多态并行阵列机中处理单元的设计与实现
2015-06-23刘应天
李 涛, 刘应天, 乔 虹
(西安邮电大学 电子工程学院, 陕西 西安 710121)
多态并行阵列机中处理单元的设计与实现
李 涛, 刘应天, 乔 虹
(西安邮电大学 电子工程学院, 陕西 西安 710121)
针对新型多态并行阵列机,设计一种专用处理单元。该处理单元采用四级流水线的超长指令字结构,指令系统采用无寄存器文件的直接寻址方式,加入独有的阻塞-非阻塞模式和邻接共享存储实现分布式指令并行和流处理运算,使用特殊指令完成PE间通信以及MIMD和SIMD的快速切换。实验结果表明,该处理单元能够实现运算模式分区并发执行和切换,工作最大频率可达167MHz.。
阵列结构;处理单元;超长指令字;阻塞标志;数据通信
在计算机图形处理器(Graphic Processing Unit,GPU)[1]体系结构发展的过程中,GPU从单纯的通过固定流水线与定制的逻辑功能部件来加速图形处理转变为利用可编程性[2],完成通用计算的阵列系统。现代图形处理架构大致可以归类为单指令多线程架构(Single Instrution Multiple Threads,SIMT)和单指令多数据架构(Single Instruction Multiple Data,SIMD)两种[3]。英伟达公司采用的SIMT架构性能相对较高,编译器设计复杂度相对较低,但是由于图形处理指令在执行之前需拆分成纯标量指令,所以其流处理器(Stream Processor)的设计相对较复杂,导致扩展性较差;而AMD公司采用的SIMD架构,性能相对较低,扩展性较好[4]。
针对上述问题,一种新型多态并行阵列众核处理器(Polymorphic Array Architecture for Graphics and Image Processing,PAAG)[5]被提出。通过自身架构下的处理单元(Processing Element, PE)实现多指令多数据(Multiple Instruction Multiple Data,MIMD)操作,通过多个处理单元和控制器联合实现SIMD操作,通过处理单元与相配套的线程管理器(Thread Manager, TM)实现线程运算粒度可控,提高扩展性,通过处理单元的通信机制实现静态和动态数据流计算,并且尝试在阵列机上实现多种模式分区并发和快速转换,同时在性能上尽量接近专用集成电路(Application Specific Integrated Circuit, ASIC)。
本文拟根据PAAG的体系结构和模式需求,为其设计专用的处理单元。该处理单元采用超长指令字结构,设计特殊指令用于MIMD和SIMD模式的切换,通过硬件线程管理器控制运算粒度粗细,使用共享存储和路由器实现近邻和远程通信机制,另外,采用特有的阻塞和非阻塞模式控制数据流动。最后,对硬件电路进行功能仿真和综合验证。
1 PAAG结构和运行模式
PAAG是由多个簇(Cluster)和特定功能单元连接构成的。完整的PAAG系统包括1个前端的处理器(FEP)、4个F簇(F Cluster0~3)、4个S簇(S Cluster0~3)、多个专用加速单元、外部存储器片上互联及片上缓存,其中F簇处理浮点运算和定点运算,S簇处理定点运算,系统整体结构如图1所示。
