双向词典和语义相似度计算相结合的词对齐算法
2015-05-04尹宝生
尹宝生,杨 阳
(沈阳航空航天大学 人机智能研究中心,沈阳 110136)
双向词典和语义相似度计算相结合的词对齐算法
尹宝生,杨 阳
(沈阳航空航天大学 人机智能研究中心,沈阳 110136)
基于统计的词对齐方法需要大规模的双语语料作为输入,难以避免数据稀疏的问题并且算法时间开销大。针对句子或段落级的实时性对齐需求,提出了一种基于双向词典和语义相似度计算的高效词对齐算法,通过采用动态组块切分和匹配、基于知网的语义相似度计算、基于最大匹配的冲突消解和剪枝消歧等策略,有效地解决了由于翻译的灵活性和多样性带来的近似译文的词对齐问题。实验表明,该算法不仅继承了基于词典词对齐算法的优点,同时还改进了传统基于词典词对齐算法的不足,有效提升了词对齐的正确率和召回率,在小规模双语语料和实时性对齐方面具有更好的适用性。
词对齐;双向词典;动态组块切分和匹配;语义相似度计算
双语语料库(Bilingual Corpus)包含两种不同语言间的互译信息,是基于统计(Statistic-Based)机器翻译[1]和基于实例(Example-Based)机器翻译[2]的重要知识源之一,被广泛应用于词典编纂、词义消歧和命名实体识别等自然语言处理任务。然而,未经任何处理的双语语料库(即生语料,Raw Corpus)不能直接应用在相关的自然语言处理任务中。依据互译片段的大小,双语语料库对齐分为多个层次:篇章对齐、段落对齐、句对齐和词对齐。所谓词对齐是指从源文和译文中匹配词语级别的对应关系,词语一级的对齐互译片段最小,含有更细粒度的双语互译信息,需要丰富的资源和多种方法的融合,处理过程相比其他层次对齐更加复杂。
目前,词对齐的处理方法主要有:
(1)基于统计的词对齐方法:通过对大规模双语语料的统计训练,获得词语一级的同现概率,把它作为词对齐的依据。文献[3]根据Brown[4]提出的基于信源信道模型的统计翻译方法,实现了第一个词对齐软件包GIZA。文献[5-6]对GIZA进行优化并发布新版的词对齐软件包,称为GIZA++。基于统计翻译模型方法的技术理论比较完善,主要不足是双语语料库规模的限制,难以避免数据稀疏的问题,并且算法时间开销大,不适合小规模双语语料库、时间要求高的应用。
