多核平台下考虑能耗的实时任务分派与调度研究
2015-05-30黄阳阳
黄阳阳

摘 要:Single-clock multiprocessor Frequency Assignment Algorithm(SFAA)算法是一个对周期性的实时任务进行分派与调度的算法。本文打算对SFAA算法和三种常见的分派和调度算法分别在4核和8核平台下在能耗和时间两个方面进行比较和分析,并且从任务集的任务数、任务集的利用率,即任务集中的每个任务的利用率之和,任务的利用率的最大值三个因素进行分析。最后通过实验验证了SFAA算法在节能方面总是优于其它三种算法;同时在时间方面总是SFAA耗时大于其它三种算法,揭示了任务集的任务数、任务集的利用率和任务的利用率的最大值对能耗和耗时的影响。
关键词:实时系统;节能;时间分析 ;多核平台
中图分类号:TP311 文献标识码:A
Energy Consumption for Real-Time Tasks Under the Multi-Cores Platform
HUANG Yangyang
(School of Computer Science and Technology, Donghua University, Shanghai 201620, China)
Abstract: Single-clock multiprocessor Frequency Assignment Algorithm (SFAA) algorithm is an algorithm for periodic real -time dispatching and scheduling tasks. This article intends to SFAA algorithm and three kinds of common assignment and scheduling algorithm based on 4-core and 8-core platform to compare and analyze such two aspects as energy consumption and time, and the paper mainly focused on the task and the task of utilization analysis from the number of jobs set for each task, the task set of use rate, maximum utilization of the three angles of each task. Finally, experiments verified the SFAA algorithm in energy efficiency is always better than the other three algorithms; and in terms of time always SFAA is larger than the other three algorithms. It reveals the impact of the number of tasks in a set, the total utilization of the tasks and the max utilization of tasks on energy consumption and time consuming under four algorithms.
