基于FP-tree算法的船舶滞留原因关联性分析
2015-07-18顾洵瑜胡甚平吴建军陈兴伟
顾洵瑜, 胡甚平, 吴建军, 陈兴伟,2
(1. 上海海事大学 商船学院,上海 201306; 2. 浙江交通职业技术学院 海运学院,杭州 311112)
基于FP-tree算法的船舶滞留原因关联性分析
顾洵瑜1, 胡甚平1, 吴建军1, 陈兴伟1,2
(1. 上海海事大学 商船学院,上海 201306; 2. 浙江交通职业技术学院 海运学院,杭州 311112)
为提高船舶安全检查的效率,提出对港口国监督(Port State Control,PSC)中船舶安全检查要素之间关联性的研究.引入关联规则进行相关性分析,从给定的数据中寻找频繁的项目知识模式,通过置信度和重要性阈值的约束,挖掘出船舶滞留原因间的潜在规律.算例结果表明,通过关联规则对船舶滞留原因的分析,可以直观地发现滞留原因间的关联,利于港口主管机关在实际工作中采取更具针对性的方法进行检查.
港口国监督(PSC); 数据挖掘; 关联规则; 滞留; 缺陷
0 引 言
港口国监督(Port State Control,PSC)被人们誉为海上安全的最后一道防线[1],是由国际海事组织(International Maritime Organization, IMO)建立,由港口国政府的海事主管机关针对抵港外籍船舶实施的专门性检查.PSC检查以限制低标准船舶为手段,目的是将低标准船舶从市场中清除,保证船舶航行安全,防止船舶污染海洋环境.借助现存的10个港口国区域备忘录体系,PSC已经可以覆盖全球绝大部分重要港口.[2]
近年来,随着相关国际公约以及修正案的生效,全球范围内PSC检查的依据已发生巨大改变,不断修订的公约对船舶以及PSC检查提出更高的要求.与此同时,随着航运竞争的日益激烈,航运业对船舶营运效率的要求日益提高,同时也要求PSC检查具有更高的效率,高效的航运已经成为IMO追求的新内容.[3]
对于PSC检查而言,信息界的决策支持和数据挖掘理念仍属于新鲜课题,业界一直在探索.杨丹等[4]介绍美国采用的“选择登轮打分表”和巴黎备忘录国家采用的“综合目标因素法”,提出新的综合评估等级法.尤庆华等[5]介绍船舶安全检查的质量船体系和模型设计的基本思路、理论基础、体系结构和实施步骤.戴耀存等[6]运用关联规则挖掘技术对PSC检查滞留数据进行研究,通过频繁项集和关联规则挖掘船舶滞留缺陷的潜在规律.孙墨林等[7]提出基于正反馈修正-支持向量机的PSC选船模型,得到合理的结果.孙忠华[8]提出基于粗糙集和层次分析法的PSC选船系统目标因素算法,并进一步提出基于改进粒子群-BP神经网络算法的PSC选船模型.陈晶等[9]设计编制船舶滞留规律挖掘与表达算法,通过缺陷代码组合的复杂化呈现船舶的各种滞留规律.
随着PSC数据的扩展,采用现代决策支持技术及数据挖掘的方法,可以对PSC检查的记录进行更科学、高效的信息拣选与处理,从而提取船舶缺陷的内在规律.[7]本文利用船舶安全检查的历史数据,采用数据挖掘技术,通过对船舶滞留原因间的关系进行关联强度分析,确定原因间的关联性,引导PSC检查官从已发现的某一缺陷确定下一步重点检查因素,“顺藤摸瓜”,从而提高安全检查效率,推进PSC检查技术的发展.
1 PSC检查要素体系
结合国内航行海船实际情况和我国海事管理机关的检查实践,船舶安全检查体系包含14个要素,见图1.
2 PSC检查方法的发展
自20世纪80年代以来,备忘录的实施推进了安全检查全球化的发展,也使得安全检查的标准化、规范化成为业内人员讨论的问题之一.[10]依据PSC检查数据的积累以及大量的数据分析技术的引入,PSC检查总体上经历了3个阶段.

