馆藏资源本体模型的语义相似度算法研究*
2015-05-10邱均平
邱均平 ,许 畅
(1.武汉大学中国科学评价研究中心,湖北 武汉 430072;2.武汉大学信息管理学院,湖北 武汉 430072)
1 前言
1.1 馆藏资源本体概述
起源于哲学的本体论(ontology),近年来受到了信息科学领域的广泛关注,本体的重要性也已在许多方面表现出来,并得到了广泛的认同。现今本体被细分为知识表示本体、通用本体、领域本体、术语本体、任务本体等类型[1]。按照学科层次逐层构建本体的方法被广泛应用。国内已在医学、农学、地理学、工学、军事、经济学、教育学等学科成功构建了大型本体。但是这种层次明显的本体划分方法很难适用于人文社科类的本体构建。特别是随着图书馆馆藏资源的数字化,对多领域、多语言异构的信息进行高效开发利用的需求日益增长,单纯划分学科层次的方法很难适用。在文献[2]中,邱均平和余凡结合语义网相关技术和计量学相关分析方法,构建了馆藏资源语义化的理论模型,并在模型中首次使用了资源本体的概念,之所以没有使用领域本体这个词,是因为两者存在差异:领域本体会把范围限制在某一个领域,资源本体的数据没有领域之分,包括所有学科馆藏资源的元数据。文中借用本体的定义,把资源本体定义为馆藏资源共享概念模型的明确的形式化规范说明。由此,诞生了一种新的基于概念间的关系本体方案——资源本体。资源本体是以语义的基本理论为基础,引入信息计量领域的相关分析方法,对语义体系进行扩展,进一步构建而成的基于资源特征本身的本体,是馆藏资源共享概念模型及关系明确的形式化规范说明[3]。资源本体除了具有本体本身的特点之外,还具有其特殊的含义。首先,现今阶段资源本体的研究对象是“馆藏资源”;其次,资源本体的相关概念及其关系的定义使用的是信息计量的相关方法。在资源本体模型中,更加强调概念与概念之间的语义关系。传统本体的相似度计算方法多从属性、结构等方面因素考虑,缺乏对语义特征、距离、层次的综合考虑以及对相似度算法准确性和高适用性的优化。因此本文综合上述因素,对适用于馆藏资源本体模型特点的语义相似度算法进行进一步的研究。
1.2 几种常用的相似度算法
1.2.1 基于距离的语义相似度计算
基于距离的语义相似度计算的基本思想是通过两个概念词在本体树状分类体系中的路径长度量化它们之间的语义距离[4]。其中,最简单的算法就是把本体中的所有路径都看成距离为1的有向边,这样两个概念的距离就为它们所对应的节点在本体结构中的最短距离的有向边数量。由此,基于距离的语义相似度算法为[5]:

其中,H为该本体的最大深度,L为概念w1和概念w2之间的有向边数量。
这种算法能够简单地反映出两个概念的距离大小。若距离越近,则他们的语义相似度越大;反之,则越小。
1.2.2 基于内容的语义相似度计算
基于内容的语义相似度计算方法的基本原理是:两个概念词共享的信息越多,它们之间的语义相似度越大;反之,共享的信息越少,相似度也越小[6]。在一个本体中,每个概念子节点都可以被认为是对其祖先节点的细化,因此,概念间的语义相似度能够通过比较与之最近的父节点所包含的信息内容来进行计算。
文献[6]给出了关于层次网络中量化每一个概念结点信息量的计算公式:
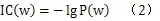

其中,P(w)表示概念w在训练资料中出现的概率;IC(w)表示概念w所拥有的信息量。
这样,依据上面概念信息的量化公式,层次网络中任意两个概念之间的语义相似度计算模型为[7]:

其中Anc(w1,w2)表示概念结点w1和w2在层次网络中的最近共同祖先结点。
1.2.3 基于属性的语义相似度计算
事物之间的关联程度和其属性是相关的。如果两个事物的很多属性相同,则它们是很相似的;反之,则不相似。基于属性的语义相似度计算方法就是通过判断两个概念的公共属性项的相似程度。

