基于示例选择的目标跟踪改进算法
2015-06-27汪荣贵蒋守欢梁启香
李 想,汪荣贵,杨 娟,蒋守欢,梁启香
(合肥工业大学计算机与信息学院,合肥230009)
基于示例选择的目标跟踪改进算法
李 想,汪荣贵,杨 娟,蒋守欢,梁启香
(合肥工业大学计算机与信息学院,合肥230009)
多示例学习是一种处理包分类问题的新型学习模式,传统基于多示例学习的目标跟踪算法在自适应获取正包时受到无益或有害示例的干扰,不能很好地提取目标的鉴别性特征。为此,设计基于核密度估计的示例选择方法,剔除训练集中的无益示例或有害示例,提高多示例学习算法的有效性,并在此基础上提出一种基于示例选择的目标跟踪改进算法,针对负示例占多数的情况建立核密度估计函数来精简正包中的示例,使用精简后的样本数据进行训练学习,最终实现对目标的实时跟踪。实验结果表明,该算法在光照变化、目标部分遮挡及形体变化等情形下都具有较好的稳健性。
多示例学习;有害示例;核密度估计;示例选择;稳健性;目标跟踪
1 概述
视频中运动目标的自动跟踪是计算机视觉的重要研究内容,在安全监控、视频内容分析、机器人导航等领域都有着广阔的应用前景。然而,在实际跟踪过程中,通常会遇到光照变化、复杂背景的干扰,以及目标的部分遮挡和形体变化等情况,这些都会导致跟踪精度下降甚至跟踪漂移或丢失。因此,跟踪算法的稳健性在视频跟踪过程中具有非常关键的作用。
稳健性跟踪算法是视频目标跟踪研究的重点和难点,其具有代表性的研究成果主要有:文献[1]提出了基于MeanShift的目标跟踪方法,该方法在物体遇到目标遮挡和形体变形时仍能实时的跟踪,但当背景与目标相似情况下该算法鲁棒性较差;文献[2]提出使用支持向量机(SVM)对目标进行跟踪,但该算法计算量大跟踪实时性弱;文献[3]提出基于子块的积分直方图跟踪方法,该跟踪方法可以很好地处理部分遮挡问题,但不能较好地适应形体变化;文献[4]提出基于AdaBoost级联的人脸检测方法,使用Haar-like小波特征和积分图方法提取人脸特征训练AdaBoost,并对AdaBoost训练出的强分类器级联对人脸进行检测,并取得较好的检测结果;文献[5]提出基于分类的目标跟踪方法,在线的方式训练Boosting特征分类器提取鉴别性特征分离目标和背景,实现了对目标物体地跟踪。Boosting算法通过对复杂背景模型的在线学习,可以较好地处理跟踪时出现的干扰和自身变化等情况。然而Boosting算法在训练阶段利用已知的概念标记类更新分类器,可是在实际应用中能标记的信息少而模糊[6],导致Boosting算法具有内在不确定性即样本的歧义性[7]。
