引入TOPSIS法的风险预警模型能提高模型的预警准确度吗?
——来自我国制造业上市公司的经验证据
2015-06-01朱卫东
朱卫东,吴 鹏
(1.合肥工业大学经济学院,安徽 合肥 230601;2.合肥工业大学工业信息与经济研究中心,安徽 合肥 230601)
引入TOPSIS法的风险预警模型能提高模型的预警准确度吗?
——来自我国制造业上市公司的经验证据
朱卫东1,2,吴 鹏1,2
(1.合肥工业大学经济学院,安徽 合肥 230601;2.合肥工业大学工业信息与经济研究中心,安徽 合肥 230601)
样本选取2011年和2012年我国沪深A股制造业中因财务困境陷入ST的公司和按照1:2比例配比的正常公司作为研究对象,并选取反映企业盈利能力、股东获利能力、现金流量能力、营运能力、发展能力、偿债能力的30个财务指标以及股权结构、管理结构、公司所在地的8个定性指标,以2011年的样本作为训练集,2012年样本作为测试集,在主成分分析的基础上构建以Logit模型为基础的传统预警模型和引入TOPSIS法后的二重分类模型。结果表明,引入TOPSIS法后构建的Logit模型能显著提高模型的预警准确度:对ST公司的预警准确度能提高18.5%,对样本总体的预警准确度能提高11.1%,这说明二重分类法可以构建有效的风险预警模型。
TOPSIS;Logit模型;风险预警模型;主成分分析;二重分类法
1 引言
对企业信用风险的评估最早是从分析其财务状况开始的,因为信用危机往往是由财务危机引致,财务困境往往预示着企业具有较大的信用风险,所以及早发现和找出一些预警财务趋向恶化的特征财务指标,可判断企业的财务状况,从而确定其信用等级,为信贷和投资提供依据。基于这一动机,金融机构通常将信用风险的测度转化为对企业财务状况的衡量问题。率先运用线性判别分析方法对企业信用风险进行度量和评级研究的开拓者是美国学者Altman[1-2]建立了著名的5变量的Z - Score线性模型,并将其发展为ZETA模型,但保证线性判别模型有效的两个前提:总体服从多元正态、分布协方差矩阵相等在现实经济中都很难满足。因此,为解决线性评分模型严格的假定条件的问题,Martin[3]首次使用Logisic回归的方法预测公司的破产及违约概率,Logit模型采用一系列财务比率变量来预测公司破产或违约的概率,根据银行、投资者的风险偏好程度设定风险警戒线,以此进行信用风险度量和管理,同时他将Logit模型与Z- Score模型、ZETA模型的预测能力进行了比较,结果发现Logit模型要优于Z-Score模型和ZETA模型。Ohlson[4]首次将该模型应用于商业银行信用风险评估领域,分析样本公司在破产概率区间上的分布以及两类判别错误和分割点的关系。由于Logit回归模型对于变量的分布不再有具体要求,而且在回归时通过概率值进行预测,具有较好的实用性,自此Logit回归分析方法逐渐取代传统的判别分析方法。
虽然受证券市场发展的影响导致国内学者在财务预警的研究使用Logit回归的方法起步较晚,但是也取得了了丰硕的成果,众多的实证研究表明Logit模型也同样适用于国内的证券市场:陈晓和陈治鸿[5]、徐光华和吴鸣明[6]都采用Logit回归方法建立财务预警模型检验传统财务指标和EVA指标的预测能力,发现两种指标都有显著的预示效应;吴世农和卢贤义[7]就系统的应用Fisher线性判定分析、多元线性回归分析和Logit回归分析三种方法,分别建立三种财务困境预测模型,研究结果表明三种模型都能在财务困境发生前进行相对准确的预测,但相对同一信息集,Logit预测模型的误判率最低。但是随着变量数量选取不断增多,多重共线性等问题也随之显现出来,为解决所选指标数量和种类的增多所带来的一系列问题,需要使用一种行之有效的方法来对指标进行处理,主成分分析就逐渐开始应用到预警模型的研究当中:张爱民等[8]采用了主成分分析方法建立Z值判定的财务失败预测模型,并进行了实证检验;刘鑫等[9]对各财务指标先进行主成分分析再分别构建线性概率模型和Logit模型,实证结果表明两个模型的预测效果都较为理想。
随着研究的深入,国内学者以Logit模型为基础构建的预警模型将研究对象细化到不同的行业:孔宁宁等[10]运用主成分析法和Logit回归法分别构建我国制造业上市公司财务预警模型,并对其判别效果进行比较分析,主成分分析模型与Logit回归模型的判别准确率均较高,ST前三年的预测准确度均在70%以上,两者在判别准确度上各有优劣,整体而言主成分分析预警模型的判别效果稍好。但是现有的诸多研究表明,传统的以Logit模型构建的风险预警模型对于样本总体的预警准确度较好,可是对ST公司的预警准确度远远低于对非ST公司的预警准确度,ST公司的预警准确度远远不能满足实际工作的要求,很大程度的原因在于实际工作中ST公司在样本中所占比例较小,使得构建的模型包含的ST公司的特征较少,所以模型对ST公司的预警准确度较低。如果提高ST公司样本所占的比例能够改进模型对ST公司乃至样本总体的预警准确度吗?
