基于笛卡尔乘积字典的稀疏编码跟踪算法
2015-07-05黄宏图毕笃彦查宇飞
黄宏图毕笃彦 查宇飞 高 山 覃 兵
(空军工程大学航空航天工程学院 西安 710038)
基于笛卡尔乘积字典的稀疏编码跟踪算法
黄宏图*毕笃彦 查宇飞 高 山 覃 兵
(空军工程大学航空航天工程学院 西安 710038)
为了提高基于稀疏编码的视频目标跟踪算法的鲁棒性,该文将原始稀疏编码问题分解为两个子稀疏编码问题,在大大增加字典原子个数的同时,降低了稀疏性求解过程的计算量。并且为了减少1范数最小化的计算次数,利用基于岭回归的重构误差先对候选目标进行粗估计,而后选取重构误差较小的若干个粒子求解其在两个子字典下的稀疏表示,最后将目标的高维稀疏表示代入事先训练好的分类器,选取分类器响应最大的候选位置作为目标的跟踪位置。实验结果表明由于笛卡尔乘积字典的应用使得算法的鲁棒性得到一定程度的提高。
计算机视觉;视频跟踪;笛卡尔乘积;稀疏编码;支持向量回归机;岭回归
1 引言
视频目标跟踪技术是计算机视觉领域的关键问题之一[1],广泛应用于视频监控、机器人导航、人机交互和精确制导等领域。跟踪面临的挑战从内外两个方面来说包括目标内部变化和外界变化,其中目标内部变化包括目标姿态变化、形变和尺度变化等,外界变化包括噪声、光照变化和遮挡等。为了处理上述变化,一个好的目标模型需要满足以下两个条件:对于目标自身变化的自适应性和对于外界变化的鲁棒性[2]。
稀疏编码广泛应用于人脸识别、图像超分辨率重建、图像去噪和恢复、背景建模、图像分类等计算机视觉领域[3]。得益于稀疏表示在人脸识别[4]领域的成功应用,很多学者将其应用到视频目标跟踪[5],可以分为基于稀疏编码重构误差的生成式模型和基于稀疏编码的判别式模型。无论是生成式模型还是判别式模型都需要首先求解目标在字典下的稀疏表示,其中稀疏性求解过程为1范数最小化问题,此类算法有同伦法、正交匹配追踪法、梯度投影法、迭代收缩阈值法、基追踪法和内点法等[6]。而这些算法的时间复杂度一般较高,尤其是当字典的维数较高时,严重制约了跟踪算法的实时性。而理论研究和实验结果表明字典中原子个数增加后目标能够获得更高维的稀疏表示,而在高维的稀疏表示下目标和背景更加线性可分[7]。这样就形成了一组矛盾,为了获得跟踪的实时性需要降低字典的维数,而为了提高鲁棒性又不得不提高字典的维数。
