基于多信息字典学习及稀疏表示的SAR目标识别
2015-08-17齐会娇王英华刘宏伟
齐会娇,王英华,丁 军,刘宏伟
(西安电子科技大学雷达信号处理国家重点实验室,陕西西安710071)
基于多信息字典学习及稀疏表示的SAR目标识别
齐会娇,王英华,丁 军,刘宏伟
(西安电子科技大学雷达信号处理国家重点实验室,陕西西安710071)
为了提高合成孔径雷达(synthetic aperture radar,SAR)图像中目标变体的识别性能,在鉴别字典学习及联合动态稀疏表示模型的基础上,提出一种基于多信息字典学习及稀疏表示的SAR目标识别方法。在训练阶段,采用鉴别字典学习LC-KSVD方法分别对目标图像域幅度信息及目标频域幅度信息进行字典学习。在测试阶段,结合训练阶段学到的2种信息的字典及测试目标的2种信息,采用联合动态稀疏表示模型求解2种信息下的稀疏表示系数。最后,根据2种信息下的重构误差实现对测试目标的识别。使用MSTAR数据集对算法进行验证,结果表明,新方法相对于现有的方法能够达到更好的识别性能。
合成孔径雷达;目标识别;字典学习;联合动态稀疏表示
0 引 言
随着合成孔径雷达(synthetic aperture radar,SAR)成像技术的发展,实际中已经可以获取大量的SAR数据。基于SAR图像的自动目标识别是从SAR数据中获取信息的一个重要方面,尤其在军事领域具有重要的应用价值。而在实际中,即使属于同一类别的2个不同目标之间的配置、结构等方面也会存在一定的差异,则将其中的一个目标称为另一目标的变体。SAR目标变体识别的难点在于训练数据永远无法表示真实世界中的所有情况,实际中不可能得到目标所有状态或者配置下的训练样本。因此传统的方法,例如模板匹配[1]、核主成分分析[2]等方法在目标变体的识别方面识别性能仍不够理想。对于SAR目标变体识别方法的研究目前仍然是一个重要的研究方向。
近年来,稀疏表示在模式识别领域受到了广泛的关注。文献[3]提出了一种基于稀疏表示的人脸识别方法,该方法利用训练样本对测试目标进行稀疏表示,根据表示结果进行识别,在人脸受到部分遮挡、噪声污染等情况下达到了较稳健识别,适用于具有局部相似性图像目标的识别。针对可以同时获取同一目标的多幅图像的情况,文献[4]提出了联合动态稀疏表示(joint dynamic sparse representation,JDSR)模型,用于多幅光学图像的目标识别,该方法由全部训练样本数据构成字典,采用联合动态稀疏表示的方法对一个测试目标的多幅图像进行联合稀疏表示,根据对测试样本的多幅图像的重构误差之和来进行目标的分类。该方法强调,同一测试样本的多幅图像享有相似但并不一定相同的稀疏表示模式,较好地利用了同一目标多幅图像之间的相关性,更具有灵活性和适用性。
由于稀疏表示在稳健的人脸识别[3]方面体现出的良好性能,目前也有一些工作将稀疏表示应用于SAR目标识别方面,其中一个有代表性的是文献[5]中的工作。他们提出了基于联合稀疏表示(joint sparse representation,JSR)的多视角下的SAR图像自动目标识别的方法,并取得较好效果。该方法不仅利用了稀疏表示的局部稳健性,还利用了同一目标多视角下的图像之间的关联性及其在字典中稀疏表示模式的一致性,因此对目标变体有较好的识别结果。在该方法中,多视角图像的稀疏表示模式的非零系数严格限制在相同的位置,这样的限制过于严格,因为在实际中,由于SAR图像目标对方位角的敏感,方位角相近的目标的散射特性依然存在差异。此外,文献[5]中的方法假设在目标识别时,同时存在同一目标不同视角下的多幅SAR图像,这在实际中是较难获取的。
