支持云计算环境的MapReduce模拟器设计
2015-08-09张国平
张国平,黄 淼,马 丽
(平顶山学院 软件学院,河南 平顶山 467000)
0 引言
MapReduce[1]已成为支持云计算的关键技术之一,流行的MapReduce模型实现包括Mars、Phoenix、Hadoop和Google的实现[2],其中,Hadoop因其开源特性而最受欢迎,然而,Hadoop大量的配置参数给用户带来一些挑战[3].
云计算环境下,通常很难确定出有助于实现良好性能的参数集,即映射器数目、节点数目及其CPU速度、缓冲区大小,建立物理Hadoop环境评估具有上百甚至上千节点的Hadoop应用的扩展性变得非常困难甚至不可能实现[4].而这些挑战使得必须存在一种可以调整Hadoop集群性能的模拟器,现有的MapReduce模拟器往往仅限于简单行为的应用[5].
基于上述分析,本文设计了一种支持云计算的MapReduce模拟器,主要贡献在于模拟Hadoop环境动态行为的高精度,模拟器中可对大量Hadoop参数建模,如节点参数、集群参数、Hadoop系统参数及模拟器参数.
模拟器的精度验证遵循两个步骤:一、针对权威基准研究验证;二、评估它的行为,比较使用两个Hadoop应用的物理Hadoop集群中模拟器的行为.比较结果表明,本文设计的模拟器在模拟Hadoop环境中获得了较高的精度和稳定性.
1 Hadoop参数建模
Hadoop应用的性能受很多参数的影响,本节将描述对这些参数的建模.
1.1 节点参数
处理器:模拟器缺省设计支持每个计算机一个处理器,但是处理器的数目可以改变,一个处理器可以有一个或多个内核,一个处理器内核的处理速度定义为每秒处理的数据单位量,可以从真实实验测试中测量.
硬盘:硬盘实体中,IO操作速度随时变化,引入多个参数构建递减读/写模型,令xmax表示硬盘的最大读/写速度,从测试Seagate Barracuda 1 TB硬盘的实验结果得知,xmax读速约为120 MB/s,写速约为60 MB/s.令xmin表示硬盘的最小读/写速度,xmin读速约为55 MB/s,写速约为25 MB/s.另一个参数,递减系数r表示每秒速度降低多少,基于实验测试该系数约为0.005 6.使用这些参数利用式(1)能计算出硬盘的实时速度x:
(1)
内存:在每个内存实体中建模两个参数:读和写,实验测试中,多通道标准DDR2-800内存的读速高达6000 MB/s,写速高达5000 MB/s.很明显,如此高的读速和写速都不是系统的瓶颈.
以太网适配器:在每个以太网适配器实体中建模两个参数:上行带宽和下行带宽,带宽范围在100~1000 Mbps.
1.2 集群参数
集群参数表示所模拟的Hadoop集群的详细信息,涉及多个方面,包括节点数目、拓扑结构和网络设施[6].
节点数目:节点数目在1到几百之间变化.
拓扑结构:节点数目可组织成某种网络拓扑结构,目前的模拟器仅支持简单机架.
网络设施:路由器速度范围为100~1000 MB/s,定义路由器带宽时,必须配置一些独立计算机连接到路由器,从而确定它们的网络容量.
作业队列和作业调度:作业队列存放等待作业实体,根据不同的作业调度器,作业等待处理资源,模拟器支持Hadoop框架的两个作业调度器,先进先得调度器和公平调度器,这两类调度器产生不同的作业处理顺序.
1.3 Hadoop系统参数
Hadoop应用开始处理数据之前,数据应该预先保存到Hadoop分布式文件系统 (Hadoop distributed file system, HDFS),文件的数目影响涉及的映射实例数目[7].
作业说明:描述作业属性涉及许多参数,JobID指跟踪作业时分配给每个作业的唯一ID,是输入数据的总大小,无论提交多少数据块,该值为整个数据的总大小.
模拟Hadoop参数:这组参数与Hadoop框架高度相关,io.sort.mb表示排序映射输出时所用的内存缓冲区大小.io.sort.record.percent表示io.sort.mb为存储映射输出结果记录边界预留的比例,剩余空间用于映射输出记录它们本身.io.sort.spill.percent参数是一个阈值,确定映射实例何时启动溢出过程写数据到内存.若达到阈值,CPU处理暂停,刷新缓冲区,意味着所有保存在虚拟内存中的数据将溢出到硬盘.io.sort.factor(1)参数指定映射阶段排序文件时合并的最大流数目,该参数显著影响系统的IO参数.mapred.reduce.parallel.copies指用于拷贝映射输出到化简器的线程数目,根据硬件资源使用适当数目的拷贝线程会提升系统性能.io.sort.factor(2)表示化简阶段执行排序文件时合并的最大流数目.The mapred.job.shuffle.input.buffer.percent为混洗拷贝阶段分配给映射输出缓冲区的总堆大小比例.mapred.inmem.merge.threshold表示启动合并输出和溢出到硬盘过程的映射输出数目阈值,使用该参数,内存中能够操作较小数目的映射器输出,而非局部硬盘,因此硬盘执行排序和合并产生较少开销.JVM Reuse参数在模拟器中部分模拟,使用JVM Reuse,可显著降低一些短期任务产生的开销.
