基于SVDD的层次纠错输出编码研究
2015-05-25王晓丹宋亚飞
雷 蕾,王晓丹,罗 玺,宋亚飞
(1.空军工程大学防空反导学院,陕西西安710051;2.空军工程大学信息与导航学院,陕西西安710077)
基于SVDD的层次纠错输出编码研究
雷 蕾1,王晓丹1,罗 玺2,宋亚飞1
(1.空军工程大学防空反导学院,陕西西安710051;2.空军工程大学信息与导航学院,陕西西安710077)
纠错输出编码能有效地将多类问题分解为一系列二类子问题进行求解,已受到众多机器学习研究者的关注。如何构建基于数据的编码矩阵是编码方法确定的关键。针对此问题,基于Fisher原理,提出一种基于支持向量数据描述(support vector domain description,SVDD)的层次纠错输出编码构造方法(hierarchical error-correcting output codes,HECOC)。该方法首先采用SVDD计算各类别的可分程度,从而得到由不同子类构成的二叉树;然后分别对二叉树的各层结点进行编码并最终形成层次输出编码。在仿真实验中,对不同子类类群划分构成的基分类器的可分性进行了对比,结果表明,该编码方法能在保证分类精度的同时,提高基分类器之间的差异性和纠错输出编码的容错能力。
多类分类;纠错输出编码;类间可分性;支持向量数据描述
0 引 言
多类分类是模式识别领域的研究重点和难点。纠错输出编码(error-correcting output codes,ECOC)[1]作为一种分而治之的多类解决方案,将复杂的多类问题分解为多个简单的二类分类任务;同时继承纠错码特有的纠错能力,使得利用一定的解码规则能对由二类分类器产生的错误具有一定的纠错能力。而编码矩阵的构造作为完成ECOC多类分类的第一步,已受到众多学者的关注和研究[2-5]。目前主要的编码方法有:事前编码、基于样本数据编码(也称基于问题域编码)和基于基分类器编码[6]。事前编码是指编码不依赖样本的编码方法,因此,所得到的编码矩阵不能反映分类信息,这在实际应用中将影响此类编码的应用效果。基于基分类器编码,即基分类器已选定,如何找出与基分类器最优搭配的编码矩阵。早在2002年,Crammer和Singe经过理论分析得出此类编码问题是NP难问题[6]。而基于数据的编码矩阵能充分利用训练样本数据本身包含的类别信息,从而提升分类效果。