基于关联规则算法的钢铁企业隐患管理重点研究
2015-08-30刘双跃北京科技大学土木与环境工程学院北京100083
刘双跃,夏 川(北京科技大学土木与环境工程学院,北京100083)
基于关联规则算法的钢铁企业隐患管理重点研究
刘双跃,夏 川
(北京科技大学土木与环境工程学院,北京100083)
在钢铁企业隐患排查信息系统得到广泛应用的同时,产生了海量的隐患排查治理的数据,而企业如何利用这些数据来指导隐患管理的研究和应用却缺乏针对性和可操作性。将钢铁企业存在的隐患进行规范化的描述,对规范化后积累的隐患台账进行分析;使用SAS软件,设计了数据预处理的流程,并以锻造厂车间隐患台账为例,应用关联规则算法,得到了优先需要关注的规则及其支持度、置信度和提升度三个指标;从作业区班组及其进行的作业活动两个层面出发,生成相应的图形,直观地帮助钢铁企业找到优先需要改善的规则,以及优先需要关注的作业区班组、作业活动以及隐患类型,并通过横向和纵向的分析比较,发现不同规则的相对重要程度,以为企业快速提高隐患管理能力提供重点和方向。
钢铁企业;隐患;关联规则算法;管理重点
钢铁在基础建设中发挥着不可替代的作用,但是由于其生产中常涉及高温高压反应、有毒有害物质和易燃易爆的气体液体,而且作业现场存在连续化高强度的作业,各类事故时常发生,特别是违反操作规程或劳动纪律原因而产生的事故[1-2]。要减少事故的发生,必须减少事故的基本组合因子隐患,隐患是事故发生量变的积累,事故是隐患质变导致的结果[3]。为了使隐患排查更加科学高效,各地都启动了隐患排查治理“两化”体系(标准化、信息化)建设,特别是云计算的引入,更是提高了实时处理大量隐患数据的能力[4]。但是部分企业隐患录入依靠个人的描述,造成不同人对同一隐患描述不同,这样既难以准确简洁描述隐患,也不利于对隐患信息后续的分析。另外,很多企业处理大量隐患数据还停留在对隐患信息中出现的频数做统计。目前一些学者开始将数据挖掘方法引入到安全生产之中,并取得了一定的成果。如Kniesner等[5]使用非均衡面板数据模型评价煤矿安全季度检查和安全状况之间的关系,得到煤矿安全检查实施中最有效的方式;Spurgin等[6]通过对影响核电站操作人员在安全方面表现因素进行模拟分析,得到着力于改善关键因素要比盲目地培训更有效的结论;陈帆等[7]结合粗糙集理论和RBE神经网络模型评价地铁施工的安全风险,提高了评价的精度;吴昊等[8]通过多维数据的Apriori算法,得到了各种因素对于道路交通事故影响的特点;汪莹等[9]构建了煤炭企业班组安全管理7大功能体系,通过数据挖掘得到了不同安全监测点危险级别。但是对于企业管理人员应当重点关注哪些方面来加强隐患管理,往往结论的针对性和可操作性较低。本文对隐患进行规范化的描述,对积累的隐患台账进行数据预处理,并应用关联规则算法,通过生成两种特定形式的规则,得到优先需要关注的规则,具体到特定的作业区班组、作业活动和隐患类型,同时通过横向比较同一班组所造成的多个隐患,纵向比较造成同一隐患类型所涉及的作业区班组,找到隐患管理的重中之重,从而对企业隐患管理的指导更加清晰和明确。