图1 船舶安全检查体系
第一阶段:要素检查.要素检查是在对整个系统的构成要素进行逐一检查时,主要检查构成要素的符合性,也就是检查是否具有安全系统的组成要素.若组成要素有缺失,则认为不符合安全标准的要求.东京备忘录的检查要素与第1节中提到的14个要素有相同的部分,也有一些差异.比如,东京备忘录中提出19个要素,包括警报信号、货物、事故预防、船舶保安及其他等.要素检查是一种符合性检查.
第二阶段:缺陷检查.缺陷检查是在对整个系统的构成要素进行逐一检查时,主要检查构成要素的有效性,也就是检查安全系统的组成要素是否有缺陷.若缺陷形成链式反应,则认为整个系统具有缺陷,不能达成系统安全的标准要求.对于船舶安全检查而言,整个船舶安全系统要素中某些缺陷之间形成链式,则认为系统失效.现阶段PSC检查仍处于这个阶段.
第三阶段:关联性检查.关联性检查是在对整个系统的构成要素进行抽查时,主要检查构成要素之间的关联性,也就是检查这些缺陷之间是否相互影响,若相互影响,且在系统中具有很重要的地位,对系统安全的影响很大,则认为系统失效的迹象明显.该阶段主要是基于第二阶段检查结果数据的积累实现基于大数据的数据挖掘,动态地、实时地反映检查的重点,提高检查的绩效和针对性.
从第二阶段发展到第三阶段,需要有数据的支持,也需要数据挖掘技术平台.
3 基于关联规则的数据挖掘
数据挖掘可以用于发现决策所需要的知识模式.而关联分析就是从给定的数据中发现频繁出现的项目知识模式,又称关联规则.关联规则广泛应用于事务分析领域.在大量用户的数据中,存在很多关联规则,但并非所有的关联规则对用户都是有用的.在实际应用中,一般采取支持度(Support)和置信度(Confidence)筛选有用的规则.
为分析PSC检查中船舶滞留原因间的关联性,运用数据挖掘中的关联规则进行对应的分析,找出各滞留原因间的关系,便于有关部门在实际工作中更有针对性地检查船舶.
3.1 关联规则
设I是数据项的集合,D为与其相关的数据集合,在D中每个事务T(Transaction)都是I的非空子集,即T⊂I,每个事务都有对应的识别号,称为TID(Transaction ID).
若A和B为项目集,且A∩B=∅,则定义关联规则A⟹B的支持度(Support)为D中事务同时包含A和B的概率P(A∪B),其置信度(Confidence)为当D中事务已包含A的同时包含B的百分比,即条件概率P(B|A).

(1)

(2)
支持度大于最小支持度的项集称为频繁项集.当关联规则同时满足大于最小支持度阈值(min_sup)和最小置信度阈值(min_conf)的要求时,该关联规则称为强关联规则,反之称为弱关联规则.以上阈值需要根据数据挖掘自行设定.为便于计算,支持度和置信度的值一般用0~100%之间的值而不是0~1.0之间的值表示.[11]
3.2 关联规则挖掘
Apriori算法是关联规则数据挖掘中的经典算法.该算法通过挖掘数据产生布尔关联规则所需要的频繁项集,而关联规则挖掘算法的核心就是寻找出频繁项集.
Apriori算法的基本性质是:一个频繁项集的任一子集都是频繁的.该算法采用逐层搜索的迭代方法对频繁项集进行挖掘,利用k-项集的挖掘结果产生(k+1)-项集.
该算法首先统计所有只含1个元素的项集出现的频率,由此决定一维频繁项集L1;然后开始循环处理,由L1挖掘L2,由L2挖掘L3,直至再也没有频繁项集产生.该算法的循环过程:逐层搜索数据库以计算候选项集的支持度,将其与最小支持度进行比较,找到k维的最大项集.为使候选项集中项目支持度的计算更加快捷,可以利用subset函数进行计算.该方法要求预先自行设定阈值来控制支持度,并且需要遍历数据库多次,因此该算法的复杂度是呈指数级增加的.因此,如果有n个项目,那么就有2n个可能的频繁项集,这构成项集I上的可能解空间.[12]
针对以上Apriori算法的固有缺陷,HAN等[13]提出频繁模式树(Frequent Pattern tree, FP-tree)算法.该算法可以在不产生候选项集的情况下挖掘频繁项集.采用分治的方法,在完成对数据库的第一次扫描后,把提供频繁项集的数据库压缩进一个FP-tree中,但同时保留其中的项集关联信息,随后再将FP-tree分化成一些条件数据库,对这些条件数据库进行挖掘.因此,当原始数据量很大时,可以结合划分数据库的方法,使一个FP-tree可以放入主存中.由此可知,FP-growth不仅能处理不同长度的规则,并且在效率上远高于Apriori算法.