(2)基于语言学的词对齐方法:主要思想是利用语言资源和语言学知识来进行词语级别的对齐。很多学者依据该方法进行了研究,如文献[7]提出的基于双语词典的汉英词对齐算法;文献[8]基于锚点词对的双语词对齐算法研究;文献[9]基于语言学上相似性的观点并充分利用语言学知识来进行词对齐。基于语言学的词对齐方法可以获得很高的对齐正确率,往往受到分词准确率以及双语资源规模的影响,对齐召回率不高。因此,本文采用动态组块切分匹配方法和基于知网对未对齐的组块进行语义层面的相似度扩展对齐加以处理。
近几年,多位学者从不同的角度对词对齐进行了研究,如文献[10]基于深度神经网络探索了一种新的词对齐模型;文献[11]从约束双语命名实体之间的对齐角度出发,提出了一种改进词对齐结果的方法;文献[12]提出的基于对偶分解的词对齐搜索算法,其基本思想是将复杂的问题分解为两个相对简单的子问题,迭代求解直至收敛;文献[13]为减少词对齐的错误,提出一种基于对齐困惑度的双语语料过滤方法和一种改进的判别式词对齐算法。
本文使用英汉、汉英两部词典进行词对齐,因为词典含有丰富、高质量的源语言(Source Language)和目标语(Target Language)之间的互译信息,是诸多自然语言处理任务的基础性资源。目前,随着词典规模的不断扩充,充分利用现有的词典来解决词对齐问题已成为一种直接可靠的选择。
针对句子或段落级的实时性对齐需求,本文提出一种基于双向词典和语义相似度计算的高效词对齐算法,实现了一种即时性词对齐方法,利用英汉、汉英两部词典进行词对齐,基本思想是双向融合。本文使用词典驱动的动态组块切分匹配方法,不需要预先对汉语句子进行分词处理,有效避免了汉语分词不当而无法使用词典进行对齐的问题。另外,针对词典的完备性问题,本文基于知网对未对齐的组块进行了语义层面的相似度扩展对齐,明显提高了对齐的召回率。
1 词对齐的问题描述