1 隐患数据采集及关联规则算法
1.1隐患数据的采集
高效的隐患数据采集离不开计算机系统软件技术,本文融合安全隐患分级闭合管理的思想[10],开发多角色协同软件,以保证隐患数据实时高效地采集[11]。隐患描述的规范化可以参照《安全生产事故隐患排查治理体系建设实施指南》,将隐患分为基础管理和现场管理,又细分为24小类,再结合企业已有的隐患描述和实际情况,隐患录入人员就可以通过选择多层次的下拉列表框完成隐患的描述,这样既可以达到隐患描述精准、简练,又利于使用算法进行分析[12]。通过电脑端或移动终端,用户采集到的隐患数据都可进入到服务器的数据库之中,为知识发现做好原始数据的准备[13]。
1.2关联规则算法
隐患数据中部位、类型、责任班组等信息都是名义数据,即只用来区分个体在属性上的特征或类别上的不同,不表示大小、先后、优劣之分。要找出它们多种组合情况联系的大小,关联规则算法作为十大经典数据挖掘算法是理想的方法之一[14],其在繁杂的大型数据库中,可以方便地找出各属性关联性的强弱,从而挖掘出有助于提高隐患管理的信息[15]。关联规划算法的基础表需要用二元形式来表示(0和1),对于非二元属性可以转化为二元属性,如隐患级别这个属性包括四级,即隐患级别=一级、隐患级别=二级、隐患级别=三级、隐患级别=四级,划分成四个二元属性。该算法基础表中的每一行(t1~tp)表示一个事务,每一列(i1~iq)表示一个项,事务出现则值为1,不出现则值为0,如表1所示。

表1 关联规则算法的基础表Table 1 Underlying table of association rules algorithm
I={i1,i2,i3,…,iq}是所有项的集合,T= {t1,t2,t3,…,tp}是所有事务的集合,若项集X是T中一个事务tj的子集,则这个候选项集X的支持度计数可以定义为
σ(X)=count{t|X⊆t,t∈T}
关联规则是形如候选项集X→候选项集Y的表达式,其中X∩Y=Ø,关联规则的强度可以用支持度(Support)、置信度(Confidence)和提升度(Lift)三个指标来衡量。
支持度(Support)(X→Y)表示候选项集X和Y同时出现的支持度计数占总事务频数的比率,定义如下:
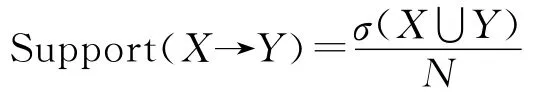
支持度是衡量该规则出现频繁程度的指标,支持度小则说明该规则很少出现,不重要;支持度大则说明该规则出现频繁,相对重要。频繁项集产生需要搜索的是指数规模的,为了删除不重要的规则,需要引入最小支持度(minsup),保留支持度大于或等于最小支持度的规则,删除支持度小于最小支持度的规则。
置信度(Confidence)(X→Y)表示候选项集X和Y同时出现的支持度计数占候选项集X支持度计数的比率,定义如下:

置信度是衡量通过规则进行推理可靠性大小的指标,置信度越低表示候选项集Y包含在候选项集X的事务出现的概率越小;反之概率越大。相似地,引入最小置信度(minconf),保留置信度大于或等于最小置信度的规则,删除置信度小于最小置信度的规则。
提升度(Lift)(X→Y)表示置信度(Confidence)(X→Y)和支持度(Support)(Y)之比,定义如下:
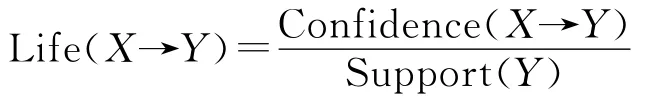
提升度可衡量X和Y的关联程度的强弱,提升度大于1,表示候选项集X的提高会使候选项集Y提高;提升度小于1,表示候选项集X的提高会使候选项集Y降低[16]。
2 关联规则算法在钢铁企业隐患数据分析中的应用
2.1隐患描述的规范化
由于钢铁企业涉及的作业存在连续性和交叉性,相同作业活动的隐患较为相似,因此隐患的规范化描述应以各作业区的多种作业活动展开。本文以锻造厂为例,对涉及锻造厂车间现场管理中从业人员违规作业存在的隐患进行了规范化描述。
将锻造厂车间分为:压机作业区、锤部作业区、天车作业区、退火作业区和精整作业区,每个作业区都有若干个班组和作业活动,每种作业活动又包含许多对应的隐患类型,因此以作业区班组、作业活动和隐患类型三个属性进行分析。若要考虑到各隐患本身重要的级别可能不一样,可以分别对同一级别的隐患进行分析。如以锻造厂车间中的锤部作业区为例,隐患描述规范化后积累的隐患台账见表2。

表2 锤部作业区隐患台账Table 2 Ministry of hammer's hazard management standing books
2.2数据预处理的流程
原始数据存在许多问题,比如数据内涵不一致,同一数据重复出现,需要用到的数据为空值,数据中存在错误,数据结构与所选的数据挖掘模型不匹配等等,这就需要在数据挖掘之前对原始数据进行预处理[17],满足数据挖掘的要求。本文采用在数据挖掘领域应用最为广泛的SAS(Statistics Analysis System)作为实现数据挖掘的工具。SAS可以实现和外部数据库的直接访问,导入到SAS中的数据就可以进行数据的预处理。隐患数据预处理流程如图1所示。
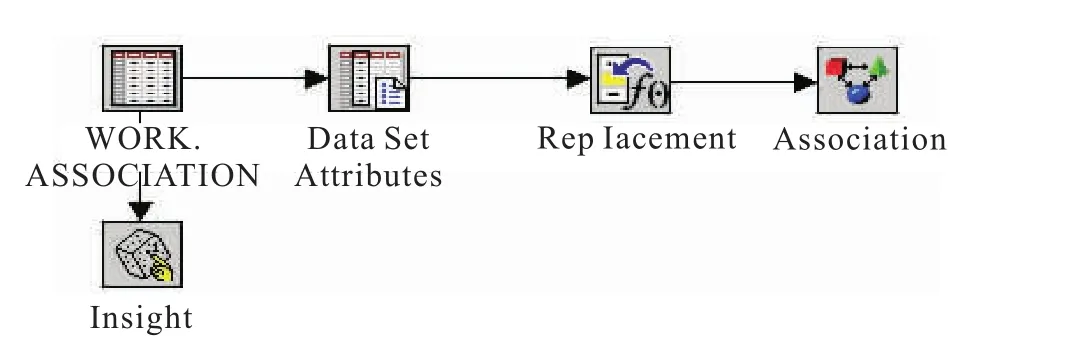
图1 隐患数据预处理流程Eig.1 Hazard data preparation process
WORK.ASSOCIATION数据集节点可用于导入锻造厂车间的隐患台账,Insight探索节点可以实现交互式探索和分析,查看作业区班组、作业活动和隐患类型三个属性的分布情况。Data Set Attributes数据集属性节点可用于修改数据集的名称(Name)、角色(Model Role)和度量方式(Measurement),序号属性用来标识各条记录,角色设置为标识变量(ID),度量方式设置为连续变量(Interval);作业区班组、作业活动和隐患类型三个属性是最终要形成关联结果的属性,角色均设置为目标变量(target),度量方式设置为名义变量(Nominal);其他没有用到的属性废弃,角色设置为舍弃不用(rejected)。Rep Lacement替换节点可用于替换数据集中的缺失值和某些非缺失值的替换方法,对于作业区班组、作业活动和隐患类型这些非连续数值变量,出现缺失值或者不属于隐患规范化描述之内的值,均用样本高频值的方法替换[18]。
