基于极限学习的深度学习算法
2015-05-04赵志勇李元香易云飞
赵志勇,李元香,喻 飞,易云飞,2+
(1.武汉大学 软件工程国家重点实验室,湖北 武汉430072;2.河池学院 计算机与信息工程学院,广西 宜州546300)
0 引 言
随着人工神经网络 (neural network,NN)[1]技术的出现,机器学习领域得到了迅速的发展,产生了很多基于神经网络的机器学习模型和算法,如前馈神经网络 (BP)[2]、支撑向量机 (SVM)[3]及其改进的算法[4]等。然而这些早期的神经网络模型都属于浅层的结构,这些浅层结构难以有效地表示复杂的函数,为了表示一个需要指数级问题的时候,利用浅层的结构则需要大量的训练样本[5]。深度学习可以通过对低层的特征的组合形成更加抽象的高层表示[6]。
深度学习概念的出现促进了深层结构的神经网络模型和算法的研究。Lecun等[7]提出的卷积神经网络是第一个深层学习算法;Geoffrey Hinton等[8]提出了一种贪婪的逐层无监督训练算法,该算法可以有效地训练深度信念网(deep belief network,DBN)。DBN的思想是先通过贪婪的策略学习浅层的特征,再通过浅层特征的组合得到更加抽象的描述[9]。随着深度结构的神经网络的发展,出现了很多对深度学习的改进算法,深度学习得到了很广泛的应用。深度学习已经成功应用在语音识别,图像处理等[9,10]。Hinton指出[8],为了训练DBN,首先要通过无监督贪婪训练每一层的受限玻尔兹曼机,并通过一组受限玻尔兹曼机的组合构建深度信念网DBN,然后通过传统的全局学习算法对构建的DBN微调,以使得网络达到最优。然而基于梯度的全局优化算法并不能很好的训练深度结构的神经网络,并且对于深度结构的神经网络模型,基于梯度的全局优化算法会陷入局部最优[5],并且这样的全局微调过程需要大量的训练时间。
随着机器学习的发展,不同的学习算法被提出用于加快学习的速度。极限学习机 (extreme learning machine,ELM)是由Huang等[11]提出来的一种适合传统的神经网络的快速学习算法,特别是单隐层前馈神经网络 (singlehidden layer feedforward networks,SLFNs)。ELM 随机初始化SLFNs的输入权重和隐层的偏置,并能够得到对应的输出权重。ELM能保证输出权重的范数最小,而且输出权重是唯一的。随着ELM的发展,出现了一些对基本ELM的改进的算法[13-15],又进一步提高了基本ELM的性能。为了加快DBN的训练准确性,并提高分类的准确性,受到ELM思想的启发,本文提出来一种基于ELM改进的深度结构学习算法IDBN,充分利用ELM的快速学习能力来提高DBN的训练速度。通过对手写体数据库MNIST和USPS数据集分类的仿真实验,验证了基于ELM的深度结构学习算法IDBN比传统的深度结构学习算法DBN的速度更快,同时可以得到同样的准确性。
1 深度学习算法
1.1 深度信念网 (DBN)
文献 [8]中提出的深度信念网 (DBN)是一种典型的生成性深度结构。假设一个DBN有n个隐层,令gi表示第i个隐层的向量,则DBN的模型可以表示成


