基于OpenStack Sahara集群的高可用性的设计与实现
2015-06-01朱志祥梁小江蔡晓龙
唐 攀,朱志祥,梁小江,蔡晓龙
(1.西安邮电大学计算机学院,西安 710061;2.西安未来国际信息股份有限公司,西安 710065;3.洛阳师范学院软件职业技术学院,河南 洛阳 471023)
基于OpenStack Sahara集群的高可用性的设计与实现
唐 攀1,朱志祥1,梁小江2,蔡晓龙3
(1.西安邮电大学计算机学院,西安 710061;2.西安未来国际信息股份有限公司,西安 710065;3.洛阳师范学院软件职业技术学院,河南 洛阳 471023)
针对目前大数据处理环境成本高,存在点单故障等问题,使用OpenStack Sahara可以将云计算与大数据结合起来.设计出一种基于OpenStack Sahara集群的高可用性方案,验证结果显示,该方案解决了单点故障问题,实现了自动故障切换,保证了集群的高可用性,从而提高了Sahara集群的性能.
单点故障;OpenStack;Sahara;高可用性;故障切换
随着云计算和大数据的发展,带动了数据分析的发展,将大数据放在云平台上,用云计算来进行大数据分析处理,其中以Hadoop应用为代表的大数据分析,是最适合在云平台上运行的业务之一.Open-Stack作为当今的主流云平台之一,OpenStack和Hadoop的结合即OpenStack Sahara作为开源云计算与大数据结合的方案之一,可以快速提供了一个Hadoop集群环境,并且使用户对集群的管理和扩展变得十分方便,但是OpenStack Sahara集群中的NameNode(NN)存在单点故障(Single PointOf Failure,SPOF)问题,对于只有一个NN的集群,如果NN出现故障、宕机或者软硬件升级,会造成整个集群的服务不可用,严重影响集群的整体性能,因此解决单点故障是提高Sahara集群性能的关键[1-3].
本文提出了一种OpenStack Sahara集群的高可用方案的设计与实现,解决了Sahara集群NN的SPOC问题,若当前Active NN故障、宕机或者软硬件升级维护,Sahara集群自动切换到Standby NN,提高了Sahara集群的可用性,从而提高整个Sahara集群的性能.
1 相关概念
1.1 Openstack Sahara
OpenStack Sahara架构如图1所示.

图1 OpenStack Sahara架构
Horizon:提供GUI图形化界面的方式使用OpenStack Sahara.
Keystone:认证用户并提供安全令牌,用以与OpenStack通信和分配特定的OpenStack权限.
Nova:为Hadoop集群提供虚拟机.
Glance:Glance负责镜像管理服务.用于储存Hadoop虚拟机镜像,每个镜像都包含了已安装的OS和Hadoop.
Swift:Swift可以作为Sahara的输入/输出数据存储,或者数据处理程序包存储.
1.2 高可用性
在可靠性理论中,一般采用RAS(Reliability, Availability,Servieeability)来定义系统的健壮性和完整性.RAS代表可靠性、可用性、可维护性.系统运行状态,如图2所示.
高可用性:即HA(High Availability)是指系统对外正常提供服务时间占服务启动到当前为止时间的百分比.具体来说,HDFS的可靠性可用平均故障间隔(MTTF)来度量,即HDFS正常服务的平均运行时间;HDFS的可维护性用平均系统恢复时间(MTTR)来度量,即HDFS从不能正常服务到重新正常服务的平均恢复时间.因此HDFS的HA定义为:
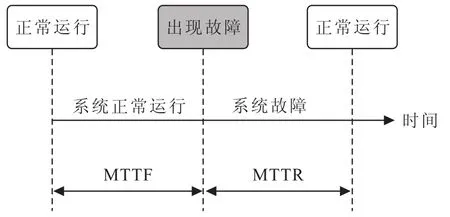
图2 系统运行状态图
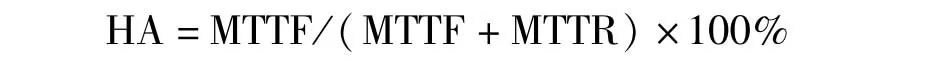
由上面的定义可知,高可靠性更多地是对于系统自身而言,它是系统可靠程度的一个指标.而高可用性则更多地是从系统对外的角度来说的,除了包含系统正常工作的能力,它还强调系统中止服务后迅速恢复的能力;一个可靠性很高的系统,如果其中止服务后,恢复时间很长,那么它的可用性也不会很高,而一个可靠性不是特别高的系统,如果发生中止服务后,可迅速恢复,那么其可用性也可能很高.因此只有高可用性才能准确度量系统对外正常服务的能力[4].
