移动机器人检测识别技术的研究
2015-06-26汤辰万衡王凯凯
汤辰,万衡,王凯凯
(上海应用技术学院 电气与电子工程学院,上海 201418)
0 引言
时代在进步,科学在发展,在工业领域以及家庭中很多时候机器人可以代替人类进行各项操作,通过图像处理技术可以获取大量的信息进行计算分析,从而使得机器人拥有人类所具有的分类、分割、识别、跟踪、判别决策等功能。其中目标的检测识别是图像处理技术中的重要任务之一[1]。目前,SIFT算法是识别技术的主流技术之一,该算法是基于尺度空间下的特征点检测,对光照变化、尺度缩放、仿射变化以及角度变化等具有一定的不变性[2]。同时也存在特征提取较多、配准点冗余、匹配耗时等问题。
针对以上出现的情况,本文采用分割级联分类器的检测目标作为原图与目标图进行SIFT配准的方法,其中级联分类器分割出目标作为原图的做法有效地缩小了配准的区域范围,直接减少了特征点提取的数目,大大提高了SIFT配准的效率。因此使用级联分类器提取目标物体的手段具有很大的优势,尤其是与SIFT算法相结合时体现出了其优越性。
1 SIFT算法
1.1 尺度空间的建立
为了使从图像中提取出来的特征点具有不变性,特征点的检测通常是在不同的尺度下完成的,以获取图像的特征点在不同尺度下的信息[3]。尺度空间是采用高斯卷积核与原图像卷积而成的。一幅在不同尺度下的图像定义为I(x,y),高斯卷积核为G(x,y,σ),则其公式表达形式如下:
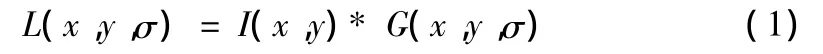
其中L为图像的尺度空间,x和y为图像点的像素坐标,σ为尺度因子,它也是高斯正态分布的方差,其反映了图像被平滑的程度,该尺度因子越大图像越模糊,反之则分辨率越高。
1.2 构建金字塔
所谓金字塔就是采用不同的高斯卷积核对原图像进行降采样得到的图像进行卷积[4]。为了让图像在不同尺度下保持一定的连续性,则在采样的过程中加入Gaussian滤波,该处理方式可以让原图像产生几组(Octave)不同模糊程度的图像,每一组图像又分为几层(interval)图像。
为了进一步在图像中找到高精度的配准特征点,基于图像金字塔的基础之上建立高斯差分金字塔(DOG尺度空间),DOG尺度空间中金字塔每一个相邻层的差值与高斯差分卷积核进行卷积而形成高斯差分金字塔[5],通过层与层图像相减获得的局部坐标极值点,在很大程度上减少了计算量(如图1所示),高斯差分尺度空间用DOG算子表示如公式(2)所示:

1.3 检测极值点
高斯差分金字塔建立之后,需要在其每一层寻找极值点,并将这些极值点作为候选点,再对这些候选点进行一系列的判断选择。为了可以在尺度空间下找到极值点,就是要将高斯差分金字塔任意一层中的采样点与周边的点进行比较,若大于或者小于周边点,则为极值点[6]。如图2所示,任意一层的采样点与处在同一层中周边的8个点以及上下两层18个点进行比较,也就是和26个点进行对比,若该点在 DOG尺度空间下为最大值或者最小值时,则该点就判断该点为该尺度下的极值点。

图1 高斯差分结构图

图2 高斯差分影像特征点检测
1.4 确定主方向并生产特征描述符
根据梯度直方图,分配关键点方向的具体过程如下:
(1)通过运算获取SIFT特征点的直方图参数;
(2)直方图是由36个柱所组成,其范围为0度到360度,其中每一个柱为10度;
(3)采用高斯函数对方向直方图进行平滑处理;
(4)求得直方图的梯度方向;
(5)对该特征点的直方图进行三维二次拟合处理,进一步明确关键点的方向;
当SIFT关键检测完成之后,则这些检测出来的关键点都具备尺度、方向、位置三个数据信息;因此而具备旋转、缩放和平移不变性。
将特征点周围16×16的窗口分解成为16个4×4的窗口,其中,在这些4×4的窗口中来计算梯度的大小和方向,图中每一个窗口则代表一个像素,每一个像素都含有8个梯度方向,并且直方图中加入的值是该像素用高斯加权之后的梯度大小,然而特征点周围16×16的窗口中含有16个4×4的子窗口,共有16×8=128个[7],最后将这128个数组成的向量进行单位化,单位化之后的向量也就是SIFT的特征描述子。
1.5 SIFT特征匹配结果
如图3所示,原图和待配准图的特征点数目分别为2 319个和2 033个共有1 679个特征点匹配。两张图片在位置角度上有所偏差,但影响效果不大。特征点的检测分别耗时1.87 s、1.35 s,匹配用时 12.034 s。

图3 SIFT算法特征匹配
2 局部目标特征提取
针对目标物体的特征形式来训练弱分类器,通过某种迭代的方式将这些弱分类器融合成一个强分类器,采用Adaboost算法将我们所训练的强分类器串联起来形成级联分类器(Cascade Classifier)其训练检测过程如图4所示。

图4 级联分类器检测原理
2.1 训练级联分类器
采集N个大小为20×20的训练样本,其中正样本m个(只包含检测物体的样本),负样本n个(不包含检测物体的样本)。选取分类错误率最小的值为原则,其分类错误率最小为如下公式(3)所示:

此时该阈值所对应的弱分类器即为最佳的弱分类器。
强分类器的检测精度才能满足我们的检测要求,其是由若干个弱分类器T轮迭代组成,具体步骤如下:
(1)给定一些列的训练样本(x1,y1).(x2,y2)……(xn,yn),其中yi=0表示其为负样本,yi=1表示其为正样本。n为一共的训练样本数量。
(2)初始化权重w1j=D(i);
(3)对t=1…T;
① 归一化权重:
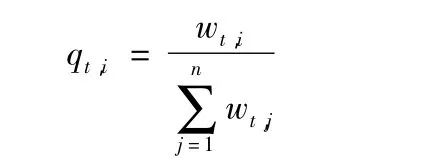
② 对每一个特征 f,训练一共弱分类器 h(x,f,p,θ);计算其对应所有特征的弱分类器的加权(qt)错误率εf。
(4)提高上一轮中被误判的样本的权重。
(5)将新的样本和上次本分错的样本放在一起进行新一轮的训练。
(6)循环执行4-5步骤,T轮后得到T个最优弱分类器。
(7)组合T个最优弱分类器得到强分类器,其组合形式如公式(4):
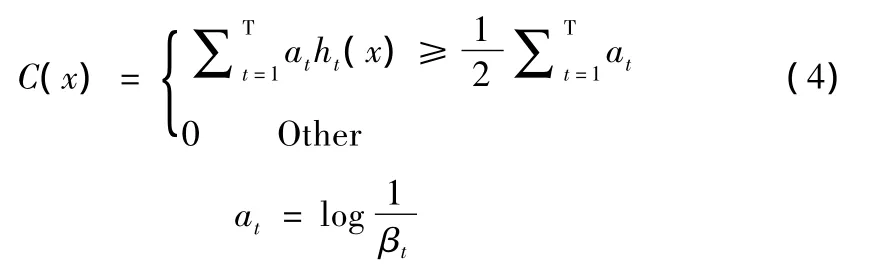
最终采用Adaboost算法将这些强分类器级联起来形成本文所需要的XML文件,即级联分类器。
2.2 基于级联分类器结构的改进
级联分类器的训练属于一种离线训练方式,需要大量的前期准备工作,为了提高检测提取的精度,降低训练的时间,提出了改变分类器结构的方法,即在级联结构中引入辅助的判断函数,当样本被某分类器判别为假时,使用该级的判断函数对其进行二次判断。该判断函数不仅得到了当前分类器的判断结果,同时也利用了之前的历史信息,如果输入样本被该判断函数拒绝,则该被拒绝的样本直接排除,在整个Adaboost算法当中每一级的级联分类器当中都加入该函数,其中第N级的判断函数如公式(5)所示:

其中xi代表第i级的样本,comfN(xi)代表第N级分类器对样本判断的加权值;∂即为当前的分类器的加权值;hN代表第N层分类器对该层分类器判断的结果;m表示该样本被之前m-1级分类器判断为假的次数。由以上公式可以看出m越大就越小,说明之前的样本被分类器判断为假的次数比较多,此时应该多考虑当前的判断。相反,若m越小则应该多考虑前几层的历史信息。试验表明,该辅助判断函数的加入,使得它在速度和精度上都有所改善。
2.3 图像局部特征检测结果
针对可口可乐瓶和矿泉水瓶分别训练两种级联分类器,其检测效果如图5所示。
采用该改进之后的方法进行训练,其在第一层强分类器的生成过程中所花费的时间为1 332.70 s,相比改进之前的1 897.11 s,在训练效率上有了较大的提高。
3 基于局部特征提取的SIFT匹配的实现
实验通过MFC设计了一个实现该方法的上位机界面,采用该系统界面只需要将正负样本采集好,描述文件做好,点击按钮即可完成级联分类器的训练,接着根据其圆心的图像坐标来提取目标物体作为原图与目标图进行SIFT配准,这样有效地减少了原图特征点的检测,从而加快了其配准的速度。该系统界面如图6所示。

图5 级联分类器检测效果
在完成了局部特征的匹配之后,采用K-means算法根据目标图中的SIFT特征点,找出稳定散落在目标物体上的一点,也就是图6中红色那一点,最后根据该红点转换成机器人所需要的三维坐标点传送给机器人的手臂模块有底盘模块完成物体的识别及抓取。
4 结束语
针对SIFT配准耗时的问题,提出了一种基于局部特征提取的SIFT匹配方法,通过减少原图特征点数目的原理在一定程度上提高了匹配的效率。该方法在MFC平台上进行实验,实验结果证明了本文方法的有效性,为日后对物体检测识别技术的研究奠定了基础。
[1]李明,蒋建国,齐美彬.基于SIFT特征点匹配的目标跟踪算法研究[D].合肥:合肥工业大学,2011.
[2]谢凡,秦世引.基于SIFT的单目移动机器人宽基线立体匹配[J].仪器仪表学报,2008:29(11):2-3.
[3]商磊.基于改进SIFT算法的图像配准研究[D].成都:电子科技大学,2014.
[4]唐红梅,张恒,高金雍,等.一种改进的基于SIFT特征的快速匹配算法[J].电视技术,2013,37(15):1-2.
[5]翟海涛,吴健,陈建明,等.基于SIFT特征度量的Mean Shift目标跟踪算法[J].计算机应用与软件,2011,28(6):2-3.
[6]杨环.人脸检测及人眼定位算法的研究[J].山东大学.2010:37(1):3-4.
[7]苏顺谦.基于SIFT特征的无人机遥感影像拼接技术研究[J].电光与控制,2012:19(3):2-3.