Key words: Real-time Systems; Energy Efficiency; Time Analysis; Multicore Platform
0 引 言
在近些年,能量管理已经成为现实发展异常活跃的研究领域。一个研发多核处理器的架构(Chip Multi-Processors,简称CMPs)的重要因素是不可能持续增长的处理器频率和传统单核架构的功率密度的趋势。所以,在多个操作点的步骤规划时,CMPs即配备了动态电压和频率调节(Dynamic Voltage and Frequency Scaling)。
处理器的能量消耗主要包括两部分,也就是动态和静态功耗。具体的来说,动态功耗就是切换行为(switch activity)的消耗;静态功耗则主要是泄露电流。一种常见的减少动态功耗的方法就是使用动态电压和频率调节,即DVFS[1]。而一种可以减少静态功耗的方法即是当处理器空闲的时候,关闭多核处理器[2-5]。这样一种机制若要实现,即动态关闭处理器,就需要硬件支持才可以完成。在实时环境下通过采用DVFS和动态关闭处理器方式的节能调度问题就是要保证所有的实时任务均可到达截止期,且此过程中能量消耗则要最小。
这些年已经有很多论文已经针对基于DVFS的实时嵌入式系统的方案可以运用在每个处理器中不同的芯片(chip)的传统的多处理器平台上展开多方研究论证[6]。研究后成果确认该问题主要归结为两个难点:一是任务的分派,二是运行时在不同处理器上电压的调节[6]。但是新兴的CMP平台却因其自身独具的一些特性,而使得这一问题和传统的多处理器平台呈现了不同的问题论述。事实上,多核处理器在商业的CMPs中是共享同一个电压电平的。
众所周知,在强条件下的多处理器的实时调度分派是一个NP-hard问题[6],但是在实践中则会发现一些简单且高效的分派启发法在多数情形下却有着上佳表现[6]。无独有偶的是能量消耗最小的任务的分派问题同样也是一个NP-hard[6]问题。最近研究则已表明处理器负载均衡就能有效降低能量消耗[6]。Worst-Fit-Decrease(WFD)启发式算法即可使处理器达到负载均衡,从而降低能量消耗。但是负载平衡却并非总能降低能量消耗,由此Single-clock multiprocessor Frequency Assignment Algorithm(SFAA)算法随即形成并已获提出[6]。
1背景 介绍
1.1Sys-Clock算法
Sys-Clock算法是在一个应用给定的优先级设计的调度策略的系统中,用来计算在单个处理器下使得任务集的每个任务都不会错过截止期的前提下,处理器能够达到最小频率的一个流程描述。该算法主要利用了一个处理器的基本性质:如果处理器运行其工作负载是在一个最小的可能的恒定速度下,那么此时耗费的能量最小。但是在一个系统中使用给定的优先级设计的调度策略时,工作负载需要完成的任务的请求,即包括该任务本身运行时间和中断该任务的高优先级的多个任务的运行时间。而且当系统中有多个周期任务运行时,处理器的空闲区也不 是均匀分布在任务的最坏情况下的运行区域(critical zone)。