程的算法时间复杂度为O(Nm2n3/2),其中N是候选目标个数,m为特征维数,n为字典中原子个数[5]。因此降低稀疏性求解过程的计算量可以分为以下两种方法:(1)降低每次1范数最小化的计算量。(2)减少1范数最小化的次数。虽然上述方法一定程度上降低了稀疏性求解过程的计算量,但是实质并没有增加字典中原子个数,因而在提高跟踪的鲁棒性方面效果有限。如何在计算量一定的前提下,增加字典中的原子个数来提高跟踪算法的鲁棒性是稀疏编码跟踪算法需要解决的关键问题。
本文提出了基于笛卡尔乘积字典[8]的稀疏编码跟踪算法,将原始字典分解为两个子字典,而后按照同样的方式分别求解目标在两个子字典上的稀疏表示,以较低的计算代价获得了目标高维的稀疏表示。为了进一步提高跟踪算法的实时性,利用基于岭回归的重构误差排除大量的无关粒子,而后求解重构误差较小的若干个候选目标在两个子字典上的稀疏表示,最后将目标的高维稀疏表示代入事先训练好的支持向量回归机,根据分类器响应确定目标的跟踪位置,在此基础上利用跟踪结果和正负样本对分类器进行在线更新。实验结果表明由于乘积稀疏编码的应用,算法的鲁棒性得到了一定程度的提高。
2 过完备字典构建
如图1所示,首先通过仿射变换将目标转换至32×32大小区域,对于每个候选目标iY这里使用固定大小(16×16)的滑动窗,利用尺度不变特征变换(Scale-Invariant Feature Transform, SIFT)提取交叠的k个图像块的[9]特征{y1,y2,…,yk},其中k=9。与原始SIFT特征不同,本文指定图像块的中心为关键点,而后对关键点周围的区域提取梯度幅值直方图,并且为了降低特征提取过程的计算量,仅提取一个尺度下的SIFT特征,目标的尺度变化可以通过仿射变换中的尺度参数对其进行描述。
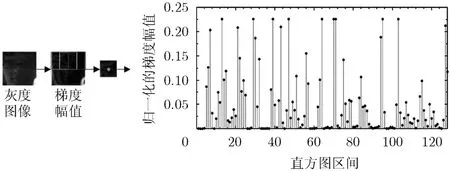
图1 图像块的SIFT特征提取
3 笛卡尔乘积稀疏编码
对于两个子字典的笛卡尔乘积稀疏编码[8]问题,可以将图像块的SIFT特征表示为x=[,]T,x1∈和x2∈分别是x的两个子向量。按照同样的方式字典D∈ℝm×n中的原子可以表示为[,]T,其中d1p是D1∈中的第p个原子,d2q是D2∈中的第q个原子,p,q=1,2,…,n。选取目标和其中心8邻域目标的SIFT特征构建字典D,即m=128, n=81。x在该字典下的笛卡尔乘积稀疏表示βpq可以通过下面的目标函数获得。
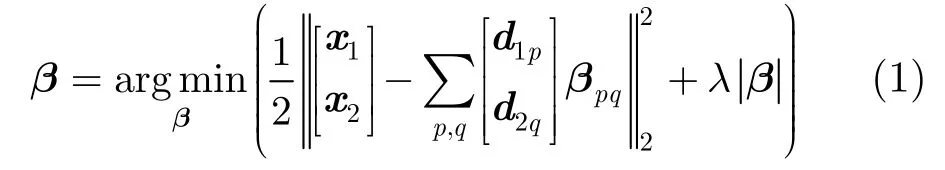
式(1)的稀疏编码问题的等价形式为
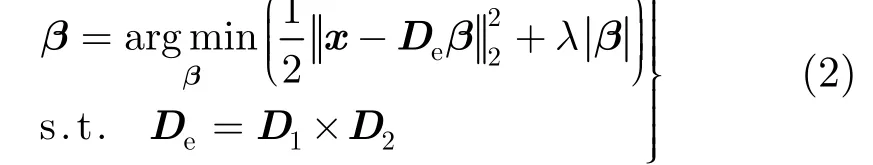
其中De为字典D1和D2的笛卡尔乘积。
式(2)的稀疏编码问题可以分解为下面两个子稀疏编码问题[8]:
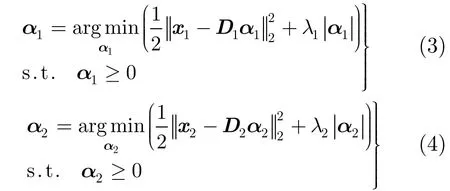
其中λ1=λ2=λ/2=0.15。
则有x在D1和D2的笛卡尔乘积字典下的稀疏表示为
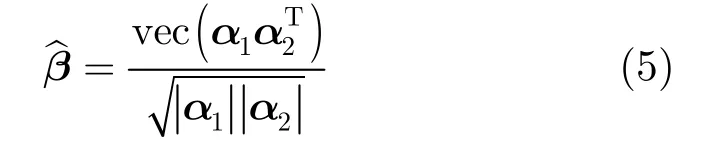
其中vec(·)表示将矩阵按列转换成列向量,ˆβ为式(2)的近似解。
原始稀疏编码问题为
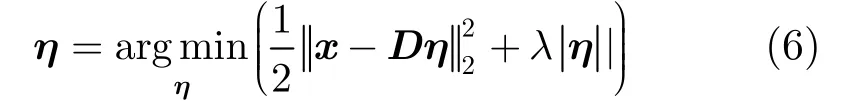
基于式(2)和式(3)~式(5)的稀疏性求解过程的算法时间复杂度比较如表1所示。从表1中可以看出当m=128, n =81时,基于笛卡尔乘积字典的稀疏表示的计算量远远小于直接在等效字典上求解稀疏表示的计算量。因此基于笛卡尔乘积的稀疏表示在增加原子个数的同时,降低了求解的计算量。

表1 算法时间复杂度比较
则有候选目标iY的所有k个图像块的SIFT特征在笛卡尔乘积字典下的稀疏表示为
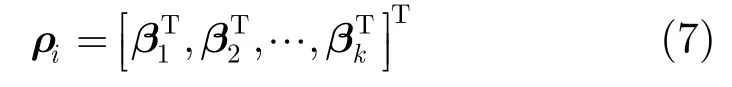
4 支持向量回归机
在当前帧跟踪位置基础上,在目标周围按照高斯分布提取一定数量的正负样本,其中正样本中心坐标lpos满足负样本中心坐标lneg满足, l为当前帧的跟踪位置,σt1和σ2为样本中心与目标中心之间的欧式距离(像素)。分别计算正负样本在当前笛卡尔乘积字典下的稀疏表示ρj。将代入线性分类器进行训练,其中lj=±1表示样本标签,c=100,即50个正样本和50个负样本。线性分类器的目标函数[10,11]为
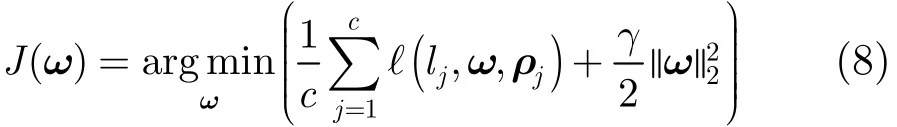
其中ω是分类器参数,γ=0.01为正则化参数。损失函数l(lj,ω,ρj)为
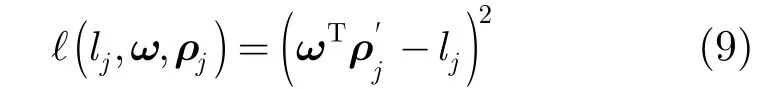

5 基于岭回归的粗估计
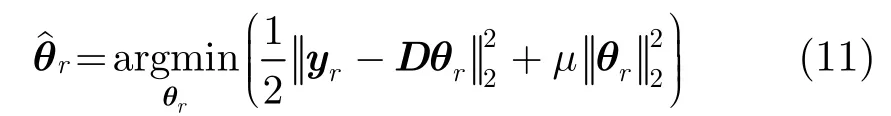
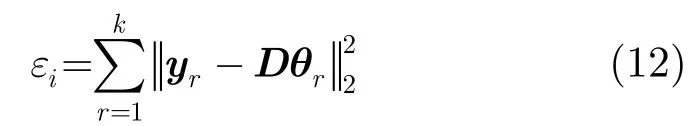
对于N个候选目标选择重构误差较小的0N个粒子,因此大大减少了1范数最小化的次数。
6 跟踪算法
算法是在粒子滤波框架[13]下完成。粒子滤波通过观测数据I1:t来递推计算状态St取不同值时的置信度p(St|I1:t),由此获得状态的最优估计。给定目标的观察变量集合I1:t={I1,I2,…,It},目标的状态变量St可以通过最大后验估计得到
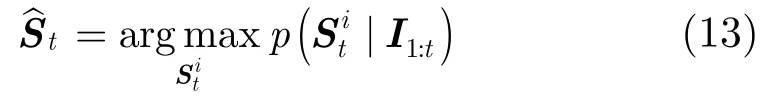