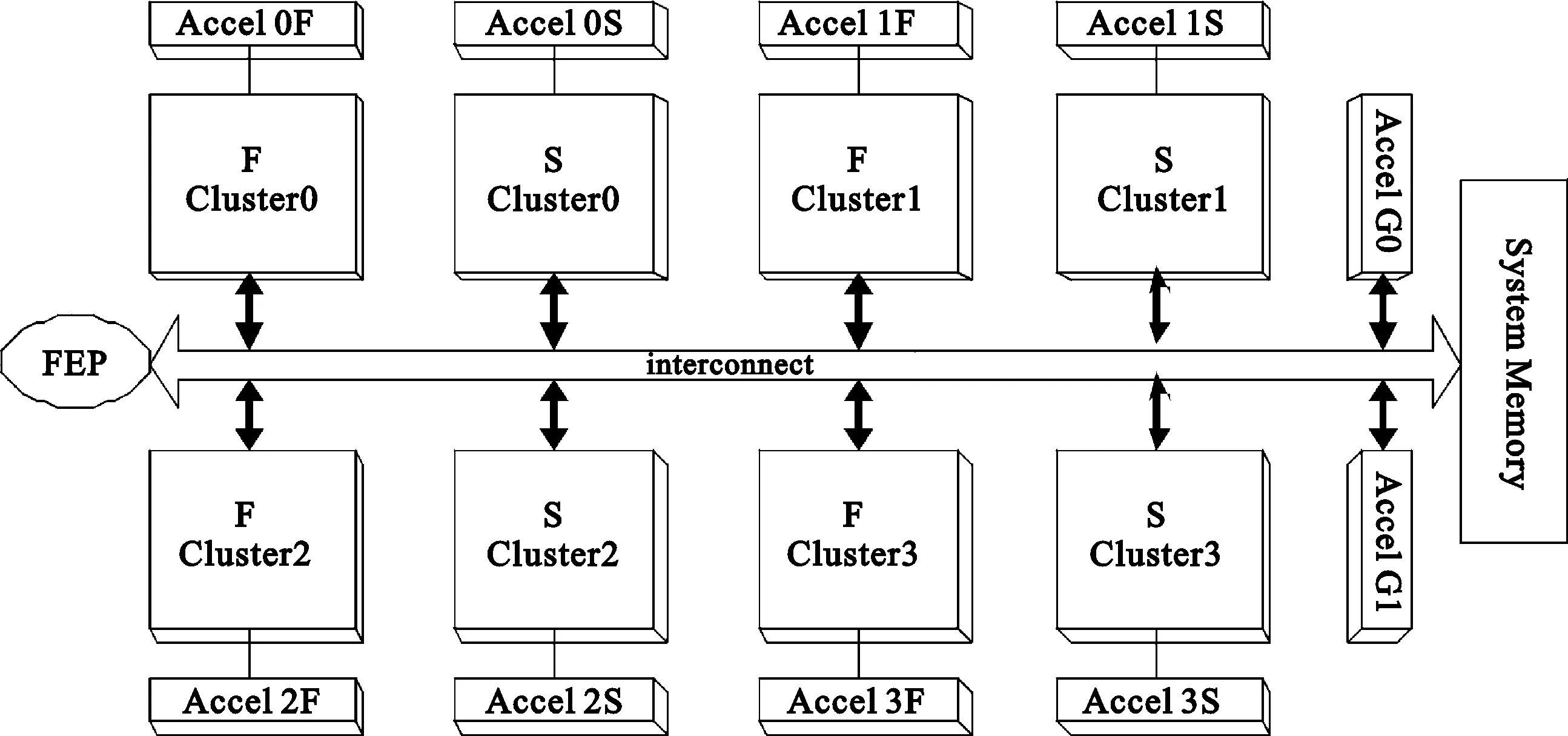
图1 系统整体结构
1个簇(Cluster)是由16个PE互联构成的4×4二维阵列,既可以平面结构展开,也可以分层次展开。簇中还包含1个簇控制器(Cluster)、4个行控制器(Row Controller, CR)和4个列控制器(Column Controllor, CC)[6]。簇控制器管理整个簇的运行,行控制器管理所在行的4个PE的SIMD运算,列控制器管理对应列存储,簇的基本结构如图2所示。

图2 簇的基本结构
PAAG有4种运行模式:MIMD运行模式、SIMD运行模式、分布式指令并行模式及流处理运行模式。
(1) MIMD运行模式
MIMD运行模式是PAAG的基本运行模式。一个程序被划分成多个基本任务,并分配到不同的PE上分别执行。任务之间如果需要传递计算结果,可以通过邻接共享存储或者路由器传递。
(2) SIMD运行模式
SIMD运行模式适合做数据并行计算。图形图像处理的运算对象通常为4维向量,用一行PE就可以完成该运算,如果需要做4维以上16维以下运算,可以用4~16数量PE做相应SIMD运算。
(3) 分布式指令级并行计算模式
分布式指令级并行计算的基础是数据流计算。PAAG采用计算结果直接链接的方法,无需使用寄存器重命名,这与数据驱动数据流的形式是一致的。
(4) 流处理运行模式
PAAG的流处理模式与典型的流水线类似,每个PE处理的颗粒粗细程度可以按照性能需求进行调整和配置。每个PE相当于一级流水线,重复执行分配的任务,并将结果通过邻接共享存储传递到其它PE。
2 处理单元的设计
若要支持PAAG实现上述运行模式,PE本身需要能够执行MIMD和SIMD运算,各线程指令粒度的粗细需要可配置并且线程间能够进行快速切换,更需要一个合适的数据传递机制[7]进行数据通信。
每个处理单元配有1个线程管理器(Thread Manager, TM)[8],1个路由器(Router Unit, RU)[9],以及与东(E)/西(W)/南(S)/北(N)4个邻接PE相连接的邻接共享存储(Me, Mw, Ms, Mn)。PE除了负责算术逻辑运算外,还要通过线程管理器实现8个线程的上下文切换,利用路由器和邻接共享存储实现PE间的数据通信,结构如图3所示。
采用超长指令字结构(Very Long Instruction Word, VLIW),每个时钟取两条指令进行处理,不同的两条指令进入两个独立的执行单元,发挥指令并行的特点。在MIMD模式下,PE执行来自本地指令存储的指令。采用没有寄存器文件的存储访问方式对本地数据存储进行访问,且设计有直接寻址的邻接共享存储器和片内数据存储器两种存取模式。在SIMD模式下,PE执行来自簇控制器和行控制器的SIMD指令,数据来自本地存储或邻接共享存储。指令读写屏蔽寄存器控制当前PE是否执行SIMD指令。

图3 处理单元及周边结构
一个PE有8个线程,当前某个线程暂停时,TM根据PE所处状态控制线程切换,执行其他线程指令。若原线程可以继续执行,线程管理器记录当前所处线程状态,切换回原线程。PE通过线程管理器的线程切换减少执行流水线空闲时间。