上述方法都是利用训练样本直接构成字典,这样形成的字典的原子之间存在较多的冗余信息。因此,近年来学者们对于字典学习方法也开展了深入的研究。文献[6]提出了K-SVD算法,在最小化重构误差的基础上,经过迭代更新字典和系数,学习到一个能够稀疏表示训练数据的字典,该方法属于非监督字典学习。在此基础上,文献[7]提出了LC-KSVD方法,该方法属于监督字典学习方法,其强调同一类目标应有相似的稀疏编码模式,不同类目标的编码模式则相差较大。该模型在代价函数中引入鉴别信息,利用K-SVD算法对代价函数进行优化。经过学习后的字典既可以对训练数据较好地重构,又具有一定的可鉴别性,在多组实验数据上得到了较好的分类结果。
受文献[1-7]启发,本文提出一种基于多信息鉴别字典学习及联合动态稀疏表示的SAR目标识别方法。在基于稀疏表示进行目标识别时,结合目标图像域幅度信息及目标频域幅度信息,采用多信息联合动态稀疏表示模型进行识别。同时,稀疏表示的字典是利用LC-KSVD方法分别对目标的图像域幅度信息、频域幅度信息进行字典学习得到。利用学到的2种信息字典采用联合动态稀疏表示模型进行稀疏系数的求解,根据重构误差对目标进行识别。本文方法既利用了稀疏表示的稳健性,又利用了同一目标多种信息之间的关联性,对SAR图像目标特别是目标变体取得了较好的识别效果。与现有方法相比,本文的方法有以下优势。
(1)与文献[4]中提出的JDSR方法相比,本文利用经过LC-KSVD方法[7]学习得到的字典代替了原来由训练样本得到的字典。一方面,学习降低了字典的冗余性;另一方面,为了减小存储量和后续联合动态稀疏表示的运算量,需要降低字典的原子数目。而在字典原子数目较少时,学习得到的字典,与直接由训练样本构成的字典相比,能够更好地包含各类目标的信息,因此达到更好的识别性能。
(2)与文献[7]中提到的LC-KSVD方法相比,LC-KSVD方法中仅对目标的一种信息进行字典学习,而本文的方法分别对目标的图像域幅度信息和频域幅度信息进行鉴别字典学习,结合目标的图像域幅度信息字典及频域幅度信息字典,采用联合动态稀疏表示的方法对测试目标进行稀疏表示,根据重构误差的大小对测试目标的类别进行判断。本文方法综合利用了同一目标的图像域幅度信息及频域幅度信息之间的相关性,提高了目标变体的识别率。
(3)SAR图像目标的图像域信息对目标的位置变化比较敏感,仅利用图像域幅度信息来进行稀疏表示,达不到很好的识别结果。而目标的频域信息则对目标的位置不敏感,因此通过结合目标图像域幅度信息和频域幅度信息,本文方法即使在图像域目标没有进行配准等预处理的情况下,依然能保持较好的识别结果。
1 基于多信息字典学习及稀疏表示的SAR目标识别