1.2 Single-clock multiprocessor Frequency Assignment Algorithm(SFAA)算法
能耗值不仅与任务分派有关,还和任务集的调度策略有关。由于在RMS调度下,负载均衡(load-balancing)不一定总能做到能量最小。针对这一情况,SFAA提出了一定改进,相应策略是使用sys-clock算法来完成分派和调度。WFD启发式分派算法在分派时只考虑了任务的利用率,而SFAA分派算法除了考虑了任务的利用率,同时还一并考虑了任务的周期的影响。
1.3 Liu and Layland Bound和Hyperbolic Bound算法
2 模拟实验的系统模型
3 实验
本文实现四种算法,分别是:WFD算法,HB算法,Sys算法和SFAA算法。其中,WFD算法,HB算法和Sys算法都是使用WFD启发式分派算法来实现任务分派,算法中保证任务集的可调度性策略分别是LL-Bound,H-Bound,Sys-clock算法。
3.1实验设计
本文的实验设计以文献[6]为基础,并在参数设置上进行了扩充。本文为每组实验随机生成1 000个任务集,文中每个任务的利用率服从均匀分布,在 的区间上随机产生实时任务的利用率。
3.2实验结果与分析
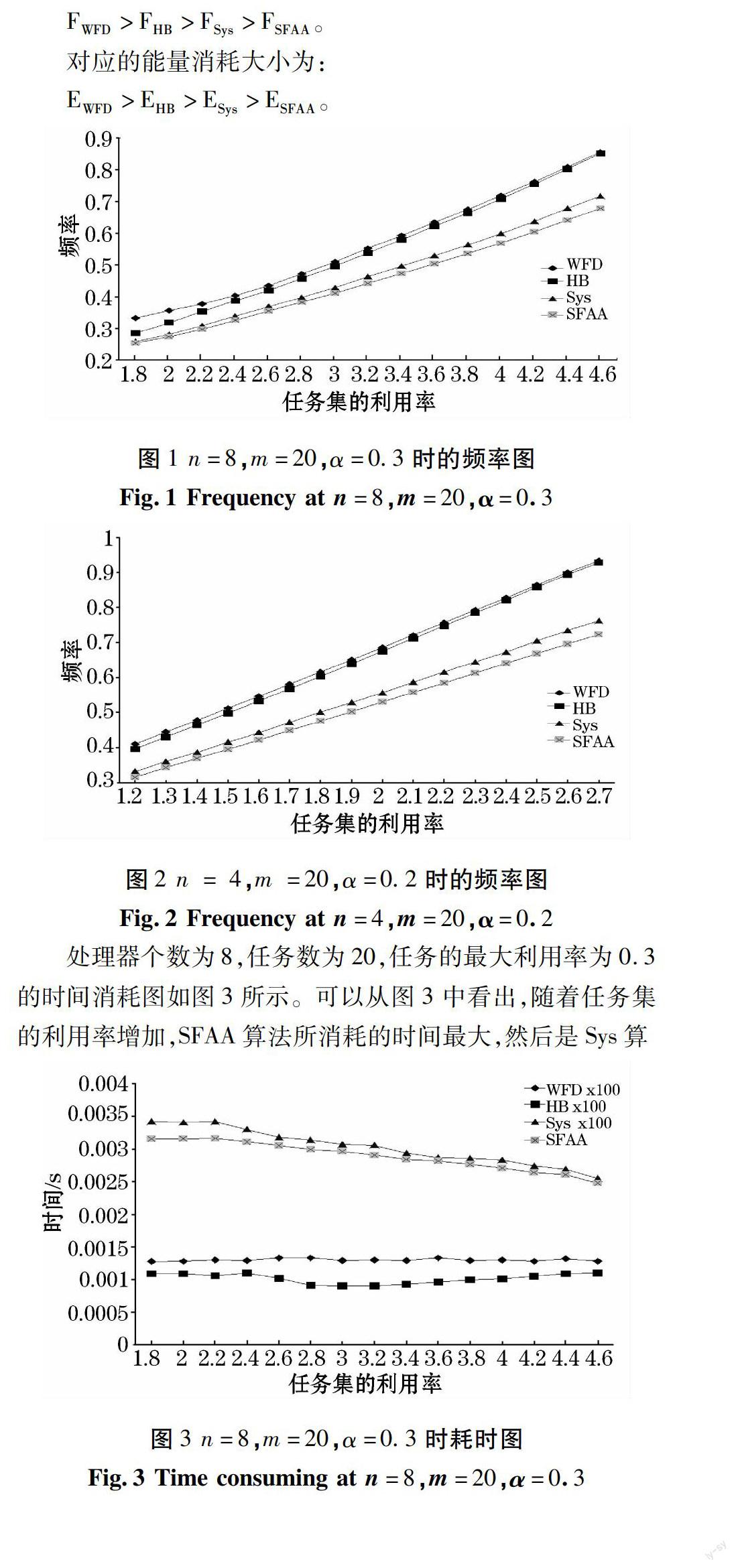
处理器个数为8,任务数为20,任务的最大利用率为0.3的频率图如图1所示。可以从图1中看出,增大任务集的利用率,则8核处理器的整体频率增大;并将WFD算法和HB算法得到的整体频率进行对比后,发现随着任务集的利用率的增加,HB算法得到的整体频率的优势越小;而SFAA算法得到的整体频率的优势却越来越大。任务数为20,任务的最大利用率为0.2,处理器为4时的频率图则如图2所示,与处理器为8时的情况相同。4种算法得到的整体频率总是有:
图1 n=8,m=20,α=0.3时的频率图
Fig.1 Frequency at n=8,m=20,α=0.3
图2 n = 4,m =20,α=0.2时的频率图
Fig.2 Frequency at n=4,m=20,α=0.2
处理器个数为8,任务数为20,任务的最大利用率为0.3的时间消耗图如图3所示。可以从图3中看出,随着任务集的利用率增加,SFAA算法所消耗的时间最大,然后是Sys算法消耗的次多,HB所消耗时间则要小于WFD所消耗的时间,整体看来四种算法所消耗的时间均呈略降态势。任务数为20,任务的最大利用率为0.2,处理器为4的耗时如图4所示,不难看出与处理器为8时的结论相同。
图3 n=8,m=20,α=0.3时耗时图
Fig.3 Time consuming at n=8,m=20,α=0.3
图4 n=4,m=20,α=0.2时耗时图
Fig.4 Time consuming at n=4,m=20,α=0.2