2.3关联规则算法的结果
数据预处理完成时,利用Association节点对预处理过的数据进行Apriori算法的运算,设置好最小支持度和最小关联度,只有满足条件的规则才会被显示出来,这些规则代表了需要重点关注的隐患。每条满足条件的规则都包含关联集合的项目数(Relations)、提升度(Lift)、支持度(Support)、置信度(Confidence)四个指标(见表3),利用这些指标可对不同规则的相对重要程度进行后续区分。
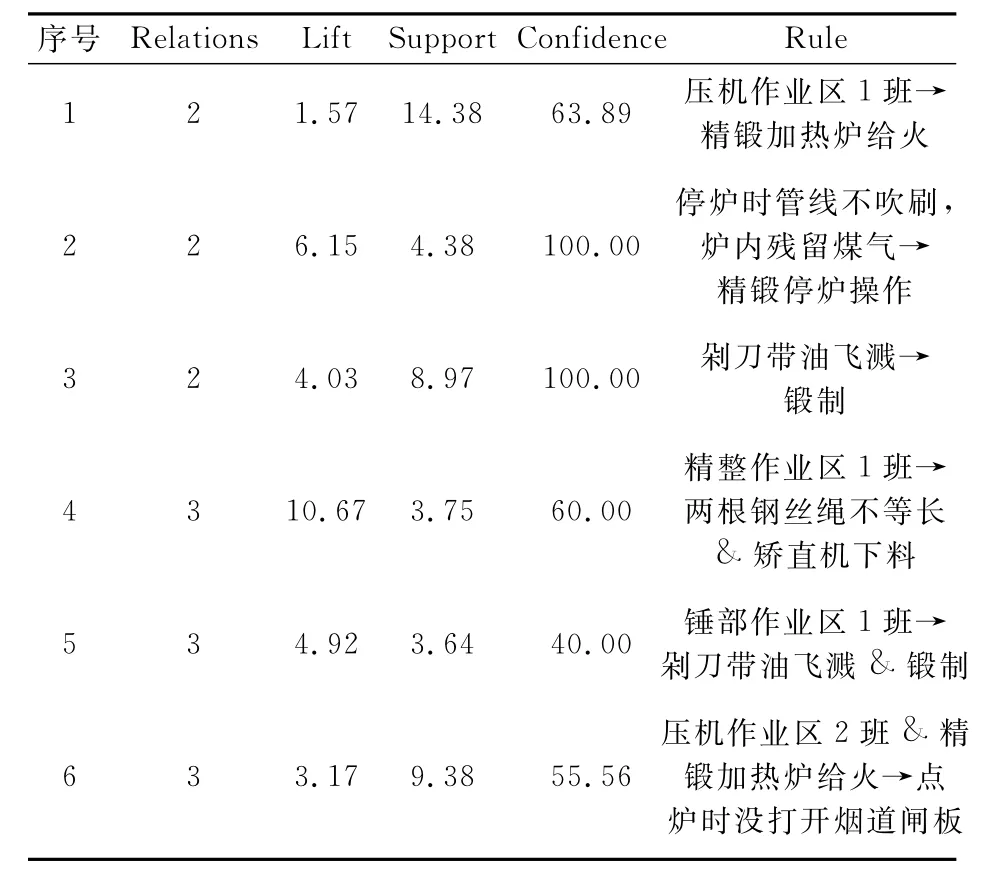
表3 关联规则算法生成的结果Table 3 Result of association rules algorithm
2.4隐患管理重点的分析
并不是所有生成的规则都能用来指导隐患管理,比如表3中第2条规则:停炉时管线不吹刷,炉内残留煤气→精锻停炉操作,而停炉时管线不吹刷,炉内残留煤气隐患类型,本身就包含于精锻停炉操作的,所以分析该规则没有意义。本文利用SAS筛选出特定形式的规则,再将这些规则生成图形,每种颜色代表一个支持度区间,每种形状代表一个置信度区间,图形的相对大小代表提升度的大小,这样就可以直观地反映出有用的结果。
2.4.1作业区班组层面的分析
如果要在某个作业区班组中,找出其进行作业活动中产生隐患较为频繁的规则,这就需要针对作业区班组层面进行分析,生成作业区班组→作业活动+隐患类型形式的规则,如图2所示。

图2 作业区班组→作业活动+隐患类型形式的规则Eig.2 Rules in operational team→(job activity+hazard type)form
某作业区班组进行特定作业活动产生特定的隐患越频繁,说明本条规则的支持度越大。如图2中绿色图形的支持度最大,也就是压机作业区2班进行精锻加热炉给火作业时,生成点炉时没打开烟道闸板隐患类型最频繁,因此提高压机作业区2班在进行精锻加热炉给火作业中点炉时没打开烟道闸板隐患类型的意识和技能,是隐患治理的重点。每个作业区班组易产生的隐患可能有多个,但是多个隐患之间的重要程度也有差别。如图2中压机作业区2班所在行有两个图形,绿色“×”字形和黄色圆柱体,两者进行横向比较,前者比后者的支持度和置信度都要高,说明就提高压机作业区2班的隐患管理而言,提高精锻加热炉给火作业时点炉时没打开烟道闸板隐患类型的管理要比提高先给煤气、后点火隐患类型更重要。
某作业区班组在进行各类作业活动产生隐患时,属于特定作业活动和隐患类型的概率越大,其置信度越大,说明就该班组而言,提高本作业活动和隐患类型是隐患治理工作的重点。如图2中六棱柱置信度最大,对于淡蓝色六棱柱,说明精整作业区1班在作业形成隐患时,属于在矫直机下料作业中两根钢丝绳不等长隐患类型的概率有55%以上,所以对于精整作业区1班,提高对矫直机下料作业中两根钢丝绳不等长隐患类型的管理要比其他的隐患类型重要得多。