多示例学习(Multiple Instance Learning,MIL)[8]由Dietterich于上个世纪90年代提出。这种学习的训练样本由包组成,因而在处理标记模糊性问题上比传统的学习方法更加灵活。Paul Viola提出一种基于多示例学习目标跟踪方法,该方法通过对包的训练学习将内在不确定性传递给学习算法,以此构造MILBoost分类器对目标进行检测。文献[9-10]在Paul Viola的基础上采用自适应外观模型,并改进MILBoost算法将其应用到目标跟踪,取得了较好的跟踪效果。但对于MILBoost跟踪系统来说,通过跟踪结果来预测目标的最佳位置,根据该点位置在一定搜索半径内选择出样本训练集正包和负包,然而在搜索半径内获取满足条件的训练样本较多,会阻碍多示例学习的有效性。事实上,该方法得到的正包训练样本占主导地位的往往是负示例,此时通过提取目标鉴别性特征来更新分类器反而降低跟踪精度。
本文通过对多示例进行在线筛选的思想解决上述问题,提出一种基于高斯核密度估计的在线示例选择方法。通过对多示例学习框架和核密度估计方法的研究,以及对获取的训练样本中负示例占多数现象的分析,利用AdaBoost分类器训练得到的特征集,建立基于负示例的高斯核密度估计函数来在线筛选正包中的示例,用筛选过后的正包在线更新AdaBoost分类器预测目标的最佳位置,由此提高跟踪算法的稳健性。
2 多示例学习与核密度估计
2.1 多示例学习
多示例学习被认为是与监督学习、非监督学习和强化学习并列的一种新型机器学习框架,文献[11]提出多示例学习概念,将每一种分子作为一个包,分子的每一个同分异构体作为包中的一个示例。拓展到理论研究上即训练样本集由若干个概念标记的包组成,每个包包含若干个没有概念标记的示例,若一个包中至少包含一个正样本,则该包标记为正,若一个包中的所有示例都是负样本,则该包标记为负。通过对训练包的学习,尽可能正确地对训练集之外包的概念标记进行预测[12]。
在传统的学习框架的训练模式下,处理的样本是一类已知的标记类,然而实现应用中可提供的标记信息少而模糊,而多示例学习处理的训练样本是以包为单位,只需知道包的概率标记而不是示例,在处理标记模糊性方面更加灵活[13]。多示例学习方法在图像检索、数据挖掘以及图像分割、目标检测和目标跟踪等领域具有良好的应用前景。
传统鉴别性学习算法训练二值分类器来估算p(y|x),{(x1,y1),(x2,y2),…,(xn,yn)}表示训练样本集(xi表示样本,yi表示二值标记),在多示例学习框架里训练数据由包组成,表示形式为{X1,X2,…,Xn},其中,包Xi={xi1,xi2,…,xim};xij表示包中示例,yi∈{0,1}是包的概念标记,则包的概念标记定义为:

其中,yij是示例标记,实际训练过程中yij是未知的。由多示例学习框架得知,训练集由若干个具有概念标记的包组成,每个包包含若干没有概念标记的示例。从训练角度来看,如果训练数据过多,会导致跟踪算法的计算复杂度增加,且训练数据中会存在对分类结果无用的示例,导致分类器精度下降。由于非参数核密度估计方法不需要假定数据的密度分布形式,直接从数据中估计未知密度函数。因此,本文在训练阶段运用核密度估计方法对训练样本进行筛选。