数据通信机制分近邻通信和远程通信两种。近邻通信是本地PE与东/西/南/北4个邻接PE通过邻接共享存储实现的数据通信方式。每个线程都在邻接共享存储中占有一个存储位置,可以直接寻址进行存取。共享存储存取有两种模式。
(1) 阻塞模式(线程间同步)
每个共享存储地址都有一位数据有效标志。读数据时,如果标志无效,则当前线程发生阻塞;如果标志有效,则取走数据,并将有效标志置于无效。写入数据时,标志无效则直接写入,标志有效则等待其变为无效后再写入。
(2)非阻塞模式(线程间异步)
在读取或写入数据时,忽略有效标志状态,直接进行读写。
远程通信是本地PE与非临近PE或列存储之间的数据交互方式。本地PE解析路由指令后,将控制信息和数据打成包发送至路由器,路由器根据包控制信息将数据包发送到目标PE。路由器允许数据多播,可以实现数据流的多目标扇出。路由器处理的信息包括MOVET/MOVEF(PE之间远程信息传递),MVT/MVF(PE与列控制器之间的远程信息传递),CALLR/RETR(远程函数调用)和CALLC/RETC(调用其他PE实现SIMD操作)。
3 处理单元的实现
3.1 指令集结构
采用指令双发射机制,两条指令的结构完全相同,单个指令结构如图4所示。指令采取直接存储寻址的方式,指令中加入阻塞标志,操作数分为直接寻址操作数和立即数两种,每条指令通常包含3个操作数。

图4 指令结构
指令最高位为阻塞标志位,操作码占6位,目的操作数和源操作数A各占11位,源操作数B占16位,可以是操作数地址,也可以是立即数。寻址空间在2K范围内,对于细粒度和中等粒度并行计算,该范围满足要求。指令包括以下7种类型。
(1) 定点算数与逻辑指令:定点算数包括加、减、乘、除,逻辑指令包括与、或、异或、移位等。这两类指令的操作数包括正整数和带符号的定点数两种。
(2) 定点比较与转移指令:根据比较后的结果判断是否需要转移控制流。
(3) 浮点算数指令:包括加、减、乘、除,操作数都是浮点数。
(4) 浮点比较与转移指令:根据比较后的结果判断是否需要转移控制流。
(5) 跳转与函数调用指令:可以实现无条件跳转、函数调用、函数返回以及远程调用等。
(6) SIMD屏蔽与上下文切换指令:用于SIMD模式的屏蔽操作和上下文堆栈操作。
(7) 远程路由指令:用于路由器远程传输数据等操作。
3.2 功能划分
处理单元在设计上包含指令预取、译码访存、执行、回写4个大的流水级[10]。指令预取每次可以取出一条超长指令字指令(包含两条单指令字),再由译码进行解析并产生访存控制信号。读取的数据经过多路分配逻辑分送到相应的执行单元进行运算,最后由地址流水单元控制来自执行级运算结果的写回操作。处理单元内部结构如图5所示,该图描绘了处理单元所包含的功能模块和内部的数据流向。

图5 处理单元内部结构
从功能上看,处理单元分为指令存储(imem)、指令预取单元(ifetch)、译码单元(decoder)、执行管线、地址流水线单元(addrpipeline)、数据存储(dmem)等模块[11]。