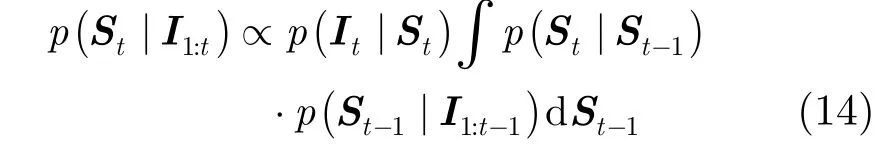
其中p(St|St-1)表示动态模型,p(It|St)表示观察模型。动态模型描述相邻两帧之间目标状态的时间相关性,这里使用6参数的仿射变换[14]来模拟相邻两帧之间目标的运动,St=(xt,yt,θt,st,αt,φt)分别表示t时刻目标x方向和y方向位移,旋转角度,尺度,宽高比,倾斜角度。状态转换公式为p(St|St-1)= N(St;St-1,Σ), Σ是仿射变换参数的标准差组成的协方差矩阵,这里假定仿射变换参数相互独立且不随时间变化[14]。
观察模型p(It|St)表示观察变量It位于状态St的可能性,算法构建的观察模型为
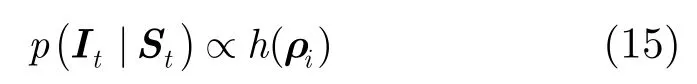
其中h(ρi)表示候选目标的分类器响应。
因此,本文跟踪算法框架如图2所示。
7 实验结果及分析
7.1 跟踪结果及分析
测试视频来自文献[1],视频数据及目标特征描述如表2所示,实验在Dual-Core 3.20 GHz,内存3 GB的台式计算机上通过Matlab(R2013a)软件实现。其中粒子个数=600N,经过粗估计后剩余粒子个数为N0=200。FaceOcc2仿射变换参数的标准差为[4,4,0.02,0.03,0.001,0], Cliffbar仿射变换参数的标准差为[5,5,0.05,0.20,0.005,0.001], Jumping仿射变换参数的标准差为[8,18,0,0,0,0], Trellis仿射变换参数的标准差为[4,4,0.01,0.01,0.002,0.001]。
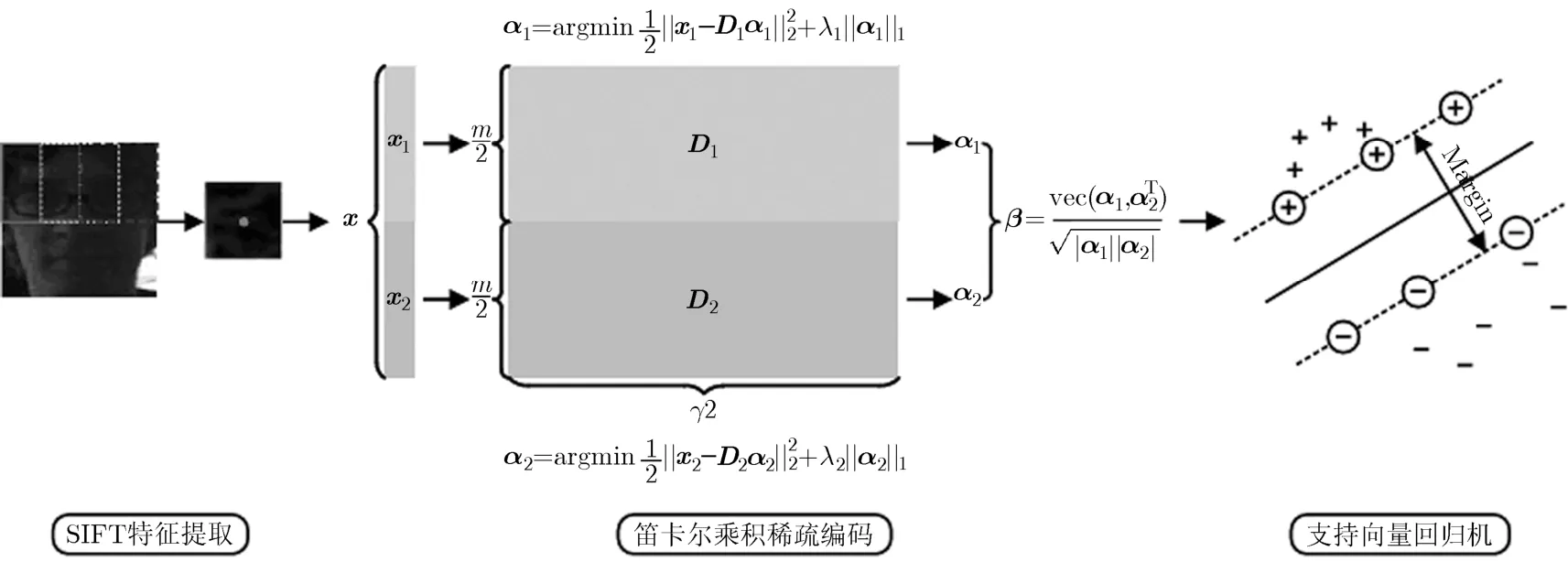
图2 算法跟踪过程

表2 视频数据及目标特征描述
实验的部分跟踪结果如图3所示,其中白色实线为本文算法跟踪结果,其它算法跟踪结果如图例所示。比较算法分别为:增量子空间学习算法(Incremental Visual Tracking, IVT)[14],多事例学习算法(Multiple Instance Learning, MIL)[15],基于加速最近梯度的快速1跟踪算法(L1 Tracker Using Accelerated Proximal Gradient Approach, L1APG)[16],快速压缩感知跟踪算法(Fast Compressive Tracking, FCT)[17]。稀疏编码跟踪算法(Sparse Coding Tracking, SCT)为基于字典D的跟踪算法,基于笛卡尔乘积的稀疏编码跟踪算法(Product Sparse Coding Tracking, PSCT)为本文提出算法,其中SCT算法和PSCT算法除字典不同外其它参数均相同。