提高ST公司在样本中所占的比例的最直接的方法就是对研究样本进行初分类。Hwang和Yoon[11]首次提出的TOPSIS法根据有限个评价对象与理想化目标的接近程度进行排序在现有的对象中进行相对优劣的评价。TOPSIS法是一种逼近于理想解的排序法,是多目标决策分析中一种常用的有效方法,又称为优劣解距离法,能够对研究样本进行粗略的排序,将研究样本初分类为代表ST公司的样本和代表非ST公司的样本,进而提高样本中ST公司或者非ST公司的比例。这种二重分类法构建的风险预警模型能显著的改进模型的预警精度吗?
2 风险预警模型指标体系设计
2.1 样本选取
国外研究者一般都是从借贷和公司债券市场入手,通常选取破产企业与存续企业,违约贷款(债券)与非违约贷款(债券)作为样本来分析和发现那些预兆财务趋向恶化的特征指标从而建立预警模型,并将其应用于信用风险评估。我国由于历史原因,借贷和公司债券市场起步晚,不够发达,借贷市场资料及破产企业财务信息的获得非常困难,更没有建立历史违约数据库,因此无法按照国外研究者的思路来进行研究。
鉴于此,为排除行业因素对风险预警模型预警精度的影响,尽可能的比较预警方法对预警效果的影响,本文的样本选择2011、2012年的沪深A股制造业上市公司,以当年ST公司作为违约样本,非ST公司作为正常样本。为更接近现实中的比例,ST与非ST公司按照1:2比例进行配比抽样。根据华融同花顺软件与CSMAR数据库的信息进行样本选取,过程如下:
选取2011、2012年中国A股市场因财务状况异常而被特别处理的制造业上市公司作为违约样本(即ST公司);
剔除数据残缺和异常的ST公司,最终分别得到50家(2011年)、27家(2012年)ST公司为研究样本;
根据1:2配比比例按照“主营业务相同或类似、资产规模大体相等、尽可能在同一交易所上市”的原则选取同年度的正常公司作为ST公司的配对公司;
通过上述的样本选取过程,最终得到2011年150个样本(其中50家ST公司,100家非ST公司),2012年81个样本(其中27家ST公司,54家非ST公司)。为了更好的对预警效果进行比较,在研究中,将2011年的样本作为训练集,2012年的样本作为测试集。
需要特别指出的是,因为公司在T年被ST是基于T-1年的财务数据,所以选取T-1年的财务数据研究意义不大。本文所用的数据是ST公司被宣布特别处理前两年的财务数据,即若ST公司是2012年被宣布特别处理,使用的数据年份为2010年,与之配对的正常公司使用的数据年份也是2010年。
2.2 指标的选取与筛选
目前大多数现有的文献对上市公司的评价主要是通过对企业的一系列财务指标与定性分析相结合来确定企业的信用等级。财务指标能够综合地反映企业在一定时期的财务状况的变动情况,能够准确地揭示企业盈利的质量,与其他资产存在方式相比更容易核查、验证,而且现金流量指标受企业经营者主观歪曲的影响较小。因此,以基于现金流量指标的业绩指标能迅速地提示企业信用风险,达到更好的预警效果。
