基于PAAG的图像处理算法并行化设计
2015-06-23黄虎才
李 涛, 乔 虹, 黄虎才
(西安邮电大学 电子工程学院, 陕西 西安 710121)
基于PAAG的图像处理算法并行化设计
李 涛, 乔 虹, 黄虎才
(西安邮电大学 电子工程学院, 陕西 西安 710121)
针对图形处理中的Gamma校正算法和平均滤波算法,在多态并行阵列机上进行并行化设计。该设计利用多线程调度模式将算法中不相关程序分为多个线程相互填充,减少线程的阻塞等待时间,最后将多线程程序映射到阵列机上实现算法的并行化。仿真结果表明,Gamma校正算法在单线程下运行消耗时间是多线程的3.5倍,平均滤波算法在单线程下运行消耗时间是多线程的2.2倍。
多态阵列机;并行计算;图像处理算法
在大规模并行计算领域,以图形处理器(Graphic Processing Unit,GPU)为代表[1-2]的众核处理器的研发逐渐成为主流。作为一种新型的体系结构,众核处理器具有计算单元复杂度低、计算单元功耗低以及计算单元密集、性价比高等鲜明的特点,与多核处理器相比,众核处理器的计算量吞吐量远高于多核处理器[3]。用单个芯片上的成千上万简单处理核的并行计算能力来获得高效能的计算,成为计算机体系结构研究的热点[4]。
处理器中并行计算[5]的常用方法有数据级并行(Data Level Parallelism,DLP)[6]、指令级并行(Instruction Level Parallelism,ILP)[7]和线程级并行(Thread Level Parallelism,TLP)[8]。而迅速发展起来的Gamma校正和平均滤波等图像处理算法具有非常强大的并行处理特征,使得该类算法被广泛应用于处理器的并行计算研究中。
数据级并行[9]和指令级并行[10]都是单线程运行模式,通过使用较多的硬件资源来提高处理效率,存在硬件资源利用率较低的问题。本文针对数据级并行和指令级并行的缺点,提出了一种在PAAG架构上实现Gamma校正算法和平均滤波算法线程级并行的方法。以PAAG多态阵列处理器为硬件平台,进行线程级并行设计,挖掘图像处理领域中的大规模并行计算能力,从时空满载的角度来使计算任务最大并行化,以利用众核上的硬件资源,减少众核处理器上硬件资源的浪费,以此解决目前众多众核处理器中资源利用率不高的问题。并借助仿真分析,将线程级并行的理论数据与实验数据进行对比。
1 PAAG多态阵列处理器结构
PAAG由多个簇构成,每个簇为一个规则的二维阵列,一个基本簇由一个4行4列的阵列,共16个处理单元(Processing Element, PE)以及控制这些处理单元的行控制器(Row Controller)、列控制器(Column Controller)和共享存储组成[11]。PE包含1个算术逻辑运算器、1个路由器、1个PE控制器、4个邻接通信共享存储、1个本地数据存储和1个本地指令存储。PAAG目前的设计可以支持多达1024个PE。PAAG支持单指令多数据流结构和多指令多数据流结构的并行编程方式,并且能够结合数据并行,线程并行和操作并行等多种并行计算模式。