4.2.2作业活动层面的分析
如果要在某个作业区班组进行特定作业活动中找出其产生特定隐患较为频繁的规则,并在此基础上找出属于哪种隐患类型的概率大,这就需要针对作业活动层面进行分析,生成作业区班组+作业活动→隐患类型形式的规则,如图3所示。

图3 作业区班组+作业活动→隐患类型形式的规则Eig.3 Rules in(operational team+job activity)→hazard type form
作业区班组+作业活动→隐患类型和作业区班组→作业活动+隐患类型两种形式的规则,关于支持度的分析方法和结果都是一样的,区别在于对置信度的分析。某作业区班组进行特定作业活动产生隐患时,属于特定的隐患类型概率越大,说明本条规则的置信度越大。如图3中六棱柱置信度最大,对于红色六棱柱,说明压机作业区3班在进行精锻加热炉给火作业形成隐患时,属于点炉时烧嘴泄露隐患类型的概率有57%以上,所以对于压机作业区3班在精锻加热炉给火作业,提高对点炉时烧嘴泄露隐患类型的管理要比其他的隐患类型重要得多。造成同一隐患类型所涉及作业区班组可能有多个,但是它们的严重程度也存在差别。如图3中点炉时没打开烟道闸板所在列有两个图形,油绿色八面体和淡绿色四棱锥,两者进行纵向比较,前者比后者的支持度和置信度都要高,说明了精锻加热炉给火作业时,压机作业区2班要比压机作业区1班更易生成点炉时没打开烟道闸板的隐患类型,所以就点炉时没打开烟道闸板隐患类型而言,压机作业区2班更需要加强管理。
3 结 论
为了有效利用隐患台账,帮助企业找到隐患管理的重点,本文首先对钢铁企业可能存在的隐患进行规范化;然后将隐患排查治理系统生成的隐患台账利用SAS进行数据的预处理,采用关联规则算法,得出各个规则的支持度、置信度和提升度三个指标;最后通过对作业区班组→作业活动+隐患类型形式规则的分析,得出了需要重点关注的作业区班组及其在进行某种作业活动中易发生的隐患类型,同时对易发生多种隐患类型的作业区班组,通过横向比较得出了对该作业区班组而言更需关注的隐患类型,并通过对作业区班组+作业活动→隐患类型形式规则的分析,得出了需要重点关注作业区班组进行的作业活动类型及其易发生的隐患类型,同时再对造成同一隐患类型的多个班组,通过纵向比较得出了对该隐患类型而言更需提高管理的班组。通过以上的分析比较,使隐患管理人员真正掌握企业中需要优先关注的作业区班组、作业活动以及隐患类型,并了解它们之间的相对重要程度,明确了隐患治理的重点,为隐患排查治理能力的提高和减少事故的发生提供指导。
[1]王志,张倩倩.钢铁企业安全生产现状与问题分析[J].工业安全与环保,2014,40(10):93-95.
[2]杨涛,尹景燕.钢铁企业生产事故致因要素分析[J].安全与环境学报,2013,13(4):213-215.