遮挡:由于算法提取的是局部图像块的SIFT特征,并且稀疏性求解过程即是对图像块SIFT特征的选择过程,能够抓住目标中较为稳定的图像块的SIFT特征,因而能够较好地处理跟踪中的遮挡问题。
共面旋转和尺度变化:算法每次生成不同尺度和旋转角度的候选框,并且SIFT特征本身对于共面旋转具有不变性,因此能够解决跟踪中的共面旋转和尺度变化问题。
运动模糊和快速运动:由于算法字典中原子个数大大增加,使得目标能够获得高维的稀疏表示,同时支持向量回归机具有较好的推广能力,使得在稀疏的高维特征下目标和背景更加线性可分。
非均匀光照变化:SIFT特征由于对梯度幅值直方图进行了归一化因而能够对于光照变化具有一定的鲁棒性,同时PSCT算法字典中原子的个数远大于SCT算法字典中原子的个数,使得高维稀疏表示下分类器区分目标和背景的能力更强。
7.2 跟踪精度
7.2.1 重叠率 RT是算法标定的跟踪区域,RG是人工标定的真实目标区域,area(RT∩RG)是二者重叠面积,area(RT∪RG)是二者面积之和。定义重叠率[18]为
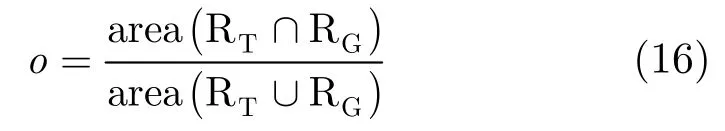
不同算法下4个视频重叠率随帧数变化曲线如图4所示。
7.2.2 中心误差 中心误差定义为算法跟踪框的中心位置与人工标定的真实的中心位置之间的欧氏距离(像素)[18],中心误差的统计特征如表3所示,其中每个视频对应的第1行为中心误差的均值,第2行为中心误差的标准差。从表3中可以看出本文提出的算法整体上优于其它4种算法,并且PSCT算法优于SCT算法。
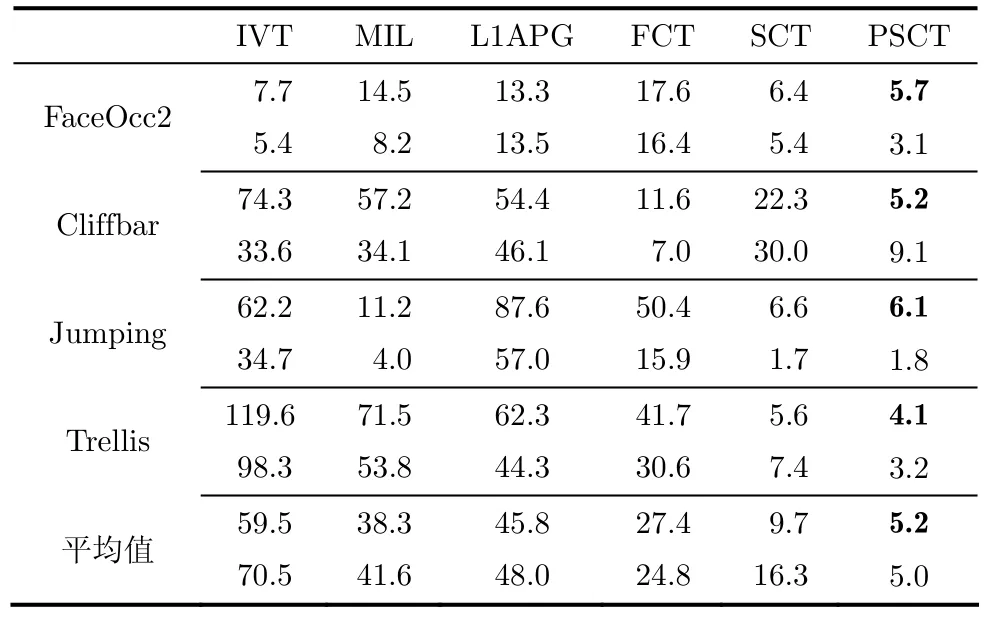
表3 不同算法下各视频中心误差的均值和标准差(像素)

图3 部分实验跟踪结果

图4 各视频重叠率随帧数的变化曲线
7.3 跟踪鲁棒性
如果在一帧中重叠率0.5o≥,则认为跟踪成功,反之则认为跟踪失败[18]。不同算法下视频的跟踪成功率如表4所示,其中最后一行为算法在4个视频上的跟踪成功率的平均值。从表4中可以看出本文提出算法的跟踪成功率整体上高于其它5种算法。
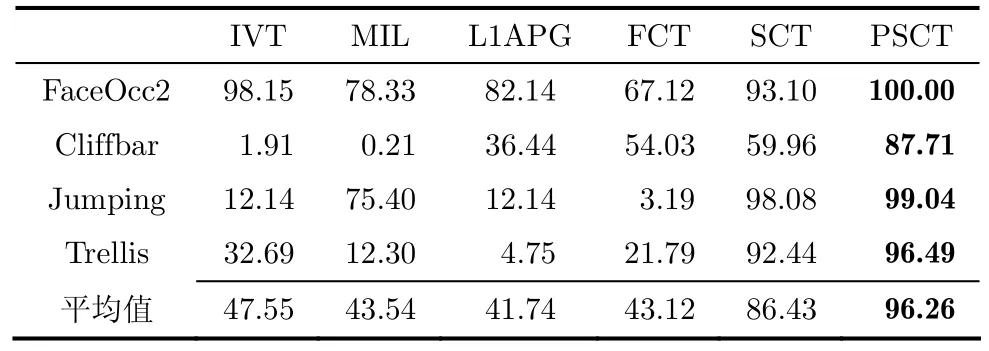
表4 不同算法下各视频跟踪成功率(%)
8 结束语