传统的财务指标主要包括企业盈利能力、股东获利能力、现金流量能力、营运能力、发展能力、偿债能力这六个方面的能力,现有的国内外学者研究也多是采用全部或部分能力的指标,在CSMAR数据库中也如是分类。这些财务指标可以较好的说明企业的经营状况、盈利状况等内容,这些都会影响到企业的财务状况进而影响企业是否会陷入财务困境。
但是影响公司运营状况的因素有很多,仅仅采用财务指标数据不能充分表现公司的实际情况,公司的股权结构、管理结构、宏观经济状况等都会对公司的经营和财务状况造成重要的影响,所以在考虑财务指标数据的情况下,也要兼顾反映公司其他方面能力的指标。
姜秀华等[12]利用股权集中度(前三大股东持股比例的平方和)作为公司治理的代替变量,并结合财务变量分析了我国上市公司中弱化的公司治理与财务困境之间的关系,实证结果表明,股权集中度越高的公司越不容易陷入财务困境。而 Lee等[13]对我国台湾上市公司的所有权集中情况考察后发现,控股股东在董事会中拥有的董事会席位百分比、控股股东用作银行抵押贷款的股票百分比、控制权与现金流量要求的偏离程度这3个变量与公司在下一年度陷入财务困境的可能性正相关, Lee认为股权越分散,股东之间相互搭便车的动机就越强烈,公司就越强烈,公司就越容易陷入财务困境。这与姜秀华的结论正好相反。
Elloumi[14]以92家加拿大上市公司为样本(46家财务困境与46家非财务困境公司),考察了董事会结构与企业财务困境之间的关系后发现,外部董事比例和公司发生财务困境的可能性存在显著的负相关关系。Judge等[15]认为,高比例的的内部董事会使得董事会很少参与公司的决策制定,这就使得管理层对公司拥有绝对的控制,进而影响公司的战略决策影响企业的经营。沈艺峰等[16]的研究表明董事长和总经理兼任是我国公司治理结构失败的原因之一,我国“强管理者、弱董事会”的治理现象是公司出现财务困境的重要原因。Wang Zheng等[17]选用董事会成员持股比例、董事会规模、内部董事比例、董事长总经理兼任情况这四个指标,对我国上市公司董事会特征和财务困境的关系进行研究,结果表明,高管人员持股比例越高公司成员陷入财务困境的可能性就越小;董事长与总经理兼任公司陷入财务困境可能性就越大。
赵冠华[18]认为,企业面临的地区经济和制度环境,如经济发展水平、地方对企业的管理状况等对企业的经营能力也有影响。对制造型企业而言,经济发展水平较高(GDP总量居全国前十名)的地区市场前景好、消费潜力大、公共物品供应充足,企业陷入财务困境的可能性较小。
所以,本文主要使用财务指标,并加上部分定性指标,在参考和借鉴李志辉和李萌[19]、陈艳和张海君[20]、张新红和王瑞晓[21]等人对财务指标的研究成果和等人对定性指标研究的基础上,考虑数据的可得性与完整性,选择全面反映企业盈利能力、股东获利能力、现金流量能力、营运能力、发展能力、偿债能力的30个财务指标以及股权结构、管理结构、公司所在地的8个定性指标作为备选变量。