2 高可用性架构设计与实现
2.1 高可用架构的设计
OpenStack Sahara集群的高可用设计方案[5],如图3所示.
本HA方案,将NN配置在两台独立的机器上.在任何时间,其中一个NN处于Active状态,而另一个处于Stanby状态.Active NN负责集群中所有的客户端的操作,而Standby NN主要用于备用,它主要维持足够多的状态,保证在必要的时候提供一个快速的故障转移.
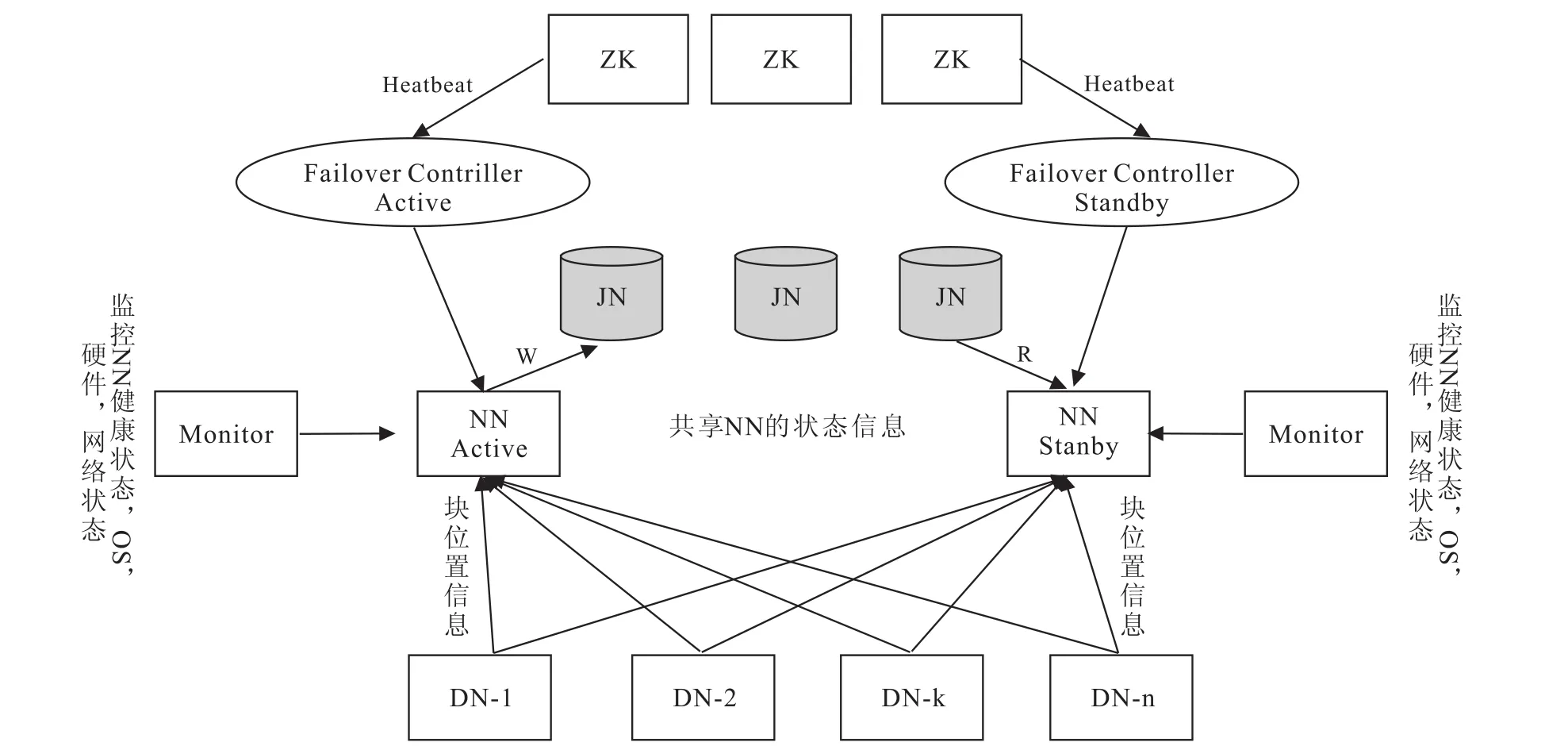
图3 OpenStack Sahara集群的高可用设计方案
为了保证Active NN和Stanby NN节点状态同步,即元数据一致性.DataNode(DN)需要向两个NN发送block位置信息,还构建了一组独立的守护进程“JournalNodes”(JNs),用来记录Edits信息.当Active NN修改任何的命名空间,都会通过这些JNs记录日志(editLog);Standby NN可以监控Edits日志的变化,并且通过JNs读取Active NN发送过来的edits信息和更新其内部命名空间.当故障转移时,Standby NN需要保证从JNs中读取到所有的Edits,然后切换成Active状态.这是为了保证NameSpace的状态和迁移之前是完全同步的[6].