目前在此方面的研究有:判别式编码方法[7](discriminate error-correcting output codes,DECOC)、子类编码方法[8](subclass error-correcting output codes,SECOC)等。2013年,为保证基分类器之间的独立性,文献[9]提出子空间ECOC编码方法(subspace ECOC),利用不同的特征子集训练基分类器。文献[10]针对经典的“一对一”三符号编码矩阵中符号“0”会引入分类偏差的问题,利用训练样本分类结果对编码矩阵中的码字“0”进行再编码,并将该分类结果作为权值融入到基于损失函数的解码过程中,基于人脸数据的实验表明,该方法能提高基于传统一对一和稀疏编码矩阵的ECOC分类性能。文献[11]提出利用编码矩阵中二类划分的先验原始类结构信息可以提高ECOC分类性能,并给出了在流形假设和聚类假设的情况下将先验结构信息融入基分类器决策函数的方法。文献[12-13]把编码矩阵的构造问题转化为一个搜索问题并得到包含训练样本数据信息的编码方法和基于混淆矩阵的自适应编码方法。
本文针对如何构造基于数据样本的编码矩阵问题,提出了一种基于支持向量数据描述(support vector domain description,SVDD)的层次纠错输出编码构造方法(hierarchical error-correcting output codes,HECOC)。该方法基于Fisher准则,首先利用SVDD获得类间可分性度量,并根据依此度量形成的二叉树获得最优子类划分;然后自上而下对二叉树每层结点进行编码并最终获得所需的编码矩阵。
本文首先简要介绍基于ECOC进行多类分类的原理和HECOC的基本思想;然后提出一种基于SVDD的层次矩阵编码方法,利用SVDD作为类别可分性度量准则,找出最优类别组合并据此构建层次编码输出;最后给出实验结果和分析。
1 基于SVDD编码的思想
模式识别中经典的Fisher准则函数:

指出,当同类别数据样本密集紧凑,不同类别数据样本分散时,就能得到优秀的分类效果。因此两类样本均值之差越大越好,而类内离散度越小越好。此时分类样本具有最大的类间距离和最小的类内距离,最容易被区分,即具有最佳的分类效果。ECOC编码的本质是如何进行最优二类划分,尽可能地减少分类的复杂性。因此,在基于数据的编码矩阵构造当中,其目的就是依据Fisher准则来尽可能地获得最优的子类划分,这些子类之间相关性较小,易于分类;相关性较大的原始类别将被分为同一子类。基于此类划分构造的基分类器分类的难度最小,能达到较高准确率,从而实现分类效果的整体提高[8,13]。