为简化模型,选择对ST公司和非ST公司区分能力最强的指标以及剔除过多指标带来的多重共线性问题,需要选取具有显著差异的指标构建模型。利用SPSS 18.0使用K-S检验对样本的正态性进行检验,然后对服从正态分布的指标用独立样本T检验进行区分度显著性检验,对不服从正态分布的指标用Mann-Whitney方法进行区分度显著性检验。以上检验显著度水平均为0.05,指标选取与检验结果如表1:
表中,(M)代表K-S检验不符合正态分布使用Mann-Whitney方法进行区分度显著性检验之后的结果,(T)代表K-S检验符合正态分布使用独立样本T检验之后的结果。用表中存在显著差异的指标构建预警。
3 传统预警模型的构建与结果分析
由于Logit回归模型对于变量的分布不再有具体要求,而且在回归时通过概率值进行预测,具有较好的实用性,从以前学者的研究成果来看,Logit模型的预测结果均较为理想,所以本文的传统预警模型选择Logit模型。
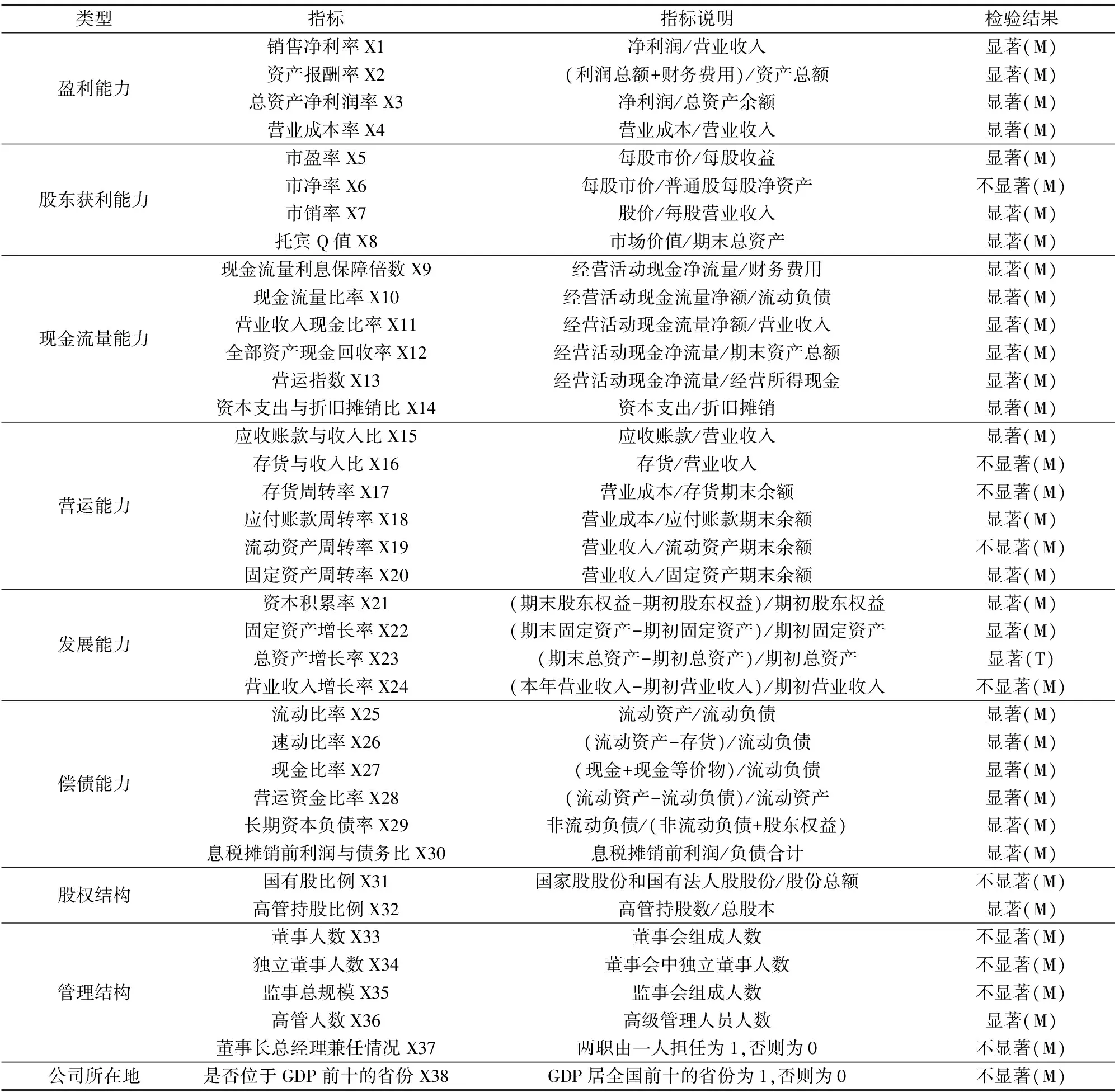
表1 选取的指标及检验结果
3.1 主成分分析
上述检验过程剔除了缺乏显著性的指标,但余下的指标高度相关,直接纳入分析不仅复杂,而且可能因为多重共线性而无法得出适当结论。因此在构建模型前利用因子分析中的主成分分析法对样本数据进行处理。
在主成分分析前,对数据进行KMO检验和Bartlett球形检验,以判断是否合适进行主成分分析,结果如表2所示:
由上表可见,Bartlett球形检验的sig值均为0,小于0.05;KMO 值均大于 0.6,两者皆说明原始指标体系较适合做因子分析。

表2 KMO和Bartlett球形检验结果
使用SPSS进行主成分分析后,根据解释的方差表,以特征值大于1为标准,选取主成分进行模型构建,主成分解释的方差如表3:
由于进入因子分析的变量较多,在筛选处理后最终得到9个主成分;累积的方差贡献率达到70%左右,能够反映大部分的方差变化,因子分析的效果较为理想。
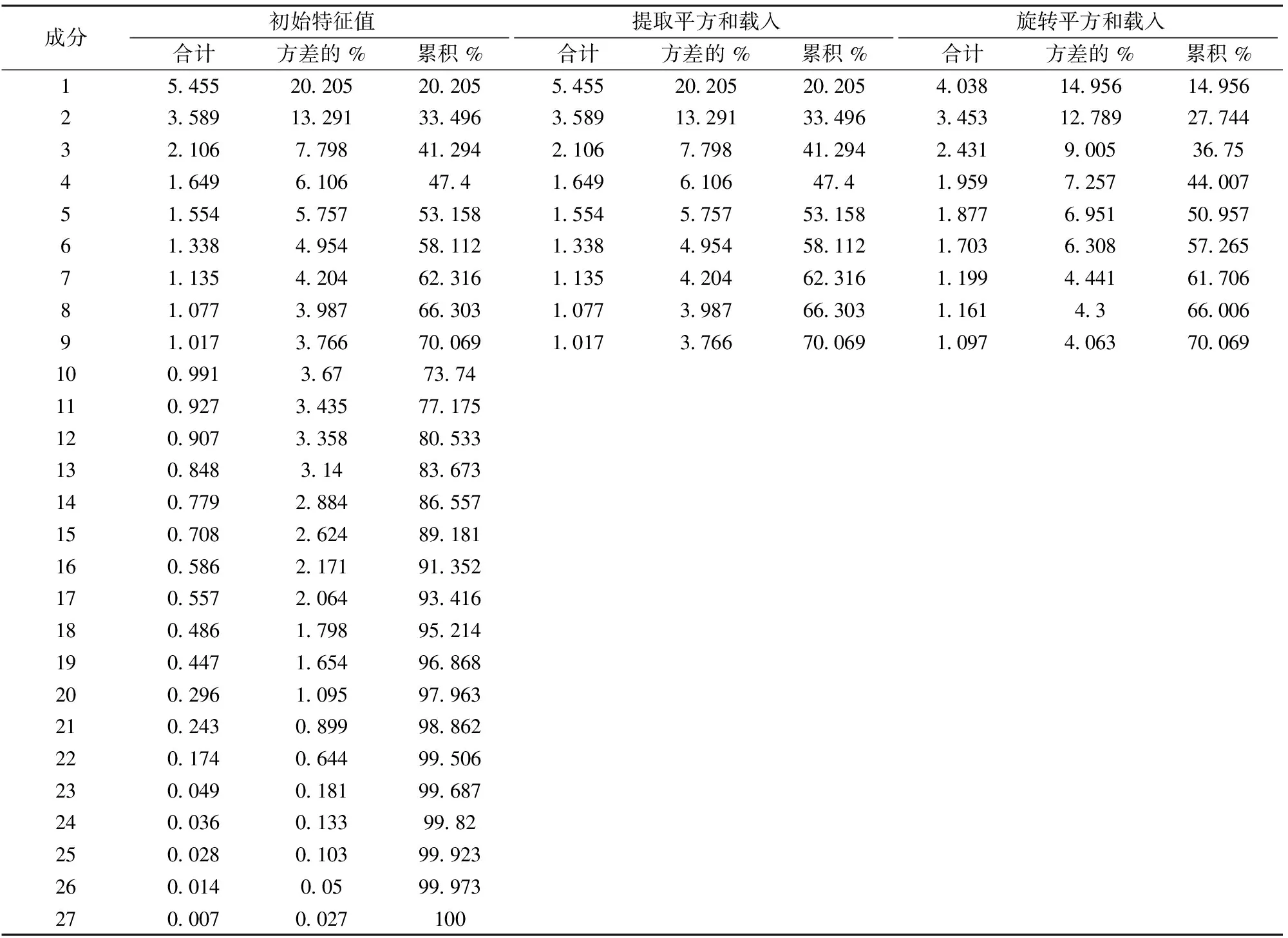
表3 主成分解释的总方差
提取方法:主成分分析

表4 Logit回归模型的估计结果
注: *表示估计值显著性水平在0.1以内,**表示估计值显著性水平在0.05以内,***表示估计值显著性水平在0.01以内
3.2 Logit模型的预警分析
根据spss输出结果中的成分得分系数矩阵可以得到因子得分函数,利用筛选出的主成分F1,F2…,F9,以训练集构建Logit模型。
利用F1,F2…,F9构建出的违约概率P的计算公式如下:
P∈(0,1)
(1)
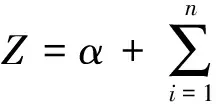
以0.5为界限,P大于0.5判别为ST公司,P小于0.5判别为非ST公司,将通过训练集训练得到的预警模型中系数不显著的变量F4、F5、F6、F7、F8剔除后,用构建得到的预警模型来检验测试集,训练集与测试集的结果如表5、表6所示:
从表5和表6来看,仅使用Logit模型构建的风险预警模型的判别和预警效果较好,对非ST公司的判别和预警准确度均较高,而对ST公司的判别准确度较高,预警准确度则较低。出现这样的原因是多方面的,这就需要我们使用一种新的方法,提高对ST公司的预警准确度。
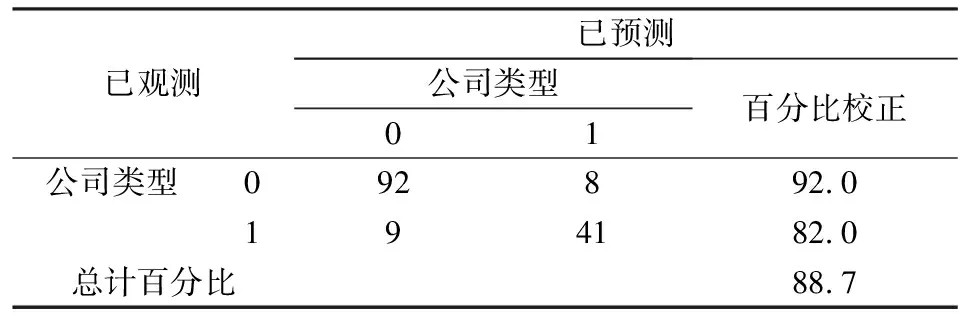
表5 训练集判别准确度
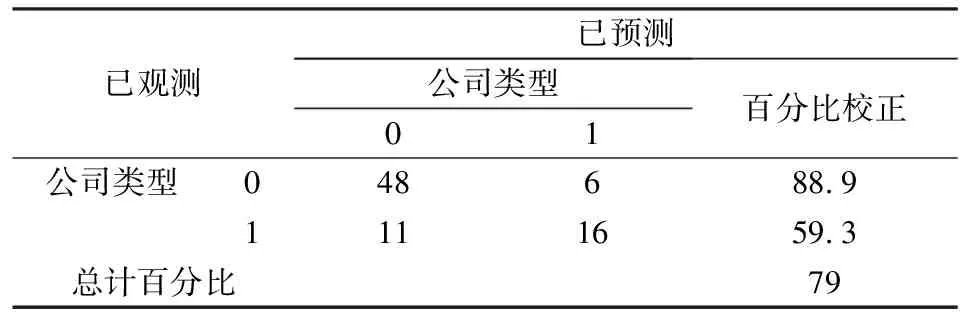
表6 测试集预警准确度
4 引入TOPSIS法的风险预警模型的构建和结果分析
仅仅使用Logit模型来构建的预警模型无法有效区分ST公司与非ST公司,对于训练集的样本而言,训练得到的结果不能充分表达ST公司和非ST公司的特征,所以,测试集中得到的准确度也较低。如果能采取一定的手段能够有效的将尽可能多的非ST公司与ST公司区分出来再分别构建新的Logit模型,使得用于构建Logit模型的训练集中ST和非ST公司所占的比例尽可能高,得到的模型也更能反映不同类型公司的特征,得到的结果也会更加准确。
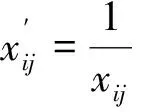
(1)计算规范决策矩阵。规范值为:
(2)
(i=1,2,…,m;j=1,2,…,n)
(2)计算加权规范决策矩阵
其加权值为:υij=ωj·nij
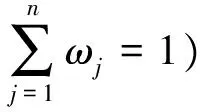
(3)确定正理想解和负理想解
(3)
(4)计算某个方案与正理想解和负理想解的分离度
(4)
(5)
(5)计算备选方案与正理想解的相对接近度
(6)
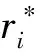
以上的计算过程在MatlabR2010中完成,通过计算样本与负理想解之间的距离得到样本的接近度,按从大到小排序。位置靠前的公司表现的更为优秀,可以作为代表非ST公司的样本,而位置靠后的公司则表现较差,可以作为代表ST公司的样本。为便于之后构建新的Logit模型,在本文的研究中训练集与测试集均选取排名前2/3为代表非ST公司的样本,排名后1/3为代表ST公司的样本,基于此构建新的风险预警模型。
对代表ST公司和非ST公司的训练集样本分别构建Logit模型,得到的判别准确度和模型表达表达式如下所示:
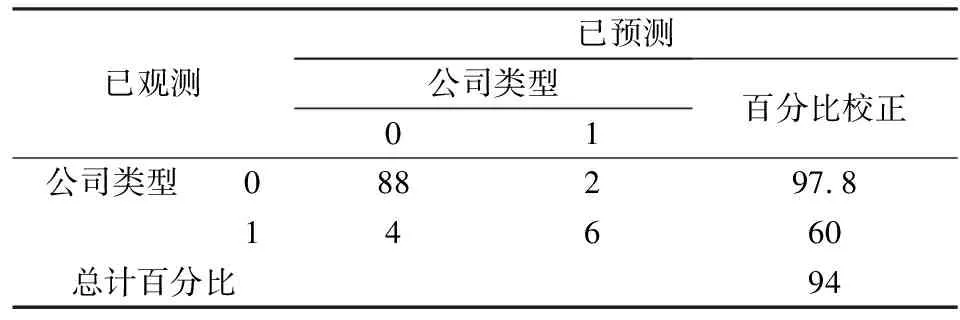
表7 代表非ST公司训练集样本的判别准确度
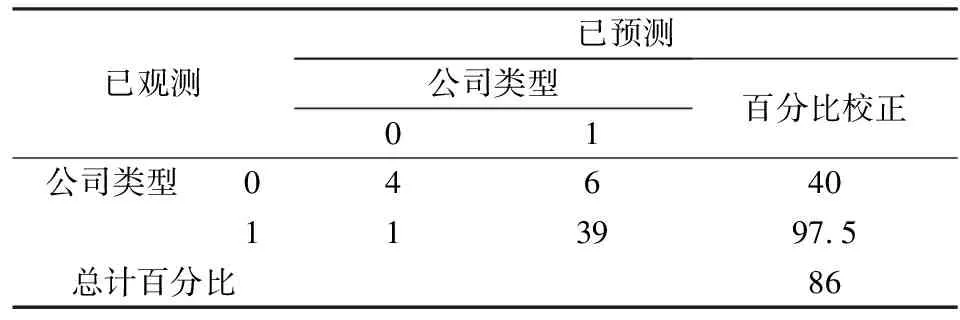
表8 代表ST公司训练集样本的判别准确度
将表7与表8整合,可以得到运用新方法后的训练集的判别准确度,如表9:
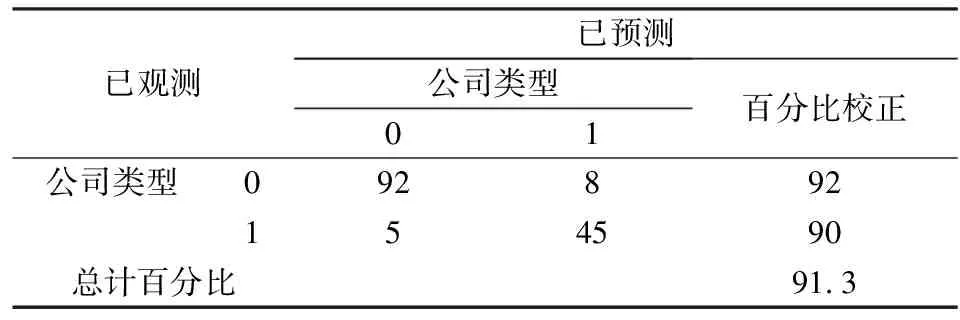
表9 新方法下的训练集判别准确度
