一种基于可变网格划分的离群点检测算法
2015-06-06马菲朱昌杰郑颖邓杰
马菲,朱昌杰*,郑颖,邓杰
(1.淮北师范大学计算机科学与技术学院,安徽淮北 235000;2.江南大学物联网工程学院,江苏无锡 214122)
一种基于可变网格划分的离群点检测算法
马菲1,朱昌杰*1,郑颖1,邓杰2
(1.淮北师范大学计算机科学与技术学院,安徽淮北 235000;2.江南大学物联网工程学院,江苏无锡 214122)
LOF(Local Outlier Factor)算法是常用的离群点检测算法,但是该算法在面对大规模数据集时往往需要高昂的时空开销,基于固定网格的离群点检测算法虽然在一定程度上可以解决该问题,但是它的执行效果易受到网格划分粒度的影响。对此提出一种基于可变网格划分的离群点检测算法。该算法首先根据数据点在空间的实际分布情况来动态构建与原始数据集分布大体一致的网格空间,然后删除网格中数据点数目超过设定阈值的网格中所有数据点,最后在剩余的数据点集上执行LOF算法。实验结果显示,相对于固定网格的离群点检测算法,所提算法的执行效率明显提高并且检测精确度亦有所提高。
局部离群因子;离群点检测;可变网格;大规模数据集
随着越来越多的数据被收集并存储到数据库中,有效和高效地分析并挖掘包含在这些大规模数据集中的信息具有重要意义[1]。在大规模数据集包含的信息中,由于离群点常常包含潜在有用的信息,对其检测越来越受到人们的重视。离群点一般被定义为数据集中与其他数据对象差异较大的那些数据对象。离群点检测目的是发现数据集中的离群点并根据这些离群点推断潜在的、有价值的知识。随着大数据时代的到来,离群点检测在实际生活中得到了广泛的应用,如在金融领域用来检测信用卡的异常使用、在工业控制系统中对数据的预处理、网络监管系统中网络异常识别、网络健壮性分析、在医疗领域的公共健康分析、图形图像的处理等[2-4]。
LOF(Local Outlier Factor)算法于2000年被Breunig等[5]人提出,它是一个基于密度的算法。LOF算法通过计算数据点的局部离群因子来表征该数据点的偏离程度,使得对离群点的检测不再是二元结果。LOF算法在进行局部离群因子计算时,检测精确度常常受到用户给定参数的影响[6]。同时,在进行大规模数据集中的离群点检测时,该算法往往需要高昂的时空开销。
为了解决这些问题,薛安荣等人[7]提出一种改进的局部离群点检测算法。首先将对象属性分为固有属性和环境属性,然后通过环境属性确定邻域对象、固有属性计算离群因子的方法,有效地避免了参数的输入,但是该算法对邻域的确定仍然需要消耗大量的时间。Zhang Ke等人[8]提出一种新的计算局部离群因子算法,与LOF算法相比,该算法时间效率有所提高并且对参数的敏感度也有所降低。Rajendra Pamula等人[9]提出一种基于聚类的离群点检测算法,该算法首先使用K-means方法进行聚类,然后删除离聚类中心较近的数据点,最后对剩余的数据点计算局部离群因子。由于该算法删除了部分的数据点,算法的执行效率相应地得到提高,但是在聚类时使用K-means方法进行聚类,导致算法对初始聚类中心较为敏感。文献[10]中提出基于网格技术的高维大数据集离群点挖掘算法(Outlier Mining Algorithm based on Grid Techniques,OMAGT),该算法将网格思想引入其中,把空间划分为大小相同的网格单元,从而将对数据集中数据点处理转化为对空间中有限网格单元的处理。通过这种方式能有效地提高算法的执行效率,但是由于该算法使用的是固定网格划分,所以易受网格划分粒度的影响,并且它并没有考虑数据集中数据点的实际分布,这会导致计算结果有一定的偏差。
鉴于此,文中在LOF算法与OMAGT算法基础上,提出一种基于可变网格划分的离群点检测算法(Outlier Detecting Algorithm based on Variab le Grid,ODAVG)。
ODAVG算法首先根据数据集在空间的实际分布情况,将每一维非等宽地划分成数段,进而在空间中形成大小不一的网格单元;然后统计每个网格单元中数据点的数目,删除网格中数据点数目大于设定阈值网格中的所有数据点;最后对剩余的数据点利用LOF算法进行离群点检测。在多个数据集的实验结果表明,相对于OMAGT算法,ODAVG算法执行效率明显提高并且准确率也有所提高。
1 LOF算法
1.1 LOF算法的基本概念
在离群点检测领域,LOF算法常常被用来计算数据点的离群程度,它不再简单地判别数据点是不是离群点,而是给出数据点的离群程度,实际上反应了该数据点是否偏离相对集中的区域。下面介绍LOF算法的一些基本概念。
定义1(对象p的k距离)
在数据集D中,对于任何一个正整数k,以k-distance(p)来表示对象p的k距离,以d(p,0)表示对象p到对象o(o∈D)的距离。满足下面两个条件,则k-distance(p)=d(p,o):
(1)至少有k个对象o'∈D{p},它到p的距离d(p,o')≤d(p,o);
(2)至多有k-1个对象o'∈D{p},它到p的距离d(p,o')<d(p,o)。
定义2(对象p的k-distance邻域)
已知对象p的k-distance(p),p的k距离邻域是指D中的对象q到p的距离不大于k-distance(p)的所有对象的集合,记为