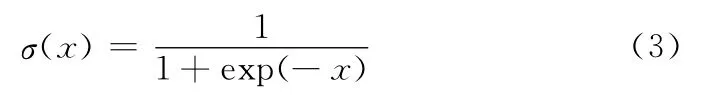
DBN是由一组受限玻尔兹曼机 (RBM)单元的自底向上的叠加组成的,为了得到DBN,首先需要通过逐层地贪婪学习得到一组RBM。为了得到最终的深度神经网络模型,还需要利用训练数据对整个模型进行有监督的调整,这被称为微调。
1.2 受限玻尔兹曼机 (RBM)
RBM是一种特殊的玻尔兹曼机模型,即同层节点之间没有连接。一个RBM是由可见层节点和隐含层节点组成的,RBM 作为一个系统所具备的能量E(v,h;θ)[9],其中向量v表示可见节点状态,向量h表示隐含层节点状态。当参数θ确定时,基于该能量函数,我们可以得到联合概率分布p(v,h;θ)[9]。
RBM在层间有连接,而层内无连接,则对于给定某层节点的状态时,另一层节点之间的状态条件分布相互独立。则当给定可见节点v的状态时,我们可以得到第j个隐含层节点的被激活的概率求得所有隐含层节点后,基于RBM的对称结构,可见节点的激活概率为通过吉布斯采样 (Gibbs sampling)[9],我们可以重构整个深度网络。
2 极限学习机 (ELM)
ELM是一种新型的快速学习算法,对于单隐层神经网络,ELM可以随机初始化输入权重和偏置并得到相应的输出权重。
对于一个单隐层神经网络,假设有N个任意的样本(Xi,ti),其中 Xi= [xi1,xi2,…,xin]T∈Rn,ti= [ti1,ti2,…,tim]T∈Rm。对于一个有珦N个隐层节点的单隐层神经网络可以表示为
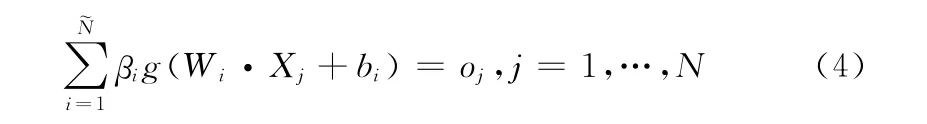
其中,g(x)为激活函数,Wi= [wi,1,wi,2,…,wi,n]T为输入权重,βi为输出权重,bi是第i个隐层单元的偏置。Wi·Xj表示Wi和Xj的内积。
单隐层神经网络学习的目标是使得输出的误差最小,可以表示为
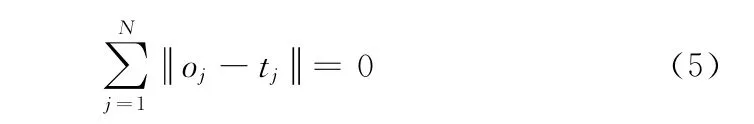
即存在βi,Wi和bi,使得

可以表示为

式中:H——隐层节点的输出,β——输出权重,T——期望输出

为了能够训练单隐层神经网络,我们希望得到^Wi,^bi和使得


传统的一些基于梯度下降法的算法,如BP学习算法及其变种,可以用来求解这样的问题,但是基本的基于梯度的学习算法需要在迭代的过程中调整所有参数。而在ELM算法中,一旦输入权重Wi和隐层的偏置bi被随机确定,隐层的输出矩阵H就被唯一确定。训练单隐层神经网络可以转化为求解一个线性系统Hβ=T。并且输出权重β可以被确定为

3 基于极限学习机的深度学习算法
在传统的DBN的构建过程中,可以分为三步[9]:①通过贪婪的方式预训练得到每一层;②利用无监督的方法从输入得到每一层,得到一组RBM,并由得到的一组RBM构建DBN;③利用传统的全局优化方法对构建的整个网络进行微调。传统的DBN的微调方法中是通过梯度下降的方法完成的,但是基于梯度的优化方法需要在迭代的过程中修改参数,这将会花费大量的时间,而且基于梯度的方法会陷入局部最优。对于传统的单隐层神经网络极限学习机的方法可以加快神经网络的训练速度。在基于极限学习机的深度学习算法中,我们使用极限学习机的算法对整个网络进行微调。
3.1 改进的深度信念网IDBN的构建
DBN是由一组RBM单元的叠加组成的,假设有一个有n个隐层的DBN,可以表示为

式中:I——输入向量,O——输出向量,Hi——第i个隐层的输出向量,每一个Hi都是对输入I的抽象。其中输入层到第一个隐层IH1,第i个隐层到第i+1个隐层HiHi+1为一个RBM。在预训练阶段,我们通过对每一层的RBM进行吉布斯采样,利用对比差异算法得到每一个RBM。对于 N 个任意的样本 (Xi,ti),其中Xi= [xi1,xi2,…,x1n]T∈Rn,ti= [ti1,ti2,…,t1m]T∈Rm。则对于深度结构的学习算法,输入I即为X。
对于一个含有n个隐层节点的DBN,我们通过贪婪的训练方式得到n-1个RBM,即从输入层,隐层1,…,隐层n-1。而第n-1个隐层到第n个隐层以及第n个隐层到输出层的权重和偏置则是由ELM算法确定。
3.2 深度信念网的优化

式中:Wi——第n-1个隐层到第n个隐层的权重,bi——第n-1个隐层到第n个隐层的偏置,βi——第n个隐层到输出层的输出权重。对于深度信念网DBN,目标是最小化输出的误差,可以表示为

并且,存在βi,使得

这个问题可以转化为

式中:Hn——深度信念网的第n-1层到第n层的输出。其中
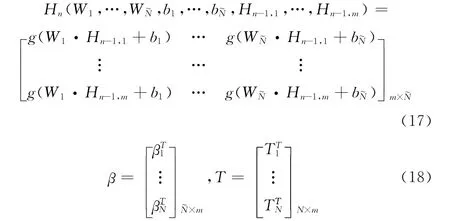
为了训练单隐层神经网络,特殊的^Wi,^bi和^β需要被训练,使得