从表7-表9来看,并与表5进行对比,我们发现,在新方法下,对于代表非ST公司的训练样本集,因为得到的Logit模型能包含更多的非ST公司的特征,所以对于非ST公司的判别准确度较高,而对ST公司的判别准确度则较低,远远低于未筛选的训练集中对ST公司的判别准确度;同样,对于代表ST公司的训练集样本,得到的Logit模型能更好的反映ST公司的特征,所以对于ST公司的判别准确度较高,高于未筛选的训练集样本中对ST公司的判别准确度。从表9中的数据得知,在新方法下的训练集整体,与未筛选的训练集判别准确度进行对比,新方法对样本总体的判别准确度仅能提升2.6%,其中对于非ST公司的判别准确度没有差异,可是对于ST公司的判别准确度在原方法已经达到82%的情况下仍然能够提升8%,所以对ST公司有着较强的判别能力。
利用同样的方法,对测试集样本的接近度进行排名,筛选出排名靠前(2/3)即表现更为优秀的企业作为代表非ST公司的测试样本集,排名靠后(1/3)即表现较差的企业作为代表ST公司的测试样本集,计算测试集样本中的违约概率P,同样以P=0.5为界,P大于0.5预测为ST公司,P小于0.5预测为非ST公司,得到的代表ST公司和非ST公司的预警准确度如下所示:
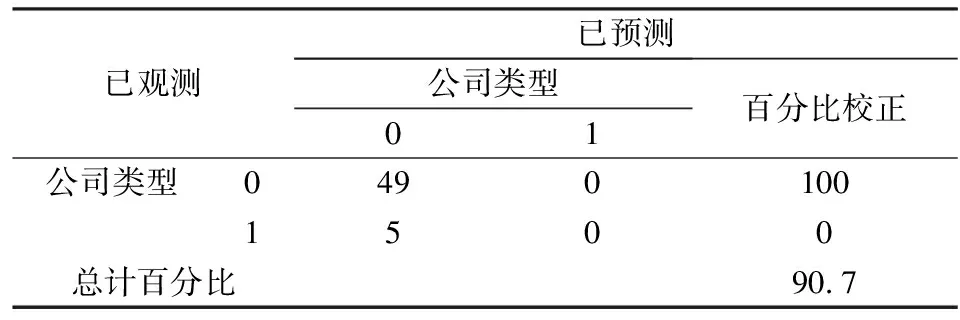
表10 代表非ST公司的测试集样本预警准确度
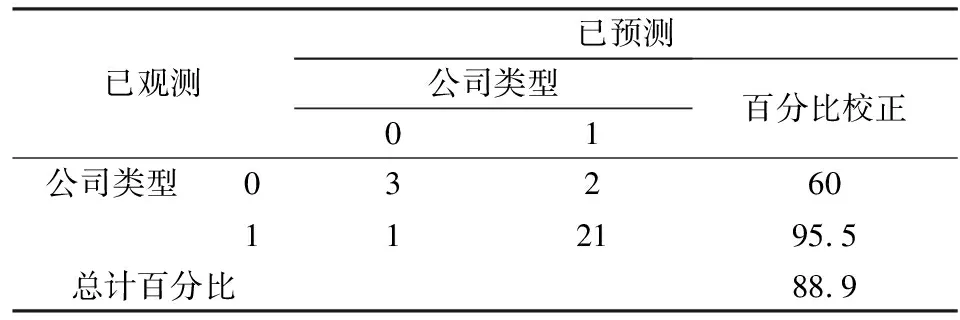
表11 代表ST公司的测试集样本预警准确度
将表10与表11整合,可以得到运用新方法后的测试集的预警准确度:
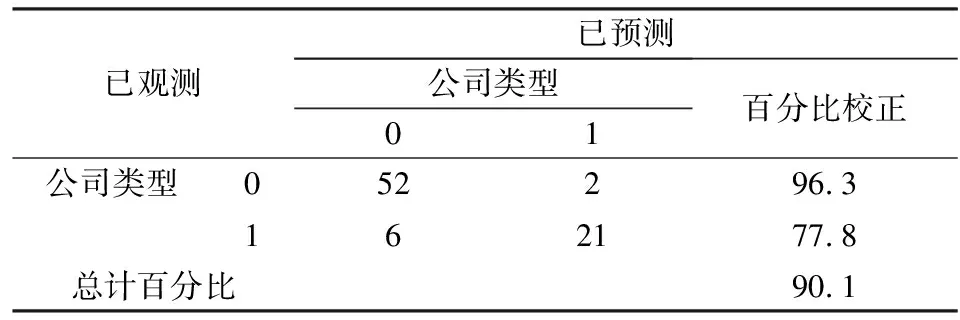
表12 新方法下的测试集预警准确度
从表10-表12来看,并与表6进行对比,发现因为从之前代表非ST公司的训练集中得到的Logit模型能包含更多的非ST公司的特征,所以对于代表非ST公司的测试样本集的预警准确度为100%,而对ST公司的预警准确度则仅为0,远远低于未筛选的训练集中对ST公司的预警准确度;同样,对于代表ST公司的测试样本集,之前得到的代表ST公司的Logit模型能更好的反映ST公司的特征,所以能大大提升对ST公司的预警准确度,远远高于未筛选的训练集样本中对ST公司的判别准确度,而对代表ST公司测试样本集中非ST公司的预警准确度则稍稍下降。从表12来看,对于测试集总体而言,新方法在传统方法对非ST公司的预警准确度达到达到88%这一较高的水平下依然能够提高8个百分点,效果较为显著;对于ST公司传统方法的预警准确度水平仅能达到59%,对于实践工作而言这个预警度水平非常低,而新方法能较大幅度的提升对ST公司的预警准确度,较于传统方法的预警准确度提升18%,能够达到77.8%这一较高水平,这可为银行等行业的实践工作提供有力的参考依据;而对于整个测试集样本而言,新方法的使用能够使测试集总体的预警准确度从79%提高到90.1%,这说明新方法对于提升模型的预警准确度是非常有效的。