3.3 重要性阈值
已有的关联规则挖掘算法大部分都使用支持度-置信度阈值的框架.虽然这样的阈值框架能够排除大量无趣的规则,但仍会有一些存在,为此使用相关性度量来扩充这一框架.为保证关联规则挖掘结果的准确性,引入重要性阈值以进一步屏蔽无趣的规则.定义重要性(Importance)为

(3)
重要性的取值范围为(-∞,+∞).当重要性为0时,表明A和B是相互独立的项,它们之间没有关联;当重要性大于0时,表明当A发生时,B发生的概率会上升;当重要性小于0时,表明当A发生时,B发生的概率会下降.[13]
4 算例分析
采用2011年1月至2014年6月某辖区PSC检查数据.共滞留船舶321艘次,获得缺陷要素数据4 643个.限于篇幅,表1仅列出2011年该辖区外籍船舶滞留情况的部分数据.
4.1 船舶滞留原因分布

表1 2011年某辖区外籍船舶滞留情况部分数据
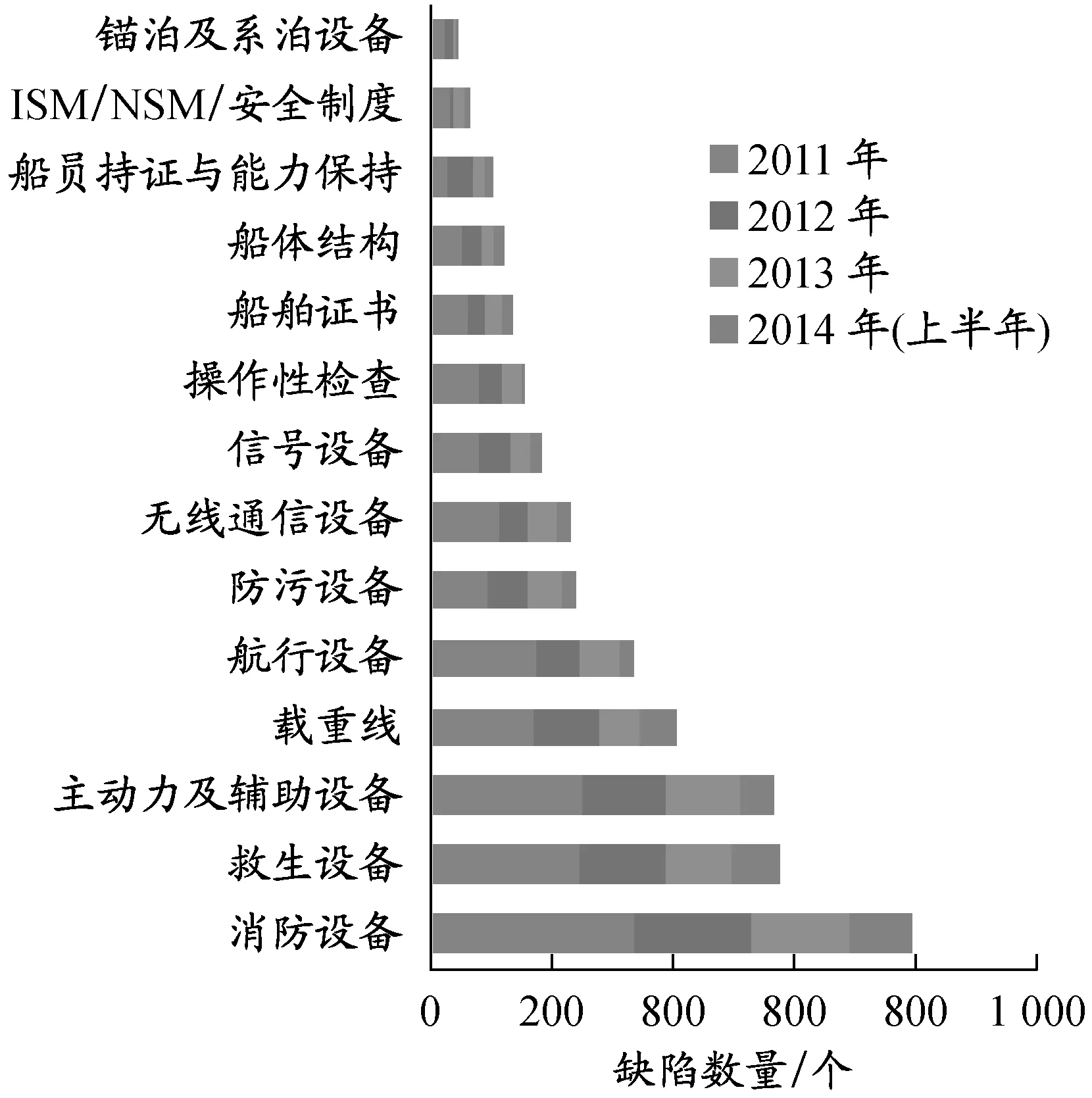
图2 2011年1月至2014年6月某辖区PSC检查中船舶滞留原因分布
为使有关主管机关更有针对性地进行PSC检查,首先将2011年1月至2014年6月某辖区PSC检查中船舶滞留原因以条形图(见图2)展示,这样可以更加直观地表现出在此期间哪些滞留原因出现的频数最多,有关部门可以从这些方面开始检查.
从图2可以清晰地发现2011年1月至2014年6月该辖区PSC检查中船舶滞留原因出现频数最大的3项为消防设备、救生设备、主动力及辅助设备.相关港口主管当局在实施船舶PSC检查时,可以从出现频数较大的滞留原因着手进行初次检查.
4.2 滞留原因间的关联性分析结果
采用SAS软件中关联规则的功能,运用FP-tree算法进行数据分析,采用置信度-重要性阈值的框架约束无趣规则的产生,结果见表2(置信度≥60%,重要性≥0).表2展示出不同滞留原因间的规则.