2.2 核密度估计
核密度估计是由Rosenblatt和Parzen提出的一种非参数检验方法。该方法不使用数据分布的先验知识,是一种从数据样本本身出发研究数据分布特征的方法,因而在统计学和应用领域均受到高度重视。下面简要介绍核密度估计基本知识。
设数据{x1,x2,…,xn}取自连续分布,在任意点x处的总体概率密度函数f(x)的核密度定义为:

其中,h为预先给定的正数,通常称为窗宽或者平滑参数。
(x)表现的好坏与核函数K(u)和窗宽h有关,当窗宽较大时(x)的估计较稳定,方差波动较小,反之,当窗宽较小时,估计的偏差较小,使得f^(x)的波动方差较大。
为了保持概率密度估计的合理性,通常要求核密度满足以下条件:
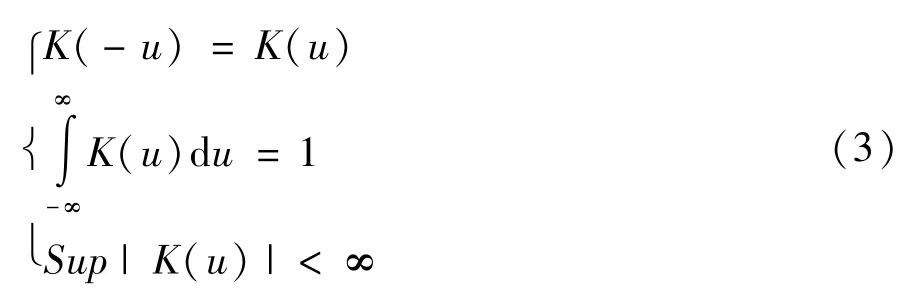
常用的核函数有以下3种:
(1)高斯核函数:

(2)Epanechnikov核函数:

(3)Biweight核函数:
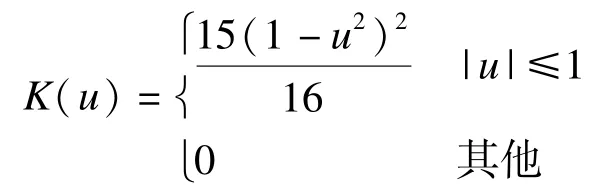
依据高斯模型运算简单的优势,核密度估计模型对随机序列分布描述精确的特点,本文将非参数的核密度估计方法和高斯模型结合,综合利用两者的优势与特点对示例进行选择。
3 基于高斯核密度估计的示例选择
本文利用多示例学习框架对目标进行跟踪时,采用自适应方式选择训练样本数据,通过预测目标物体的最佳位置l∗,将满足条件X+={||l(x)-l∗(x)||<r}选取得到的训练样本集作为正包中的示例,而满足条件X-={r<||l(x)-l∗(x)||<β}选取得到的训练样本集作为负包中的示例。
这种方式选择得到的训练样本会存在以下2个问题:(1)训练样本提取的特征过多,增加计算复杂度;(2)训练样本包会存在干扰示例,并且干扰示例具有绝对的选择权,会弱化分类器的分类结果,导致下一帧跟踪目标的预测位置错误。因此,在基于多示例框架的跟踪过程中,需要摒弃对分类过程产生干扰的无益示例或者有害示例[14]。其中,无益示例指一些类中不能提供有用的信息的示例;有害示例指在分类过程提供错误信息导致分类错误的示例。
假设对于某个示例集合C={a1,a2,…,as}(ai是类中的示例)。运用多样性密度(Diverse Density, DD)算法来计算某个示例ai在全部包的概率大小,如式(4)所示:
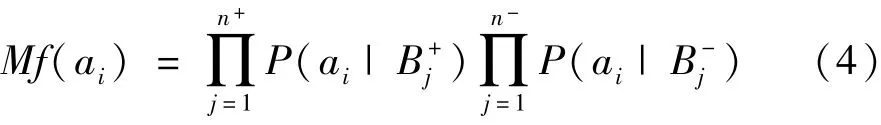
根据Bayes理论计算ai概率大小其复杂度高,而且DD方法在选择示例方面更加严格,因为它总是只能寻找一个示例。这种示例选择方法获得的训练集中仍存在很多无益示例或者有害示例。所以,本文提出基于核密度估计的示例选择,以有效减少训练集中无益示例或者有害示例对分类结果的干扰,提高目标跟踪算法的稳健性。
