文本数据挖掘技术对速记教学及语料库建设的启示——以松下幸之助演讲数据分析为样例
2015-07-22丁潇君高等教育出版社外语与国际汉语出版事业部北京0009北京青年政治学院英语系北京000北京工业大学经管学院北京004
闵 阅,老 青,丁潇君(.高等教育出版社外语与国际汉语出版事业部,北京0009;.北京青年政治学院 英语系,北京000;.北京工业大学经管学院,北京004)
文本数据挖掘技术对速记教学及语料库建设的启示——以松下幸之助演讲数据分析为样例
闵阅1,老青2,丁潇君3
(1.高等教育出版社外语与国际汉语出版事业部,北京100029;2.北京青年政治学院 英语系,北京100102;3.北京工业大学经管学院,北京100124)
摘要:基于文本数据挖掘技术,探讨在速记教学设计中如何培养职业速记人员利用文本数据挖掘技术发现潜在的、有用的知识,以更加有效地开展速记前的信息储备工作。速记笔记符号识别语料库能够解决速记中笔记产出的受阻情况,提升速记笔记记录源信息的质量。
关键词:文本数据;挖掘技术;速记教学;语料库建设
文本数据并非数字型态的数据。以往对这类数据的比较常见的分析方法,是通过截取、引用原文的一部分,再添附分析者的说明、研究等。与之相比,被称为文本数据挖掘的计量分析方法则提出对文本数据加以某种数字化操作,从而进行计量分析。
对文本进行计量分析的目的主要有两点:提高客观性和数据搜索性。例如,一个人以肉眼阅读演讲和发言内容后,能够对演讲或发言内容有一个大概的印象。但是,怎样才能将这些印象客观地展示给第三方呢?当文本数据数量庞大,多至无法全部阅读的时候又该如何呢?若想如根据年代、受众等特征来搜索演讲内容发生了什么变化,又该如何呢?这就需要利用文本数据挖掘的计量分析优势,来解决这些问题。
在实际运用中,文本数据挖掘有三大要素:第一是提取数据;第二是数据分析;第三是分析结果的可视化。也就是说文本数据挖掘必须考虑:怎样减少误差,正确有效地收集必要的信息;该用什么样的方法对这些信息进行科学分析;如何以一目了然的形式来说明体现分析结果。我们可创建数据库、对数据进行处理分析,并对其结果进行研究,具体流程见图1。

图1 文本数据挖掘技术应用研究流程[1]
一、文本数据挖掘技术应用的示范
我们从日本PHP研究所 (松下幸之助于1946年所创立的研究所及出版社)收录整理的松下幸之助讲演集,包括1940年至1987年之间松下幸之助发言记录的文字数据中,特别选定了以面向松下电器集团外部经营者为主的对外演讲(第1卷~第5卷)(以下简称“对外演讲”)和面向松下电器集团内部员工的对内讲话(第22卷至第24卷)两个部分[2]。
我们将松下幸之助共计百余次演讲、发言的内容收入数据库,之后用文本数据挖掘的分析工具在数据库的基础上构建关键词库,从整体数据和特定关键词两个角度进行分析。最后,全面评测分析结果,进行深层解析并讨论,从而对松下幸之助的经营思想全貌进行科学客观的理解分析,探索其经营思想的特征以及其在不同时期的变化。
(一)语素分析与高频词
文本数据挖掘法,将文本数据进行数字化分析研究,它并没有具体特定的分析方法与流程。文本数据挖掘有多种形式,有的是从文本数据中提取高频词,汇总叙述统计量;有的是将观测数据分组;有的是调研一组句子中两个特定词同时使用的倾向,等等。这些研究方法均以语素分析为基础。语素是语言中最小的语音结合体。语素分析是把一个个句子进行语素分离,分析出这句话用了哪些词汇,正确地说是分析每一句话由哪些语素构成,从而获得基本统计量。
例如,我们对松下幸之助的所有演讲和发言都进行语素分析和纠错处理(排除没有分析必要的语言和使用频率较低的词),在此基础上,提取排名靠前的高频词,统计使用该词条的演讲、发言的次数以及该词条总共出现的次数,并将对外演讲和对内讲话进行对比验证。
总结起来,对外演讲和对内讲话的共通点表现在:首先,确认了词条的“出现次数”(词条在所有文本数据中共出现多少次)和“出现演讲场次”(该词条在多少场演讲中被使用过)之间的关联性。也就是说,“出现演讲场次”较多的词,其“出现次数”也较多。其次,高频词涵盖了经营、政治、地域、销售、劳动雇用等多元化领域,同时还发现松下幸之助的特征性语言出现频率并不高。另一方面,与对外演讲较为宏观的视角相比,对内讲话则更多是从职员、工人、个人等比较微观的视角出发。这便是他讲话的一个基本特征。
