证精确记录。为了确保被试认真观看每张图片,在500幅图片呈现之后,实验者安排了一个对照实验。具体内容为:实验者从之前的500幅图片中随机选取150张图片,并另外加入150张其它的图片。被试需要识别每张图片是否在之前呈现过,并做相应的按键反应。在被试按键后,当前的图片会立即消失并呈现下一张图片。正确率低于80%的被试数据将会被剔除。
1.1.3 眼动数据分析
通过实验,获得了10名被试自由观看状态下的注视点分布。所有被试在对照实验中的正确率都高于80%,这说明被试在试验中认真地观看了图片。为防止在图片呈现前的中心注视行为对后续图片注视点分析的影响,每张图片的第一个注视点被剔除。利用BSDS500图像库提供的手工勾画分割结果,统计每个分割区域中的注视点密度,注视点密度由所有被试(n=10)观看某幅图片的注视点统计得出。并以此作为该区域显著性的指标。注视点密度较高的区域则认为具有较高的显著性。在BSDS500图像库中,每幅图像都有多人手工勾画的分割图像,本研究基于每个分割图像得到的显著图的平均结果作为最终的分割显著图。这样,可获得500幅自然图像的显著分割图并以此定为标准显著图(ground truth)。该图像库可用于评价显著目标检测算法的性能。
1.2 从图像分割到显著目标检测
1.2.1 基于图像分割的显著目标检测
为探讨图像分割在显著目标检测中的作用,设计了一个简单的实验。本实验主要目的在于探讨基于较好的图像分割结果,加上简单计算是否可以得到较好的显著目标检测结果。检测效果用之前构建的显著目标检测图像库作为评价标准。首先利用效果较好的图像分割算法对图像进行区域分割,然后根据简单的中央偏置先验和图像边界先验信息计算每个区域的显著值,以此获得显著目标检测结果。中央偏置先验和图像边界先验是两个常用的显著性算法后处理方法。中央偏置先验认为图像的显著目标倾向于位于图片中央位置,这是由于在图片拍摄过程中,摄影师偏好于将重要目标放置于图像中央[13];图像边界先验基于类似的思想,认为位于图像边界的像素可以被视为背景像素(非显著目标)[14-15]。因此,简化了显著性计算过程,仅使用中央偏置先验和图像边界先验两个后处理方法实现从分割图像中提取显著目标。
首先利用图像分割算法(gPb-UCM[10])将图像分为不同的区域。针对第i个区域,区域中心坐标为(xi,,yi),记Ri=(xi/H,yi/W)为区域i归一化后的中心点位置(其中H和W分别为图像的高度和宽度),M=(0.5,0.5)为归一化后的图像中心点位置;N=2(H+W)为图像边界像素数量,Ni为第i个区域中位于图像边界的像素数量。那么,第i个区域的显著值可表示为
(1)
1.2.2 显著目标检测的定量评价
与其它的图像库不同,本研究所构建的显著目标图像库里的标准图像不再是二值的目标模板,而每个点都是范围在[0,1]的实数值。所以目前常用的评价方式(如AUC和PR曲线[16])在这里无法使用。为了能利用该图像库对算法结果进行定量评价,我们使用相关系数作为算法性能的定量评价指标[17]。相关系数的计算方式为
(2)
式中,Sm(x,y)和Sh(x,y)分别为模型计算得到的显著图和实验得到的标准显著图,μm和μh分别为Sm(x,y)和Sh(x,y)的均值,σm和σh分别为Sm(x,y)和Sh(x,y)的标准差。ρ为两个图像的相关系数,其值范围为-1~1。ρ=0意味着两个图像之间不相关,即算法效果差;ρ越趋近于1,说明算法得到的结果图与标准显著图越接近。
2 实验结果
2.1 显著目标图像库构建结果
图1 展示了其中一幅图像标准显著图的计算过程,即基于图像库提供的单个人手工分割图和本研究眼动数据得到显著图示例。实验中,将较小的分割区域融合到相邻区域中,以避免产生过多碎片区域。

图1 利用标准分割和注视点分布获取标准显著图。(a)原始图像;(b)手工勾画的分割图像[10];(c)本文实验获取的注视点分布;(d)本研究所得到的标准显著图。其中,亮度越高,代表该区域越显著Fig.1 Obtaining ground truth of saliency map based on the ground truth of segmentation and the human fixations. (a) Input image; (b) The ground truth of image segmentation; (c) Human fixations; (d) Our ground truth of saliency map, the higher brightness represents the more salient regions

图2 所构建的图像库和其它图像库的对比(从上到下依次为:原始图像,基于注视点的图像库参考标准,显著目标图像库参考标准[9],所构建的显著目标检测图像库参考标准)Fig.2 The comparison between the present dataset and other datasets (From top to bottom: the input image, the ground truth of human fixation, the ground truth of salient object, and the ground truth proposed in this paper)