数据表明因素之间的关联有明显差异:(1)有些滞留因素与其他因素的关联度较强.比如,在船舶证书为滞留原因的案例中,91.36%的案例中也包含航行设备这项滞留原因.在锚泊及系泊设备为滞留原因的案例中,97.30%的案例中也包含救生设备这项滞留原因.(2)因素之间的关联形成网络拓扑关系.比如,在救生设备为滞留原因的案例中,首先表现为与航行设备、消防设备、锚泊及系泊设备、主动力及辅助设备的强关联关系,而锚泊及系泊设备、主动力及辅助设备均与载重线有强关联性,该数据也能反映救生设备与载重线有较强关联性.由此,因素之间形成可拓的网络结构,替代以往的层次结构.(3)在安全检查实施过程中,可以按照关联程度进行检查,从而提高检查的针对性.也就是说,当PSC检查发现船舶某项因素未达标时,应当对与其相关较大的因素进行检查,以排除各类隐患,减小船舶发生事故的概率.
根据图2和表2,将各项滞留原因按照发生的频数和置信度进行排列.将发生频数小的项排列在靠边缘的位置,将发生频数大的项排列在相互靠近中心的位置;将置信度大,即相关性大的项排列在靠近的位置,将置信度小,即相关性小的项排列在相隔较远的位置.结果见图3.
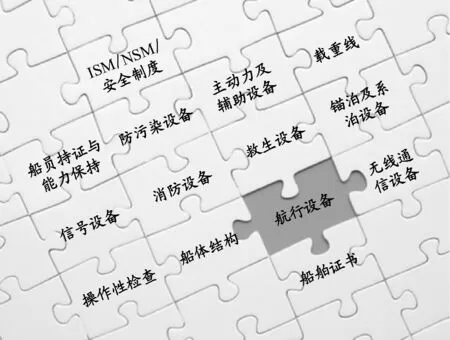
图3 滞留原因间的关联性
因此,基于数据挖掘的因素关联分析可以将滞留因素之间的关联情况进行完整分析,得出因素之间的关联关系,从而为PSC进行关联性检查提供服务.PSC检查官在检查中可以根据图3优先检查位于中心位置的项目.若该项存在缺陷,可以再检验与其相关较大的项,即与该项相邻的其他项.然后,根据各项之间的相关性确定需要检查的项,增大检查出船舶缺陷的概率,增大船舶滞留比例,减小低标准船舶在海上航行时发生事故的概率.