线程级并行是指应用层多个任务甚至多个轻量级任务(线程)之间的互不相关较为明显,可以很自然的实现并行处理。
2 PAAG中线程并行方式的性能分析
在PAAG阵列处理器中,每个PE可以用来进行单个线程的计算,也可以进行多个线程的计算。在单线程执行模式与多线程执行模式下完成同一个算法,执行时间可能有很大不同。每个图像的像素处理指令分为复杂指令(称为长周期指令)和简单指令(称为短周期指令),长指令的周期一般是简单指令的周期若干倍。定义以下符号。
Nshort:程序中短周期指令数。
Nlong:程序中长周期指令数。
Tshort:程序执行短周期指令的时间。
Tlong:程序执行长周期指令的时间。
N:所要处理的像素个数。
SUMs:单线程模式下单个PE对N个像素的处理所需时间。
SUMm:在多线程执行模式下的PE中所消耗的时间。
C:C=Tl/Ts,表示长周期指令与短周期指令执行时间的比例系数。
则短周期指令运行的时间为
Ts=Tshort×Nshort,
(1)
长周期指令执行的时间为
Tl=Tlong×Nlong,
(2)
即有
SUMs=(Ts+Tl)×N。
(3)
根据式(1)和式(2)得到C的值为
(4)
则SUMm可表示为
(5)
(6)
其中常数8表示PAAG中PE的线程数。
3 图像处理算法的线程级并行设计
在PE的单线程执行模式中,对1 024×1 024个像素的图像进行处理,在集成1 024个单线程PE的PAAG中,每个PE处理一行像素点进行运算。假设单线程模式下处理一幅图像所消耗的时间为Time1。
在PE的多个线程执行模式中,让每个PE同时注入满载数量的线程,即在PAAG中为8个线程,与单线程PE执行模式一样,每个PE处理一行像素,将一行像素的处理分配给每个线程,于是每个线程处理128个像素,并且PE中的8个线程所执行的代码完全一致,相互独立。假设多线程模式下处理一幅图像所消耗的时间为Time2。
3.1 Gamma校正
Gamma校正[12]是指在不改变图像大小、几何形状以及局部结构的情况下,对像素值进行的一个映射。每个新的像素值完全依赖于相同位置的旧的像素值,而与其他位置像素值无关,尤其与其相邻的任何像素无关。校正后的像素值p′可表示为
其中p表示原始的像素值,σ表示校正系数,pmax表示所有原始像素值中最大的像素值,pow表示指数操作,round表示取整操作。

LA 0x100,pmax
DIVF 0x101, 0x50, 0x100
POW 0x102, 0x101,σ
MULTF 0x50, 0x102, 0x100