1.4 模拟器参数
模拟器本身需要一些参数控制其自身行为,下面介绍模拟器中的重要参数.
系统时钟:一个绝对且连续的计时元件,每次改变系统时钟,当前值会加1 s,用于记录当前系统时间,测量各种集群配置中Hadoop应用的性能.
执行速度:控制模拟器中所有元件的执行速度.
精度级别:对于正常Hadoop应用,将该参数设为秒级,为了维持模拟中的高精度,也可设为毫秒级.
共享参数:控制共享资源的比率,包括硬盘和带宽.比率定义为:r=AssignedResource/TotalResource.
2 模拟器设计
基于Hadoop框架,本节描述模拟器的设计.
2.1 模拟器架构
为了执行模拟,从集群读取集群参数,创建一个模拟的Hadoop集群环境.初始化指定数目的节点,使用某种拓扑结构分配这些节点.配置好集群后,由集群读取处理节点参数,而且指定节点类型,包括处理器、硬盘、内存、主节点、备节点、映射实例和化简实例.这个初始化过程既能创建同构节点也能创建异构节点.然后模拟的集群已准备好使用各种作业调度器从作业队列检索传入作业,作业说明将由作业读取元件处理,作业提交给模拟器进行模拟.
模拟器遵循主备模式,模拟的映射实例(MapperSim)、化简实例(ReducerSim)、JobTracker(作业跟踪器)和任务跟踪器位于这些节点[8].
2.2 MapperSim
当Hadoop应用提交到模拟器时,将输入数据分割成许多数据块,每个数据块与一个映射实例关联,处理过程中,分配每个任务给映射实例执行,映射实例的操作由MapperSim元件模拟.
MapperSim模拟每个节点上映射实例(映射器)的操作,它拷贝保存在HDFS上的数据到它自己的局部硬盘,通常每个MapperSim处理一个文件块,但如果HDFS仅保存了一个文件块时,则分割的逻辑块数目可控制作业中涉及的MapperSim实例数目.数据拷贝并保存在局部硬盘后,MapperSim开始处理数据,基于模拟的Hadoop应用的作业说明.处理过程中会产生中间数据,为了改善IO性能,中间数据将写入内存缓冲区.缓冲区中能够预排序数据,以便获得高效率.数据一直往缓冲区中写入,若达到阈值,则启动背景线程将数据溢出到硬盘,溢出发生时中间数据持续写入到缓冲区.若这段时间内缓冲区满了,则CPU处理受阻塞,直到溢出程序完成.对于每个输出的溢出块,在它写入硬盘之前,背景线程将划分块成与化简实例相关的分区,这期间会有内存预排序,若需要合并函数,排序后这个步骤中还涉及合并器,任务完成后,分区合并成单个文件,包含待拷贝到化简实例的有序数据.
2.3 ReducerSim
ReducerSim元件模拟Hadoop框架中的化简实例,用于收集MapperSim的输出,化简到HDFS的最终输出.
MappererSim元件中的输出文件保存在局部硬盘,ReducerSim元件因其特殊划分需要多个MapperSim元件的输出.当一个输出准备好时ReducerSim开始拷贝数据,每个ReducerSim有多个拷贝线程,以便它能并行拷贝多个MapperSim元件的输出结果.对于某些Hadoop应用,化简实例可能需要处理涉及处理器但没有IO操作的数据,模拟器中的ReducerSim支持该特性,序列图如图1所示.
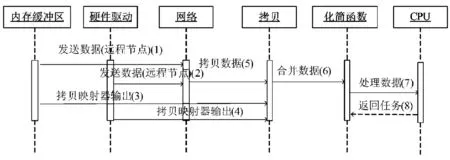
图1 ReducerSim中的硬件交互
2.4 作业跟踪器和任务跟踪器
作业跟踪器主要用于跟踪模拟的作业,任务跟踪器用于运行单个任务.当提交了作业时,发送作业ID到作业跟踪器进行跟踪,作业跟踪器开始计算作业的输入分割,然后为每个分割创建一个映射任务.任务跟踪器通过检测信号周期性发送消息到作业跟踪器,告诉作业跟踪器该任务跟踪器正在工作,作为部分检测信号,任务跟踪器将告知是否完成当前任务并准备运行新任务,图2表示模拟器中元件的工作流.