为了提供一个快速的故障转移,Standby NN要求保存着最新的block的位置信息.DN都被配置了所有的NN的地址,并且发送block的位置信息和心跳给两个NN.
在任何时候,集群都要保证只有一个活跃的NN,否则在两个Active NN的命名空间下的状态会出现分歧,导致数据丢失或者其他一些不可预见的错误.为了确保这个,防止所谓split-brain现象,在任何时候,JNs将只允许一个NN向其写Edits信息.故障转移期间,Standby NN成为活跃状态的时候会接管JNs的写权限,这会有效防止原来的NN持续处于活跃状态,允许新的Active NN安全地进行故障转移.
该方案的具体设计:
1)集群中至少启动3个JN(2N+1);
2)集群中每个NN上同时运行一个QuorumJournalManager(QJM)组件;通过Hadoop IPC(Inter Process Call)向JN写入editLog;
3)当QJM写editLog前,首先要保证没有其他QJM在写editLog,从而保证当发生脑裂时,editLog的写入依然是安全的;这一点的实现是通过QJM成为写者时(其NN成为Active节点时)分配惟一的epoch号,并广播给所有JN,JN在执行写editLog操作前对请求者QJM的epoch号进行检查;epoch号的申请也是经过JN和QJM的仲裁同意的;
4)当QJM写editLog前,同样需要保证之前editLog在所有JN上一致;例如如果一个QJM写过程中发生失败,则几个JN的editLog的尾部很可能不同,新的QJM成为写者时,需要对这些不一致的editLog进行同步,仲裁后保证一致;
5)当QJM写editLog时,只要JN中的大部分成功(若JN=2N+1则JN>=N+1写成功),就算成功,可以继续执行后续操作;
6)Zookeeper FailoverController可以实现对Active/Standby NN的状态监控和主从选举;
7)自动故障转移
自动故障转移,增加了两个新组件到HDFS部署中:一个ZooKeeper仲裁和ZKFailoverController进程(ZKFC),来实现Active NN的选举和实现故障的自动转移.

图4 Sahara集群创建流程
2.2 本设计方案的实现
2.2.1 Sahara集群创建流程
Sahara集群创建流程如图4所示.
首先用户登录OpenStack云平台,创建自己的网络和路由,其次上传预装Hadoop的虚拟机镜像到OpenStack,用户通过OpenStack dashboard界面上的Sahara来注册镜像,创建节点组模板,创建集群模板,创建Sahara集群.
2.2.2 HA配置
HA配置是向后兼容的,允许一个现有的单NN的集群配置不改变就可以工作,HA集群重用NameService的ID来标识一个HDFS集群,每一个NN都有一个不同的NN ID来区分彼此.为了支持所有NN使用相同配置文件,相关配置需要增加NameService ID和NN ID前缀.
配置HA NN必须增加一些配置项到hdfssite.xml配置文件中,这些配置项的顺序不重要,但是dfs.nameservices和dfs.ha.namenodes.[nameservice ID]选项将决定下面的配置的key的名称,因此你应该先决定这两个配置的值,再配其他的配置[7].
1)dfs.nameservices:命名空间的逻辑名称.
2)dfs.ha.namenodes.[nameservice ID]:命名空间中每个NN的惟一的标识符.可配置多个,使用逗号分隔.当前,每个集群最多只能配置两个NN.
3)dfs.namenode.rpc-address.[nameservice ID].[name node ID]:每个NN监听的RPC地址.