(1) 指令存储用于存放指令流,8个线程的指令存放在2个指令存储块(Bank)中。每个线程指令存储深度为1K,宽度为90位的双指令字。不同线程的指令地址通过指令基址加偏移地址区分。
(2) 指令预取主要包含取指控制、指令字缓冲(ififo)和指令PC缓冲(pcfifo),控制PC的自加、跳转、清空操作以及指令的读取。
(3) 译码单元对指令操作码进行解析,产生对数据流的控制信号;提取指令操作数,产生访存地址、立即数和PC值;比较源访存地址和目的访存地址,判断前馈数据是否命中;根据阻塞标志和读写地址判断是否出现阻塞状态并报告阻塞信息。
(4) 执行管线包含定点算术逻辑单元(Arithmetic Logical Unit, ALU)、定点乘、定点除、浮点ALU、浮点乘、浮点除和浮点前向单元共7个并行执行单元。
(5) 地址流水线主要产生和执行级数据同步的写地址和使能,控制数据向存储回写以及数据的互连通信。
(6) 数据存储负责响应译码控制单元和地址流水单元对数据的读写控制,还要处理从顶层互连接口写入的数据。数据存储结构采用分块(interleaved)结构,分为4个Bank,两条指令可以同时访问不在同一个Bank的数据,降低了数据存取的地址冲突。每个Bank根据线程个数又被分为8个区域,每个线程的数据在数据块中占据2K存储空间。
3.3 模块实现
指令预取单元连接指令存储和译码单元,如图6所示。该单元接收线程启动信号和初始化程序计数器(Program Counter,PC)后,产生读使能,计算指令地址并发送到指令存储。指令存储的每个地址存有一条双指令字,根据使能信号和地址将对应双指令字压入指令缓冲。另外,指令预取响应译码单元的读FIFO(First In First Out)请求,并在请求信号的下一个时钟弹出指令和同步PC值。发生转移或跳转时,指令预取要对ififo和pcfifo模块的内容进行清空,并将发送给译码单元的FIFO空信号置高,重新接收新的PC值。

图6 指令预取
译码单元连接指令预取、数据存储、执行单元及地址流水,完成指令弹出、指令解析、访存控制、阻塞判断以及数据分配等工作。按照职责的不同进行划分,译码单元又细分为指令解析、PC控制、阻塞处理及输出控制4个功能模块,如图7所示。另外,译码单元可在一个时钟内同时对两条指令进行处理。
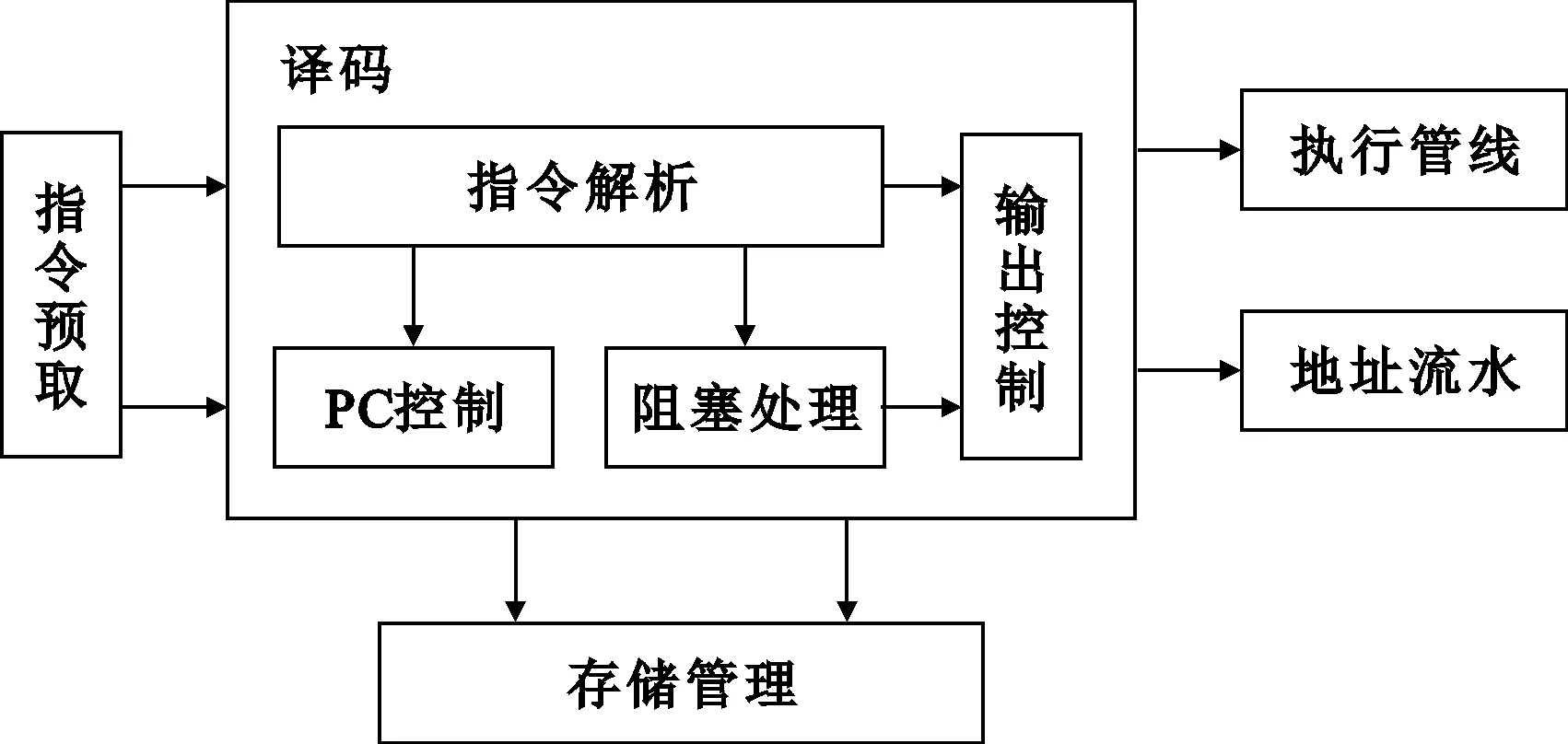
图7 译码单元
(1)指令解析模块产生指令弹出和数据流的控制信号。对于指令弹出使能信号,由于读取指令后没有对指令进行一级缓存,而是直接进行组合逻辑译码,因此,在发生数据阻塞、跳转以及线程终止时,该使能信号都会及时发生变化,控制下一条指令弹出。读数据使能根据每条指令的情况作详细处理,比如ADD加法操作含有两个源操作数,则两个操作数的读使能均置为有效。访问数据存储时,最大可同时进行四路数据的访问,两条单指令字最多含四个不同地址的源操作数。分配逻辑将待处理的信息分送到不同的执行单元,信息包括待分配数据和分配控制信号,待分配数据来自指令立即数、访存数据和前馈数据。