定义3(对象p到对象o的可达距离)
设k是一个自然数,对象p到对象o的可达距离定义为
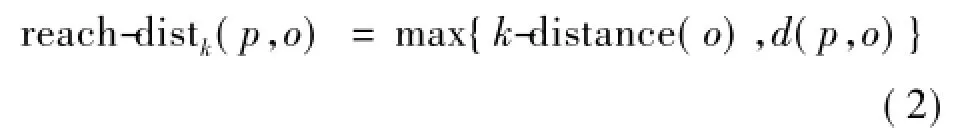
从可达距离定义可以看出,如果p远离o,则它们的可达距离等于两者之间的实际距离;如果p‘足够地’地接近o,则它们的可达距离等于o的k-distance(o)。
定义4(对象p的局部可达密度)
对象p的局部可达密度定义为

可以看出,p的局部可达密度是p的MinPts个最近邻居的平均可达距离的倒数。
定义5(对象p的局部离群因子)对象p的局部离群因子定义为

已知,p的局部离群因子显示p的离群程度。它等于p的MinPts个最近邻居的局部可达密度的平均值与p的局部可达密度之比。根据公式可以很清楚地看到,p的局部可达密度越小且MinPts个最近邻居的局部可达密度越大,则离群因子越大,也就是说p越偏离MinPts个邻居。
1.2 LOF算法的执行步骤
输入:数据集D,离群点数目n;输出:前n个局部离群因子值较大的数据对象。1)对于数据对象p,根据公式(1)~(4)来计算该数据对象的局部离群因子;
2)循环遍历数据集D的每一个对象,重复第一步,并将该结果依次存放到集合Col_LOF中;
3)对Col_LOF中的值用快速排序算法排序,并输出前n个局部离群因子值较大的数据对象。
2 基于可变网格划分的离群点检测
2.1 固定网格划分
固定网格划分是基于网格划分的离群点检测中常用的一种方法,常与基于密度的离群点检测算法结合,可以提高算法的执行效率[11]。固定网格划分,简单地说,就是将目标数据集每一维进行等间距划分,而后在空间中形成大小相同的网格单元。设D是一个d维的数据集,其属性(A1,A2,…,Ad)的取值在一个封闭的区间里。令第i维的取值范围是[li,hi],其中i={1,2,…,d},则
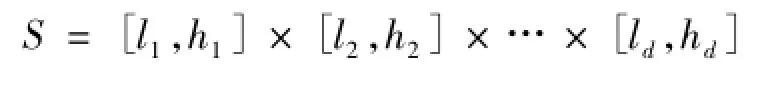
是一个d维的数据空间。取数据集的每一维,将该维等间距地划分为k段,则d维空间被划分为kd个网格。第i维的第j个区间段的长度θi=(hi-li)/k,并且该区间段的取值范围是Iij=(li+(j-1)×θi,li+j×θi),其中j={1,2,…,k}。
2.2 一种新的可变网格划分策略
固定网格划分较易理解并且方便实现,但是如果在高维数据集中使用固定网格划分的方法,随着维度的增加,网格的数量以指数级在增长,导致算法的复杂度大大增加,其可用性也因此而降低[12-13]。近年来,不少研究人员展开了关于可变网格划分技术的研究,如文献[14]提出的可变网格划分方法,该方法首先对每一维进行等深度地划分,然后合并相似度较大的相邻网格。文献[15]进行可变网格划分时引入了属性维半径向量这一概念。QIAN Xuezhong等人[16]提出根据数据集的实际分布动态构建网格空间的策略等。
文中介绍一种新的可变网格划分方法。对于数据集的每一维,首先对其等间距划分;其次统计该维每个区间中数据点数目并计算相邻区间段的相似性;最后比较相邻区间的相似性,对于相似度较高的区间段进行合并。在最后形成的网格空间中,由于每一维数据分布不尽相同,从而进行合并的区间段也不尽相同,所以最后在数据空间中就构成了大小不同的网格。
可变网格划分的执行步骤如下所述:
1)对于第i维,采用固定网格划分方法对其进行划分。
2)统计该维每个区间段的数据点数目并计算相邻段的相似性。由于每个区间段的长度是一样的,所以采用区间段中数据点的数目Countij来表示其密度,并引入参数来量化相邻区间段的相似性,其计算方式如下:

3)对于第i维,依次比较相邻段的相似性是否大于阈值T(0≤T≤1),其中T用于表示两个区间段的相似性。如果大于T,则记录相应的段,否则不做任何操作。比较结束后,对记录的段进行合并。在实际操作中,如果T值接近1,则表示进行合并的段较少,最终剩余网格的数目较多,算法的执行效率相对较低,但可以保证离群点检测的精确度;如果T值接近0,表示进行合并的段较多,则最终剩余的网格数目较少,虽然可以提高算法的执行效率,但是会影响离群点检测的精确度。
4)对每一维均执行1)到3)。
2.3 基于可变网格划分的离群点检测算法
通过2.2节提出的可变网格划分策略,可以对给定的数据集动态地进行网格划分。划分后的网格可以尽可能地将相似度大的数据点划分到同一个网格,相似度小的数据点划分到不同的网格。文中将上述网格划分方法与LOF算法相结合,提出基于可变网格划分的离群点检测算法。在此引入密度阈值Min P,表示网格中数据点数目。当网格中数据点数目大于Min P时,则认为该网格中数据点是密集的,否则认为是稀疏的。该算法的具体步骤如下:
输入:数据集D,离群点数目n,密度阈值Min P;
输出:前n个LOF值较大的数据点。
1)扫描数据集D,采用2.2节所述可变网格划分方法对空间进行划分,将划分后的网格总数记为|grid_counts|。
2)统计网格中数据点的数目Nm,m={1,2,…,|grid_counts|},并比较Nm是否大于密度阈值M in P,如果大于,则删除这个网格中的所有数据点,否则不做任何操作。
3)对于剩余的数据点执行LOF算法,并输出前n个LOF值较大的数据点。
3 实验与分析
为了测试ODAVG算法的有效可行性,在实验环境为Matlab R2014a、操作系统W in7(CPU 3.4 Hz,内存:4.00 GB)的平台上分别从网格划分效果、执行时间和检测精确度3个方面对ODAVG算法、OMAGT算法和LOF算法进行对比分析。
3.1 实验数据集信息
选择5组数据集对提出算法的有效性进行实验,其中2组人工数据集Dataset1和Dataset2,3组 UCI标准数据集Shuttle、Breast和KDD Cup。对于人工数据集,采用Matlab R2014a提供的函数mvnrnd(MU,COV,M)进行生成,其中MU为均值,COV为均值对应的协方差,M表示生成数据的规模。Dataset1数据集有3种类型的离群点,共100条。Dataset2数据集有4种类型的离群点,共1 000条。Shuttle数据集共有7个类簇,其中第2类、第6类和第7类相对较少,共54条数据,视此3类为离群点。对Breast数据集中进行处理:把Malignant类减少到83条并视其为离群点。KDD Cup数据集是网络入侵检测数据集。5组数据集的基本信息如表1所示。

表1 各个数据集的基本信息Tab.1 Basic in formation of each dataset
3.2 网格划分效果对比
在进行网格划分效果对比时,采用Dataset1和Dataset2为测试集,对比OMAGT和ODAVG 2种算法进行网格划分以及删除密集数据点后的效果图并进行分析。为了算法的客观性,ODAVG算法进行网格划分时,每一维的初始区间段个数与OMAGT算法进行网格划分时保持一致。网格划分的效果如图1所示。