正如前文所述,目前已有的显著性图像库的参考标准(ground truth)主要有两类:实验记录的眼动注视点分布和手工标注的显著目标。如图2所示,眼动注视点分布能够反映局部位置的显著性,但无法提供目标区域的形状信息(见图2中第2行),因此无法用于评判显著目标检测算法的性能。另一方面,手工标注的显著目标往往将图像像素简单地划分为目标类和背景类,丢失了多个目标或区域之间的相对显著性差异(见图2中第3行),无法满足多目标场景的显著性计算。
本研究同时利用手工勾画的图像分割和实验记录的眼动数据,构建了包含500幅图像的显著目标检测图像库。从图2中第4行可以清晰看出,所构建的显著性目标检测标准图像具有以下优点:(1)各个显著区域之间边界清晰;同时,各个区域内部的显著程度一致;(2)提供了不同目标(或不同区域)之间的相对显著性,可用于评价多目标场景的显著目标检测算法;(3)各个区域之间的相对显著程度符合人类感知经验。例如,人脸、近距离目标等往往具有更高的显著性。因此,相比以往的图像库,该图像库能够为显著目标检测算法提供更客观、合理的测试标准。

图3 显著目标检测结果。(a)原始图像;(b)FT方法结果[18];(c)HC方法结果[8];(d)RC方法结果[8];(e)HS方法结果[9];(f)我们的结果;(g)标准显著图Fig.3 The results of salient object detection. (a) Input images; (b) The results of FT; (c) The results of HC; (d) The results of RC; (e) The results of HS; (f) Our results; (g) Ground truth
2.2 显著目标检测结果
基于gPb-UCM分割算法[10]以及中央偏置先验和图像边界先验信息计算每个图像的显著性检测结果,与目前典型的4个显著目标检测算法进行定性对比。从图3中可以看出,所提出的方法效果明显优于经典的FT[18]、HC[8]、RC[8]和HS[9]算法,更接近利用眼动数据得到的标准显著图像。具体表现为,本方法获得的显著目标更为完整,形状边缘更为精确。
基于相关系数,计算了图3中4幅图像在各个算法下的结果与标准显著图的相关系数。如表1所示。
表1 图3中图像的相关系数
Tab.1 The correlation coefficient of images listed in Fig.3
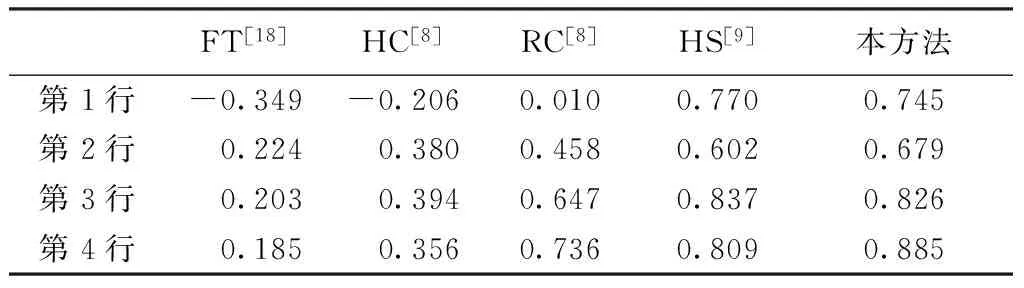
FT[18]HC[8]RC[8]HS[9]本方法第1行-0.349-0.2060.0100.7700.745第2行0.2240.3800.4580.6020.679第3行0.2030.3940.6470.8370.826第4行0.1850.3560.7360.8090.885
在整个图像库(n=500)上对算法结果进行统计分析。从图4中可以看出,所提出的方法达到了和HS接近的结果,且明显优于其他几个方法。这说明,基于高质量的图像分割结果,复杂的显著目标检测可以通过十分简单的方法来实现。因此,图像分割在显著目标检测中有着十分重要的意义,不应被忽视。

图4 整个图像库的平均相关系数,其中误差条为95%置信区间Fig.4 The mean correlation coefficient over the whole dataset, the error bars represented the 95% confidence intervals
3 讨论
现有的基于手工勾画的显著目标检测图像库主要针对单目标场景设计,每幅图像包含一个主要目标[9, 18]。相对于直接手工勾画的显著目标,本研究基于多个被试自由观看状态下的眼动数据构建的图像库提供了更合理的显著目标检测标准图像。所给出的标准显著图能够反映不同区域显著性的相对关系,即该图像库可用于评价单目标和多目标检测任务。同时基于图像分割信息,图像库中每个显著区域边界清晰,区域内部显著性一致。所以,本研究为显著目标检测领域提供了一个更可靠的标准显著图像库。
实验发现,基于图像分割算法的分割结果,引入简单的后处理就可以实现高质量的显著目标检测任务,说明为了实现高效的显著目标检测,可以借鉴图像分割的研究成果,简化显著目标检测问题,这也为显著目标检测算法的设计提供了新的思路。值得注意的是,所提出的显著目标检测算法的主要目的是证明图像分割在显著检测中的重要作用。尽管其获得了较好的显著目标检测结果,但对于部分复杂场景,由于中央偏置和图像边界先验并不能完全有效地估计显著区域,因此,显著性的计算仍有待进一步提高。
4 结论
本研究以标准图像分割库(BSD500)为基础,借助于眼动实验数据,构建了一个含500幅自然图像的显著目标检测图像库。该图像库为每幅图像提供了符合人眼选择性注意特性的标准显著图,可用于显著目标检测算法的性能评估。同时验证了基于高质量的图像分割结果,加入简单的后处理(例如中央偏置,图像边界先验)能够获取较好的显著目标检测结果。通过定性和定量的对比分析,所提出的方法可以接近现有最优方法的效果。因此我们强调图像分割在显著目标检测中的重要作用。
[1] Rutishauser U, Walther D, Koch Cetal. Is bottom-up attention useful for object recognition? [C] // IEEE Conference on Computer Vision and Pattern Recognition. Washington: CVPR, 2004: 37-44.