与前人有关财务预警的研究结果相比,二重分类法得到的预警效果也非常优秀。吴世农[7]分别构建了多元线性回归、Fisher模型和Logit模型,对财务困境前5年的误判情况进行分析,其中ST前2年误判率最低的为Logit模型,误判率为15.71%,预警准确度低于本文得到的结果。李志辉[19]的文章中利用Fisher 线性方法、Logit 模型、BP 神经网络技构建了商业银行信用风险识别模型,其中Logit模型对于ST公司的误判率为32.4%,样本总体的预警准确率为80%,也远远低于本文利用二重分类法得到的预警结果。S Ding[22]也做了相似的研究,研究中加入了更多的定性指标对于提升模型精度有着一定的效果,但是加入定性指标之后,样本总体的误判率依然达到16.26%,比本文的研究结果稍差。这说明相对而言,二重分类法的预警精度非常高。
5 结语
国内外的有关风险预警模型的研究已经持续了半个世纪,从线性模型、Logit模型再到BP等人工智能模型,其本质都是使用训练出的模型来对样本进行预测,因此如何得到更优秀的训练模型是提高模型预测准确度的前提。传统得到良好的风险预警模型的思路都是针对训练集样本采用不同的训练方法,比如Tobit、支持向量机等,现有的研究也逐渐成熟,有关预警模型研究的脚步也逐渐放缓。因此在目前训练方法可能已经充分挖掘的基础上,可以考虑从训练集样本入手,通过某种规则构建合适的训练集样本,进而得到更优秀的训练模型。
训练是一个从训练集样本中提取符合研究目的的过程,比如本文的研究就期望训练得到的模型能够更好的体现ST公司或者非ST公司的特征。基于本文的这种“二重分类法”的预警模型对训练集样本进行二次分类,相对于传统方法,得到的新的训练集样本包含的非ST公司与ST公司的比重更大,能较好的代表这两类公司,当然模型包含的信息体现在哪些方面仍然需要进一步的探索。通过训练得到的模型也包含了更多的ST公司和非ST公司的信息,更能表达两类公司的特征,所以对于提升模型的判别准确度有一定的效果;对于测试集而言,新方法下通过训练集得到的模型的综合预警效果较好,预警精度均能得到一定程度的提升,尤其能较大幅度的提高对ST公司的预测精度。本文通过构建合适的训练集与测试集样本,在使用常用的预警方法的基础上得到的结果更优秀,这对于相关机构的实践工作有一定的启示:风险预警模型的构建除了不断改进预警方法、构建复杂的指标体系之外,可以从训练集的科学合理构建着手。
但是本文的研究还存在着一定的局限性,在以后相关研究中仍然需要实现突破:
(1)指标体系构建中,虽选择了一些定性指标,但是在区分显著度检验中被剔除掉一部分,在今后的研究中对于如何选取更多有区分度的检验指标仍然是研究的重点之一。
(2)为排除行业因素影响,本文的研究选取制造业上市公司,至于行业因素对于预警模型的影响如何仍然需要进一步的探讨。
(3)本文使用的“二重分类法”是使用TOPSIS法初分类后运用Logit模型进行再分类,在之后的研究中二重分类中选择的方法也值得进一步研究。
[1] Altman E I. Financial rations, discriminant analysis and the prediction of corporate bankruptcy[J]. Journal of Finance,1968,23(4)::589-609.