因此,如何根据Fisher准则来获得最佳的子类划分成为本文方法的关键。基于特征空间几何距离的方法对样本数据的充分性和样本分布的先验知识要求不高,可以较快地进行子类划分,所以本文采用基于特征空间几何距离的方法。而ECOC子类划分本身就潜在地将样本划分得不平衡,从而导致正负类样本数量上的差异。而基于距离测度的SVDD的学习过程仅仅需要“目标类”样本,与非目标类关系不大,很好地解决了分类中样本不足或者难以获得非目标样本带来的学习问题[14]。本文采用SVDD作为可分性度量准则,第2节将进行理论介绍。
2 基于SVDD的HECOC
本节利用SVDD作为类别划分度量,从而获得最优子类类群划分。然后根据子类划分自下而上构建二叉树,对二叉树的每层结点进行编码,得到最终的层次编码矩阵。
2.1 SVDD
SVDD是Tax于1999年首次提出的[15-16],其目的是在高维空间中构造一个超球体S,使得该超球体能最大限度地覆盖所有数据样本。描述如下:

式中,o为中心;r为半径。最小覆盖球可以通过求解该二次优化问题得到。文献[16]提出了采用核函数的思想来得到更为紧凑的优化区域。同时很多文献引入了松弛变量ξi,使得问题变为
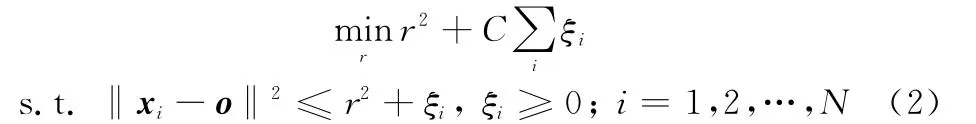
这是为了允许有少数样本不在超球体内。其中,C>0是一个惩罚因子,其作用是在最小覆盖球半径的r大小和可能落在球体外的样本数量之间保持平衡。采用Lagrange乘子,将问题转化为对偶问题:

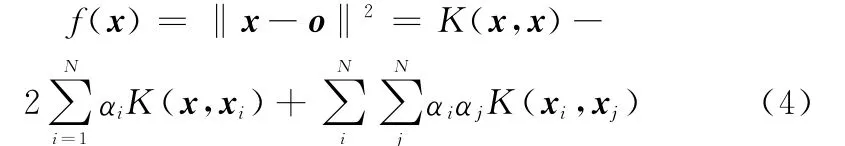
当它到超球体中心的距离满足小于或等于r时,即‖x-o‖2≤r2,则未知样本被判为目标类,否则为非目标类。
2.2 基于SVDD的可分性度量
假设对于k类分类问题,训练样本集{X1,X2,…,Xk},Xi={x1,x2,…,xNi},i=1,…,k。采用核函数,分别用每类的训练样本构造SVDD超球面,得到球面集合:S={S1,S2,…,Sk}={(r1,o1),(r2,o2),…,(rk,ok)},其中(ri,oi)表示第i个超球面的半径和球心。然后计算各类的训练样本到各类的超球面的距离,构成如下矩阵:
解该优化问题可得到αi,其中使0<αi≤C的样本点被称为支持向量。
对于未知样本x而言,设
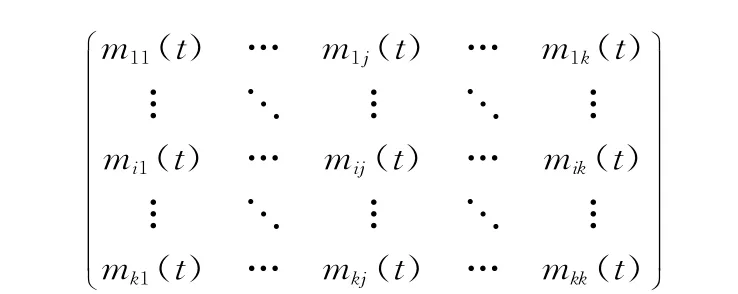