[2] Christopoulos C, Skodras A, Ebrahimi T. The JPEG2000 still image coding system: an overview [J]. IEEE Transactions on Consumer Electronics, 2000, 46(4):1103-1127.
[3] Liu W, Tong QY. Medical image retrieval using salient point detector [C] // IEEE Conference on Engineering in Medicine and Biology Society. Shanghai: IEEE, 2005: 6352-6355.
[4] Itti L, Koch C. Computational modeling of visual attention [J]. Nature Reviews Neuroscience, 2001, 2(3):194-203.
[5] Li Zhaoping. A neural model of contour integration in the primary visual cortex [J]. Neural Computation, 1998, 10(4):903-940.
[6] Itti L, Koch C, Niebur E. A model of saliency-based visual attention for rapid scene analysis [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(11):1254-1259.
[7] Li Yin, Hou Xiaodi, Koch Cetal. The secrets of salient object segmentation [C] // IEEE Conference on Computer Vision and Pattern Recognition. Columbus: CVPR, 2014: 280-287.
[8] Cheng Mingming, Zhang Guoxin, Mitra NJetal. Global contrast based salient region detection [C] // IEEE Conference on Computer Vision and Pattern Recognition. Colorado Springs: CVPR,2011: 409-416.
[9] Yan Qiong, Xu Li, Shi Jiangpingetal. Hierarchical saliency detection [C] // IEEE Conference on Computer Vision and Pattern Recognition. Portland: CVPR, 2013: 1155-1162.
[10] Arbelaez P, Maire M, Fowlkes Cetal. Contour detection and hierarchical image segmentation [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011,33(5):898-916.
[11] Brainard DH. The psychophysics toolbox [J]. Spatial Vision, 1997, 10:433-436.
[12] Pelli DG. The VideoToolbox software for visual psychophysics: Transforming numbers into movies [J]. Spatial Vision, 1997, 10(4):437-442.
[13] Judd T, Ehinger K, Durand Fetal. Learning to predict where humans look [C] // IEEE International Cconference on Computer Vision. Kyoto: ICCV, 2009: 2106-2113.
[14] Zhu Wangjiang, Liang Shuang, Wei Yichenetal. Saliency optimization from robust background detection [C] // IEEE Conference on Computer Vision and Pattern Recognition. Columbus: CVPR, 2014: 2814-2821.
[15] Wei Yichen, Wen Fang, Zhu Wangjiangetal. Geodesic saliency using background priors[C] // Europea Conference on Computer Vision. Florence: Springer-Verlag, 2012: 29-42.
[16] Borji A, Sihite DN, Itti L. Salient object detection: A benchmark[C] // Europea Conference on Computer Vision. Florence: Springer-Verlag, 2012: 414-429.
[17] Kootstra G, Nederveen A, De Boer B. Paying attention to symmetry[C] // British Machine Vision Conference. Leeds: BMVC, 2008:1115-1125.
[18] Achanta R, Hemami S, Estrada Fetal. Frequency-tuned salient region detection [C] // IEEE Conference on Computer Vision and Pattern Recognition. Kyoto:CVPR, 2009: 1597-1604.
A Dataset for Salient Region Detection Based on Human Eye Movement
Gao Xin Yang Kaifu Yao Dezhong#Li Yongjie*
(SchoolofLifeScienceandTechnology,UniversityofElectronicScienceandTechnologyofChina,Chengdu610054,China)
eye movement; salient object; image segmentation; dataset
10.3969/j.issn.0258-8021. 2015. 04.014
2014-12-01, 录用日期:2015-03-10
国家重点基础研究发展计划(973计划)(2013CB329401);国家自然科学基金(91420105,61375115)
TP391
D
0258-8021(2015) 04-0487-05
# 中国生物医学工程学会会员(Member, Chinese Society of Biomedical Engineering)
*通信作者(Corresponding author), E-mail: liyj@uestc.edu.cn