[2] Altman E I,Haldeman R G,Narayanan P. Zeta analysis: A new model to identify bankruptcy risk of corporations [J]. Journal of Banking and Finance,1977,(7):29-54.
[3] Martin D. Early warnings of bank failure: A logit regression approach[J]. Journal of Banking and Finance,1977,1(3):249-276.
[4] Ohlson J A. Financial ratios and the probabilistic prediction of bankruptcy[J]. Journal of Accounting Research,1980,18(1):109-131.
[5] 陈晓,陈治鸿.中国上市公司的财务困境预测[J].中国会计与财务研究,2000,2(3): 55-92.
[6] 徐光华,吴明鸣. 基于EVA 的行业财务预警模型研究-以沪市IT 上市公司为例[J].经济管理, 2006,(24):63-68.
[7] 吴世农,卢贤义.我国上市公司财务困境的预警模型研究[J]. 经济研究, 2001,(6):21-26.
[8] 张爱民,祝春山,许丹健.上市公司财务失败的主成分预测模型及其实证研究[J].金融研究, 2001,(3):10-25.
[9] 刘 鑫,李竹薇. 我国上市公司信用风险管理模型的构建与实证研究[J]. 财经问题研究,2009,(12):82-86.
[10] 孔宁宁,魏韶巍. 基于主成分分析和Logit回归方法的财务预警模型比较[J]. 经济问题,2010,(6):112-116.
[11] Hwang C L, Yoon K. Multiple attribute decision making[M]. Berlin: Springer, 1981.
[12] 姜秀华, 孙铮. 治理弱化与财务危机: 一个预测模型[J]. 南开管理评论, 2001, (5): 19-25.
[13] Lee T S, Yeh Y H. Corporate governance and financial distress: evidence from Taiwan[J]. Corporate Governance: An International Review, 2004, (3): 378-388.
[14] Elloumi F, Gueyie J P. Financial distress and corporate governance: An empirical analysis[J]. Corporate governance, 2001, (1): 15-23.
[15] Judge W Q, Zeithaml C P. Institutional and strategic choice perspectives on board involvement in the strategic decision process[J]. Academy of management journal, 1992, (4): 766-794.
[16] 沈艺峰, 张俊生. ST 公司董事会治理失败若干成因分析[J].证券市场导报,2002,(3):21-25.
[17] Wang Zhen, Liu Li, Chen Chao. Corporate governance, ownership and financial distress of publicly listed companies in China[J]. Petroleum Science, 2004, 1(1): 90-96.
[18] 赵冠华.企业财务困境分析与预测方法研究[M].北京:经济科学出版社,2011.
[19] 李志辉,李萌. 我国商业银行信用风险识别模型及其实证研究[J]. 经济科学,2005,(5):61-71.
[20] 陈艳,张海君.上市公司财务预警模型的研究[J]. 财经问题研究,2007,(6):92-97.
[21] 张新红,王瑞晓. 我国上市公司信用风险预警研究[J]. 宏观经济研究,2011,(1):50-54.
[22] Ding Shaofeng, Hou Yingchao, Hou Peipei. Logistic financial crisis early-warning model subjoining nonfinancial indexes for listed companies[M]//Qi ershi,Shen Jiang,Dou Runliang. The 19th International Conference on Industrial Engineering and Engineering Management. Berlin Heidelberg: Springer, 2013: 685-696.
Canthe Introduction of TOPSIS in Risk Early-warning Model Improve theAccuracy of Early-warning?—A Case Study from Listed Companies of Manufacturing Industry
ZHU Wei-dong1,2, WU Peng1,2
(1.School of Economics, Hefei University of Technology, Hefei 230009,China;2.Center for Industrial Information and Economy Research, Hefei University of Technology, Hefei 230009,China)
Taking the indebted ST listed companies and twice as many the non-ST of manufacturing industry in Shanghai and Shenzhen A-share from 2011 to 2012 as sample, 30 financial indicators that can reflect the business profitability, profitability of shareholders, cash flow capacity, operational capacity, development capacity and debt solvency and other 8 qualitative indicators including ownership structure, management structure and location of the companies are selected. Considered the sample of 2011 as a training set while the 2012 as testing set, a traditional warning model and double classification model in which TOPSIS method are introduced on the basis of the principal component analysis are built. The results show that the introduction of TOPSIS in risk early-warning model can increase the accuracy of early-warning significantly. It can improve the accuracy of early warning system 18.5% for ST companies and 11.1% for samples in general. This suggests that the method of double classification can be applied to build an effective risk early-warning model.
TOPSIS; logit model; risk early-warning model; principal component analysis; double classification
2013-12-03;
2014-08-28
国家自然科学基金资助项目(71071048)
朱卫东(1962-),男(汉族),浙江仙居人,合肥工业大学教授,博士生导师,研究方向:智能决策理论、经营决策与控制理论、会计信息化理论与实务.
1003-207(2015)11-0096-09
10.16381/j.cnki.issn1003-207x.2015.11.012
F224
A