其中存在两个长周期的操作,分别为除法操作DIVF和指数操作POW,这两个操作需要的时钟数为其他操作的几倍。从数据依赖关系角度考虑,在上述程序中,DIVF指令的执行依赖于LA指令的执行结果,即DIV指令的源操作数0x100是LA指令的目的操作数;POW指令的执行依赖于DIV指令的执行结果,即POW指令中的源操作数0x101是DIV指令的目的操作数;MULTF指令的执行依赖于POW指令的执行结果,即MULTF指令的源操作数0x102为POW指令的目的操作数。数据的此种依赖关系导致了在同一线程中,指令中的除法操作和指数操作指令阻塞了后续指令的运行。现假设LA指令和DIVF指令之间所引起的阻塞时间为Tb0,DIVF指令和POW指令之间所引起的阻塞时间为Tb1,POW指令和MULTF指令之间所引起的阻塞时间为Tb2,那么一个像素的Gamma操作将导致Tb时钟的阻塞等待时间,其中Tb为Tb0、Tb1和Tb2之和,如图1的时间轴上半部分所示。
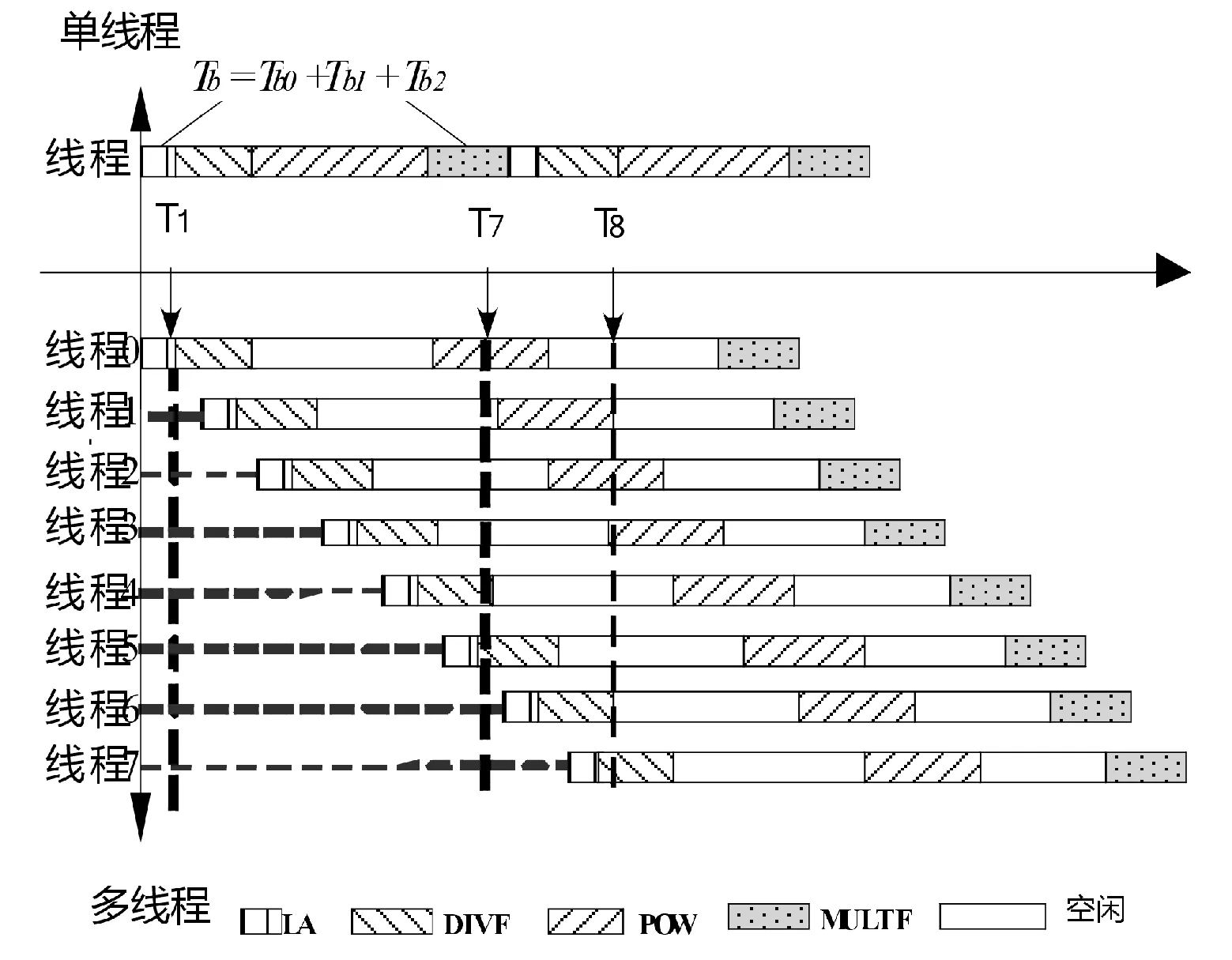
图1 Gamma校正代码单线程(上半部分)与多线程(下半部分)执行时序
在PAAG的多线程PE执行模式中,根据Gamma校正算法中线程独立执行的特性,通过引入新的线程,将新线程中的有效指令来填充阻塞等待时间,减少PE中线程的等待时间。如图1所示,在单线程PE中,T1~T8为阻塞等待时间,而在多线程PE中(图1中时间轴的下半部分),每个线程在发射多周期指令后,立即进行线程的切换。当完成7个线程的相继切换后,此时已经到达T7时刻,而此时线程0已经完成了对第一个像素的除法操作,此时重新调度线程0进入执行,继续完成指数操作POW运算。与浮点除法的调度相类似,线程1~线程7顺序地被重新调度执行。
在图像的Gamma校正运算中,PE通过引入多线程调度执行的方式使其PE在每个时钟均进行有效指令的发射,从而使PE空闲比例减少,达到满载状态,PE中多个线程的执行均为有效执行,这就充分利用了线程并行执行的特性,发挥了阵列机指令级并行计算能力。此时由图1可知,单线程消耗时间Time1接近3.5倍多线程消耗时间Time2。也就是说,利用PE的多线程的合理调度,可以大幅度提高PE的利用率。
3.2 平均滤波器
平均滤波[13]就是把每个像素的新亮度值替换为其相邻元素的亮度的平均值。像素的新亮度值可表示为
其中I(u,v)表示像素的原亮度值,通过叠加像素周围的8个亮度值和本身的亮度值,取平均值即为新亮度值。
如图2所示,假设I(u,v)表示4号像素,对其进行平均滤波计算时,需要提取0~8号像素亮度值进行求和,之后再进行一次除法操作。
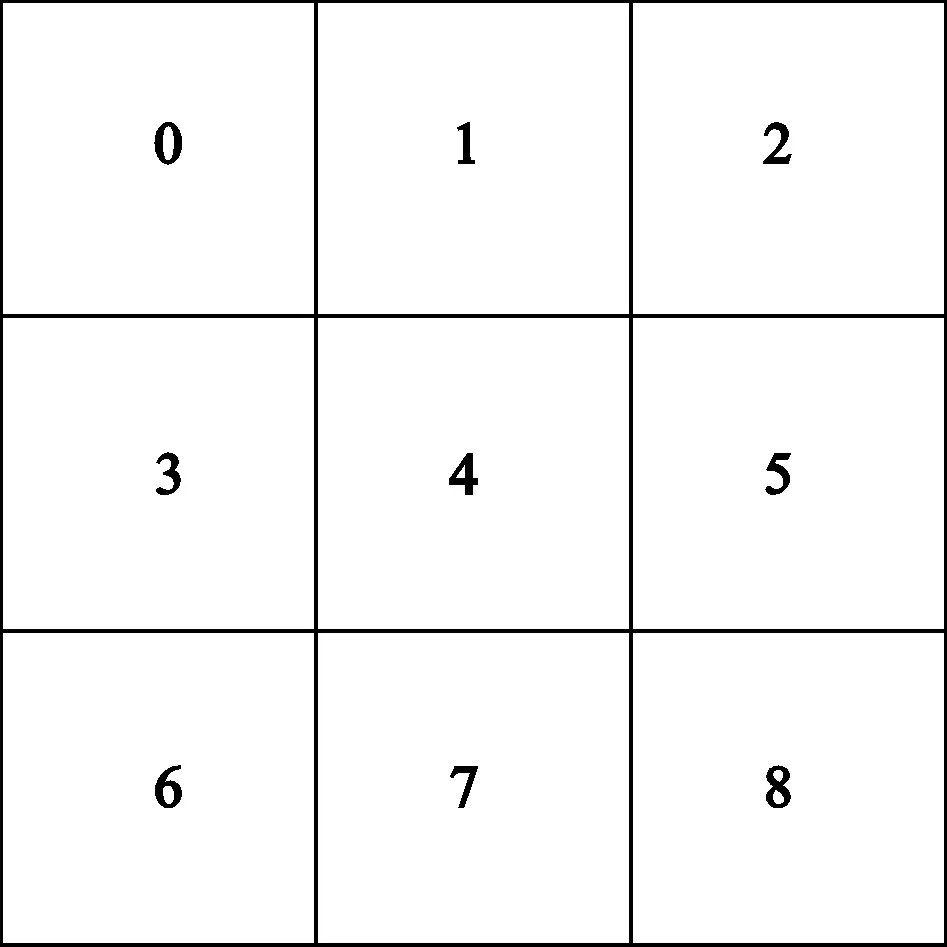
图2 平均滤波图形表示
使用汇编代码实现上述算法,具体代码如下。
ADD sum, pixel0, pixel1
ADD sum1, pixel2, pixel3
ADD sum2, pixel5, pixel6
ADD sum3, pixel7, pixel8
ADD sum, sum, sum1
ADD sum1, sum2, sum3
ADD sum, sum, sum1
ADD sum, sum, pixel4
DIV newpixel, sum, 9