图2 模拟器的工作流程
3 实验
为了验证模拟器,本文执行了许多测试,比较了模拟器的性能与公开的基准结果,还建立了Hadoop集群的实验环境,用本文的Hadoop应用评估了模拟器.
3.1 用基准验证模拟器
使用文献[9]提出的3个基准结果验证模拟器,这3个基准为Grep任务、选择任务和UDF聚合任务.
3.1.1 Grep任务
在这项任务中精确模拟文献[9]中基准研究所做的工作,分别使用1个节点、10个节点、25个节点、50个节点和100个节点模拟集群,测试两个场景:一个是分配给每个节点535MB数据去处理;另一个是提交1 TB数据到集群.每种场景评估5次,模拟结果分别如图3所示,它们接近于基准结果.两种场景的置信区间小(第一种场景中在0~2.6 s范围内,第二种场景中在4.1~7.6 s范围内),表明了模拟器的稳定性能.
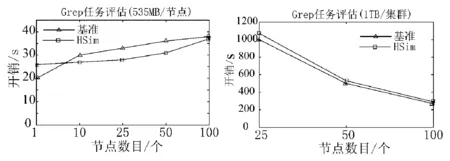
(a)535 MB/节点 (b) 1 TB/集群
选择任务的目的是观察Hadoop框架处理复杂任务的性能,每个节点处理1 GB排序表,使用用户定义的阈值检索目标pageURLs,本文模拟了这个任务,模拟结果如图4(a)所示.

(a)选择任务评估 (b)聚合任务评估
3.1.2选择任务
从图4(a)可以看出,模拟结果接近基准结果,置信区间小,在2.6~6.6 s范围内.
3.1.3 UDF聚合任务
UDF聚合任务读生成的文档文件,搜索出现在内容中的所有URLs,然后对于每个唯一URL,模拟器计数表示整个文件集中特定URL的唯一页的数目,模拟结果如图4(b)所示,从图中可以看出,仍然与基准结果接近,有小置信区间,表明了模拟器的高稳定性.
3.2 用定制的Hadoop应用评估模拟器
本文实现了两个Hadoop应用:信息检索和基于图像标注的内容,在Hadoop实验集群和模拟器中评估两个应用,本节给出了评估结果.
3.2.1实验和模拟环境
Hadoop实验集群由4个节点组成,3个节点用作数据节点,CPU Q6600@2.4G,RAM 3GB,230 GB Seagate硬盘,运行OS Fadora 12,一个节点用作命名节点,CPU C2D7750@2.26G, 2 GB RAM,运行OS Fadora 12.每个数据节点缺省集群配置下采用4个映射器和1个化简器,网络带宽1 Gbps.使用模拟器模拟Hadoop集群,与上述实验集群的配置相同.
3.2.2MR-LSI
MR-LSI[1,5]是基于分布式LSI算法用于信息检索的MapReduce,使用Hadoop框架设计并实现MR-LSI,MR-LSI拥有映射和化简函数,包含大量IO操作,本文在实验环境和模拟器中评估了MR-LSI,结果如图5(a)所示.

(a) MR-LSI (b) MR-SMO
从图5(a)可以看出,模拟器的整体性能基本上与真实Hadoop集群接近,尤其是处理大尺寸数据集和涉及增加映射器数目的MapReduce作业的场景.此外,模拟器显著优于MRPerf,相比真实Hadoop集群的性能,正如前面所讨论,使用太多Hadoop参数值的估计限制了MRPerf模拟MapReduce行为的精度.
3.2.3MR-SMO
MR-SMO[10]是基于分布式SMO算法的针对基于图像注释内容的MapReduce,MR-SMO建立在Hadoop框架基础上,也涉及映射和化简函数.在实验Hadoop集群和模拟器中评估了MR-SMO,还利用MRPerf模拟器评估了MR-SMO的性能.从图5(b)可以看出,使用模拟器的模拟集群性能与真实Hadoop集群的性能相当接近,而MRPerf不能产生精确模拟结果.
3.3 评估Hadoop参数
前文已提到,许多参数会影响Hadoop应用的性能,为了研究这些参数的影响,本文使用模拟器执行了一系列模拟测试.研究了3个重要参数的影响,即数据块大小、缓冲区大小和排序系数,通过调整它们的值.使用MR-LSI算法作为这些测试中的一个Hadoop应用,使用表1所示配置的模拟器模拟Hadoop集群.