此外,将关联程度较高的关键词贯穿成线形成关联网络,不仅能看出词条与词条之间的关系,还能了解词条与时代之间的关系。也就是说,可以研究被提取的关键词在不同时期受到松下幸之助本人何种程度的关注,以及不同时期和关键词之间又有怎样的联系。
从松下幸之助个人的角度,根据其生涯经历,将其40多年来的讲演发言,按照三大时期(社长时期、会长时期、顾问时期)划分并进行分析。同时也从另外的角度——经济景气与否的角度,划分为八个经济波动时期,结合经济的变化解析关键词所发生的变化,见表1。

表1 松下幸之助各时期演讲情况统计一览表[2]
通过分析得出,不同时期的讲话既存在共通的词条,也存在不同的关键词组。例如,20世纪50年代后期的社长时期,伴随着事业的扩展、新工厂的建设、大规模批量生产开始,这个时期的对外演讲和对内讲话两方面,都时常提到“工厂”和“生产”这类与制造业相关的关键词。20世纪60年代,随着经济的腾飞,受随之而来的物价上涨的影响,“物价”一词被多次提及。在同一时期,开始推行“顾客第一”的销售战略和积极建设服务网络的新销售制度,这一时期的发言,尤其是对内讲话中,集中出现了“销售”、“销售公司”等词条。20世纪70年代中期开始,面对艰难而不景气的日本,如何进行反省,并结合众人的智慧和力量,建设理想社会成为其主要关注点之一。在该时期,“不景气”、“反省”、“智慧”等关键词频繁出现。从这些关联网络的分析结果来看,对外演讲和对内讲话同样都受到了时代的影响。
(二)特定关键词分析
1.特定关键词的年代变迁分析
在他的演讲中,松下幸之助的经营哲学大多以格言的形式表现出来。作为经营实践中的指导思想和思考方法,“智慧集体经营”、“适应式经营”、“自主责任经营”、“共存共荣的经营”、“人尽其才”等均是松下幸之助提出的经营之道,我们把这些内容相关的词条进行整理,详细分析这些词条在对外演讲和对内讲话中出现频率的增减情况,并研究与各种经营理念有关的词条,在不同的年代是如何被运用的,其受关注时期以及相关的背景信息又是如何。
从其演讲数据分析的结果来看,“智慧集体经营”受关注的时期主要集中在20世纪50年代中期到70年代。50年代初期,受到赴美考察的影响,松下幸之助提出打造合作经营的经营理念,强调必须集中全体员工的智慧来开展经营活动。而“适应式经营”在1965年前后最受关注。当时“昭和40年(1965)大萧条”出现了进一步恶化的趋势,松下幸之助在演讲中提出了“水坝式经营与适应式经营”理念。另外“共存共荣”最受关注的年份也是1965年,松下幸之助向各销售代理店赠送手写的“共存共荣”题词,提高代理店组织的向心力。同时,“自主责任经营”的概念在很长一段时期内受到了松下幸之助的关注。他对于“自主责任经营”的思考,从战前较早的时期就已经开始并在多次讲话中反复强调。至于 “人尽其材”的概念,在战前就已经被提出,50年代初期,他去美国考察时看到了在美国“人尽其材”的实例,因此再度提出了对这一概念的重视[3]。
2.特定关键词的关联语分析
我们可以对特定关键词的周边概念进行分析来确认和特定关键词相关联的词条有哪些。这一关联是从文本数据来推测,一般是通过带有附加条件的概率计算来进行。当输入“出现〇〇特定关键词”这一条件后,系统会自动搜索满足该条件的文章,同时将其中出现频率特别高的词语列成表格。之后进一步使用列表中的高频词构建关联性网络,顾名思义,这是将分析得出的关联性特别强的词条用线连接起来而形成的一种关联词的网状图,见图2。
根据图2所示,我们可以获知如下信息:首先,与“美国”关联最密切的词条是“美国的民主主义”。尤其在谈到经营方面时,松下幸之助多次提到美国的民主主义,认为民主主义,就是要做到“人尽其用,物尽其材”。其次,提到生产性的时候,可以得知他赴美考察时参观了众多公司、工场,对美国的高效率生产非常佩服。对于劳工组织问题,他时常提到美国的工会与日本工会不同,组织结构非常透明。总而言之,可以认为“美国”对松下幸之助的经营理念产生了不小的影响。
上述示范仅在对讲演资料进行文本数据定量分析,解析演讲话题与关键词等方面做了相关展示。作为职业速记工作者。还可进一步从语言含义与深度、地区变化等其它角度入手开展有助于速记信息储备工作的更深层次的探索。
二、文本数据挖掘技术应用的相关启示
(一)文本数据挖掘技术引入速记教学
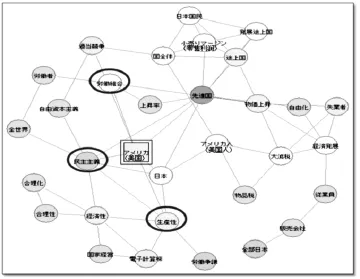
图2 特定关键词“美国”的关联语分析结构示例