假设{x1,x2,…,xn}是n个离散的样本,其服从的分布概率密度函数f(x),则密度估计为:

其中均匀核函数为:

若将式(5)窗宽放宽就得到一般核密度估计表示形式(式(2))。
为提高核密度估计的计算效率,本文采用运算简单高斯核密度,即高斯核密度估计函数。假设fei为某一特征,则fei的高斯核密度函数如下:

其中,mi表示第i个负包中扫描示例得到fei个数;xij表示第i负包中第j个示例的特征值;μ表示对应特征fei负包示例的均值;σ表示对应特征fei负包示例的方差。
示例选择的基本原理如下:
(1)利用AdaBoost分类器训练得到的特征集,对于每个特征计算负包中示例的特征值。
(2)建立相应的高斯核密度分布函数fei(x)。
(3)计算正包中的示例特征值,如果对于正包中的某示例的分布多次满足建立的高斯核密度分布(即正包中的示例满足分布两垂直虚线之间,如图1所示),则认为它是负示例,将其剔除;反之,则保留。

图1 高斯核密度函数分布
将通过高斯核密度估计函数筛选过后得到训练样本的正包,与原负包的样本一起训练AdaBoost分类器,再对目标物体进行分类并预测跟踪目标的最佳位置。但是每当有新的数据{(x1,y1),(x2,y2),…,(xn,yn)}时,若还采用原有的高斯核密度估计分布函数对正包进行筛选,会直接导致跟踪精度的下降,算法的稳健性减弱。因此,本文采用如下策略对示例选择算法的高斯核进行在线更新:
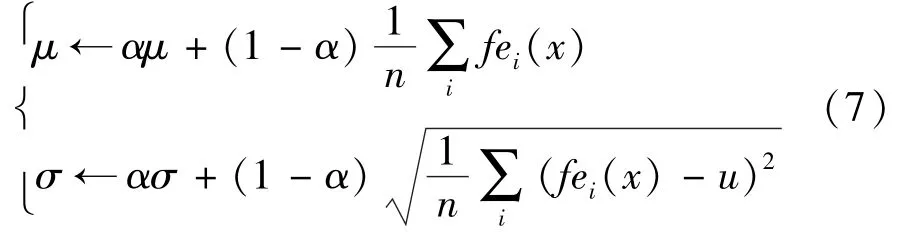
图2举例说明基于高斯核密度估计的示例选择算法,其中,实现为正包样本;虚线为负包样本(图中所框定出来的正负包样本只是训练样本一部分)。

图2 示例选择说明
4 稳健性目标跟踪算法
本文提出一种基于高斯核密度估计示例选择的目标跟踪算法。该算法在训练阶段,剔除正包中无益或者有害的示例,并训练AdaBoost分类器进而对目标物体进行跟踪。然而跟踪的初始化阶段并不进行示例选择,而是通过人机交互方式提取样本,并训练AdaBoost分类器。以图3为例,先将第1帧作为训练帧,通过手动定义样本的位置信息并规定样本统一的高宽来选取正负包,将目标位置四周的样本如实线框所示样本作为正包中的示例,而远离目标的样本如虚线框框所示样本作为负包中的示例。图3中黑色实框的样本为正包样本,白色虚框的样本为负包样本(其中图中所框定出来的正负包样本只是训练样本一部分),并对得到的训练样本集利用AdaBoost分类器进行训练。

图3 训练样本手动定义示例
本文训练AdaBoost训练器所用特征是Haarlike特征[15],如图4所示。利用积分图方式求出图像中所有区域像素和,针对图中的矩形特征的计算,通过计算特征矩形的端点积分图,再进行简单的加减运算得到特征值,这样计算方式大大提高计算速度。