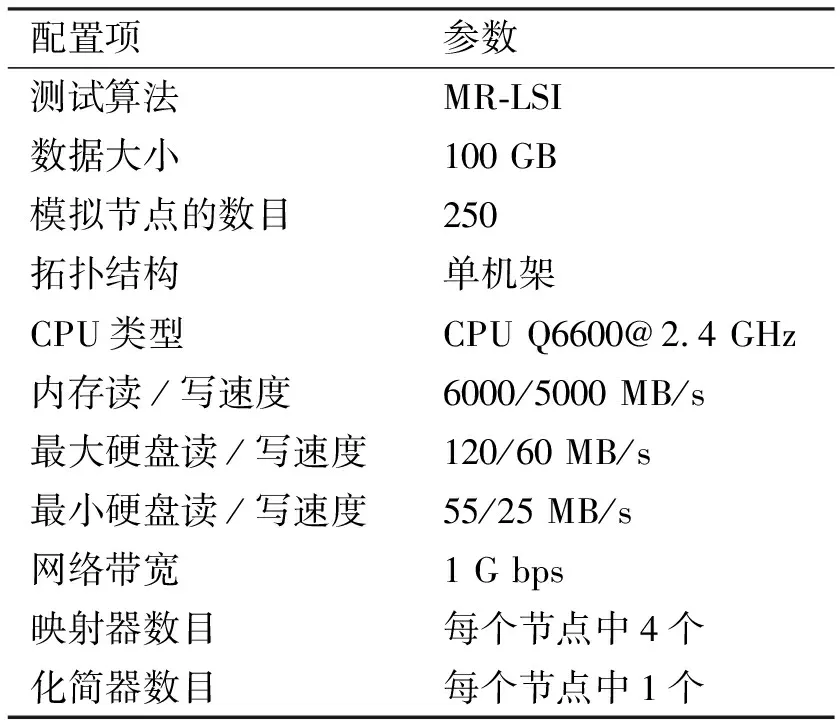
表1 使用模拟器模拟Hadoop集群配置
3.3.1块大小
增加数据块大小会减少映射波形和IO操作数,在这些测试中分别采用64 MB和100 MB的数据块大小,图6(a)表示数据块大小对Hadoop应用性能的影响.

(a)数据块的影响 (b)缓冲大小的影响 (c)排序系数的影响
从图6(a)可以看出,当映射器的数目小于800时,使用较大数据块能产生更好的性能,由于映射器波形的数目减少了.但是当映射器数目增加到800时,数据块大小几乎不再影响Hadoop应用的性能,原因是映射器数目变大时,仅涉及小数目映射器波形.例如,在800个映射器的情况下,64 MB和100 MB两种场景需要2个映射器波形产生类似性能.
3.3.2缓冲区大小
待溢出到硬盘的文件数目高度依赖于缓冲区大小,缓冲区越大,产生的文件数目越小,溢出文件数目越小,越能减少IO操作中的开销.本文分别使用100 MB和1000 MB评估了缓冲区大小如何影响Hadoop应用的性能.
从图6(b)中可以看出,使用较大缓冲区能产生较好性能,与涉及的映射器数目无关,原因是基于很多IO的Hadoop应用,使用大缓冲区能减少硬盘操作数目,从而急剧减少开销.
3.3.3排序系数
执行排序时,排序系数控制待合并的最大文件数目,使用大排序系数意味着某一时刻能合并多个文件,这会减少排序开销,如图6(c)所示为使用较大排序系数产生较好性能的场景.
Hadoop框架是一个涉及许多元件的复杂系统,设计并实现模拟器来模拟这些元件及其交互,它以类似于Hadoop框架的方式工作,但是不能简单推断模拟器能够没有任何限制的精确模拟Hadoop,模拟器的精度受许多因素的影响,如作业传播的时间、映射实例的冷启动、键分布、系统通信、共享硬件资源和动态IO负载,这些动态因素会影响实验和模拟结果的性能,依赖于用户应用.
Hadoop的性能合并器特性也会影响模拟器的精度,但是,合并器实例不能在模拟器中完全实现,合并器可以考虑为一个内存排序过程,合并映射器的输出并通过合并器写入中间文件,然后发送文件到化简器,因此当映射器数目小时,使用合并器的益处不明显,但是当映射器数目变大时,包括硬盘读写的系统IO操作和网络实体将显著受益于合并器的使用.
4 结束语
本文设计了一种支持云计算环境的MapReduce模拟器,用于模拟数据密集型MapReduce应用,使用建立的基准结果和实验环境验证了模拟器.结果表明,所设计的模拟器可以精确模拟Hadoop集群的动态行为,可用于研究许多Hadoop参数的影响,通过调整参数值,也可用于研究涉及数百个节点的MapReduce应用的扩展性.
Hadoop框架的一个显著特点是支持异构计算环境,但是,Hadoop目前的应用仅采用先进先出和公平调度,不支持考虑各种计算机资源的负载平衡.未来研究将考虑将负载平衡加入到模拟器,利用它来对Hadoop框架进行可能性扩展.此外,还计划在模拟较大型Hadoop集群中进一步验证模拟器的精度,例如Amazon EC2云.