图5给出了一个任务集利用率为2.4,最大利用率为0.1,处理器的个数为4的频率图。图6是一个任务集利用率为3.2,最大利用率为0.1,处理器的个数为8的频率图。可以从图5和图6看出,当任务集的任务数增多时,四个算法得到的处理器的整体频率基本不变。总体看来,HB算法得到的处理器的整体频率是要低于WFD算法的;Sys算法和SFAA算法进行比较,随着任务数增多,二者得到的频率之差却未见有太大的变化。SFAA算法得到的整体频率最低,其次是Sys算法,而后是HB算法,WFD算法得到的整体频率最大。对应的能量消耗大小有:
EWFD>EHB>ESys>ESFAA 。
图5 n=4,U=2.4,α=0.1时的频率图
Fig.5 Frequency at n=4,U=2.4,α=0.1
图6 n=8,U=3.2,α=0.1时的频率图
Fig.6 Frequency at n=8,U=3.2,α=0.1
图7为对应的时间图。可以从图7中看出随着任务集中的任务数的增加,WFD算法和HB算法所消耗的时间基本一样,其中SFAA算法所消耗的时间最大,然后是Sys算法消耗的时间较多,再后即是HB算法和WFD算法。整体看来,4种算法所消耗的时间均处于增长中。处理器为8的情况如图8所示,不难看出与处理器为4时的情况也是一样。
图7 n=4,U=2.4,α=0.1时耗时图
Fig.7 Time consuming at n=4,U=2.4,α=0.1
图8 n=8,U=3.2,α=0.1时耗时图
Fig.8 Time consuming at n=8,U=3.2,α=0.1
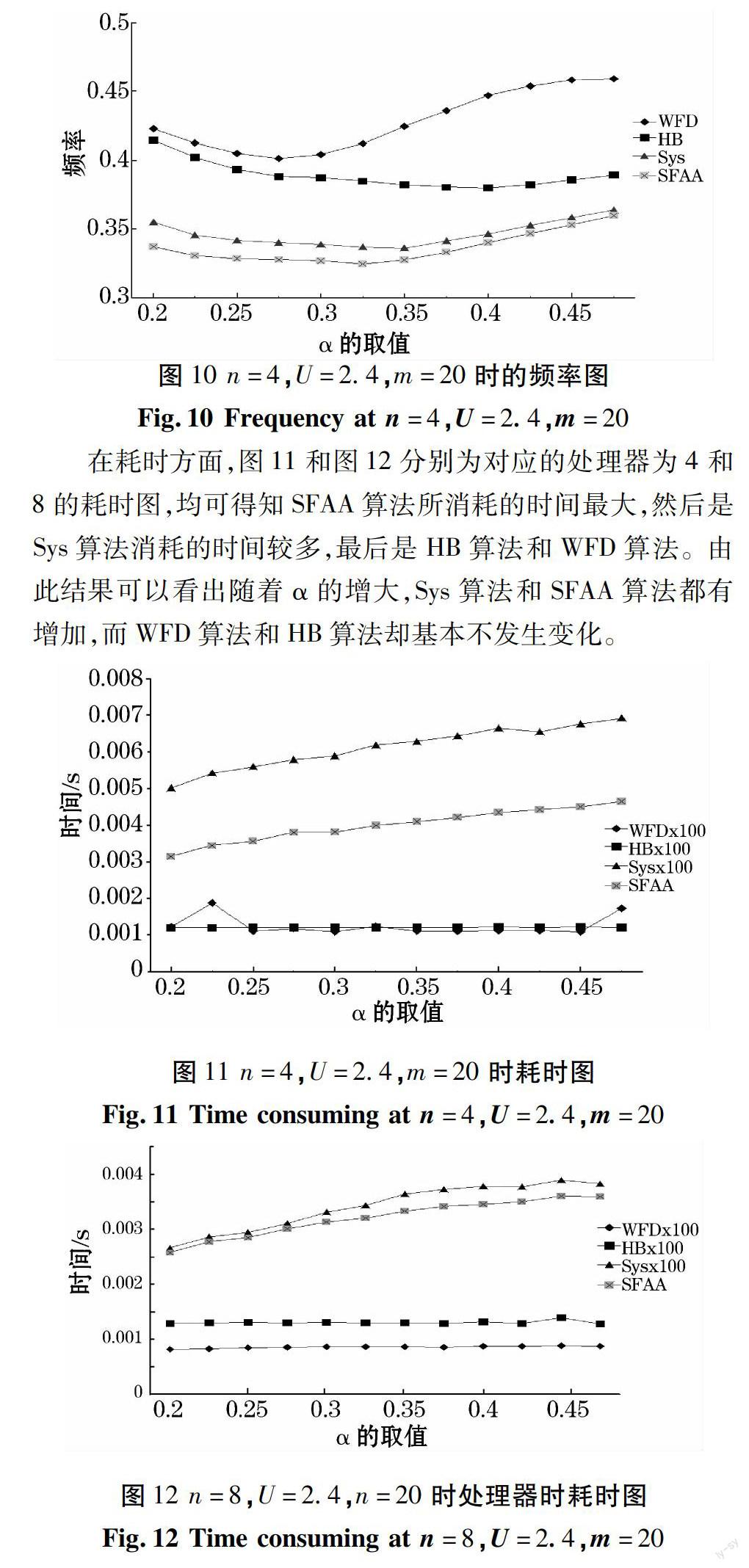
图9为任务集的利用率为2.4,任务数20,处理器的个数为4的频率图。随着α的增大,4种算法得到的频率有所减小。这是因为随着α的增大,任务集中的任务的利用率分布更稀疏。而图10即为任务集的利用率为2.4,任务数20,处理器的个数为8的频率图,可以看出随着α的增大,4种算法得到的频率都是先降后增。频率先降低是因为任务集中任务的利用率分布越来越稀疏,分到每个处理器上将更趋平均;后面升高却是因为有个别任务的利用率太大,导致其它的任务的利用率分布稠密。4核和8核处理器都可以得出:
。FWFD>FHB>FSys>FSFAA
图9 n=4,U=2.4,m=20时的频率图
Fig.9 Frequency at n=4,U=2.4,m=20
图10 n=4,U=2.4,m=20时的频率图
Fig.10 Frequency at n=4,U=2.4,m=20
在耗时方面,图11和图12分别为对应的处理器为4和8的耗时图,均可得知SFAA算法所消耗的时间最大,然后是Sys算法消耗的时间较多,最后是HB算法和WFD算法。由此结果可以看出随着α的增大,Sys算法和SFAA算法都有增加,而WFD算法和HB算法却基本不发生变化。
图11 n=4,U=2.4,m=20时耗时图
Fig.11 Time consuming at n=4,U=2.4,m=20
图12 n=8,U=2.4,n=20时处理器时耗时图
Fig.12 Time consuming at n=8,U=2.4,n=20
4结束语