图1给出了本文提出的基于多信息字典学习及稀疏表示的SAR目标识别方法的流程图。该方法主要包括训练和测试2个阶段。在训练阶段主要包括预处理、字典学习两部分,测试阶段主要包括预处理、联合动态稀疏表示及目标识别3个部分。预处理包括对所有的训练样本和测试样本进行分割、配准、截取处理。在训练阶段,预处理完成后,字典学习部分采用LC-KSVD方法分别对目标的图像域幅度信息和目标频域幅度信息进行字典学习。在测试阶段,首先对原始测试样本进行预处理,得到图像域幅度信息特征向量和频域幅度信息特征向量。联合动态稀疏表示部分采用联合动态稀疏表示模型,结合训练阶段学习得到的字典,求解测试样本多种信息在学习字典下的稀疏表示系数。最后,测试阶段的目标识别部分利用求得的稀疏系数对测试样本的图像域幅度信息和频域幅度信息进行重构,参考文献[3-4]中的分类标准得到测试样本的类别。下面对图1中的各个主要步骤进行具体介绍。
1.1 预处理
SAR图像与光学图像不同,目标对方位角有较强的敏感性,图像的质量也很容易受到相干斑影响,同时目标图像域信息对目标位置较敏感,因此在利用SAR图像进行目标识别之前需对目标图像进行滤波、配准等预处理。文献[8-10]中对图像进行了对数变换、滤波、分割等预处理,文献[11]对图像的中心目标区域求质心,以质心作为配准图像的中心进行图像的配准处理。参考文献[8-10]中的分割方法及文献[11]中的配准方法,本文首先对所有的训练样本的目标区域进行分割处理,分割后采用质心对齐的方式进行配准,对配准后的图像进行截取处理得到最终识别实验用的目标图像。图像的预处理过程示意图如图2所示。图2(a)为一幅原始的SAR目标图像,该图像来自于MSTAR数据集,其大小为128像素×128像素。图2(b)为对图2(a)进行目标区域分割等处理后的二值图像,其中白色为分割出的目标区域。图2(c)为采用质心对齐方式进行配准后的图像,与图2(a)相比,图2(a)原图像中的某个像素的位置坐标为(76,65),在图2(c)中以质心对齐方式配准后该像素的位置坐标变为(68,62)。图2(d)为对图2(c)配准后的图像以质心为中心截取63像素×63像素大小的区域后得到的图像。对实验所用的MSTAR数据,每幅原始大小为128像素×128像素的图像,通过上述预处理方法处理后得到大小为63像素×63像素的图像作为后续识别所用的样本数据。
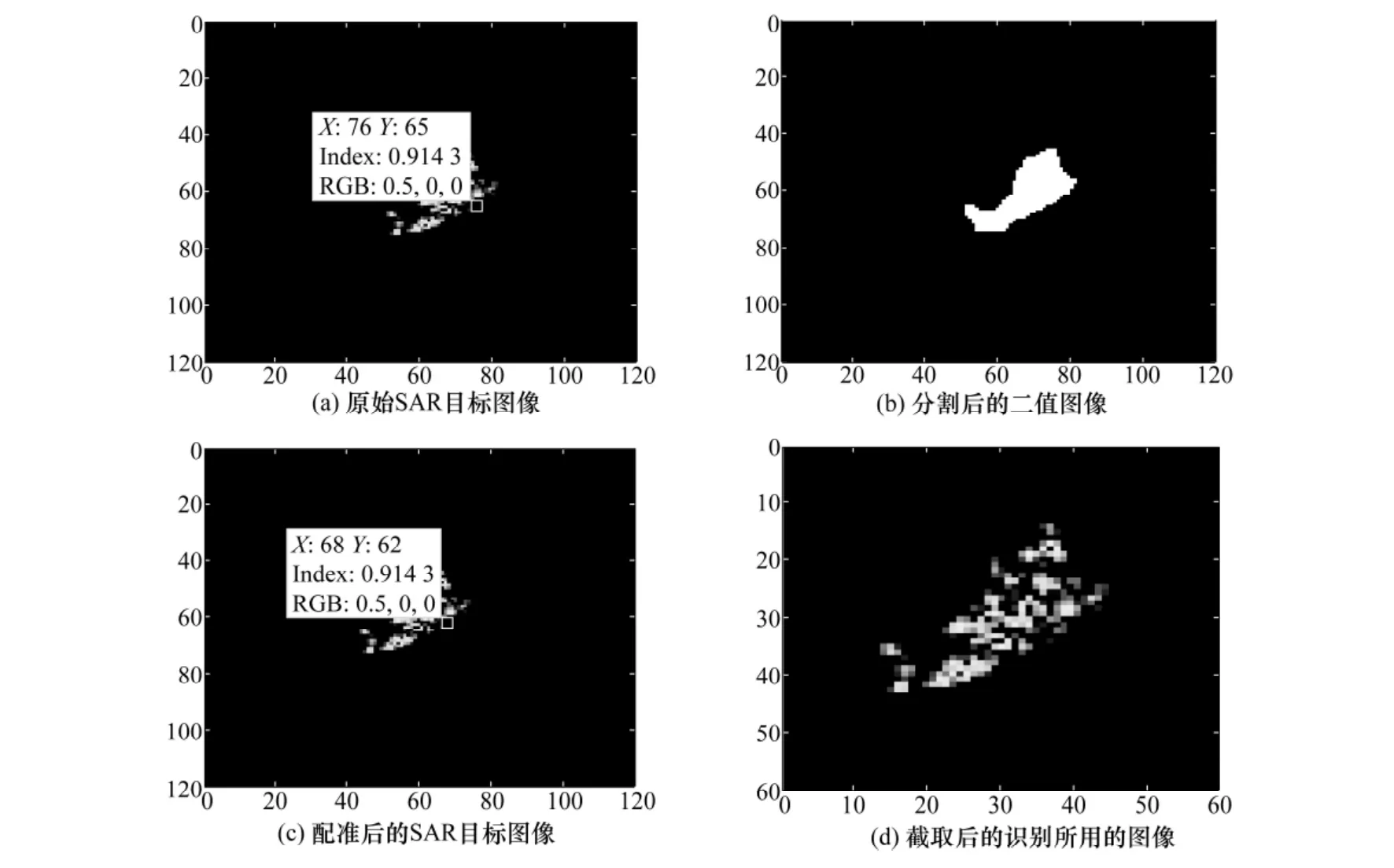
图2 图像预处理过程示意图
1.2 训练阶段
1.2.1 预处理
按照第1.1节中所述的预处理方式对所有的原始训练样本进行处理,得到大小为63像素×63像素的识别所用的训练样本。一方面,对所有识别所用的训练样本的图像域幅度信息列向量化,构成图像域幅度信息数据矩阵S1=[t1t2…tNum]∈Rd×Num,式中,ti∈Rd(i=1,2,…,Num)表示第i个训练样本的图像域幅度信息向量,d表示信息向量的维数,Num为训练样本数目。另一方面,将所有识别所用的训练样本图像通过二维傅里叶变换转化到频域,并将其频域幅度信息列向量化,构成频域幅度信息数据矩阵S2=[p1p2…pNum]∈Rd×Num,式中,pi∈Rd表示第i个训练样本的频域幅度信息向量。
1.2.2 字典学习
本文中采用文献[7]中提出的LC-KSVD方法分别对目标图像域幅度信息和频域幅度信息进行字典学习。LCKSVD字典学习的模型可以表示为