Tversky提出了一种基于属性的计算概念语义相似度的方法[8]:其中,w1∩w2表示概念w1和w2所共同拥有的属性集,w1-w2表示概念w1拥有而概念w2没有的属性集,w2-w1表示概念w2拥有而概念w1没有的属性集。
2 馆藏资源本体中语义相似度计算
2.1 相似度计算的原则
在进行相似度计算时,为了使结果更加准确,应遵循几个基本的原则。首先是量化原则,相似度是一个数值,取值范围应在[0,1]之间。其次,在计算相似度时,应尽量降低运算的复杂度,保证简单性原则。再次,应充分利用本体的特征,本文主要讨论的是馆藏资源本体中的相似度计算,应考虑馆藏资源的相关特性。除此之外,由于概念的相似度计算主观性很强,因此对于不同的概念类型,其相似度也不同,可通过设定某些参数,来保证相似度计算的可调节性。最后,概念的相似度计算应保证对称性,即Sim(w1,w2)=Sim(w2,w1)。
2.2 影响相似度的因素
根据上述的基本原则,可以进一步归纳出馆藏资源本体中相似度计算应该考虑的几个因素:
1)语义共现。共现指的是相同或不同类型特征共同出现的现象。例如多篇论文之间共同出现的主题、共同出现的合作者、共同出现的机构以及作者与期刊共同出现、作者与关键词共同出现、论文与关键词共同出现等。在计量研究中,共同出现的特征项之间一定存在着某种关联,关联的程度可以通过共现频次来测度。在馆藏资源本体中,每一个类目下的实例都有可能和同类目下或者其他类目下的实例形成语义共现。例如,w1、w2、w3同属于作者类,经过相关数据的处理,得到w1和w2这两位作者共同出现的次数为5,w1和w3这两位作者共同出现的次数为2,则w1∩w2=5,w1∩w3=2。可以看出,作者共现的频次越大,两位作者的语义相似度也越大,因此w1与w2之间的相似度,大于其与w3之间的相似度。
2)语义距离。两个概念之间的语义距离,是指在本体图中连接这二个节点的通路中的最短路径所跨的边数[9]。语义距离是决定相似度的另一个基本的因素。上文中也对基于距离的语义相似度计算方法进行了简单的介绍。一般来说,两个概念的距离越小,相似度越大;距离越大,相似度越小。这两个概念能通过距离的大小建立对应关系。需要注意的是,两个词语的距离为0时,相似度应为1。同样,它们的距离为无穷大时,相似度为0。在这里我们举一个简单的例子:如图1所示,w5和w10的距离可记为Distance(w5,w10)=5。在馆藏资源本体中,同类目下的实例之间的距离比不同的类目下的实例之间的距离要小,语义相似度更高。比如在某个馆藏资源本题中,两个作者之间的语义距离要小于某个作者与某种期刊的语义距离,作者之间的相似度也更高。
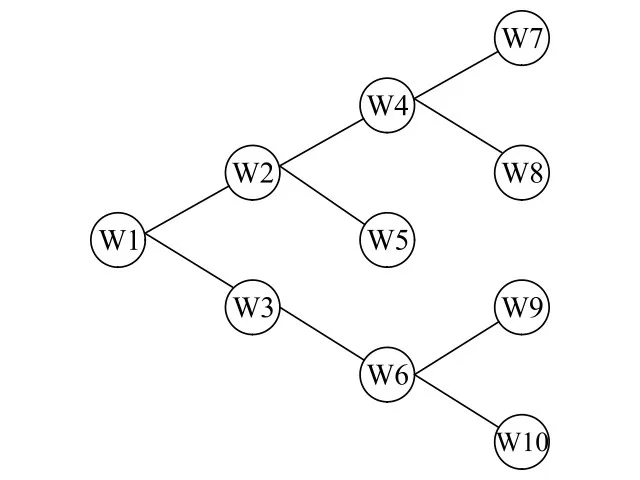
图1一个简单的本体
3)概念层次。在一个本体中,层次越深,对应的节点也就更加的细分和具体化。同样距离的两个词语,词语相似度随着他们所处层次的总和的增加而增加,随着他们之间层次差的增加而减小[10]。例如,图1中w7和w8之间的语义相似度,要高于w4与w5之间的语义相似度。因此,在计算馆藏资源本体中的语义相似度时,必须要考虑概念的层次深度这个因素。
4)调节因子。调节因子是指根据系统的需求,通过它来判定概念所在本体中各种影响因素,从而确定概念之间的相似度。上文已经论述过,在进行语义相似度计算时,需要保证可调节性原则。调节因子正是根据这种需要来设定。本文中,使用α、β、γ来表示调节因子。在计算语义相似度时,可以通过调节α、β、
第45卷 第3期 总第187期·2015年5月γ的值来确定所需要的结果,提高相似度数据的准确性。
2.3 馆藏资源本体中语义相似度计算的方法
综合考虑以上因素,提出馆藏资源本体中语义相似度计算方法,初始公式为:
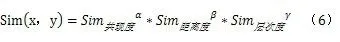
其中,Sim共现度(x,y)为概念x和y的语义共现度;Sim距离度(x,y)为概念x与y的语义距离度;Sim层次度(x,y)为概念 x与 y的概念层次度。α、β、γ 为调节因子,且 α+β+γ=1。
由于共现度的计算和两个概念的共同属性是相关的,所以我们可以采用Tversky提出的基于属性的语义相似度计算方法公式(5)来计算共现度。我们将参数进行简化,若α=β=l,则Tversky指数则成为Tanimoto系数;若α=β=0.5,则Tversky指数则成为Dice系数[3]。由于在馆藏资源本体中概念词之间的关系是可逆的,具有对称性,所以取α=β=0.5,即Dice系数,公式为:
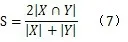
在信息检索中,给定关键词集合X和Y,相似度定义为两倍的共同信息(重叠部分)除以基数的总和[11]。根据这个概念,我们可以推导出概念x和y的共现度公式为:
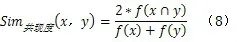
在馆藏资源本体中,同一类目下的实例间的语义距离均为1,不同的类目下的实例间语义距离为大于1的整数,我们可以简单地将两个概念间的距离度记为:

两个概念的层次差可以用作计算层次度,可得层次度公式:
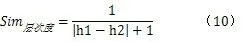
综上所述,可得出馆藏资源本体中语义相似度公式为:
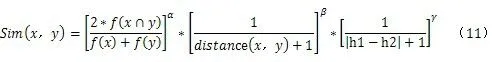
其中,α、β、γ为调节因子,且α+β+γ=1,其各项取值大小视各因素对语义相似度影响大小而定。
2.4 馆藏资源本体中语义相似度计算的流程
通过上述相似度方法的相关分析,馆藏资源本题中语义相似度计算的流程为:1)初始化概念,并设定调节因子数值;2)计算概念间的共现度;3)计算概念间的距离度;4)计算概念间的层次度;5)计算概念间的相似度;6)得出结果并按需求进行下一步处理。
3 实例分析——以竞争情报资源本体为例
期刊资源是馆藏资源的代表,并包含作者合作、共被引文献、关键词共现等计量关系,因此笔者以期刊资源为研究对象,并在CSSCI上获取近十年的期刊数据,进行处理后,利用本体开发软件Protégé构建了以竞争情报为范畴的馆藏资源本体。竞争情报资源本体的类目体系如图2所示。
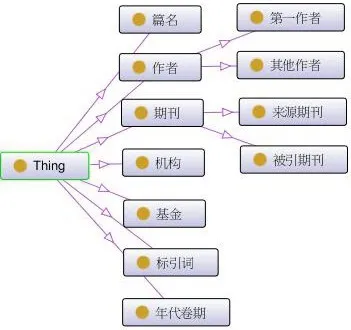
图2竞争情报资源本体类目体系
我们以标引词、作者和机构三个类目下的实例为分析对象,分别用文献[3]中的传统算法和本文算法对同一类目以及不同类目下的实例进行语义相似度的计算实验。首先计算同一类目的标引词之间的相似度,需要确定调节因子的数值。由于标引词之间的关系主要取决于词语的属性,也就是词语共现的情况,语义距离和语义层次对其的影响比较小。又α、β、γ为小数次方,所以影响越大的因素其对应的数值应越小。因此,参考二八原则,取α=0.2,β=γ=0.4,来进行计算。其次计算不同类目下标引词与作者、机构之间的相似度。由于计算的是不同类目下实例的相似度,三个因素的影响比较均衡,因此取α=β=γ=1/3。实验结果如表1所示。