图4 Haar-like特征
训练AdaBoost分类器除了得到的特征集建立高斯核密度估计外;同时还利用得到的弱分类器组合成强分类器来预测下一目标的最佳位置l∗,目标的最佳位置l∗采用具有连续置信度输出的LUT型弱分类器,如图5所示,其中,hj(x)表示特征对应的弱分类器,Wk+1和Wk
-1分别表示作为正示例和负示例的权重之和(其中,k表示第k区间),将正包中示例的置信度高作为当前帧t的目标位置即为目标的最佳位置
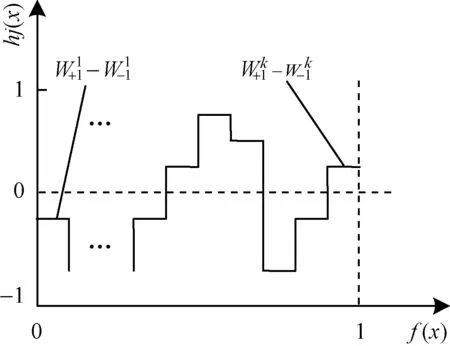
图5 LUT型弱分类器
综上所述,本文跟踪算法步骤如下:
Setp 1初始帧,通过人机交互获取样本集,运用积分图计算Harr-like特征,并训练AdaBoost分类器,所有的特征均值和方差都设置为0。
Setp 2预测当前帧t的最佳位置,根据{||l(x)-l∗(x)||<r}和{r<||l(x)-l∗(x)||<β}将样本分为正包和负包。
Setp 3并利用上一帧训练AdaBoost分类器得到的特征集,计算负包中的示例的Harr-like特征,建立高斯核密度函数,在线更新均值μ和方差σ。
Setp 4计算正包中某示例是否满足某个特征的高斯核密度分布,通过对每个示例设置计数变量来判断;如果某示例多次满足高斯核密度函数分布,则将该示例删除,以此筛选正包中的示例。
Setp 5在线更新AdaBoost分类器。
Setp 6预测下一帧的位置前,先判断这帧是否是最后一帧,如果是则结束,否则转步骤Step2。
本文目标跟踪算法流程如图6所示。

图6 本文目标跟踪算法流程
5 实验结果与分析
本文实验平台为CPU双核2.6 GHz,内存2 GB,软件为Matlab R2009a,Windows XP操作系统。为了验证本文算法的有效性,实验中选取了多组具有代表性的视频进行处理,这些视频中包含了目标的遮挡,光照的剧烈变化,目标的快速移动等较难处理的情况。本文采用 MIL跟踪方法以及 OAB(Online AdaBoost)跟踪方法作为对比实验,并且分别通过主观观察和客观评价方法验证本文算法的优越性。
本文所采用的实验对比方法采用相同的运动模型,算法在跟踪的初始化阶段,需要手动定义目标的训练样本,初始时设置μ0=0,σ0=0。本文算法和OAB算法设置搜索半径为30像素,在搜索半径内未发现目标时,下一帧将扩大搜索半径,扩大率为ε=1.1。对于本文算法,对于本文算法每一帧的半径r=5范围内视为正包中的示例,一般情况下正包中包含约60个的图像子块;对于负包示例的半径设置为β=55,一般情况下负包中会生成约70个的图像子块。更新策略的参数本文设置为α=0.85。图7为实验结果对比,其中,黑色直线为本文算法;白色点划线为MIL算法;白色虚线为 OAB算法。