(2)PC控制模块通过解析的控制信号对指令流进行处理。设计的指令集中跳转指令有直接跳转和比较跳转两种。直接跳转分为绝对跳转指令JMPA和相对跳转指令JMPR,比较跳转指令如整数比较跳转BEQ,浮点比较跳转EQF等。对于直接跳转指令,译码单元直接进行解析、计算,并将跳转有效信号和跳转地址发送到指令预取单元;对于比较跳转指令,通过控制信号将读出的操作数送入执行单元,暂停流水线,等待比较结果,再根据比较结果反馈的跳转信息发送至指令预取单元。
(3)阻塞处理模块专门用于解决指令中遇到的阻塞问题。判断指令是否发生阻塞,不仅要看指令的标志位是否为高,还要看读写地址是否为阻塞通信地址。对PE的每个线程的存储地址进行统一编制,设定0~7为近邻通信地址,该线程指令若发生阻塞,读写地址一定在0~7范围内。
发生读阻塞时,指令阻塞标志为高,两个源操作数中某个操作数的读地址为近邻通信地址,且本地的近邻共享存储对应地址没有被写入数据;发生写阻塞时,指令阻塞标志为高,目的操作数的写地址为近邻通信地址,且目标近邻共享存储对应地址已经被写入数据。当发生读阻塞、写阻塞时,记录此时PC值、阻塞类型,产生指令字掩码并提交给线程管理器。
(4)输出控制模块负责将前面阶段处理得出源操作数和符号标志发送至执行管线,将目标地址、操作码和阻塞标志发送至地址流水单元。
地址流水线单元保存了每次发射的双指令字中的目的地址,并送入寄存器级联流水线中进行流水,以此来实现和运算单元的数据同步。最后将运算单元送来的结果和目的地址匹配分组并送到数据存储提交。在进行通信时,地址流水线需要根据通信地址将运算结果写入相应的通信接口寄存器。
从图8地址流水线结构上看,地址流水线的输入包括两路目的地址值、两路操作码以及执行级的七路运算结果。输出主要包括四路送往数据存储的数据,它们分别写进存储中不同的bank。其中操作码用于产生选择信号,由选择信号可以确定运算结果和目的地址之间的对应关系。将选择出来的结果和目的地址组合在一起,就可以送往数据存储和前馈逻辑。由于存储中只含有4个bank,所以每次最多允许四路数据同时回写。对于访存时可能存在的结构冒险,比如回写数据多于四路,或者多路数据同时写一个bank,需要通过软件调度避免此种情况发生。

图8 地址流水线
4 仿真测试及性能统计
4.1 仿真测试
采用System Verilog语言搭建了包含处理单元、路由器、簇控制器和行列控制器在内的整体仿真平台,使用Modelsim SE 10.1进行仿真测试。
(1)PE的MIMD/SIMD指令测试:选择PE00作为测试目标,测试内容包括基本的MIMD/SIMD指令执行、源操作数读取、目的操作数写入。
从图9波形中可以看出PE00指令指针跳转正常,读取指令正确,能够正确读取源操作数和写入目的操作数,从而能够正常执行MIMD或SIMD指令。

图9 基本指令测试仿真时序图
(2)PAAG中PE间的近邻通信测试:阵列中,设定PE10为本地PE,北边接PE06,西边接PE09,东边接PE11,南边接PE14。测试近邻通信的数据通路结果如图10所示。
图10 近邻通信仿真时序图