大多数情况下,速记活动的过程始终处于倾听状态,基本上无二次重听的机会,职业速记者在听准关键信息的前提下,还要在有限的时间里将听取的信息加以分析与整理,迅速地掌握信息言内与言外之意,之后及时地形成有效笔记并加以保存。因此,文本数据玩具玩技术视角下,速记教学设计应以源语语言应用能力、泛专业知识储备能力为主线展开。具体可分为两个层面:
1.掌握源语语言知识,提高源语语言应用能力[4]
(1)语言分析:侧重言谈形态与逻辑结构的训练,包括基于文本数据挖掘技术的文稿结构分析、语体风格分析,等等;
(2)语言知识:侧重积累多频词汇、常套句的训练,包括基于文本数据挖掘技术源语词语数据库搭建、源语模仿跟述比对,等等;
(3)语言能力:侧重听说读写记能专项技能及综合能力应用训练,如基于文本数据挖掘技术交互转述训练比对、视录速读训练比对,等等。
2.构建泛专业知识体系,拓宽基于英语发言者所属文化及组织的背景知识
(1)泛知识领域学习与整理归类:一般知识吸收注重原理与实务的理解;专业知识吸收注重专业概念、术语辨析与词语的理解。
(2)知识与语言并行训练:潜在性训练(限时网络搜索与阅读)与显著性训练(源语速读与视读)相结合。
(3)速记时(非速录要求),除了数词、术语、专有名词以及引用经典、法条等之外,一般性内容可不采取词对词的方式完成记录,听取与思考并重并行、传讯不传词、意译式速记。
在速记中,我们常常遇到一些直接或间接地影响理解的词语,首先包括传达语言信息重点、表述实际意义的关键词,如名词、动词、形容词、数词等;其次是固定的、约定俗成的、与背景知识关系密切的困难词,如专有名词和专业名词;还有承载一个国家发展历程、社会习俗演变与传承的文化词,如典故、谚语、成语、俚语、诗歌、口号、影视片名等;异国语言与文化影响下创造出来的、多原创于新事物或新概念的外来词,等等。
上述基于文本数据挖掘技术的相关训练更适合于“慕课”环境或“翻转课堂”模式的速记教学。根据受训人员个体情况,开展多样化的 “微技能”培训,可拆解的具体“微技能”包括
频道词典:如分析关键词、困难词、文化词、外来词等在源语中的分布;
半搭配分析:如搜索关键词(某一高频动词)后面的关联与名词分布;
词性排名:基于统计的某一类词(如名词)使用频率排名;
词条比对:对比两个源语的词条超用和少用现象;
词性对比:对比两个源语(如专有名词、专业词语)的用法分布。
在速记教学设计中有意提升受训人员的信息化意识,有序培养职业速记人员利用文本数据挖掘技术发现潜在的、有用的知识,使其更加有效地开展速记前的信息储备工作。
(二)基于文本数据挖掘技术构建速记笔记符号识别语料库
随着信息通讯技术与网络的迅速发展,速记笔记符号与网络语言及文化、普适技术(ubiquitous computing,泛在计算机)产生密切联系,并使速记笔记符号具有模态互转和分享共用的特征。目前,速记模态(如语音识别、文语转换)互转辅助技术已成为现实,研发基于文本数据挖掘技术的速记笔记符号识别语料库已不再是难题。
针对速记笔记信息速符的形式表征,基于文本数据挖掘技术的速记笔记符号识别语料库可根据其属性与功能可分为:词语速符(具有实质意义,以实体词为主,如名词、动词等)、会意速符①会意速符与词语速符所不同的是,它脱离源语形式,即不依附于词语的形式和读音,并传达偏于思维化、抽象化的信息概念。会意速符在速记者实际操作时是比较普遍的,且似乎颇具共性。(表抽象语意,以不具备实质意义的功能词为主)、关系速符(语法意义为主)、区别速符(显示信息间的群组关系);下设子系统应包括速记笔记符号识别设置(词语联想、笔势识别)、手写设置(笔迹颜色、笔迹粗细、笔迹类型)、颜色设置(色彩方案)、发音设置(音速、音质)、笔势浏览(退格、空格、删除、回车)等,确保速记人员可连续以行草连笔字、英文、数字、符号等方式输入或搜寻速记笔记符号,在无须切换界面的情况下“一笔到底”,输入内容还可直接对PPT、WORD、EXCEL等文件进行批注,勾画出示意图标注重点,遇到会读不会写的字词,可通过书写同音字词速符找到[5]。应该注意的是,在构建基于文本数据挖掘技术的速记笔记符号识别语料库中,其最基本的符号识别功能应包括:
1.在词库模式下,输入词语的首尾字母(或字母组合)后,计算机即可呈现出相关词语的列表,如图3所示:
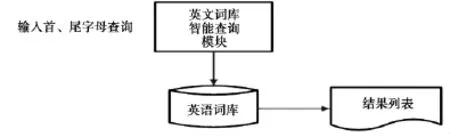
图3 速记首尾字母速写笔记符号识别结构