式中,K表示信息的种类数;Sk∈Rd×Num表示字典学习时的输入信号(训练样本),本文中是指训练样本的某种信息矩阵,Num为训练样本数目;Ak∈Rd×n表示第k种信息的字典,d为样本信息向量的维数,n为字典尺寸,即字典原子的数目;Xk∈Rn×Num表示Sk对应的稀疏系数矩阵,xki(i=1,2,…,Num)表示Xk的第i列;Qk是对输入信号稀疏编码结构的控制,用来控制稀疏系数的稀疏模式,其具体定义可参考文献[7];Fk为一个线性变换矩阵;‖Sk-AkXk‖22表示重构误差;‖Qk-FkXk‖22表示稀疏编码误差;α用于调整重构误差和稀疏编码误差之间的权重。该方法的目的在于基于训练样本Sk学习得到一个字典,该字典既可以较好地对训练数据进行重构,又具有一定的可鉴别性,其求解方法参考文献[7]中LC-KSVD的求解过程。
本文中,采用上述的LC-KSVD方法分别对识别所用的训练样本的图像域幅度信息矩阵S1和频域幅度信息矩阵S2进行字典学习,求得图像域幅度信息字典A1及频域幅度信息字典A2,用于后续的测试阶段。
1.3 测试阶段
1.3.1 预处理
采取与训练阶段相同的处理方式对测试样本进行预处理,并利用预处理后的测试图像得到测试样本图像域幅度信息向量y1及频域幅度信息向量y2。
1.3.2 联合动态稀疏表示
本文中,结合训练阶段学习得到的字典A1和A2,采用联合动态稀疏表示模型[4]对测试样本的图像域幅度向量y1、频域幅度向量y2进行稀疏求解,得到测试样本的2种信息在学习字典下的稀疏表示系数x1和x2。
基于文献[4]中的联合动态稀疏表示模型,结合本文中所使用的2种信息,联合动态稀疏表示模型可表达如下:
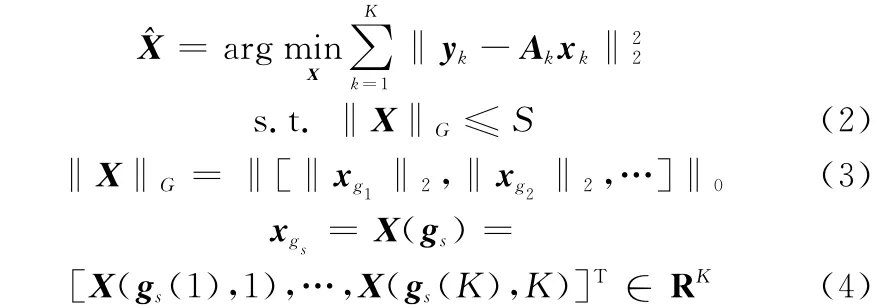
式中,yk∈Rd表示测试样本的第k种信息向量;Ak表示第k种信息字典,本文中Ak由训练样本的第k种信息数据矩阵经过字典学习求得,如1.2.2节所描述。xk∈Rn表示测试样本的第k种信息向量对应的稀疏表示系数,X=[x1, x2,…,xK]∈Rn×K表示同一测试样本多种信息向量对应的稀疏系数矩阵,K表示信息的种类数,本文方法中K=2。gs∈RK表示动态集合,其由稀疏系数矩阵X中属于同一类系数的索引构成,示意图如图3所示。
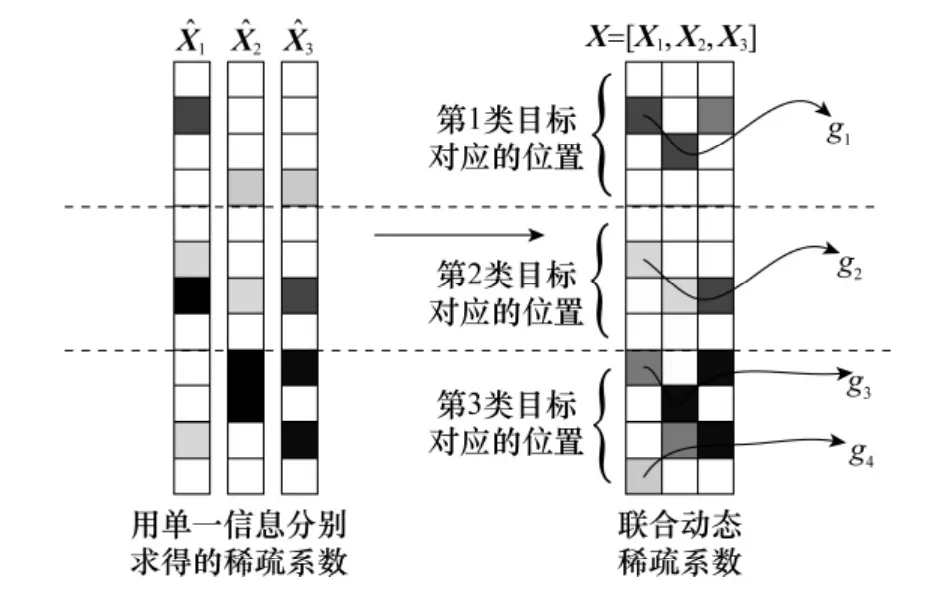
图3 联合动态稀疏表示示意图(参考文献[4]中的图2绘制)
文献[4]中的联合动态稀疏表示模型有2种应用:第1种,将训练样本图像划分为多个不同区域的子图像,对不同的区域的子图像分别构造相应的字典,采用联合动态稀疏表示模型对测试样本的不同区域的子图像求解相应区域的稀疏表示系数,根据重构误差得到最终的识别结果。该应用强调同一目标的多个区域在对应的字典中有相似的稀疏表示模式。第2种,利用所有的训练样本构成字典,采用联合动态稀疏表示模型对测试样本的多幅视图进行稀疏求解,其强调测试样本的多幅视图在同一个字典中拥有相似的稀疏表示模式。
本文中,训练阶段采用LC-KSVD方法分别对训练样本的图像域幅度信息、频域幅度信息进行字典学习,测试阶段结合学习到的2种信息的字典,采用联合动态稀疏表示模型求解测试样本的图像域幅度信息和频域幅度信息在相应字典下的稀疏表示系数,利用稀疏系数对测试样本进行重构,以重构误差最小准则对测试样本进行识别。本文中的联合动态稀疏表示模型实际上对应于文献[4]中的第1种应用,利用联合动态稀疏表示模型对测试样本的多种信息在各自的字典中求解相应的稀疏表示系数,实质上是限制了同一目标的不同信息在相应字典中稀疏表示模式相似而不一定相同,这与文献[5]中的JSR模型相比,更灵活、更适用于SAR图像目标识别。