式中,mij(t)为第i类训练样本中到第j类超球面距离小于t的样本个数。文献[17]用mij(t)来表示两类的相交程度。因为在构造各个类的SVDD超球面时,适当允许个别样本落在球体外,超球面不一定能覆盖所有样本。所以用mij(t)来表示可分程度不一定准确。因此本文用两个超球体的球心距离作为类可分性的判据:
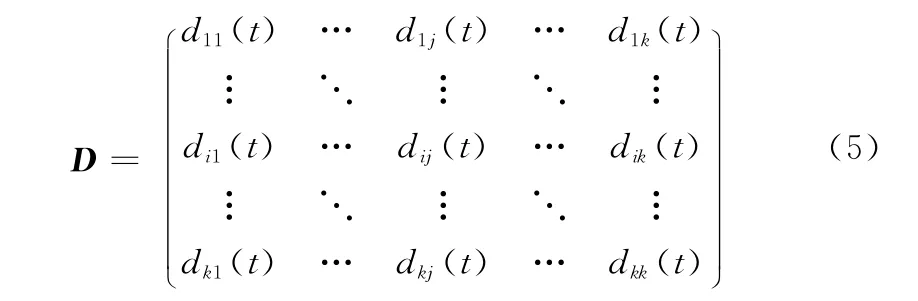
式中
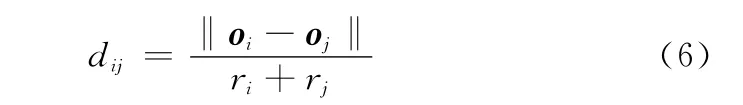
由式(6)得到的可分性度量矩阵D有两个性质:①对称性,即dij=dji;②对角线元素为0。当dij≥1说明对应的两类在特征空间没有交集,不相交,dij越大,两类的分离程度越好。0<dij<1时两类在该距离定义上相交,值越小,两类相交程度越高,即可分性越差,在识别过程中就容易发生误判。当dij=0时,则说明两个超球体在特征空间中完全重叠。
2.3 基于SVDD的层次编码矩阵构造
构造层次编码矩阵的重点是对多类根据类间可分性进行划分。其步骤如下:首先,将每个类视为一个子类类群,然后利用式(6)计算类间可分性度量矩阵D,将最不容易区分的两个子类,即dij的最小值所对应的两类(同类间的距离度量值dii排除)合并成一个子类,再计算该重组子类和剩余其他类之间的可分性度量矩阵,将相交程度最高两个子类进行合并,一直到所有子类合并成一个类。对于一个k类问题,这样就构成了一个倒立的二叉树T。接下来利用该二叉树的每个节点(除去叶子节点和父节点)对不同子类进行编码:
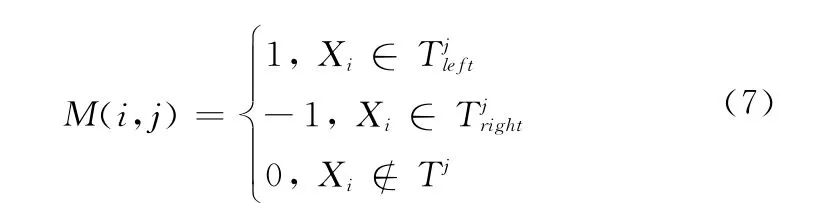
式中,M(i,j)表示编码矩阵的第i行第j列码字;对于二叉树的第j层结点(除去父节点),和分别为其左右树枝,当类别Xi属于或时,其在编码矩阵中对应的码字为“1”或“-1”;当类别Xi都不属于这一层结点时,其对应的编码为“0”。
假设有5类数据,如图1所示。SVDD的核函数采用高斯核函数,通过交叉验证法选择其参数为C=3.56,σ=1.02。
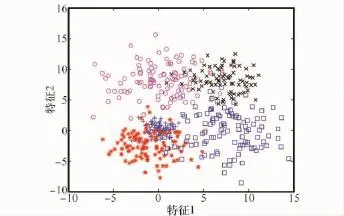
图1 5类高斯分布样本数据
根据式(6)得到类可分性度量矩阵D1,如表1所示。
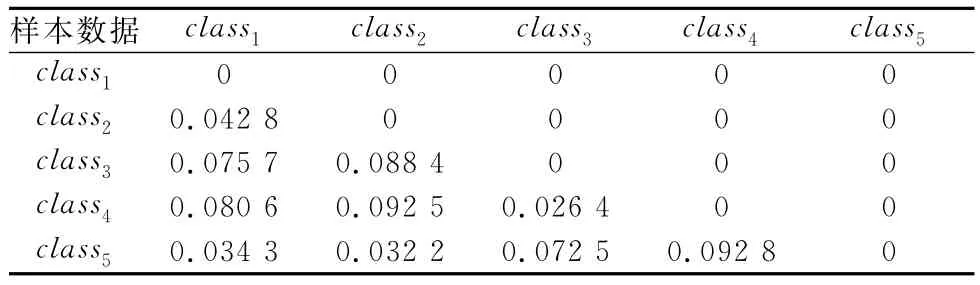
表1 5类样本数据的可分性度量矩阵