在平均滤波运算过程中,每个新生成像素的值由原始图像数据的像素及其周围8个像素所决定,采用静态数据固定加载映射的方法,平均滤波器所具有的并行性与图像的Gamma校正运算相一致。
由平均滤波算法的代码可知,完成一个像素的平均滤波需要执行一条除法操作,在PAAG中,除法操作DIV为多周期运算指令,为了弥补长延时操作所带来的损失,每个线程在进行除法运算时,每个PE将会进行线程的切换,将其他线程调入执行。如图3所示,线程0在执行完成ADD操作后,直接发射DIV操作,线程0被切换出去,线程1被切换至执行状态,由于PAAG中的除法操作没有进行流水,线程1在执行完成ADD操作后,将线程2切换到执行状态,在线程2执行ADD操作结束后,线程0中的DIV操作执行结束,线程1被调入执行发射DIV操作后,线程3被切换至执行状态,发射ADD操作指令。当线程4中的DIV操作发射时,也就是到达T4时刻,线程0已执行结束。纵观8个线程的执行过程,长延时除法操作最终由于线程的切换调度执行,其阻塞时间被消除。此时,每个PE在数据满载的情况下即可获得最大的指令级并行度。可以看出单线程PE执行模式下所消耗的时间Time1接近等于多线程消耗时间Time2的2.2倍。

图3 平均滤波器程序的单线程(上半部)和多线程(下半部)执行时序
4 实验结果
将Gamma校正算法和平均滤波算法的单线程模式和多线程模式映射在PAAG多态阵列处理器中,统计每种模式的具体执行时间。根据式(1)~式(6),结合PAAG多态阵列处理器特性,分别取短周期操作指令执行时间Tshort= 2,长周期指令Tlong= 23,得到图像处理算法执行的仿真结果如图4和图5所示。
从图4可以看出,Gamma校正程序完成相同个数的像素处理时,单线程PE执行模式下所消耗的时间约等于多线程PE执行模式下所消耗时间的3.5倍;图5可以看出,平均滤波程序完成相同个数的像素处理时,单线程PE所消耗的时间约等于多线程消耗时间的2.2倍。可以得出,多线程处理速度高于单线程处理速度,执行效能优于单线程模式。另外,PE中多个线程的有效执行,使得PE空闲比例减少,达到满载状态,提高了PE的利用率。因此,合理使用PAAG多态阵列处理器的多线程并行,能够提高硬件资源的利用率。

图4 Gamma校正程序的多线程和单线程模式仿真结果

图5 平均滤波算法多线程和单线程模式仿真结果
5 结束语
以图像处理算法中的Gamma校正和平均滤波为例,通过分析推导出PAAG阵列处理器中单个PE在两种不同执行模式下的性能统计计算公式,利用单线程执行模式和多线程执行模式结合算法的指令执行特征进行了详细的分析,实现了Gamma校正和平均滤波算法的线程级并行化计算,并利用实验数据结果验证了理论分析结果。仿真结果表明,利用PAAG基本处理单元PE的多线程执行模式,在PAAG上进行图像处理将能获得性能的提升,并改善了由于阻塞等待所带来的较低硬件资源利用率的情况。
[1] 韩俊刚,刘有耀,张晓.图形处理器的历史现状和发展趋势[J].西安邮电学院学报,2011,16(3):61-64.