图7(a)为视频 david inside的跟踪效果,本文提供了#1,#14,#154,#277, #316和#460帧作为效果展示图,从效果图可以看出视频跟踪中遇到光线变化和自身变化等情况,本文算法较MIL和OAB都具有较好的跟踪效果。图7(b)为视频sylverster的跟踪效果,此视频主要难点在于目标的自身变化和光照变化,如#1,#389,#608,#866,#933, #1344图中所示,本文算法在跟踪效果方面比MIL算法和OAB算法好。图7(c)从occluded face2中选取#1,#282,#411,#658,#732,#812的效果图,本视频存在的主要处理难点是人脸遮挡问题,该视频中人脸的遮挡率大75%,,如#732,本文算法仍然有较好的跟踪效果。图7(d)从tiger2中选取#1,#53,#114,#205,#329, #362的效果图,该视频主要处理的是物体的快速移动以及经常性遮挡,从图中可以看出,当目标出现全遮挡本文算法依然可以跟踪。
上述的实验结果对比是从主观上来评价本文算法的优越性,下面从客观角度来衡量本文算法性能。目前对于跟踪算法主要采用中心像素误差作为评价标准,中心像素距离指的是目前跟踪到的目标中心位置与目标实际中心位置的像素距离。图8为每个视频基于中心像素距离标准的跟踪效果对比,其中对于每个视频每隔5帧,提取该目标的中心位置和实际中心位置的像素距离。
但是这种方法并不能很好地分析跟踪算法准确性,如图9所示,由图9(a)可以看出,尽管它们的中心点重合,但是由于文章采用自适应选取样本,因此它在大小和形状相差很大,如果单独考虑中心像素误差,会认为跟踪精确度达到100%,但事实情况并非如此。图9(b)显示目标较大时,尽管中心平均像素误差较大,但还是有较多区域重合,而目标较小时,如图9(c)所示,尽管中心平均像素误差较小,但跟踪结果已偏离目标。因此,本文认为跟踪目标的准确度和目标的中心位置有关,还和目标的大小有关,为此本文采用一种更加严格的评价标准,基于重合面积的精确度计算方法[16-17]。

图7 实验结果对比
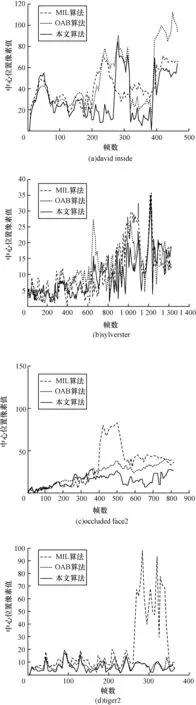
图8 中心像素距离对比
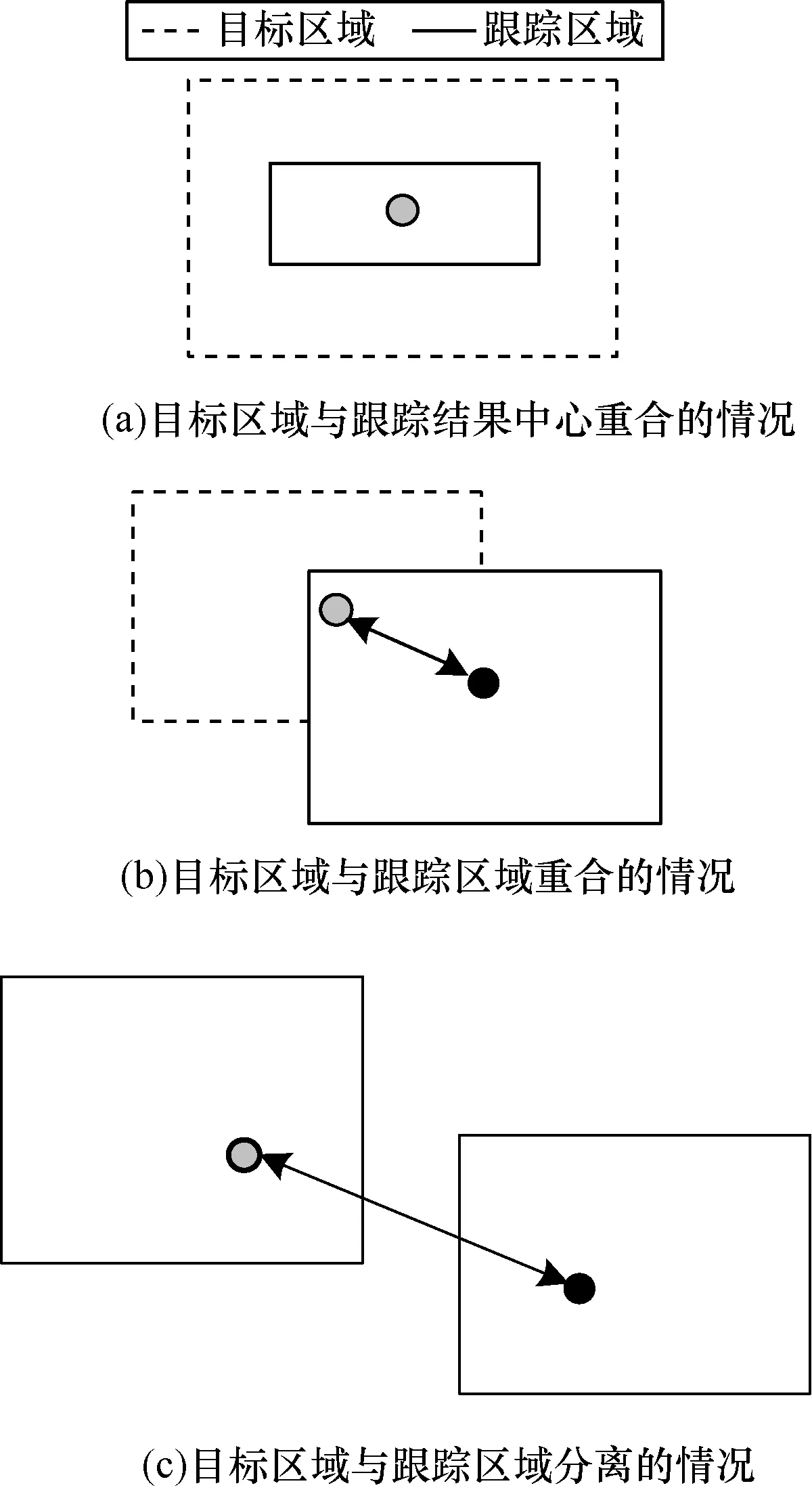
图9 跟踪结果现象分析
如图10所示,S1代表真实目标区域面积,S2代表跟踪到的目标区域面积,S3为S1和S2面积的重合部分,则其精确度评价标准p为:


图10 重合面积表示
基于此评价标准,对图8中的每个视频的跟踪效果进行对比,结果如图11所示。