由类可分性度量矩阵可以看到,类间距离0.026 4最小,将class3和class4合并为一个新类,记为subgroup1={class3,class4},此时类的总数减少1。再利用SVDD,按照式(6)计算新类和其他类的距离,得到新的可分性度量矩阵。依次类推,可以得到如图2所示的二叉树。

图2 5类数据的层次二叉树
自下而上得到二叉树后,利用式(7)对其进行编码,得到最终的层次输出编码矩阵为
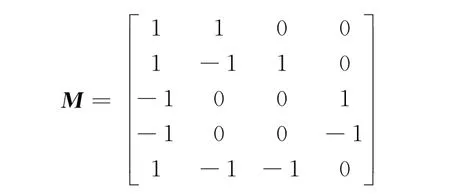
3 实 验
本节采用UCI数据集来验证本文方法的分类效果。
3.1 实验数据
实验中所用的UCI数据集如表2所示。
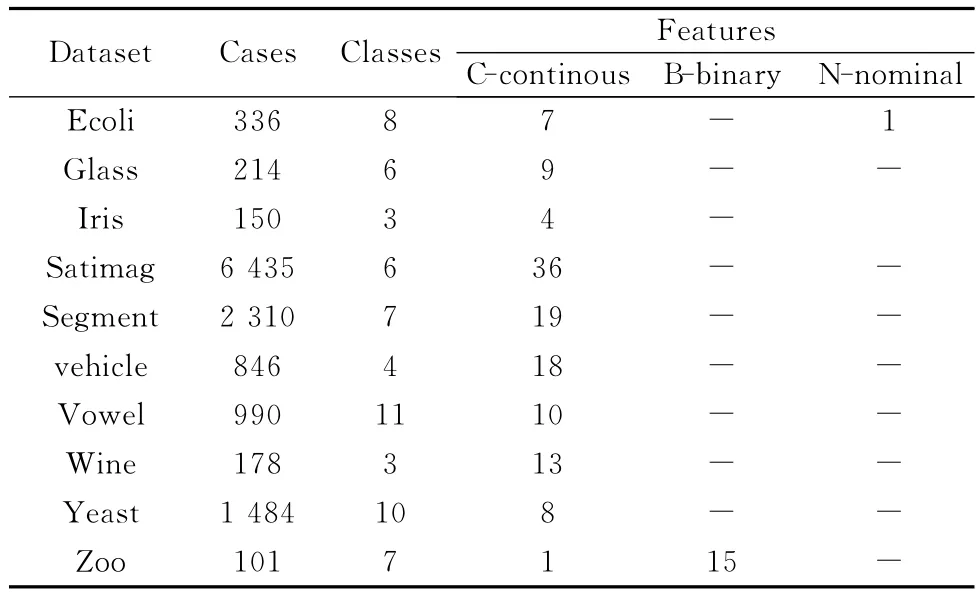
表2 UCI数据集及数据描述
3.2 实验设计
首先,基于UCI公共数据集对基于SVDD的层次编码矩阵与几种经典的编码方法:一对一编码(one-versusone)、一对多编码(one-versus-all)、密集随机编码(dense random)、稀疏随机编码(sparse random)、判别式编码(DECOC)以及子类编码(SECOC)在不同解码策略下的分类效果。两种随机编码方法的选择按照文献[13]进行。实验中采用的两种解码策略为:Hamming距离解码和欧式距离解码;两种基分类器为:线性逻辑分类器(linear logic classifier,LOGLC)和支持向量机(多项式核函数,C=2)。
接着,对经典编码方法与本文方法进行编码长度比较,讨论编码的有效性和纠错能力。最后探讨在不同编码方式下,训练得到的基分类器的独立性。
利用双边估计t检验法来计算置信水平为0.95的分类错误率置信区间作为最终结果,计算公式如下:
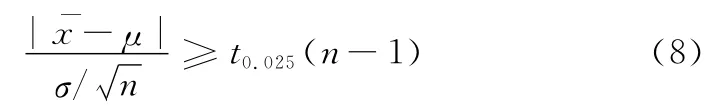
式中,μ、σ分别表示n重交叉验证的均值和标准差;t0.025(4)=2.776 4;t0.025(9)=2.262 2。
3.3 实验结果及分析
3.3.1 分类结果比较
表3和表4列出了当基分类器采用SVM时,基于SVDD的编码方法HECOC与经典编码方法的分类结果比较。在每张表中加粗的数据为最大分类正确率,分类正确率下方为编码长度。
从表中的结果可以看出,在大部分情况下,基于HECOC编码方法的分类精度要优于其他经典的事前编码或部分基于数据编码方法。同时,HECOC编码矩阵长度也占有优势。这是因为从初始数据集开始,进行了类间可分性比较,在获得可分性矩阵的前提下,对二叉树从上至下进行了编码,使得对于N类样本数据,其编码矩阵为N×(N-1),这与DECOC编码的码字长度类似,但分类精度表现更好;同时针对其他的编码方法,尤其是事前编码,HECOC不仅能在促进多类分类的实际效果的情况下,提高了编码的纠错性能,而且能获得更加紧凑的编码,大大缩减了训练和测试时间,提高了编码解码的速度。