本文针对SFAA算法及其它三种算法在多核平台下进行了能耗和时间的研究分析。通过研究发现,四种算法在节能方面均表现为SFAA算法优于Sys算法,Sys算法优于HB算法,HB算法优于WFD算法,在时间消耗方面则与上相反。在实时系统中,任务集的利用率越大,能耗就越大;任务集中的任务数对于能耗并无影响;任务集中的任务的利用率的分布,对于能耗却是有其具体影响的。相对于时间方面,任务集中的任务数越多,四种算法都是耗时越多;而随着任务集的利用率的增大,SFAA算法和Sys算法耗时减少,WFD算法和HB算法耗时不变;随着任务集中最大利用率的增长,SFAA算法和Sys算法耗时增加,而WFD算法和HB算法的耗时只是有所波动,但基本保持不变。
参考文献:
[1] YAO F, DEMERS A, SHENKER S. A schedling model for reduced cpu energy[C]// FOFS 95: Proceedings of the 36th Annual Symposium on Foundations of Computer Science, USA, Washington, DC:IEEE Computer Socitety, 1995:374 .
[2] IRANI S, SHUKLA S, GUPTA R. Algorithms for power saving s. ACM Trans[J]. Alorithms, 2007, 3(4):41.
[3] LEE Y, REDDY K P, KRISHNA C M. Scheduling techniques for reduing leakage power in hard real-time systems[C]// Euromicro Conference on Real-Time Systems , Portugal , Porto:IEEE , 2003 :105.
[4] JEJURIKA R, GUPTA R. Procrastination scheduling in fixed priority real-time systems[J]. SIGPLAN Not, 2004,39(7):57-66.
[5] ROWE A, LAKSHMANAN K, ZHU H, et al. Rate-harmonized scheduling for saving energy[C]// In RTSS08:Proceedings of the 2008 Real-Time Systems Symposium, USA, DC, Washton:IEEE Computer Socitety, 2008:113-122.
[6] KANDHALU A, KIM J. Engery-Aware partition fixed-priority scheduling for chip multi-processors[C]// 2011 IEEE 17th International Conference on Embedded and Real-Time Computing System and Applications, Japan T-oyama:IEEE, 2011,1:93-102