图1 2种算法所画网格效果Fig.1 Grid d ivision result using the tw o algorithm s
从图1(a)~(d)可以看出:(1)ODAVG算法进行网格划分后的网格数目要明显小于OMAGT算法进行网格划分的数目,这样可以在后续的处理中提高算法的执行效率;(2)ODAVG算法划分的网格空间也更加合理,画出的网格单元更符合数据点的实际分布,这是由于在进行网格划分时,对相似度较高的相邻段执行了合并操作。
删除密集区域后对应的效果如图2(a)~(d)所示,其中图1(a)与图1(b)是二维数据对比结果,图1(c)与图1(d)是三维数据对比结果。

图2 两种算法删除密集区域后Fig.2 Delete dense regions using the tw o algorithm s
当密度阈值Min P一定时,从图2(a)~(d)可以看出,ODAVG算法删除密集区域后剩余的数据点的数目要小于OMAGT算法剩余的数据点数目,这样减少了参与LOF算法的数据点数目,提高了ODAVG算法的执行效率。
3.3 执行时间对比分析
首先,以Dataset1作为测试集,从Dataset1中抽取数据量不同的数据集对ODAVG算法、OMAGT算法和LOF算法进行执行时间对比。为了使以上3种算法更具有客观性,分别执行上述3种算法5遍,选取平均执行时间,并且在网格划分时,ODAVG算法的每一维初始区间段个数与OMAGT算法进行网格划分时保持一致。表2表示的是在Min P=400的情况下,选择不同数据量在ODAVG算法、OMAGT算法和LOF算法的运行时间。
从表2可以看出,ODAVG算法和OMAGT算法的执行时间明显要低于LOF算法的执行时间,这是因为ODAVG算法和OMAGT算法删除了大部分参与局部离群因子计算的数据点。由于ODAVG算法是根据数据集的分布将空间划分大小不同的网格,它并不需要搜寻聚类区域,而OMAGT算法将空间进行网格划分后,需要搜寻聚类区域,同时与OMAGT算法相比,ODAVG算法删除较多的数据点,所以ODAVG算法的执行时间低于OMAGT算法的执行时间。

表2 不同数据量的执行时间Tab.2 Execution tim e of the differen t data size
其次,将Dataset2作为测试集,测试在数据量保持不变的情况下,通过改变密度阈值Min P的大小,来对比ODAVG算法、OMAGT算法和LOF算法的执行时间,其中密度阈值的选取分别为300,500,700,900,1 100。为了执行结果的客观性,每个算法同样运行5遍,然后取平均值,并且在网格划分时,ODAVG算法的每一维的初始区间段个数与OMAGT算法进行网格划分时保持一致。由于LOF算法没有密度阈值,所以该算法选取执行5遍的时间平均值。表3表示不同密度阈值下3种算法的执行时间。

表3 不同密度阈值下的运行时间Tab.3 Execution time of the different density threshold
从表3可以看出,LOF算法的执行时间明显高于ODAVG算法和OMAGT算法。当选取不同的密度阈值时,ODAVG算法随着密度阈值增加,它的执行时间也不断增加,这是因为当选取的密度阈值增大时,执行删除操作后剩余的数据点相对较多,因此执行过程消耗的时间相对较多。随着密度阈值的增大,虽然ODAVG算法的执行时间也在增加,但是增加的幅度并没有OMAGT算法增加的幅度大。
为了进一步体现实验结果的真实可靠性,在UCI数据集上进行了实验。表4给出3个算法在Breast、Shuttle和KDD Cup 3个数据集上的执行时间。从表中可以看出,当数据量较小时,所提算法在时间上的优势并不明显(以Breast数据集为例),但是当数据量增大时,所提算法的优势明显体现出来并且随着数据量的增大,这种优势越明显。为了保证算法执行结果的客观性,在实验过程中,对于Breast数据集,ODAVG算法和OMAGT算法的密度阈值Min P均设置为10;对于Shuttle数据集,ODAVG算法和OMAGT算法的密度阈值Min P均设置为120;对于KDD Cup数据集,ODAVG算法和OMAGT算法的密度阈值Min P均设置为200。对于区间段相似性阈值T,均设置为0.5。

表4 3种数据集的运行时间Tab.4 Execution time of the three datasets
3.4 检测精确度对比
为了测试ODAVG算法的精确度,分别采用Dataset2、Shuttle和Breast3个数据集作为测试数据集,对ODAVG算法、OMAGT算法和LOF算法进行精确度测试。为了使结果较客观,对每一个算法分别运行5遍,然后取平均值。在网格划分时,ODAVG算法的每一维初始的区间段个数与OMAGT算法保持一致。检测的精确度采用以下公式进行度量:

实验结果如表5所示。通过表4可以看出:对于离群点较少的Shuttle数据集和Breast数据集,LOF算法的检测精确度要高于ODAVG算法和OMAGT算法,且ODAVG算法的检测精确度要高于OMAGT算法。对于Dataset2,由于离群点较多并且以较小类簇的形式出现,导致LOF算法的精确度相对较低,但是由于ODAVG算法和OMAGT算法删除了大部分参与LOF算法运算的数据点,使得ODAVG算法和OMAGT算法的检测精确度相对略高。在实验过程中,对于DataSet2数据集,ODAVG算法和OMAGT算法的密度阈值M in P均设置为300;对于Shuttle数据集,ODAVG算法和OMAGT算法的密度阈值Min P均设置为120;对于Breast数据集,ODAVG算法和OMAGT算法的密度阈值Min P均设置为10。对于区间段相似性阈值T,均设置为0.5。
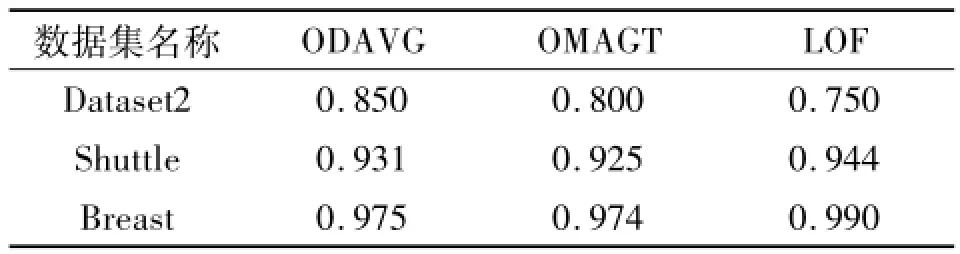
表5 3种算法的精确度Tab.5 Accuracy of the three algorithm s
综上所述,从网格划分效果来看,相对于OMAGT算法,ODAVG算法可以根据数据集的实际分布以更少的网格数目构建出与原始数据集分布一致的网格空间;从执行时间上来看,相对于OMAGT算法和LOF算法,ODAVG算法由于使用了可变网格的策略来处理大规模数据集,因此它能够获得较该两种算法更高的执行效率,并且随着数据量的增加,这种优势会更加明显;从检测精确度来看,ODAVG算法能够保持与OMAGT算法和LOF算法较一致的精确度。因此,文中所提出的ODAVG算法能够在保证较高检测精确度的同时,可以获得更高的执行效率。
4 结语
离群点检测是数据挖掘领域中一个重要的研究方向,并且在实际生活中有着广泛的应用。文中提出了一种新的基于可变网格划分的离群点检测算法。该算法首先根据数据集的分布将空间划分为大小不一的网格,然后删除不可能成为离群点的数据点,最后对剩余的数据点执行LOF算法。相对于固定网格划分的离群点检测算法与LOF算法,该算法可以在保证正确率同时提高执行效率。但是,文中研究工作仍需要继续进行,如在高维大规模数据集的执行效率是否可以进一步减少等。
[1]DUAN L,XU L,GUO F,et al.A local-density based spatial clustering algorithm with noise[J].Information Systems,2007,32 (7):978-986.
[2]YUAN Y,ZHANG Y,CAO H,et al.New local density definition based on m inimum hyper sphere for outlier mining algorithm using in industrial databases[C]//Control and Decision Conference(2014 CCDC),The 26th Chinese.Changsha:IEEE,2014: 5182-5186.
[3]Aggarwal C C,YU PS.Outlier detection for high dimensional data[J].ACM Sigmod Record,2001,30(2):37-46.
[4]古平,刘海波,罗志恒.一种基于多重聚类的离群点检测算法[J].计算机应用研究,2013,30(3):751-753.
GU Ping,LIU Haibo,LUO Zhiheng.Multi-clustering based outlier detect algorithm[J].Application Research of Computers,2013,30(3):751-753.(in Chinese)
[5]Breunig M M,Kriegel H P,Ng R T,et al.LOF:identifying density-based local outliers[J].ACM Sigmod Record,2000,29(2): 93-104.
[6]王敬华,赵新想,张国燕,等.NLOF:一种新的基于密度的局部离群点检测算法[J].计算机科学,2013,40(8):181-185.
WANG Jinghua,ZHAO Xinxiang,ZHANG Guoyan,et al.NLOF:a new density-based local outlier detecting algorithm[J].Computer Science,2013,40(8):181-185.(in Chinese)
[7]薛安荣,鞠时光,何伟华,等.局部离群点挖掘算法研究[J].计算机学报,2007,30(8):1455-1463.
XUE Anrong,JU Shiguang,HEWeihua,et al.Study on algorithms for local outlicr detection[J].Chinese Journal of Computer,2007,30(8):1455-1463.(in Chinese)
[8]ZHANG K,Hutter M,JIN H.A new local distance-based outlier detection approach for scattered real-world data[C]//Advances in Knowledge Discovery and Data Mining.Berlin,Heidelberg:Springer,2009:813-822.
[9]Pamula R,Deka J K,Nandi S.An outlier detection method based on clustering[C]//Emerging Applications of Information Technology(EAIT),2011 Second International Conference on.Washington,DC:IEEE,2011:253-256.
[10]曹洪其,孙志挥.基于网格技术的高维大数据集离群点挖掘算法[J].计算机应用,2007,27(10):2369-2371.