3.3.2 基分类器差异性比较
为进一步总结本文方法优势,本文从统计学的角度采用Yule的Q统计量[18]对基分类器之间的差异性进行比较。
对于分类器Ci和Cq,两者之间的Q统计量可表示为

式中,Nab的含义如表5所示。
从式(9)可以看出,对于识别同一类别的基分类器,其Q统计量的值为正,否则为负;相互独立的基分类器,其Q值为零。对于L个基分类器,可以用平均值来衡量,即

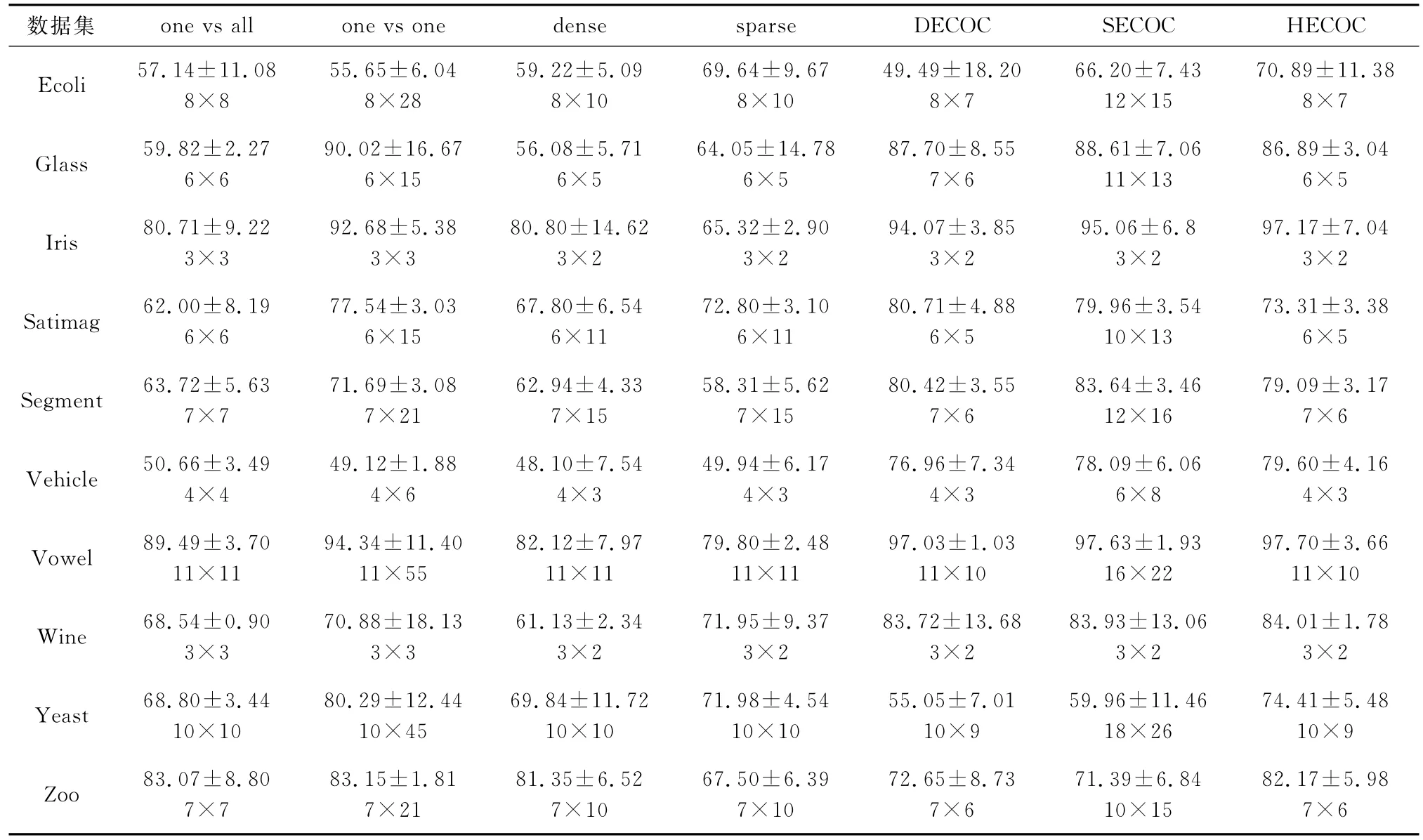
表3 基于SVM和Hamming距离解码的各数据集分类正确率及置信区间为0.95的置信区间 %
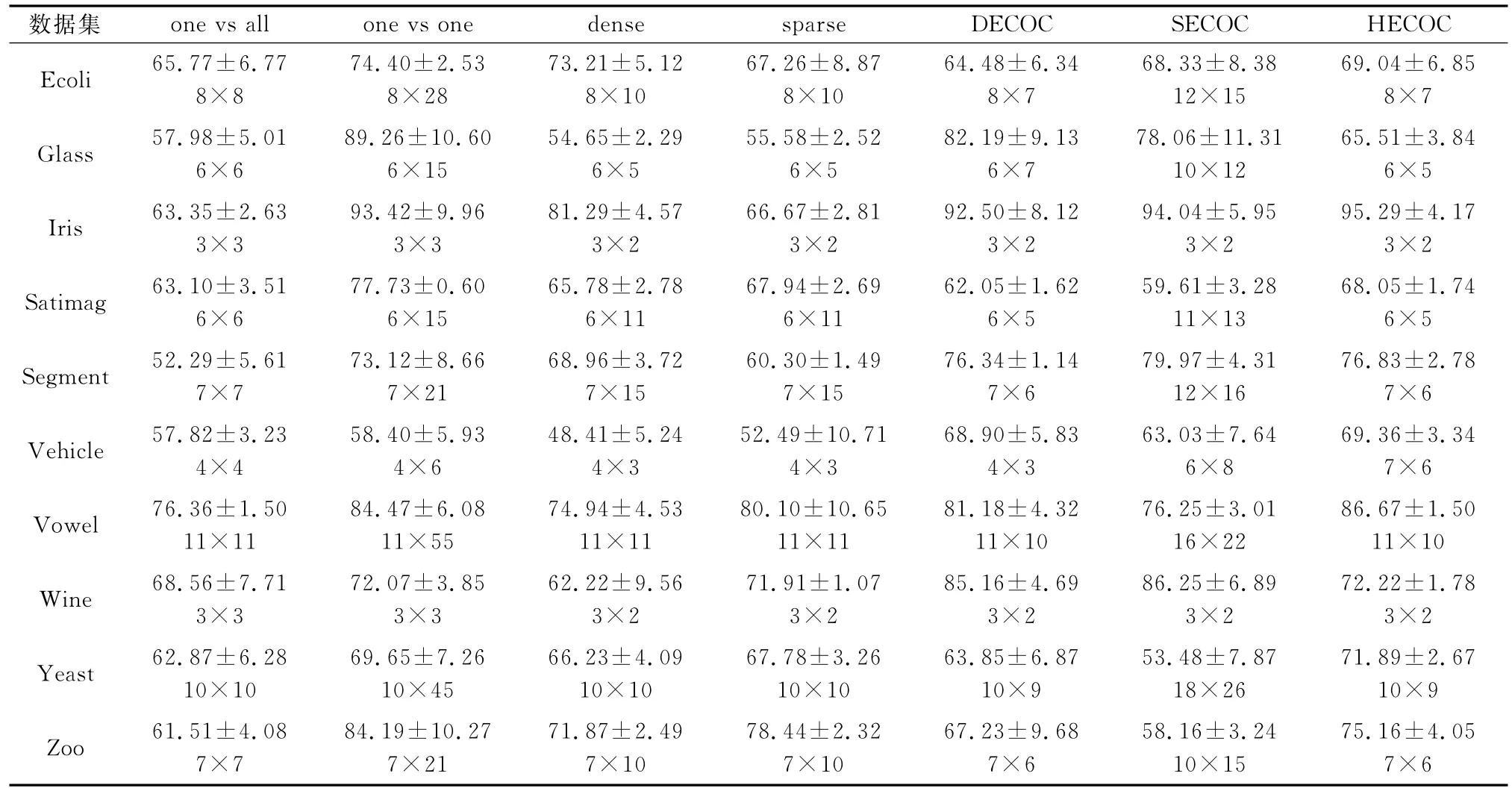
表4 基于SVM和欧式距离解码的各数据集分类正确率及置信区间为0.95的置信区间 %

表5 Nab的含义
表6和表7给出了在所有数据集上的基分类器差异性比较的结果,第一行是每种方法在所有数据集上的平均值。其中“s”表示wintieloss统计量,即col<row,col=row和col>row的数据集个数。
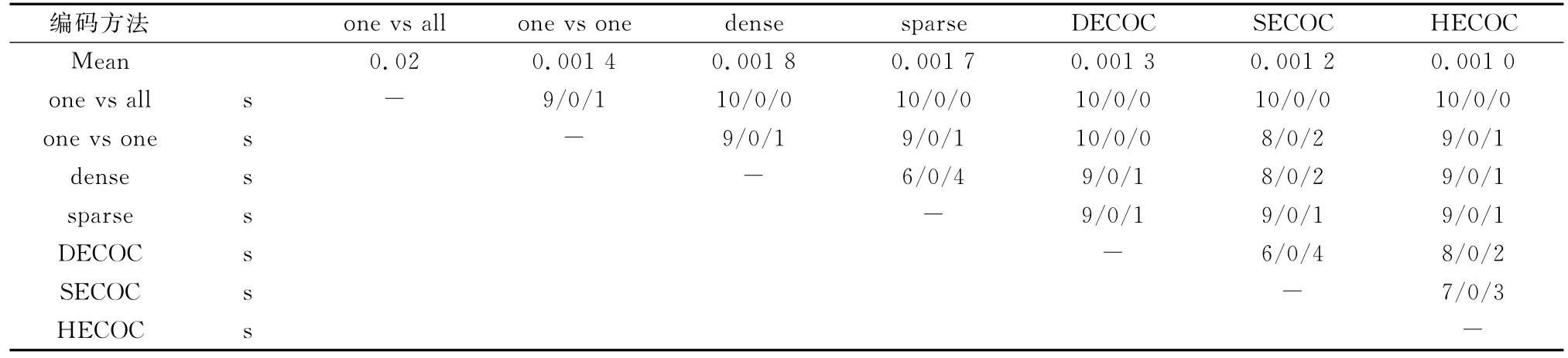
表6 基于SVM的各个数据集上差异性比较
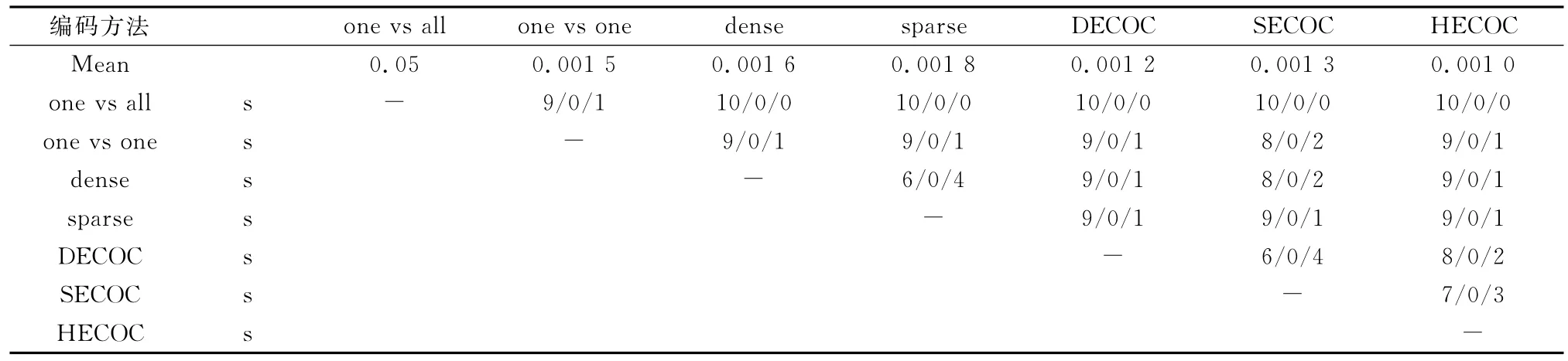
表7 基于LOGLC的各个数据集上差异性比较
从表中的实验结果可以看出,基于HECOC编码方法训练得到的不同基分类器都具有最大的差异性。7种方法中基分类器差异性由好到差的排列为HECOC、SECOC、DECOC、one-vs-one、dense/sparse、one-vs-all。由前面的分析可得,基于数据的编码矩阵能使子类的可分性最佳,因此,训练不同子类数据得到的基分类器之间的差异性也就应该更明显。
4 结 论
在基于ECOC的多类分类中,如何快速有效地构造基于样本数据的编码是目前研究的重点。本文从Fisher判据出发利用SVDD构造类可分性准则,基于该准则找出最相似的两类进行合并,从而使相关性较大的子类划分在一起,依此类推,直到所有子类合并为一个类。然后从上至下建立二叉树,对二叉树的每层结点进行编码,从而获得最终的层次纠错输出编码。利用公共数据集对其验证发现HECOC在有效提高多类分类准确率的同时,能提高基分类器之间的差异性。这也是因为在编码矩阵构造时对相似度高的子类进行了合并,将相似度低的子类划分开来,确保了训练得到的基分类器差异性,同时提高分类精度。
[1]Dietterich T G,Bakiri G.Solving multi-class learning problems via error-correcting output codes[J].Journal of Artificial Intelligence Research,1995,34(2):263-286.
[2]Bagheri M A,Qigang G,Escaler S.A genetic-based subspace analysis method for improving error-correcting output coding[J].Pattern Recognition,2013,46(5):2830-2839.
[3]Miguel A B,Escaler S,Xavier B,et al.On the design of an ECOC-compliant genetic algorithm[J].Pattern Recognition,2014,47(8):865-884.
[4]Escaler S,David M.Online error correcting output codes[J].Pattern Recognition Letters,2011,32(1):458-467.
[5]Bouzas D,Arvanitopoulos N,Anastasios T.Optimizing linear discriminant error correcting output codes using particle swarm optimization[J].Lecture Notes in Computer Science,2011,6792(4):79-86.
[6]Crammer K,Singer Y.On the learnability and design of output codes for multiclass problems[C]∥Proc.of the 13th Annual Conference on Computational Learning Theory,2000:896-909.