4)dfs.namenode.http-address.[nameservice ID].[name node ID]:每个NN的监听的http地址.
5)dfs.namenode.shared.edits.dir:标识两个NN将分别读/写edit log的一组JNs的URL.URL格式:qjournal://host1:port1;host2:port2;host3:port3/journalId.这里host1、host2、host3指的是JN的地址,必须是奇数个,至少3个;其中journalId是集群的唯一标识符.
6)dfs.client.failover.proxy.provider.[nameservice ID]:HDFS客户端用来连接Active NN的Java类. HDFS客户端决定哪一个NN当前是Active的Java类,从而决定哪个NN服务于客户端请求.目前只有一个实现configuredFailoverProxyProvider.
7)dfs.ha.fencing.methods:脚本或Java类的列表,它们将在一次故障转移期来保护Active NN.在任意时刻必须保证只有一个NN处在Active状态.
故障转移使用的fencingmethods方式:shell和sshfence.
(1)sshfence:SSH到Active NN然后杀掉该进程.
sshfence选择SSH到目标节点,然后用fuser命令杀掉在服务TCP端口上的进程.为了使fencing option工作,它必须能够免密码SSH到目标节点.因此,必须配置dfs.ha.fencing.ssh.private-key-files选项.
(2)shell:运行任意的shell命令来fence Active NN
若shell命令结束返回0,fence成功;若返回任何其他的结束码,fence失败
8)在core-site.xml中配置fs.defaultFS
fsdefaultFS:Hadoop文件系统客户端使用的默认的路径前缀.
可选地,为Hadoop客户端配置了默认使用的路径来启用新的HA的逻辑URI.若用“mycluster”作为nameservice ID,这个ID将是所有你的HDFS路径的authority部分.
9)dfs.journalnode.edits.dir:JN守护进程在对NN的目录进行共享时,存储数据的路径,此路径中存储了edit和JNs使用的其它的本地状态.
2.2.3 自动故障转移配置

这列出了多个正在进行Zookeeper服务的主机名-端口号信息,用每个nameservice的id做前缀来作为配置时的key.例如,在开启HA集群中,你可能需要明确的指定所要开启自动故障转移的nameservice用dfs.ha.automatic-failover.enabled.my-nameservice-id指定.
3 Sahara集群高可用性的验证
3.1 启动集群

因为自动故障转移在配置中已经被开启了,start-dfs.sh脚本将会在任意运行NN的机器上自动启动一个ZKFC守护进程.当ZKFC启动,它们将自动选择一个NN变成Active[8-10].
3.2 高可用性验证
首先定位Active NN.可以访问NN的Web接口分辨出nambnode1为Active,namenode2为Standby,故障转移前NN状态图如图5所示.本实验在Active NN上造成一个故障,采用kill-9<pid of NN>杀掉NN进程和关闭NN节点,触发故障转移,另一NN节点均能在几秒后从Standby状态变为Active状态,说明实现了自动故障转移,从而实现了集群的高可用性.故障转移后NN状态图如图6所示.
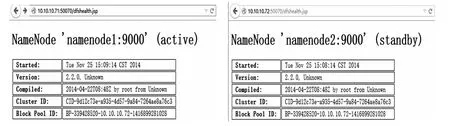
图5 故障转移前NN状态图
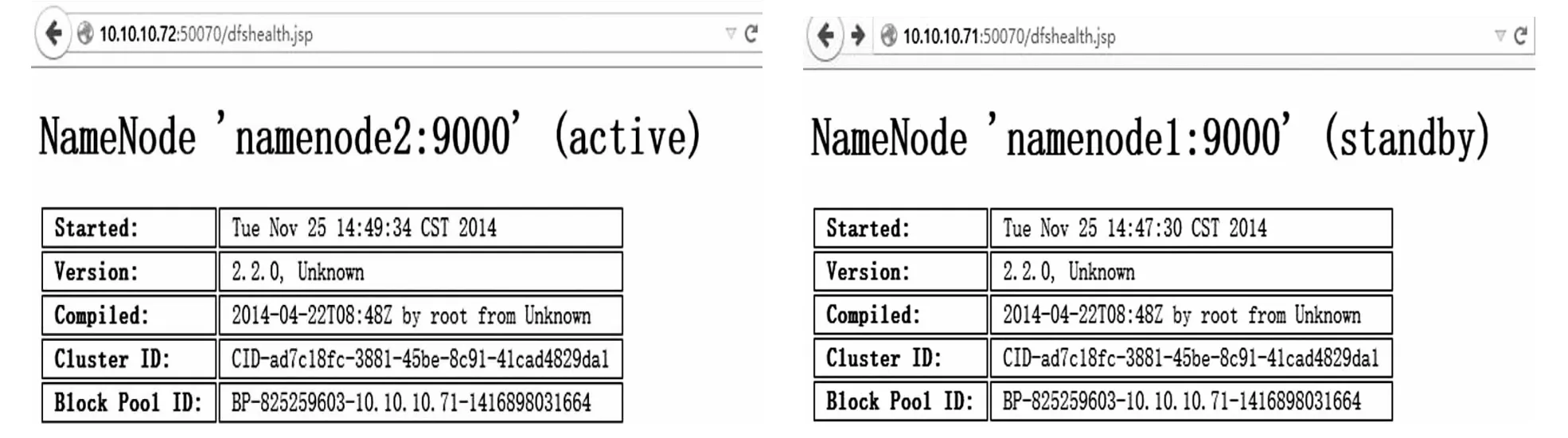
图6 故障转移后NN状态图
4 结语
针对目前OpenStack Sahara集群实验环境,设计并实现基于OpenStack Sahara集群的HA,可以实现在Sahara集群的一个NN节点遇到故障、宕机或者软硬件升级维护时,自动切换到另一台NN,保证Sahara集群的高可用性,提高整个集群的性能.
[1] RAGHURAM D,GAYATHRIN,SADASIVAM G S.Efficiently Scheduling Hadoop Cluster in Cloud Environment[M]∥Informatics and Communication Technologies for Societal Development.Springer India,2015:95-102.