1.3.3 识别
在对测试样本的类别进行判断时,本文采用与文献[3-4]中相似的分类准则,基于重构误差完成测试样本类别的判断,其可以表示为
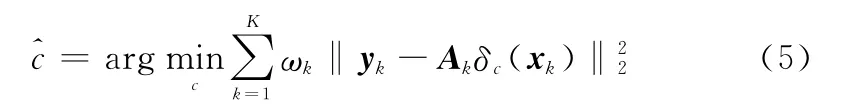
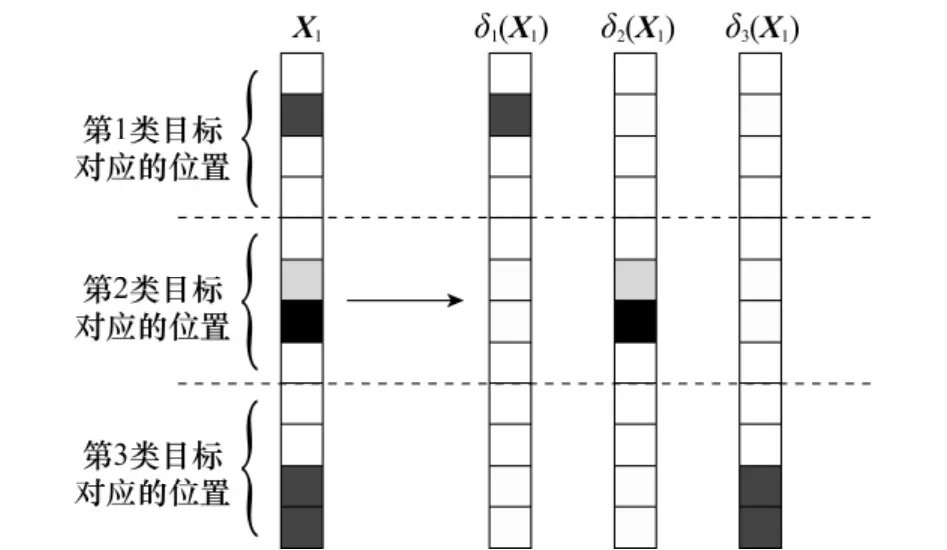
图4 δc(xk)示意图
2 实验结果
2.1 数据集介绍
现有的SAR目标识别文献(例如[2,5,8,9,11-13])中,实验部分常用MSTAR数据集[13]对其方法进行验证,为了便于与现有文献中识别方法进行比较,本文实验部分同样利用MSTAR数据集对所提方法进行验证。该数据集中包含多个俯仰角、多个方位角下的目标图像,本文使用其中的俯仰角为17°和15°下的BMP2、BTR70,以及T72 3类目标的图像进行实验。每一类目标的方位角均由0°变化到360°,目标图像的分辨率为0.3m×0.3m,大小为128像素×128像素。其中BMP2目标又包含了3种不同型号,即BMP2SN9563,BMP2SN9566,BMP2SNC21;BTR70目标包含一种型号BTR70C71;T72目标也包含了3种不同的型号:即T72SN132,T72SN812,T72SNS7。
为了验证本文方法对于目标型号变体的识别性能,文献[12]中的实验设置方法,如表1所示,选取17°俯仰角下的3种型号的目标图像作为训练样本,15°俯仰角下的7种型号目标图像作为测试样本,可以看到同一类目标中部分测试样本的型号与训练样本相比发生了变化。

表1 实验中的训练样本和测试样本型号及数目(参考文献[12]中的实验设置方法设置)
2.2经过配准预处理的实验
2.2.1 实验方法及参数的设置
为了验证本文算法的有效性,将本文方法(记为OURS)与参考文献[3]的SRC方法、参考文献[4]的JDSR方法及参考文献[7]的LC-KSVD1、LC-KSVD2方法进行比较。这里的SRC是指只利用目标图像域幅度信息进行稀疏表示,根据重构误差对测试样本进行识别。JDSR是指由训练样本的图像域幅度信息、频域幅度信息直接构成字典,采用联合动态稀疏表示模型对测试样本的图像域幅度信息、频域幅度信息2种信息进行稀疏表示,根据重构误差进行分类。LC-KSVD1、LC-KSVD2是指仅对训练样本的图像域幅度信息进行字典学习,按照参考文献[7]中的线性分类方法对测试样本进行识别。
实验中,识别所用的训练和测试样本的大小均为63像素×63像素,因此每一种信息特征向量的维度d=63×63=3 969。
本文方法结合了样本的图像域幅度信息及频域幅度信息,因此K=2。训练阶段的字典学习部分及测试阶段的联合动态稀疏表示部分的稀疏度S统一设置为15。
训练阶段的字典学习时,LC-KSVD方法中的参数α通过3折交叉验证方法进行选取。当α选取A=[0.000 1 0.001 0.01 0.1 1]中不同值时对应的识别率不同,其结果如图5所示。交叉验证的结果显示α=0.001时,识别结果最优,因此在后续实验中统一设置α=0.001。对比SRC方法、JDSR方法、LC-KSVD1方法、LC-KSVD2方法的稀疏度同样设为15,同时LC-KSVD1、LC-KSVD2方法中的参数α=0.001。