利用笛卡尔乘积将稀疏编码问题分解为两个子字典下的稀疏编码问题,在大大增加字典原子个数的同时降低了稀疏性求解过程的计算量。为了减少l1范数最小化的次数,利用基于岭回归的重构误差排除大量无关粒子,从而选取重构误差较小的若干个粒子求解其在两个子字典的笛卡尔乘积上的稀疏表示。实验结果表明由于字典中原子个数大大增加,使得目标能够获得更加高维的稀疏表示,进而使得目标和背景更加线性可分,提高了算法的鲁棒性。
[1] Wu Yi, Lim J, and Yang Ming-hsuan. Online object tracking: a benchmark[C]. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Portland, USA, 2013: 2411-2418.
[2] Arnold W M S, Dung M C, Rita C, et al.. Visual tracking: an experimental survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(7): 1442-1468.
[3] 彭义刚, 索津莉, 戴琼海, 等. 从压缩传感到低秩矩阵恢复:理论与应用[J]. 自动化学报, 2013, 39(7): 981-994.
Peng Yi-gang, Suo Jin-li, Dai Qiong-hai, et al.. From compressed sensing to low-rank matrix recovery: theory and applications[J]. Acta Automatica Sinica, 2013, 39(7): 981-994.
[4] Wright, Yang A, Ganesh A, et al.. Robust face recognition via sparse representation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(2): 210-227.
[5] Zhang Sheng-ping, Yao Hong-xun, Sun Xin, et al.. Sparse coding based visual tracking: review and experimental comparison[J]. Pattern Recognition, 2013, 46(7): 1772-1788.