词对齐是在句对齐的基础上,自动获得词语一级的对应关系。不同英汉句对间内容和形式的差异,导致词对齐存在多种复杂的对应关系,如:一对一、多对一、一对多和多对多等。另外,英语和汉语分属印欧语系和汉藏语系,各语言独有的特点使得英汉双语对齐不满足顺序上的绝对对齐,经常出现前后交叉的现象。
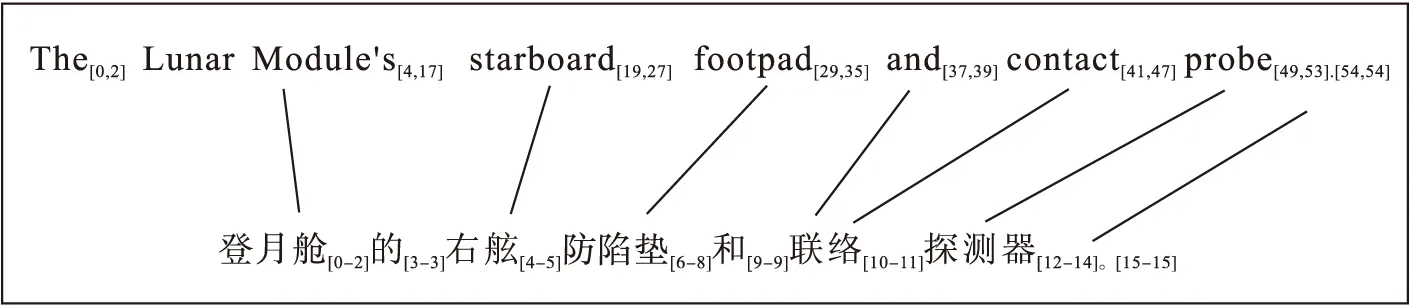
图1 词对齐实例1
一对一:starboard[19,27]=> 右舷[4-5];probe[49,53]=> 探测器[12-14]
多对一:LunarModule′s[4,17]=> 登月舱[0-2]
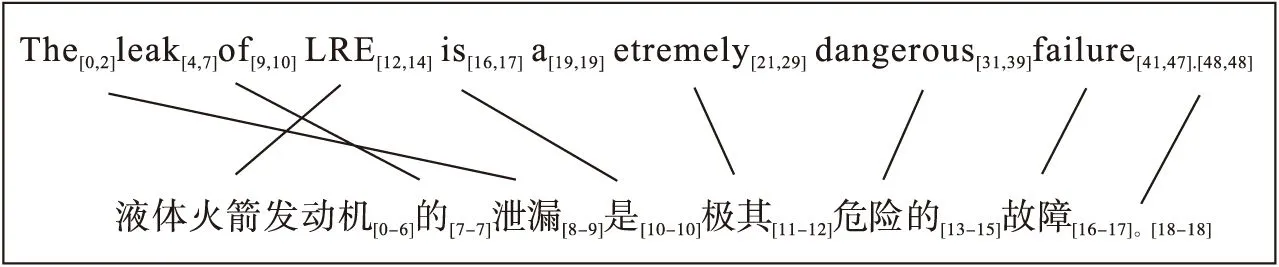
图2 词对齐实例2
一对多:LRE[12,14]=> 液体火箭发动机[0-6]
交叉现象:leak[4,7]=> 泄漏[8-9];LRE[12,14]=> 液体火箭发动机[0-6]
英语多省略、汉语多补充的特点导致词对齐中经常出现空对和对空的现象(空对,指译文没有对应的源文;对空,指源文没有对应的译文),如图1、2所示:
空对:NULL => 的[3-3];对空:a[19,19]=> NULL
目前,汉语中关于词还没有一个绝对统一的定义,汉语的分词界限尚未彻底解决,这就是分词颗粒度问题,相同的汉语句子在不同领域分词结果也不尽相同。然而,现有的词对齐方法很大程度上依赖于分词的效果,如何解决分词带来的弊端,是英汉词对齐中的关键问题。本文中,登录词和未登录词的界定以词典为标准,即词典中出现的词为登录词,否则为未登录词。
2 词对齐算法描述
本文提出的方法不对汉语句子进行分词处理,而是使用词典驱动的动态组块切分匹配方法,避免了汉语分词不当而无法使用词典进行对齐的问题,提高了词典的翻译覆盖率,并且算法很好地处理了英文节点相同,中文位置相交的情况以及N对N等问题。采用基于知网的语义相似度计算、基于最大匹配的冲突消解和剪枝消歧等策略,实现了双语未对齐组块间的扩展对齐,提高了对齐召回率,算法流程如图3所示:
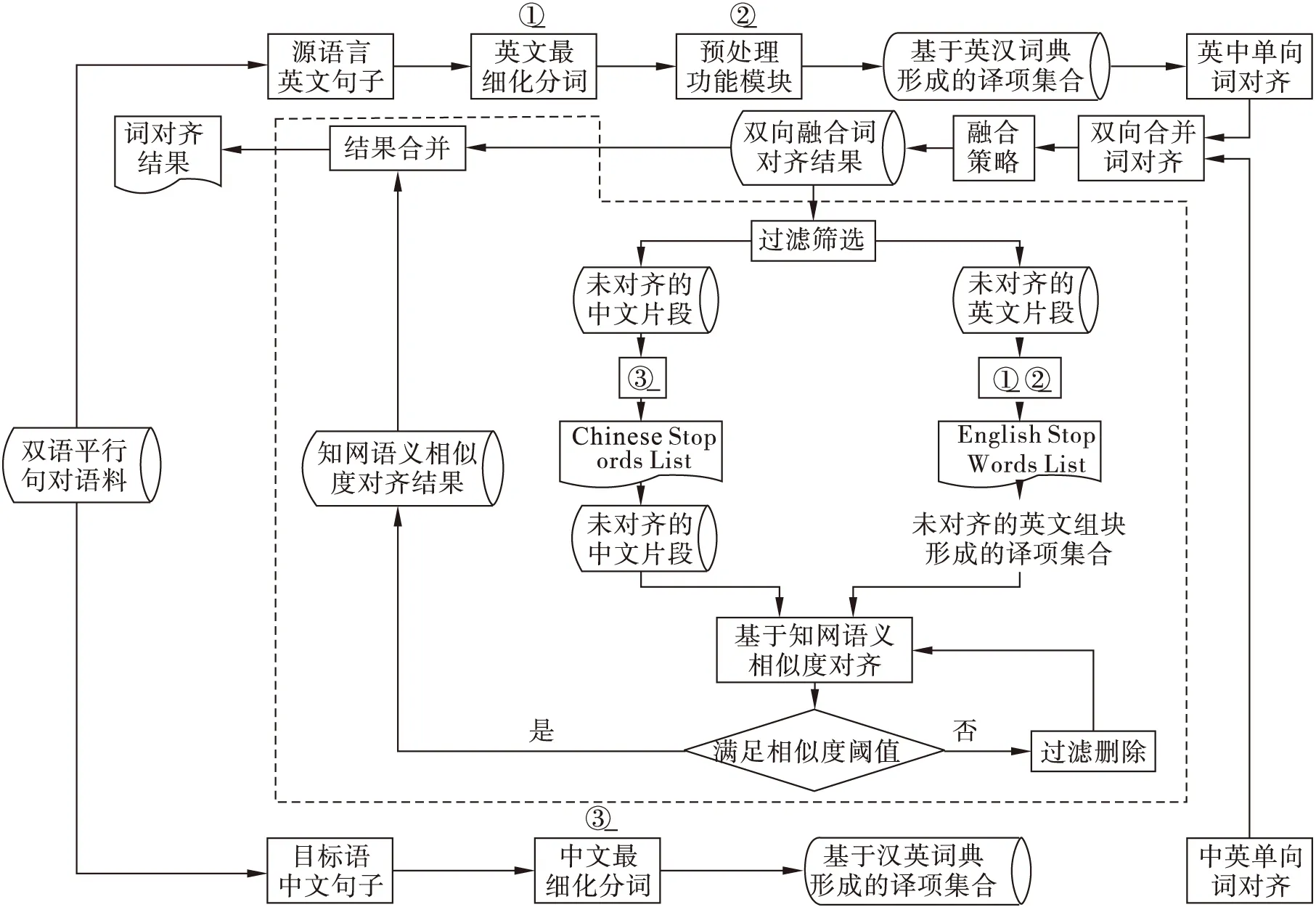
图3 算法流程图
2.1 双语句子处理