随机初始化第n-1个隐层到第n个隐层的权重Wi和偏置bi,则可以得到隐层的唯一输出矩阵Hn。训练深度信念网就可以转化为求解一个线性系统Hnβ=T。并且输出权重β可以被确定为

与传统全局优化方法不同的是,基于ELM的深度学习算法没有对每一个受限玻尔兹曼机RBM的权重和偏置调整。而传统的全局优化方法需要对整个网络的权重和偏置进行调整,这将花费大量的时间。基于ELM的深度学习算法充分利用ELM的快速学习能力,能够很快地收敛[11]。
4 实验与结果分析
4.1 实验数据
为了测试我们提出的改进的深度结构的学习算法IDBN,我们选取了 MNIST数据集,Binary Alphadigits数据集和USPS数据集,并与传统的深度结构的学习算法DBN对比。其中MINST中包含50000个训练数据和10000个测试数据。MNIST是由0~9阿拉伯数字的手写体样本组合而成。实验时的所有样本都为28×28大小的标准灰度图像。Binary Alphadigits数据集是由数字0~9和英文字母A~Z组成的灰度图像,数据集是由20×16的36类图像组成,我们对这个数据集进行了处理,选取其中240个作为训练集,160个作为测试集。USPS手写体库是由16×16的10类图像组成,我们对原始的图片进行了灰度处理,并从其中选择了7000个作为训练数据,另选了4000个作为测试数据。
4.2 实验数据
实验的运行环境是i7处理器,Matlab R2010a。对于两个测试集,我们设置了不同的运行参数。表1给出了MINST数据集,Binary Alphadigits数据集和USPS数据集上运行的参数。每个数据集上独立运行50次取平均值。

表1 两个数据集的运行参数
4.3 结果与分析
本文章采用训练时间 (training time),训练的准确性(training accuracy)和测试的准确性 (testing accuracy)作为算法性能测试和比较的标准。表2给出了在MNIST数据集上两种算法独立运行50次后取平均值的运行结果。表3给出了在Binary Alphadigits数据集上两种算法独立运行50次后取平均值的运行结果。表4给出了在USPS数据集上两种算法独立运行50次后取平均值的运行结果。
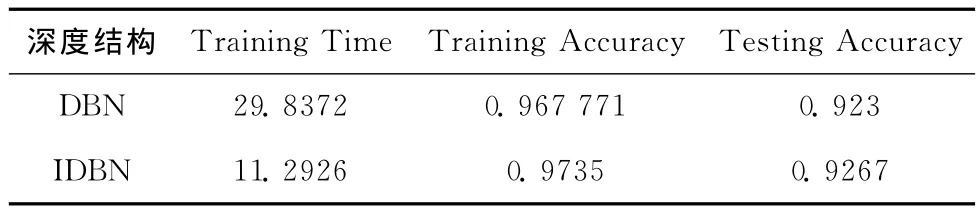
表2 MNIST数据集的运行结果

表3 USPS数据集的运行结果

表4 USPS数据集的运行结果
从图1中很容易看出,IDBN在训练时间上比DBN的训练时间要少,说明了基于极限学习机改进后的深度学习算法比传统的深度学习算法在性能上有了很大的提升。图2中显示的是Training Accuracy的比较结果,对比结果说明了改进后的深度学习算法IDBN能够获得与传统深度学习算法DBN较优的训练准确性。图3显示的是Testing Accuracy的比较结果,对比结果显示,IDBN在测试精度上比DBN的准确性较高。
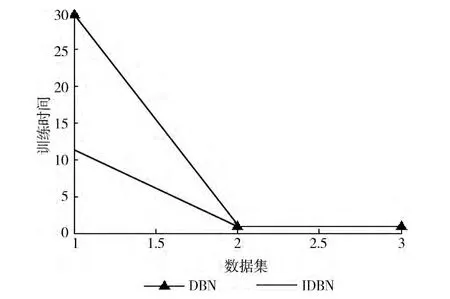
图1 两个算法的训练时间比较
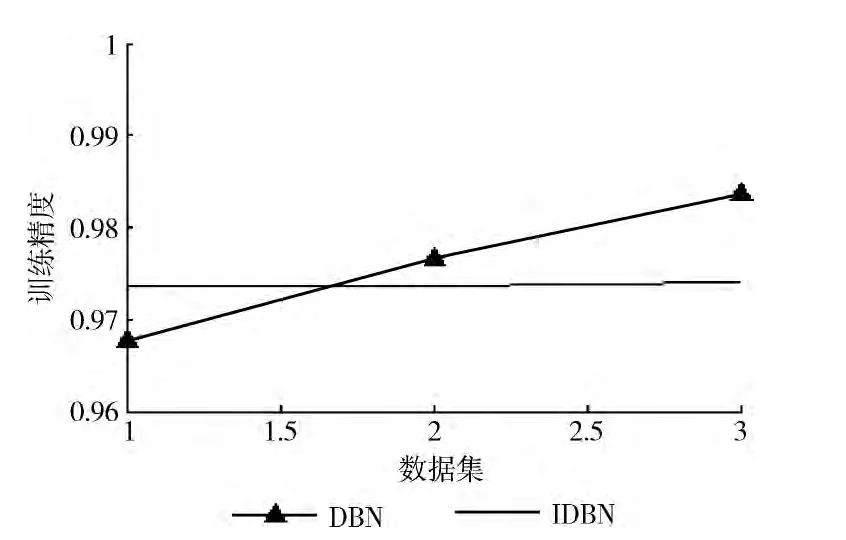
图2 两个算法的训练的准确性比较