从波形中可以看出PE06的vld2south_ch0信号为高有效,PE09的vld2west_ch0信号为高有效,PE11的vld2east_ch0信号为高有效,PE14的vld2north_ch0信号为高有效,这说明与PE10相邻的四个PE分别向PE10成功发送数据。而且PE10执行乘法运算,相乘的结果39和609分别写回至地址20和22。近邻通信功能正确,确保数据流可以在PE间通过数据驱动,计算结果可链接,为分布式并行计算和流处理计算提供良好的数据通道。
(3)PAAG中PE间远程通信测试:阵列中,设定PE00为本地PE,测试调用远程PE10函数执行指令并将数据返回的通路,结果如图11所示。

图11 远程通信仿真时序图
从波形中可以看出本地PE00向远程PE10发送远程函数调用CALLR请求,当PE10执行完后,给PE00返回RETR数据包,内容包含数据来源和运算结果。特殊指令测试证明PE解析特殊指令正确,且能够利用路由器进行远程数据通信。
4.2 性能统计
使用ISE14.4工具,以Virtex7-2000T芯片为目标器件,对处理单元电路进行逻辑综合,综合报告如表1所示,占用了1%的查找表(Look Up Table, LUT)、1%的片寄存器(Slice Registers)、3%存储(Memory)和1%数字信号处理单元(Digital Signal Processor, DSP)。
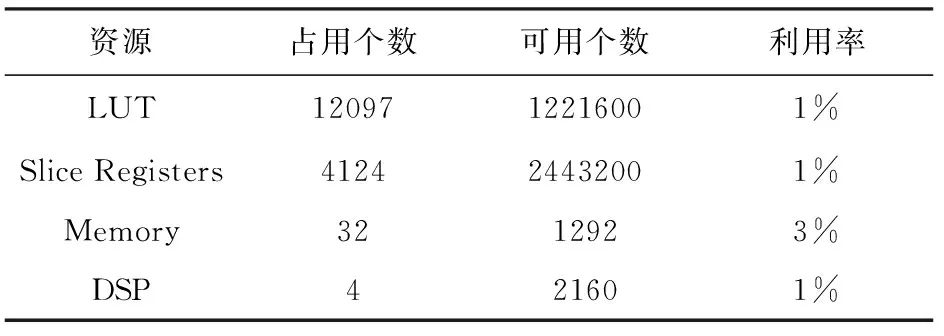
表1 PE资源利用情况
电路运行最大工作频率为167MHz,资源消耗适中。
5 结束语
设计了一种基于PAAG的体系结构的专用处理单元。该处理单元采用四级流水线的双发射指令字结构,降低设计难度;使用片上存储作为指令和数据存储减少多层次存储间数据流动;加入阻塞-非阻塞模式和邻接共享存储实现分布式指令并行和流处理运算;设置特殊指令完成PE间通信和MIMD到SIMD的快速切换;使用线程管理器配置线程运算粒度粗细。通过仿真验证,所设计的处理单元可实现在阵列机上实现分区并行和快速切换。
[1] 李涛,肖灵芝.面向图形和图像处理的轻核阵列机结构[J].西安邮电学院学报,2012,17(3):41-47.
[2] 陈庆奎,王海峰,那丽春,等.图形处理器通用计算的研究综述[J].黑龙江大学自然科学学报,2012,29(5):673.
[3] 韩俊刚,姚静,李涛,等.多态并行机上的3D图形渲染[J].西安邮电大学学报,2015,20(2):1-6.
[4] 黄亮,秦信刚,武玲娟,等.一种面向55nm工艺的可扩展统一架构图形处理器设计与实现[J].计算机工程与科学,2014,36(12):2418-2419.
[5] 李涛,杨婷,易学渊,等.萤火虫2:一种多态并行机的硬件体系结构[J].计算机工程与科学,2014,36(2):191-200.
[6] 蒲琳,李涛,易学渊,等.多态并行处理器中的SIMD控制器设计与实现[J].电子技术应用,2013,39(11):53-59.
[7] 李静梅,王军峰,张岐.一种适应多核处理器核间通信机制的设计[J].智能计算机与应用,2011,1(2):26-27.
[8] 钱博文,李涛,韩俊刚,等.多态并行处理器中的线程管理器设计[J].电子技术应用,2014,40(2):30-32.
[9] 海虎,李涛,韩俊刚,等.多态并行处理器的数据通信和路由器的设计[J].电子技术应用,2014,40(8):38-47.