5 结束语
随着PSC检查历史数据的积累,以往要素性检查可以发展为关联性检查,提高安全检查的效率,提升针对性.这需要数据支持,也需要数据挖掘技术平台.本文从船舶滞留缺陷的大数据中寻找规律,运用关联规则等数据挖掘方法发现滞留缺陷间的相关性.对某辖区2011年1月至2014年6月的PSC检查数据的分析表明,该辖区目前核心因素是航行设备、救生设备、船体结构、无线电通信设备等硬件设施设备部分,操作性检查还在外围要素部分.这将为船舶管理人员和PSC检查官在实际工作中提供指导性方法,对降低船舶尤其是无限航区的远洋船舶海上事故的发生率起到积极的作用.
[1]曾向明,张善杰,陈宝忠,等. 世界主要区域港口国检查组织实施情况[J]. 中国航海, 2007(4): 13-16,28.
[2]傅俊杰,刘昌禄. 基于数据统计的港口国监督效能评估[J]. 世界海运, 2011, 34(7): 50-52.
[3]傅俊杰,周驰. 港口国监督检查在外籍船舶综合管理中的应用[J]. 中国航海, 2013(3): 106-111.
[4]杨丹,吴兆麟. 运用综合评估等级法确定PSC检查的重点[J]. 大连海事大学学报, 1998, 24(3): 35-37.
[5]尤庆华,高德毅,耿鹤军. 船舶安全检查的质量船体系和模型设计[J]. 中国航海, 2004(1): 8-13, 24.
[6]戴耀存,陈兴伟,陈雪峰. 船舶港口国监督的滞留原因分析[J]. 中国航海, 2010(3): 64-68.
[7]孙墨林,郑中义.基于正反馈修正-支持向量机的PSC选船模型[J].大连海事大学学报, 2014, 40(2): 31-33, 38.
[8]孙忠华. 基于智能优化算法的港口国监督选船模型研究[D]. 大连: 大连海事大学,2013.
[9]陈晶,金永兴,陈锦标,等. 基于辨识度关联的船舶滞留规律挖掘与表达[J]. 交通运输系统工程与信息,2014,14(1):102-108.
[10]马雪梅,罗卫华. 论船级社检验、船旗国监督与港口国监督三者关系[J]. 航海技术, 2007(1): 74-75.
[11]赵晨. 关联规则挖掘算法的研究及应用[D]. 西安: 西安电子科技大学, 2011.
[12]HAN J, KAMBER M. Data mining: concepts and techniques[M].Beijing: China Machine Press, 2012: 160-166.
[13]刘刚. 数据挖掘技术与分类算法研究[D]. 郑州: 中国人民解放军信息工程大学, 2004.
(编辑 赵勉)
Correlation analysis of ship detention reasons based on FP-tree algorithm
GU Xunyu1, HU Shenping1, WU Jianjun1, CHEN Xingwei1,2
(1. Merchant Marine College, Shanghai Maritime Univ., Shanghai 201306, China; 2. Sea Transportation Faculty, Zhejiang Institute of Communication, Hangzhou 311112, China)
To improve the efficiency of ship safety inspection, the correlations among ship safety inspection elements of Port State Control are studied. By introducing association rules to analyze the correlations, the frequent project knowledge models are found out from the given data. Then through the constraints of confidence and importance threshold values, the potential laws in ship detention reasons are mined. The result from a case shows that the correlations among ship detention reasons can be directly found out through the association rule analysis, which helps port authorities to take more effective measures in the practical work.
Port State Control (PSC); data mining; association rule; detention; deficiency
10.13340/j.jsmu.2015.02.011
1672-9498(2015)02-0060-05
2014-11-22
2015-03-17
浙江海事局项目(201425)
顾洵瑜(1992—),女,江苏南通人,硕士研究生,研究方向船舶安全与管理,(E-mail)jsntqdgxy@163.com; 胡甚平(1974—),男,湖北通城人,教授,博士,研究方向为载运工具运用工程、安全工程、水上交通风险管理, (E-mail)sphu@shmtu.edu.cn
U691.6
A