[2] WANG F,QIU J,YANG J,etal.Hadoop high availability throughmetadata replication[C]∥Proceedings of the first international workshop on Cloud datamanagement.ACM,2009:37-44.
[3] FOLEY M.High Availability HDFS[C]∥28th IEEE Conference on Massive Data Storage,MSST,2012(12):3-5.
[4] 文艾,王磊.高可用性的HDFS:Hadoop分布式文件系统深度实践[M].北京:清华大学出版社,2012:350-370.
[5] OpenStack.Sahara Cluster HA[EB/OL].(2014.11.10)[2014.11.18].https:∥wiki.openstack.org/wiki/Sahara/ClusterHA.
[6] 杨帆.Hadoop平台高可用性方案的设计与实现[D].北京:北京邮电大学,2012.
[7] 董西成.Hadoop YARN单点故障解决方案(HA)介绍[EB/OL].(2013.11.27)[2014.11.15].http:∥dongxicheng. org/mapreduce-nextgen/hadoop-yarn-ha-in-cdh5/.
[8] 杨平安.基于Paxos算法的HDFS高可用性的研究与设计[D].广州:华南理工大学,2012.
[9] 邓鹏,李枚毅,何诚.Namenode单点故障解决方案研究[J].计算机工程,2012,38(21):40-44.
[10]代志远.高可用的HDFS架构剖析[J].程序员,2012(7):108-111.
[责任编辑马云彤]
Design and Im plementation of High Availability Based on OpenStack Sahara Cluster
TANG Pan1,ZHU Zhi-xiang1,LIANG Xiao-jiang2,CAIXiao-long3
(1.College of Computer Science and Technology,Xi'an University of Posts and Telecommunications,Xi'an 710061,China;2.Xi'an Future International Information Co.,LTD,Xi'an 710065,China;3.College of Software,Luoyang Normal University,Luoyang 471023,China)
To address the high cost ofmass data processing environment and point-single failures,we apply OpenStack Sahara in an effort to combine cloud computing and mass data and put forward a solution of high availability based on OpenStack Sahara.The verification result shows that the solution is effective in handling the point-single failures and the automatic handover.Thus,the high availability of cluster is ensured and the performance of Sahara cluster is improved.
single point failure;OpenStack;Sahara;high availability;handover
TP393
A
1008-5564(2015)02-0055-06
2014-12-20
唐 攀(1988—),男,陕西咸阳人,西安邮电大学计算机学院硕士研究生,主要从事云计算与大数据处理
研究;
朱志祥(1959—),男,天津人,西安邮电大学计算机学院教授,博士,主要从事信息安全研究.