[3]郑贤斌.浅析安全、危险、隐患和事故之间的关系[J].中国安全生产科学技术,2007,3(3):50-52.
[4]徐卫东,刘祖德.基于云计算的企业安全管理趋势研究[J].安全与环境工程,2014,21(3):86-93.
[5]Kniesner T J,Leeth J D.Data mining mining data:MSHA enforcement efforts,underground coal mine safety,and new health policy implications[J].Journal of Risk and Uncertainty,2004,29(2):85-108.
[6]Spurgin A,Petkov G.Advanced simulator data mining for operators'performance assessment[J].Studies in Computational Intelligence,2005,5:487-513.
[7]陈帆,谢洪涛.基于粗糙集和RBE神经网络的地铁施工安全风险评估[J].安全与环境学报,2013,13(4):232-235.
[8]吴昊,李军国.基于关联规则理论的道路交通事故数据挖掘模型[J].电子技术应用,2009(2):135-142.
[9]汪莹,周婷,王光岐,等.基于数据挖掘的安全管理信息系统研究—以某煤炭企业班组安全管理为例[J].中国矿业大学学报,2014,43(2):362-367.
[10]高春学,曲志清,张建文.安全生产隐患排查治理方法探讨[J].安全与环境工程,2008,15(2):112-115.
[11]赵作鹏,尹志民,陈金翠,等.协同软件技术在煤矿隐患排查系统中的应用[J].煤炭工程,2010(5):115-117.
[12]王升宇,江飞.煤矿隐患管理系统优化[J].辽宁工程技术大学学报(自然科学版),2012,31(5):696.
[13]Eayyad U,Piatetsky-Shapiro G,Smyth P.Erom data mining to knowledge discovery in databases[J].AI Magazine,1996,17 (3):37-54.
[14]Wu X D,Vipin K,Ross Q J,et.al.Top 10 algorithms in data mining[J].Knowledge and Information Systems,2008,14(1): 1-37.
[15]Chen C Q,Yan P,Wei Q.Discovering associations with uncertainty from large databases[J].Recent Advances in Decision Making,2009,222:45-50.
[16](美)Pang-Ning T,Michael S,Vipin K.数据挖掘导论(完整版)[M].范明,范宏建等译.北京:人民邮电出版社,2011.
[17]Cooley R,Mobasher B,Srivastava J.Data preparation for mining world wide web browsing patterns[J].Knowledge and Information Systems,1999,1(1):5-32.
[18]杜强,贾丽.SAS统计分析标准教程[M].北京:人民邮电出版社,2010:299-323.
Research on Focal Points of Hazard Management in Iron and Steel Enterprises Based on Association Rules Algorithm
LIU Shuangyue,XIA Chuan
(School of Civil and Environmental Engineering,University of Science&Technology Beijing,Beijing 100083,China)
While hazard investigation and management information system is widely used in iron and steel enterprises,the system produces a great mass of hazard investigation and management data.But it's often lacking in pertinence and operability for iron and steel enterprises administrators to use these data to guide hazard management's research and application.This paper first standardizes descriptions of iron and steel enterprises'hazard and analyses hazard standing books.Then taking forging factory workshop's hazard management standing books for instance,this paper uses Statistical Analysis System(SAS)to design data preparation process,and applies association rules algorithm to obtaining the rules which need prior attention and their related Lift,Support and Confidence's value.Last,resulting from the two aspects of the operational team and their performance,the corresponding graphics can help iron and steel enterprises to find the priority of rules for improvement and the priority of operational teams,job activities or hazard types for attention.Vertical and horizontal comparison analysis can help to distinguish the relative important degrees of different rules,which provides the direction and focal points for enhancing hazard management abilities.
iron and steel enterprises;hazard;association rules algorithm;focal points of management
X92
A
10.13578/j.cnki.issn.1671-1556.2015.05.016
1671-1556(2015)05-0091-05
2015-04-02
2015-06-02
刘双跃(1958—),男,博士,教授,主要从事产业安全技术、危险辨识与安全评价、安全预警与管理系统等方面的教学与科研工作。E-mail:liusy@ustb.edu.cn