[10] Hennessy J L, Patterson Da A.计算机系统结构:量化研究方法[M].4版.白跃彬,译.北京:电子工业出版社,2007:109-111.
[11] 刘览.基于FPGA的32位RISC嵌入式微处理器设计[D].南京:南京航空航天大学,2010:12-20.
[责任编辑:祝剑]
Design and implementation of processing element of polymorphous array architecture for graphics and image processing
LI Tao, LIU Yingtian, QIAO Hong
(School of Electronic Engineering, Xi’an University of Posts and Telecommunications, Xi’an 710121, China)
A customized Processing Element(PE) is designed to support a new polymorphic array. It uses the four-stage pipelined VLIW construction and its ISA takes addressing mode without register files. The particular block-nonblock mode and neighbor shared memory are devoted to finish parallel execution of distributed instructions and dataflow computations. The communications among PEs and quick switch between MIMD and SIMD are implemented through special instruction. Experimental results show that PE can realize divisional parallel excuting and shifting of operating modes and the maximum working frequency of PE can achieve 167 MHz.
array architecture, processing element, VLIW, block flag, data communication
2014-12-01
国家自然科学基金重大项目(61136002)
李涛 (1954-),男,博士,教授,从事计算机体系结构,计算机图形学研究。E-mail:litao@xupt.edu.cn 刘应天(1988-),男,硕士研究生,研究方向为专用集成电路设计及集成系统。E-mail:dne_kira@sohu.com
10.13682/j.issn.2095-6533.2015.03.003
TN492
A
2095-6533(2015)03-0021-08