由图8和图11的实验结果可以看出,在视频跟踪的前期阶段,MIL算法跟踪效果较好,因为MIL算法主要通过基于部分模型解决遮挡问题,但不能很好地解决目标的自身变化。而OAB算法跟踪整体效果不错,但跟本文算法相比,由于训练样本过多,导致跟踪精度都不如本文算法。从上面的主观和客观的分析结果可以看出本文提出的方法能够更加稳健的跟踪到目标,并且在背景复杂,光线变化,物体的快速移动,目标遮挡等复杂条件下,都具有较高的准确率。
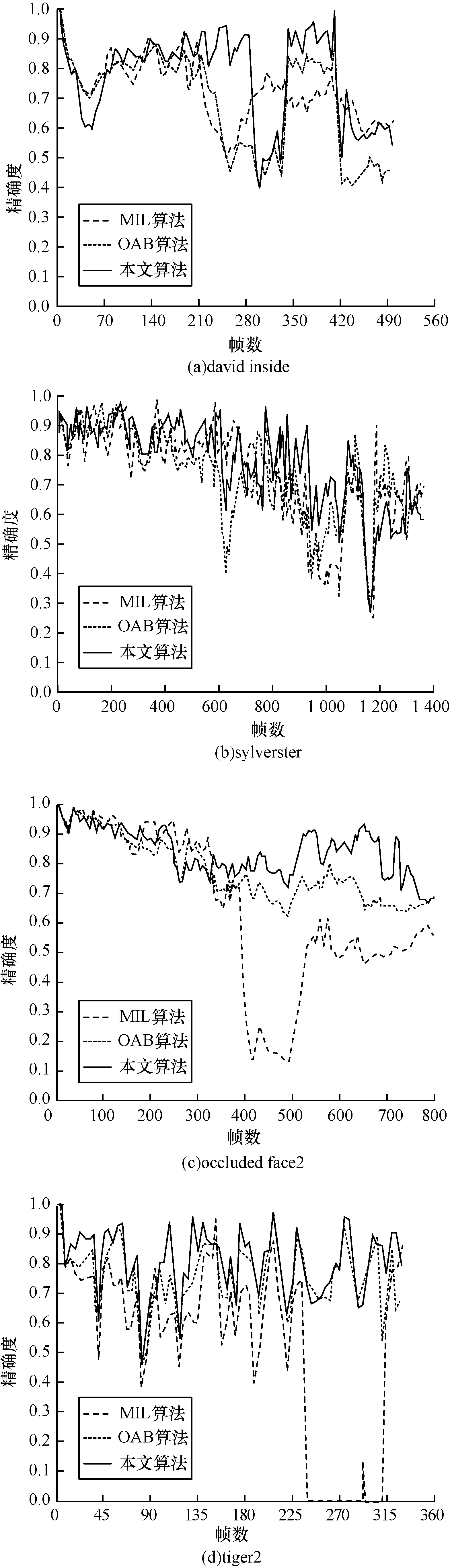
图11 重合精确度对比
6 结束语
本文对多示例学习框架训练分类器的优点与不足进行分析,根据选取训练样本的样本分布特点,提出了基于高斯核密度估计的示例选择的目标跟踪方法,并针对负示例占据主导优势的情况,建立基于负示例分布的高斯核密度,对正包中的示例进行筛选,得到最终的训练样本数据,然后更新训练AdaBoost分类器对目标进行跟踪。实验结果表明,本文算法在处理遮挡、光照变化、快速移动以及自身变化的情况时,具有较好的跟踪效果。
[1] Comaniciu D,Rameshand V,Meer P.Real-time Tracking of Non-rigid Objects Using Mean Shift[C]// Proceedings of CVPR’00.Hilton Head Island,USA: IEEE Press,2000:142-149.
[2] Avidan S. Subset Selection for Efficient SVM Tracking[C]//Proceedings of CVPR’03.Madison, USA:IEEE Press,2003:85-92.
[3] Adam A,Rivlin E,Shimshoni I.Robust MILments-based Tracking Using the Integral Histogram [C]// Proceedings of CVPR’06.New York,USA:IEEE Press, 2006:798-805.
[4] Viola P,Jones M J.Real-time Face Detection[J]. International Journal of Computer Vision,2004,57(2): 137-154.
[5] Grabner H,Grabner M,Bischof H.Real-time Tracking via Online Boosting[C]//Proceedings of BMVC’06. Edinburgh,UK:[s.n.],2006:47-56.
[6] Li Mu,Kwok J T,Lu Baoliang.Online Multiple Instance Learning with No Regret[C]//Proceedings of CVPR’10.San Francisco,USA:IEEE Press,2010: 1395-1401.