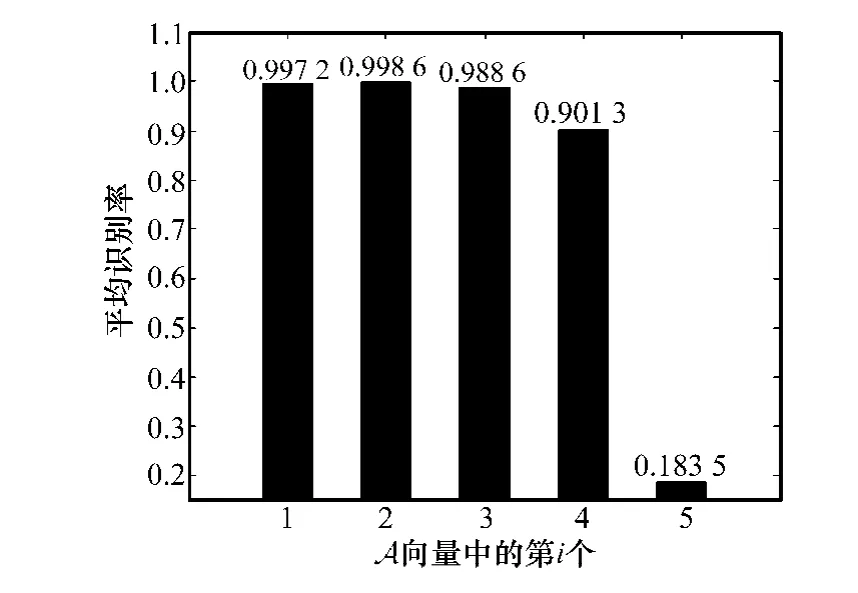
图5 交叉验证选取参数α
2.2.2 识别结果比较
为了研究字典尺寸(字典原子的数目)对识别性能的影响,将字典尺寸设定为[69 75 87 99 114 138 174 231 350 467],图6为5种方法在字典尺寸变化时的平均识别率结果,其中LC-KSVD1、LC-KSVD2、OURS的实验结果均为5次实验平均后的结果。如图6所示,整体上5种方法随着字典尺寸的增大识别率均成上升趋势。随着字典尺寸的减小,本文的方法在字典尺寸较小时具有更高的平均识别率。在字典尺寸较小时,SRC方法的结果出现波动,其原因分析如下。
SRC方法的字典是由训练样本的图像域幅度信息直接构造的,实验中,字典尺寸较小时,字典尺寸变化较小,如字典尺寸为69、75时,字典中仅相差6个原子,此时字典包含的各类目标信息变动性较小,因此SRC的识别结果可能会出现波动。
与SRC相比,LC-KSVD1、LC-KSVD2方法经过了鉴别字典学习,学习后的字典在字典原子数目较少时仍能较全面地包含各类目标信息,因此其识别性能有明显提升,这也验证了字典学习的有效性。JDSR方法的识别结果明显好于SRC的识别结果,这表明联合利用目标的图像域幅度信息与频域幅度信息2种信息比单一采用图像域幅度信息对于SAR图像目标识别更有效。本文方法在训练阶段分别对训练样本的图像域幅度信息及频域幅度信息进行了字典学习,学习后的字典在字典原子数目较少时依然较全面地包含各类目标信息,在测试阶段又结合学习的字典,采用联合动态稀疏表示模型对测试样本的两种信息进行稀疏系数求解。与其他4种方法相比,本文方法综合利用了字典学习及结合多种信息进行稀疏表示两方面的优势,在字典尺寸较小时有明显的优势,且对字典尺寸不敏感,有较好的稳定性。
在字典尺寸较大时,如图6中所示,在字典尺寸大于350时,本文方法与JDSR的识别率相当,而SRC与LCKSVD1、LCKSVD2的识别率也相当。这说明当字典使用足够多的训练样本作为原子来构造时,直接利用训练样本构造的字典与使用字典学习算法学习得到的字典相比,可以得到类似的分类性能。直接基于训练样本构造的字典已经可以充分地包含各类目标的信息,经过字典学习并没有提供更多对于分类有益的信息。因此,字典学习的优势主要体现在字典原子数目较少的情况下。
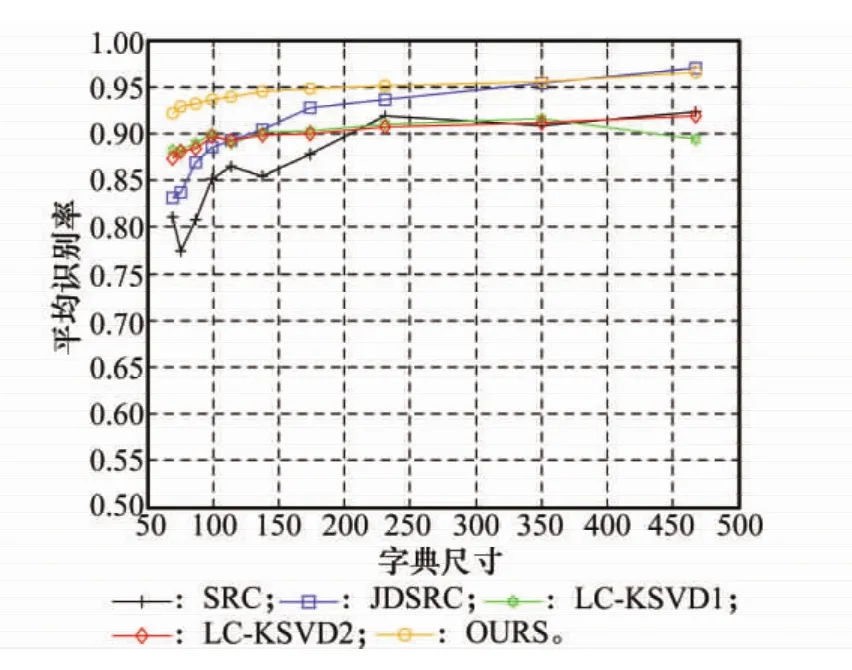
图6 各种方法的平均识别率随字典尺寸变化曲线
为了验证在字典尺寸较小情况下本文方法对目标变体的识别优势,将字典尺寸设置为75,比较5种方法下各型号目标的识别结果。表2为5种方法对各型号目标的识别率及平均识别率。
如表2所示,在字典尺寸为75情况下,本文方法对7种型号的目标,特别是对4种型号目标变体BMP9566、BMPC21、T72S7、T72812有相对较好的识别结果,验证了本文结合字典学习及结合目标多种信息进行联合动态稀疏表示的有效性。

表2 不同方法在字典尺寸为75时的各型号的识别率及平均识别率%
2.3 未经配准预处理实验