[2] Diaz J, Munoz-Caro C, Nino A. A Survery of Parallel Programming Models and Tools in the Multi and Many-Core Era.Parallel and Distributed Systems[J].IEEE Computer Society,2012,23(8):1369-1386.
[3] Borkar S. Thousand core chips: A Technology Perspective[J]. Design Automation Conference, 2007,19(7):746-749.
[4] Marowka, Ramat Gan. Back to Thin-Core Massively Parallel Processors[J]. IEEE Computer Society, 2011,44(12):49-54
[5] 陈国良. 并行计算:结构,算法,编程[M]. 北京:高等教育出版社,2003:23-56.
[6] Hillis D. New computer architectures and their relationship to physics or why CS is no good[J].International Journal of Theoretical Physics,1982, 21(3/4):255-262.
[7] Hennessey J, Patterson D. Computer architecture: A quantitative approach[M].4th Ed. San Francisco: Morgan Kauffmann,2006:33-39.
[8] Quinn MJ. Parallel programming in C with MPI and OpenMP[M]. NY: McGraw-Hill,2004:103-120.
[9] 韩俊刚,姚静,李涛,等.多态并行机上的3D图形渲染[J].西安邮电大学学报,2015,20(2):1-6.
[10] 李涛,孙健.基于PAAG的OpenVX核心库函数并行化实现[J].西安邮电大学学报,2015,20(2):7-10.
[11] 李涛,肖灵芝.面向图形和图像处理的轻核阵列机结构[J]. 西安邮电学院学报, 2012, 17(3): 41-47.
[12] Lindholm E, Nickllls J, Oberman S, et al. NVIDIA Tesla: a unified graphics and computing architecture[J]. IEEE Micro, 2008, 28(2):39-55.
[13] KhronosGroup.OpenVX[EB/OL].(2013-11-19)[2014-11-12]. http://cn.khronos.org/openvx.
[责任编辑:祝剑]
Research of image processing parallelization on PAAG
LI Tao, QIAO Hong, HUANG Hucai
(School of Electronic Engineering, Xi’an University of Posts and Telecommunications, Xi’an 710121, China)
A parallel implementation method is presented in this paper for Gamma correction and average filtering algorithm of image processing on Polymorphic Array Architecture for Graphics and image processing (PAAG). The multi-thread scheduling mode is used to divide irrelevant programs into multiple threads and to fill each other to reduce blocked waiting times of single thread. Thus, the multi-thread program is mapped to array implements parallelization of Gamma correction and average filtering algorithm. Simulation results show that Gamma correction consumes 3.5 times running time under single-thread mode than that under multi-thread mode, and that the average filtering algorithm 2.2 times.
polymorphic array processor, parallel computing, image processing
2014-12-01
国家自然科学基金重大项目(61136002)
李涛(1954-),男,博士,教授,从事计算机体系结构,计算机图形学研究。E-mail:litao@xupt.edu.cn 乔虹(1988-),女,硕士研究生,研究方向为图形图像与视频处理。E-mail:404910814@qq.com
10.13682/j.issn.2095-6533.2015.03.004
TN492
A
2095-6533(2015)03-0029-05