表1实验结果

图3语义相似度计算结果对比分析图
通过分析实验结果可知:1)本文算法具备传统算法在语义相似度计算中所考虑的影响因素,因此,如图3所示,两种算法的相似度值走向趋势是大致相似的。2)本文算法得到的语义相似度值覆盖区间较大,数值更加精确。实验中本文算法得到的语义相似度最大值为sim(竞争情报、企业)=0.516 42,语义相似度最小值为sim(竞争情报、张玉峰)=0.145 11,语义相似度值覆盖区间为[0.145 11,0.516 42];同理,可得传统算法的语义相似度值覆盖区间为[0.036 454,0.146 919]。对于同样的数据标准,若语义相似度值覆盖区间较小,则说明区间内的概念实例相对较多,会导致语义扩展精度的降低。在应用语义相似度解决实际问题时,大的数值覆盖区间会带来较高的精度[12]。3)本文算法得到的语义相似度值数值较高,更符合语义相似度计算中的归一量化原则,所得结果更接近标量。传统算法得到的语义相似度计算值偏小,缺乏准确度,不太利于后续馆藏资源本体中实例间相关性的判断。
以上分析说明:本文算法考虑了传统算法在计算语义相似度时所用到的各种因素,并通过对传统算法的改进,得到的结果在精确性和准确度上都有所提高,且符合人类的主观判断。虽然本文算法综合考虑的因素较多,在一定程度上提高了相似度计算过程的复杂程度,但随着现今技术的发展,这种程度的运算问题已可以解决,应更多考虑运算时的准确度和合理性。
4 结束语
概念间的相似度量化表示是馆藏资源本体中智能检索、分析和推理的重要基础。本文针对馆藏资源本体的特点,提出了一种综合的馆藏资源本体模型的语义相似度算法。该算法考虑了馆藏资源本体中实例概念间的语义共现、语义距离、概念层次因素,并引入了调节因子,能根据系统的不同需要,得到不同的计算和扩展结果。实例中得到的结果也比较合理。本文的研究只是一个开始,许多问题还有待进一步研究,例如本文的算法只针对在一个馆藏资源本体内部的概念,并没有涉及不同馆藏资源本体间的语义相似度计算。在后续工作中,将进一步扩展相似度计算的广度,并将新算法应用于馆藏资源本体的构建中以提高效率和效果。
[1]李健康,张春辉.本体研究及其应用进展[J].图书馆论坛,2004(6):80-86.
[2]邱均平,余凡.基于计量分析的馆藏资源语义化理论研究[J].中国图书馆学报,2012(4):71-78.
[3]邱均平,楼雯.基于CSSCI的情报学资源本体构建[J].情报资料工作,2013(3):57-63.
[4]孙海霞,钱庆,成颖.基于本体的语义相似度计算方法研究综述[J].现代图书情报技术,2010(1):51-56.
[5]张德.万维网信息聚类研究[D].南京:东南大学计算机系,2002.
[6]LIN D.An Information-Theoretic Definition of Similarity[C]//Proc of the Int’l Conf on Machine Learning San Francisco:Morgan Kaufmann Publishers Inc.1998:296-304.
[7]黄果,周竹荣.基于领域本体的概念语义相似度计算研究[J].计算机工程与设计,2007(10):2460-2463.
[8]TERVSKY.Features of Similarity[J].Psychological Review,1977(4):327-352.
[9]张忠平,赵海亮,张志惠.基于本体的概念相似度计算[J].计算机工程,2009(7):17-19.
[10]吴健.基于本体论和词汇语义相似度的Web服务发现[J].计算机学报,2005(4):595-602.
[11]C.J.Van Rijsbergen.Information Retrieval[M].London:Butterworths,1979.
[12]曹叡,吴玲达.一种改进的领域本体语义相似度计算方法[J].微电子学与计算机,2014(8):109-114.