图3 两个算法的测试精度比较
从上述的结果中,我们发现基于ELM的深度结构学习算法IDBN可以获得与传统的深度学习算法DBN同样的训练和测试准确性,同时,改进后的深度学习算法IDBN比传统的深度学习算法DBN的训练速度更快,在训练中可以节省大量的时间。在构建深度信念网的过程中,先通过逐层受限玻尔兹曼机训练使模型得到一个较优的初始参数值,然后通过采用传统的全局学习算法进行网络的微调,使得网络达到最优。在微调的过程中,传统的全局学习算法需要对整个网络的权重和偏置调整,需要花费大量时间,而基于ELM的深度结构算法IDBN结合了ELM的优点,不需要对训练好的权重和偏置调整,在微调过程中节省了时间,也为整个深层神经网络的训练节省了时间。
5 结束语
本文借鉴了极限学习机ELM的快速学习的算法设计并将其引入到传统的深度学习算法DBN中,改进了传统的基于全局学习算法的微调方法。通过对不同数据集的测试过程的分析结果表明,改进后的深度学习算法IDBN不但能够保证原来训练和测试的准确性,而且能够明显加快深度学习的训练速度。下一步,将寻找一个较好的应用方向,将改进后的算法用于实际问题的求解中。
[1]Yang X,Zheng J.Artificial neural networks [J].Handbook of Research on Geoinformatics,2009:122-130.
[2]Pradhan B,Lee S.Regional landslide susceptibility analysis using back-propagation neural network model at Cameron Highland,Malaysia [J].Landslides,2010,7 (1):13-30.
[3]Catanzaro B,Sundaram N,Keutzer K.Fast support vector machinetraining and classification on graphics processors [C]//Helsinki,Finland:ACM,2008:104-111.
[4]ZHENG Fengde,ZHANG Hongbin.Lagrange twin support vector regression [J].Computer Science,2011,38 (12):247-249 (in Chinese).[郑逢德,张鸿宾.Lagrange双支撑向量回归机 [J].计算机科学,2011,38 (12):247-249].
[5]Bengio Y,Lamblin P,Popovici D,et al.Greedy layer-wise training of deep networks [J].Advances in Neural Information Processing Systems,2007,19:153-160.
[6]Bengio Y,Delalleau O.On the expressive power of deep architectures[G].LNCS 6925:Algorithmic.Learning Theory.Berlin Heidelberg:Springer,2011:18-36.
[7]Le Cun Y,Bottou L,Bengio Y,et al.Gradient-based learning applied to document recognition [J].Proceedings of the IEEE,1998,86 (11):2278-2324.
[8]Hinton GE,Osindero S,Teh YW.A fast learning algorithm for deep belief nets [J].Neural Computation,2006,18 (7):1527-1554.
[9]Dahl GE,Yu D,Deng L,et al.Large vocabulary continuous speech recognition with context-dependent DBN-HMMs [C]//IEEE International Conference on Acoustics Speech and Signal Processing,2011:4688-4691.
[10]Mohamed A,Sainath TN,Dahl G,et al.Deep belief networks using discriminative features for phone recognition[C]//IEEE International Conference on Acoustics Speech and Signal Processing,2011:5060-5063.
[11]Huang GB,Zhou H,Ding X,et al.Extreme learning machine for regression and multiclass classification [J].IEEE Transactions on Systems,Man,and Cybernetics,2012,42(2):513-529.
[12]Nobrega JP,Oliveira ALID.Improving the statistical arbitrage strategy in intraday trading by combining extreme learning machine and support vector regression with linear regression models [C]//IEEE 25th International Conference on Tools with Artificial Intellgence,2013:182-188.
[13]Chen H,Peng J,Zhou Y,et al.Extreme learning machine for ranking:Generalization analysis and applications [J].Neural Networks,2014,53:119-126.
[14]Xi-Zhao W,Qing-Yan S,Qing M,et al.Architecture selection for networks trained with extreme learning machine using localized generalization error model [J].Neurocomputing,2013,102:3-9.