[6] 李佳, 王强, 沈毅, 等. 测量矩阵与重建算法的协同构造[J].电子学报, 2013, 41(1): 29-34.
Li Jia, Wang Qiang, Shen Yi, et al.. Collaborative construction of measurement matrix and reconstruction algorithm in compressive sensing[J]. Acta Electronica Sinica, 2013, 41(1): 29-34.
[7] Chatfield K, Lempitsky V, Vedaldi A, et al.. The devil is in the details: an evaluation of recent feature encoding methods[C]. Proceedings of British Machine Vision Conference (BMVC), Dundee, England, 2011: 1-12.
[8] Ge Tie-zheng, He Kai-ming, and Sun Jian. Product sparse coding[C]. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 1211-1218.
[9] David G L. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91-110.
[10] Alex J S and Bernhard S. A tutorial on support vector regression[J]. Statistics and Computing, 2004, 14(3): 199-222.
[11] Chang Chih-chung and Lin Chih-jen. LIBSVM: a library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology, 2011, 2(3): 1-27.
[12] 向馗, 李炳南. 主元分析中的稀疏性[J]. 电子学报, 2012, 40(12): 2525-2532.
Xiang Kui and Li Bing-nan. Sparsity in principal component analysis: a survey[J]. Acta Electronica Sinica, 2012, 40(12): 2525-2532.
[13] Michel I and Andrew B. Condensation-conditional density propagation for visual tracking[J]. International Journal of Computer Vision, 1998, 29(1): 5-28.
[14] David A R, Jongwoo L, Lin R S, et al.. Incremental learning for robust visual tracking[J]. International Journal of Computer Vision, 2008, 77(1/3): 125-141.
[15] Babenko B, Yang Ming-hsuan, and Belongie S. Visual tracking with online multiple instance learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(8): 1619-1632.
[16] Bao Cheng-long, Wu Yi, Ling Hai-bin, et al.. Real time robust L1tracker using accelerated proximal gradient approach[C]. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 2012: 1830-1837.
[17] Zhang Kai-hua, Zhang Lei, and Yang M H. Fast compressive tracking[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(10): 2002-2015.
[18] Mark E, Luc V G, Christopher K I, et al.. The PASCAL visual object classes (VOC) challenge[J]. Interational Journal of Computer Vision, 2010, 88(2): 303-338.
黄宏图: 男,1986年生,博士生,研究方向为视频目标跟踪.
毕笃彦: 男,1962年生,博士,教授,博士生导师,研究方向为图像处理和模式识别.
查宇飞: 男,1979年生,博士,副教授,研究方向为计算机视觉和机器学习.
高 山: 女,1983年生,博士,讲师,研究方向为图像处理.
覃 兵: 男,1991年生,硕士生,研究方向为视频目标跟踪.
Sparse Coding Visual Tracking Based on the Cartesian Product of Codebook
Huang Hong-tu Bi Du-yan Zha Yu-fei Gao Shan Qin Bing
(Aeronautics and Astronautics Engineering College, Air Force Engineering University, Xi’an 710038, China)
In order to improve the robustness of the visual tracking algorithm based on sparse coding, the original sparse coding problem is decomposed into two sub sparse coding problems. And the size of the codebook is intensively increased while the computational cost is decreased. Furthermore, in order to decrease the number of the1-norm minimization, ridge regression is employed to exclude the intensive outlying particles via the reconstruction error. And the sparse representation of the particles with small reconstruction error is computed on the two subcodebooks. The high-dimension sparse representation is put into the classifier and the candidate with the biggest response is recognized as the target. The experiment results demonstrate that the robustness of the proposed algorithm is improved due to the employed Cartesian product of subcodebooks.
Computer vision; Visual tracking; Cartesian product; Sparse coding; Support vector machine regression; Ridge regression
TP391
A
1009-5896(2015)03-0516-06
10.11999/JEIT140931
2014−07−15收到,2014-10-28改回
国家自然科学基金(61175029, 61379104, 61372167),国家自然科学基金青年科学基金(61203268, 61202339),博士后特别资助基金(2012M512144)和博士后面上资助基金(2012JQ8034)资助课题
*通信作者:黄宏图 huanghongtu@sina.cn