[7] Viola P,PlattJC,Zhang Cha.Multiple Instance Boosting for Object Detection[C]//Proceedings of NIPS’05.Whistler,Canada:[s.n.],2005:1417-1426.
[8] Dietterich T G,Lathrop R H,Lozano-Pérez T.Solving the Multiple-instance Problem with Axis-parallel Rectangles[J].Artificial Intelligence,1997,89(1/2):31-71.
[9] Babenko B,Yang M H,Belongie S.Visual Tracking with Online Multiple Instance Learning[C]// Proceedings of CVPR’09.Miami,USA:IEEE Press, 2009:983-990.
[10] Babenko B,Yang M H,Belongie S.Robust Object Tracking with Online Mutltiple Instance Learning[C]// Proceedings of PAMI’11.Miami,USA:IEEE Press, 2011:983-990.
[11] Maron O,Lozano-Perez T.A Framework for Multiple Instance Learning[C]//Proceedings of NIPS’98. [S.l.]:MIT Press,1998:570-576.
[12] 邓剑勋,熊忠阳.多示例图像检索算法研究及在人脸识别中的应用[D].重庆:重庆大学,2012.
[13] Zho Zhihua,Xu Junming.On the Relation Between Multi-instanceLearning and Semi-supervised Learning[C]//Proceedings of ICML’07.New York,USA: [s.n.],2007:1167-1174.
[14] Fu Zhouyu,Robles-Kelly A,Zhou Jun.MILIS:Multiple Instance Learning with Instance Selection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(5):958-977.
[15] Suha K,Nam W,Han B.Learning Occlusion with Likehoods for Visual Tracking[C]//Proceedings of ICCV’11.Barcelona,Spain:[s.n.],2011:1551-1558.
[16] 戴经成,汪荣贵,游生福,等.在线多示例学习目标跟踪方法研究[J].计算机工程与应用,2012,48(15): 129-135.
[17] 戴经成,汪荣贵.基于多示例学习的图像分析方法研究[D].合肥:合肥工业大学,2013.
编辑 金胡考
Improved Object Tracking Algorithm Based on Instance Selection
LI Xiang,WANG Ronggui,YANG Juan,JIANG Shouhuan,LIANG Qixiang
(School of Computer and Information,Hefei University of Technology,Hefei 230009,China)
Multiple Instance Learning(MIL)is a new learning paradigm that deals with the problem of bags classification.The object tracking algorithm based on MIL is often interfered by useless or harmful instances when adaptively choose positive bags,and can not extract good discriminative feature,and this will affect the robustness of tracking algorithm.Therefore,this paper proposes an instance selection method based on kernel density estimation to improve the efficiency of MIL algorithm,which eliminates useless or harmful instances in training set,and then on this basis it provides a robust object tracking algorithm based on instance selection.Firstly,the algorithm builds up kernel density estimation function,uses it to optimize instances of positive bag for the majority of them are negative instances, and then uses the optimized training data to training-and-learning,and finally achieves real-time object tracking. Experimental results demonstrate that when the object suffers from the illumination changes,object partial occlusions, appearance changes and some other situations,the proposed object tracking algorithm is more robust.
Multiple Instance Learning(MIL);harmful instance;kernel density estimation;instance selection; robustness;object tracking
1000-3428(2015)01-0150-08
A
TP181
10.3969/j.issn.1000-3428.2015.01.028
国家自然科学基金资助项目“雾天视频中目标跟踪的视觉计算模型与方法研究”(61075032);安徽省自然科学基金资助项目(1408085AF117)。
李 想(1990-),女,硕士,主研方向:计算机视觉;汪荣贵(通讯作者),教授、博士;杨 娟,讲师、博士;蒋守欢、梁启香,硕士研究生。
2014-02-18
2014-03-21 E-mail:wangrgui@hfut.edu.cn
中文引用格式:李 想,汪荣贵,杨 娟,等.基于示例选择的目标跟踪改进算法[J].计算机工程,2015,41(1):150-157.
英文引用格式:Li Xiang,Wang Ronggui,Yang Juan,et al.Improved Object Tracking Algorithm Based on Instance Selection[J].Computer Engineering,2015,41(1):150-157.