为了验证本文方法对SAR图像中目标位置变化的稳健性,对原始的训练数据不再进行配准预处理,而只是分别对所有原始训练样本及测试样本截取图像中大小为63像素×63像素中间区域作为识别所用的训练样本及测试样本。此时,截取后图像中的目标位置并不一定都位于图像中心,有些目标会略微地偏移图像的中心位置。通过比较经过配准预处理和未经过配准预处理2种情况下的本文方法及参考文献中SRC方法、LC-KSVD2方法、JDSR方法的识别性能,验证本文方法对图像中目标位置发生上述变化时的稳健性。同时改变稀疏度,观察不同稀疏度下各方法的识别结果。
参照实验2.2.1部分进行实验参数的设置,α=0.001,稀疏度设置为[5 10 15]。字典尺寸设为[69 75 87 99 114 138 174]。
为了验证本文方法对图像中目标位置变化的稳健性,令稀疏度S=5,比较经过配准预处理和未配准预处理2种情况下各方法的变化趋势。
图7中4幅分图分别为SRC方法、LC-KSVD2方法、JDSR方法及本文方法在配准与未配准2种情况下平均识别率随字典尺寸变化的变化曲线,方形的曲线为经过配准预处理时各方法的实验结果,菱形的曲线为未经过配准预处理时的实验结果。如图7(a)和图7(b)所示,与配准情况下相比,在未配准情况下仅利用目标图像域幅度信息的SRC、LC-KSVD2方法的识别结果下降较明显,说明这2种方法对目标在SAR图像中的位置配准要求较高,没有较好的稳健性。图7(c)和图7(d)中JDSR方法及本文方法结合了目标图像域幅度信息和频域幅度信息,在2种情况下的识别结果相差较少,这表明结合频域幅度信息,有效地解决了SAR目标识别中识别方法对目标位置的敏感性问题,验证了本文方法具有较强的稳健性。
下面对稀疏度对识别率的影响进行分析。图8中的3个分图分别为稀疏度为5、10、15时,未配准情况下SRC方法、JDSRC方法、LC-KSVD2方法及本文方法的平均识别率随字典尺寸的变化曲线。实验结果表明,在不同稀疏度下本文方法具有较稳定的识别结果。
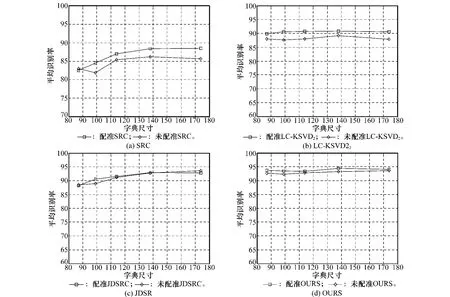
图7 配准与未配准2种情况下各方法的识别结果

图8 未配准情况下4种方法的平均识别率在不同稀疏度下随字典尺寸的变化曲线
3 结束语
本文结合SAR图像目标的图像域幅度信息及频域幅度信息,在对训练样本的2种信息进行字典学习的基础上,采用联合动态稀疏表示模型对测试样本的2种信息进行稀疏系数求解,根据重构误差对测试目标进行识别。实验结果表明,本文方法比采用单一信息对目标识别具有更好的识别性能。经过字典学习,在字典尺寸较小时本文方法依然能够较全面包含目标的信息,减少了联合稀疏表示的计算量和存储量,能够较高效地完成SAR图像目标的识别。此外,本文方法对SAR图像目标的位置变化也体现出了一定的稳健性。
为了便于与现有文献中识别方法进行比较,同时也由于实际中录取较完备SAR目标数据集存在较大困难,目前本文仅利用分辨率为0.3m×0.3m的MSTAR数据集对方法进行了验证。随着SAR目标识别技术的不断发展,相信将来会出现更多的SAR目标数据集。本文下一步工作的一个重要方面就是在将来存在更多可用数据集的情况下,进一步对算法进行验证,以提高算法的实用性。
参考文献:
[1]Zhang H,Wang C,Zhang B,et al.Target recognition in high resolution SAR images[M].Beijing:Science Press,2009(张红,王超,张波,等.高分辨率SAR图像目标识别[M].北京:科学出版社,2009.)