[7]Pujol O,Radeva P,Vitria J.Discriminate ECOC:a heuristic method for application dependent design of error correcting output codes[J].IEEE Trans.on Pattern Analysis and Machine Intelligence,2006,28(6):1001-1007.
[8]Escalera S,David M J Tax,Pujol O,et al.Subclass problemdependent design for error-correcting output codes[J].IEEE Trans.on Pattern Analysis and Machine Intelligence,2008,30(6):1041-1054.
[9]Bagheri M A,Montazer G A.A subspace approach to error correcting output codes[J].Pattern Recognition Letters,2013,34(1):176-184.
[10]Escalera S,Pujol O.Re-coding ECOCs without re-training[J].Pattern Recognition Letters,2013,31(5):555-562.
[11]Wang Y Y,Chen S C,Xue H.Can under-exploited structure of original-classes help ECOC-based multi-class classification[J].Eeurocomputing,2012,89(15):158-167.
[12]Zhou J D,Wang X D.Coding design for error correcting output codes based on perception[J].Optical Engineering,2012,51(5):322-331.
[13]Zhou J D,Wang X D,Zhou H J.Multiclass classification of adaptive error-correcting output codes based on confusion matrix[J].Systems Engineering and Electronics,2012,34(7):1518-1524.(周进登,王晓丹,周红建.基于混淆矩阵的自适应纠错输出编码多类分类方法[J].系统工程与电子技术,2012,34(7):1518-1524.)
[14]Zhu X K,Yang D G.Multi-class support vector domain description for pattern recognition based on a measure of expansibility[J].Acta Electronica Sinica,2009,37(3):464-469.(朱孝开,杨德贵.基于推广能力测度的多类SVDD模式识别方法[J].电子学报,2009,37(3):464-469.)
[15]Tao Q,Luo Q.Coordinate descent algorithms for large-scale SVDD[J].Pattern Recognition and Artificial Intelligence,2012,25(6):950-957.(陶卿,罗强.大规模SVDD的坐标下降算法[J].模式识别与人工智能,2012,25(6):950-957.)
[16]Wang X F,Zhang J P,Zhang Y.Unmixing algorithm of hyperspectral images[J].Journal of Infrared Millimeter Waves,2012,29(3):210-215.(王晓飞,张钧萍,张晔.高光谱图像混合像元分解算法[J].红外与毫米波学报,2012,29(3):210-215.)
[17]Liu Z G,Li D R.Hierarchical multi-category support vector machines based inter-class separability in feature space[J].Geomatics and Information Science of Wuhan University,2004,29(4):324-328.(刘志刚,李德仁.基于特征空间中类间可分性的层次性多类支持向量机[J].武汉大学学报(信息科学版),2004,29(4):324-328.)
[18]Garcia P N,Ortiz-Boyer D.An empirical study of binary classifier fusion methods for multi-class classification[J].Information Fusion,2011,12(9):111-130.
Hierarchical error-correcting output codes based on SVDD
LEI Lei1,WANG Xiao-dan1,LUO Xi2,SONG Ya-fei1
(1.Air and Missile Defense Institute,Air Force Engineering University,Xi’an 710051,China;2.Information and Navigation Institute,Air Force Engineering University,Xi’an 710077,China)
As a decomposing framework,error-correcting output codes(ECOC)can effectively reduce the multiclass to the binary and attract much attention,in which the construction of coding matrix based on data is the key to use ECOC to solve multiclass problems.An approach of hierarchical error-correcting output codes(HECOC)based on support vector domain description(SVDD)and Fisher theory is presented.Firstly,the SVDD is used to measure the class separabilty quantitatively.Then the inter-class separability matrix is got gradually.The binary tree is built based on the matrixes from the bottom to the top.Then,each node of the binary tree is encoded by the level to get the final HECOC.The separability of base classifiers trained by different class partition is compared in experiments.The results show that the HECOC can promote the diversity of the base classifiers and the error-correcting ability of codewords as well as enhance the classification accuracy.
multi-classification;error-correcting output codes(ECOC);class separability;support vector domain description(SVDD)
TP 391
A
10.3969/j.issn.1001-506X.2015.08.30
雷 蕾(1988-),女,博士研究生,主要研究方向为目标识别、智能信息处理。
E-mail:wendyandpaopao@163.com
王晓丹(1966-),女,教授,博士,主要研究方向为智能信息处理、机器学习。
E-mail:21776496@qq.com
罗 玺(1988-),男,硕士,主要研究方向为智能信息处理。
E-mail:wendyandpaopao2@163.com
宋亚飞(1988-),男,博士研究生,主要研究方向为数据融合、目标识别。
E-mail:yafei_song@163.com
1001-506X201508-1916-06
网址:www.sys-ele.com
2014-01-06;
2014-09-24;网络优先出版日期:2015-01-20。
网络优先出版地址:http://www.cnki.net/kcms/detail/11.2422.TN.20150120.1050.007.html
国家自然科学基金(60975026,61273275)资助课题