2.在词库模式下,计算机可按文章中选定词语的出现频率并排序,生成关键词词语的列表,如图4所示:
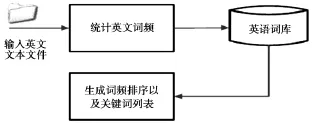
图4 关键词速记词语识别结构
速记的根本目的是记录源信息,速记的内容是对源信息内容和结构的采集记录,构建基于文本数据挖掘技术的速记笔记符号识别语料库的出发点是解决速记中笔记产出的受阻情况,如源语信息关键词输出密度过大、源语信息专业性、学术性、专有名词密集并列程度过高等,有助于提升速记笔记记录源信息的质量,尤其在提高信息完整性(Faithfulness)、笔记诠释性(Reformulation)和笔记可识率(Recognition)等方面取得显著成效。
参考文献:
[1]KH Coder.文本挖掘技术软件操作介绍[EB/OL].[2013-04-30].http://khc.sourceforge.net/.
[2]日本PHP研究所.松下幸之助发言集[M].京都:日本PHP研究所出版社,1991.
[3]经营哲学学会.经营哲学的实践[M].东京:文真堂出版社,2008.
[4]杨承淑.口译信息处理过程研究[M].天津:南开大学出版社,2010.
[5]刘幺和,宋庭新.语音识别与控制技术[M].北京:科学出版社,2008.
(责任编辑:明远)
中图分类号:H 026.1
文献标识码:A
文章编号:1007-5348(2015)07-0170-05
[收稿日期]2015-05-11
[基金项目]2015年北京市高职学生培养——高端技术技能人才培养模式改革子项目“旅游英语专业实践教学研究与实训资源建设”(PXM2015-014208-000023)
[作者简介]闵阅(1974-),女,北京人,高等教育出版社外语与国际汉语出版事业部副编审;研究方向:英语语言文学、国际出版。
The Enlightment of Text Data M ining to Stenography Teaching and Its Corpus Construction:Taking the Data Analysis of Konosuke M atsushita’s Speeches as an Exam p le
(1.Foreign Language Publications,Higher Education Press,Beijing,100029; 2.Department of English Language,Beijing Youth Politics College,Beijing 100102; 3.School of Economics and Management,Beijing University of Technology,Beijing 100124)
Abstact:‘Text Data Mining’(TDM)is a kind of technology for analyzing a large amount of text data by dozens ofmeasures,with which people could find out patterns and laws,as well as gain useful knowledge and information.Also,we are discussing how to cultivate such ability in the design of shorthand teaching so that professional stenographers could utilize TDM to discover the underlying and valuable knowledge in order tomake a better and more effective preparation before taking shorthand.And we think that notation recognition corpus based on TDM for shorthand purpose could be helpful for notation-output and improve quality of shorthand.
Key W ords:text data Mining;shorthand training;corpus;design