[2]Han P,Wu R B,Wang Z H,et al.SAR automatic target recognition based on KPCA criterion[J].Journal of Electronics and Information Technology,2003,25(10):1297-1301.(韩萍,吴仁彪,王兆华,等.基于KPCA准则的SAR目标特征提取与识别[J].电子与信息学报,2003,25(10):1297-1301.)
[3]Wright J,Yang A Y.Robust face recognition via sparse representation[J].IEEE Trans.on Pattern Analysis and Machine Intelligence,2009,31(2):210-227.
[4]Zhang H C,Nasrabadic N M,Zhang Y N,et al.Joint dynamic sparse representation for multi-view face recognition[J].Pattern Recognition,2012,45(4):1290-1298.
[5]Zhang H C,Nasrabadic N M,Zhang Y N,et al.Multi-view automatic target recognition using joint sparse representation[J].IEEE Trans.on Aerospace and Electronic Systems,2012,48(3):2481-2497.
[6]Aharon M,Elad M,Bruckstein A,et al.K-SVD:an algorithm for designing overcomplete dictionaries for sparse representation[J].IEEE Trans.on Signal Processing,2006,54(11):4311-4322.
[7]Jiang Z L,Lin Z,Davis L S.Label consistent K-SVD:learning a discriminative dictionary for recognition[J].IEEE Trans.on Pattern Analysis and Machine Intelligence,2013,35(11):2651-2664.
[8]Hu L P.Study on SAR images target recognition[D].Xi’an:Xidian University,2009.(胡利平.合成孔径雷达图像目标识别技术研究[D].西安:西安电子科技大学,2009.)
[9]Yin K Y.Study on SAR image pressing and ground target recognition technology[D].Xi’an:Xidian University,2011(尹奎英.SAR图像处理及地面目标识别技术研究[D].西安:西安电子科技大学,2011.)
[10]Hu L P,Liu H W,Wu S J.Novel Pre-processing method for SAR image based on automatic target recognition[J].Journal of Xidian University,2007,34(5):733-737(胡利平,刘宏伟,吴顺君.一种新的SAR图像目标识别预处理方法[J].西安电子科技大学学报,2007,34(5):733-737.)
[11]Chao Y,David C.MSTAR 10-class classification and confuser and clutter rejection using SVRDM[C]∥Proc.of the SPIE,2006:624501-624514.
[12]Ding J,Liu H W,Wang Y H.SAR image target recognition based on non-negative sparse representation[J].Journal of Electronics &Information Technology,2014,36(9):2194-2200(丁军,刘宏伟,王英华.基于非负稀疏表示的SAR图像目标识别方法[J].电子与信息学报,2014,36(9):2194-2200.)
[13]Ross T,Worrell S,Velten V,et al.Standard SAR ATR evaluation experiments using the MSTAR public release data set[C]∥Proc.of the Part of the SPIE Conference on Algorithms for Synthetic Aperture Radar Imagery V,1998:566-573.
E-mail:ajiao3744@163.com
王英华(1982-),通信作者,女,副教授,主要研究方向为SAR图像目标检测与识别。
E-mail:yhwang@xidian.edu.cn
丁 军(1982-),男,博士研究生,主要研究方向为雷达目标识别。
E-mail:dingjun410@gmail.com
刘宏伟(1971-),男,教授,博士生导师,主要研究方向为自适应信号处理、雷达信号处理、雷达目标识别。
E-mail:hwliu@xidian.edu.cn
SAR target recognition based on multi-information dictionary learning and sparse representation
QI Hui-jiao,WANG Ying-hua,DING Jun,LIU Hong-wei
(National Key Laboratory of Radar Signal Processing,Xidian University,Xi’an 710071,China)
To improve the synthetic aperture radar(SAR)target variant recognition performance,on the basis of the discriminative dictionary learning and joint dynamic sparse representation model,a new SAR target recognition method is proposed based on the multi-information dictionary learning and sparse representation.In the training stage,the discriminative dictionary learning method label consistent KSVD(LC-KSVD)is used to learn dictionaries for both the image domain amplitude information and the frequency domain amplitude information of the targets.In the test stage,based on the learned dictionaries for the two kinds of information,the test target representation coefficients for the two kinds of information are computed using the joint dynamic sparse representation model.Finally,the test target can be classified according to the representation residual for the two kinds of information.The MSTAR dataset is used to verify the effectiveness of the proposed method.Experimental results show that the proposed method has better recognition performance than some existed methods.
synthetic aperture radar(SAR);target recognition;dictionary learning;joint dynamic sparse representation
TP 95
A
10.3969/j.issn.1001-506X.2015.06.09
齐会娇(1989-),女,硕士研究生,主要研究方向为SAR图像目标识别。
1001-506X(2015)06-1280-08
2014-06-17;
2014-10-10;网络优先出版日期:2014-11-28。
网络优先出版地址:http://www.cnki.net/kcms/detail/11.2422.TN.20141128.1055.004.html
国家自然科学基金(61201292,61322103,61372132);全国优秀博士学位论文作者专项资金(FANEDD-201156);国防预研基金;中央高校基本科研业务费专项资金资助课题