CAO Hongqi,SUN Zhihui.Algorithm of outliers mining based on grid techniques in high dimension large dataset[J].Computer Applications,2007,27(10):2369-2371.(in Chinese)
[11]张天佑.基于网格划分的高维大数据集离群点检测算法研究[D].长沙:中南大学,2011.
[12]Hsu CM,CHEN M S.Subspace clustering of high dimensional spatial data with noises[C]//Advances in Knowledge Discovery and Data Mining.Berlin,Heidelberg:Springer,2004:31-40.
[13]贺玲,蔡益朝,杨征.高维数据的相似性度量研究[J].计算机科学,2010,37(5):155-156.
HE Ling,CAIYichao,YANG Zheng.Researches on similarity measurement of high dimensional data[J].Computer Science,2010,37(5):155-156.(in Chinese)
[14]盛开元,钱雪忠,吴秦.基于可变网格划分的密度偏差抽样算法[J].计算机应用,2013,33(9):2419-2422.
SHENG Kaiyuan,QIAN Xuezhong,WU Qin.Density biased sampling algorithm based on variable grid division[J].Journal of Computer Application,2013,33(9):2419-2422.(in Chinese)
[15]王敬华,金鹏.基于粗约简和网格的离群点检测[J].计算机工程与应用,2015,51(3):133-137.
WANG Jinghua,JIN Peng.Outliers detecting based on rough reduction and grid[J].Computer Engineering and App lications,2015,51(3):133-137.(in Chinese)
[16]QIAN Xuezhong,SHENG Kaiyuan,QIAN Heng,et.al.An improved density biased sampling for clustering large-scale datasets[J].Journal of Information and Computational Science,2014,11(7):2355-2364.
(责任编辑:杨勇)
An Ou tlier Detecting A lgorithm Based on the Variable G rid Division
MA Fei1,ZHU Changjie*1,ZHENG Ying1,DENG Jie2
(1.School of Computer Science and Technology,Huaibei Normal University,Huaibei 235000,China;2.School of Internet of Things Engineering,Jiangnan University,Wuxi214122,China)
As a widely used outlier detecting algorithm,the LOF algorithm usually spendsmuch time and space on the dealing with the large-scale dataset.The outlier detecting algorithm based on the stationary grid can solve the problems to some extent,but its implementation effect can be influenced by the granularity of grid division.Aiming at the problem,this paper proposes an outlier detecting algorithm based on the variable grid division.The proposed algorithm can dynam ically construct the grid space according to the practical distribution of data points in space,then remove all of the data points in the grid when it contains the count of data pointsmore than the threshold,finally execute the LOF algorithm in the remainder data points.The experimental results show that the proposed algorithm can receive a higher efficiency and accuracy compared with the outlier detecting algorithm based on stationary grid.
local outlier factor,outlier detection,variable grid,large-scale dataset
TP 301.6
A
1671-7147(2015)06-0751-07
2015-06-21;
2015-09-24。
安徽省高校自然科学研究项目(KJ2014B24)。
马菲(1989—),女,河南商丘人,软件工程专业硕士研究生。
*通信作者:朱昌杰(1963—),男,安徽怀宁人,教授,硕士生导师。主要从事人工智能与数据挖掘等研究。Email:840486167@qq.com