英文句子处理:按照英文为词(空格作为自然分界符)、标点符号独立的原则,把英文句子最细化分词形成独立的单词集合,记录单词的位置信息;然后,基于英汉词典对集合中的英文单词进行组合,形成所有可能的词或词组,查询英汉词典,返回其对应的所有中文译项。将不能在词典中查询到的词或词组进行词形还原,包括名词复数变换(specialists/specialist)、形容词比较级、最高级变化(narrower/ narrow、warmest/ warm)、大写变换(Appropriate / appropriate)以及动词时态还原(verified / verify、manufacturing/ manufacture);最后,对词形还原的词或词组查询英汉词典,返回其对应的所有译项。
汉语句子处理:词对齐中经常会由于汉语分词的差异而产生不同的对齐结果,从而影响对齐的准确率和召回率,如图4所示:

图4 分词不同产生不同的对齐结果
为了解决汉语分词不当产生的不完全对齐问题,降低汉语分词增加的一对多、多对多等现象,算法不对汉语句子进行预先确定性分词处理,使用词典驱动的动态组块切分匹配方法。首先,按照汉语为字、标点符号独立的原则,把汉语句子最细化分词形成独立的字集合;然后,对集合中的字进行组合,并以词典是否包含该组合为标准,得到所有可能的词或词组;最后,对得到的词或词组查询汉英词典,返回其对应的所有英文译项。
2.2 英中(EC)、中英(CE)单向词对齐
在2.1节中,算法分别获得基于英汉词典、汉英词典形成的译项集合,EC单向对齐是对集合中的中文译项元素逐一判断的过程,当与译文中的词或词组匹配时,则返回源文及其对应的中文译项元素作为EC单向对齐结果。
同理,CE单向对齐是对集合中的英文译项元素逐一判断的过程,当与源文中的词或词组匹配时,则返回译文及其对应的英文译项元素作为CE单向对齐结果。
2.3 双向对齐结果的合并
对EC、CE单向对齐结果进行双向合并,按照EC单向对齐结果从前向后、由长到短排序,舍弃重复的对齐结果,保存全部可能的词对齐结果,具体处理过程如下:
(1)中英文完全一样的节点,舍弃CE中的对齐结果,对齐等级(LEVEL)加1,LEVEL=2表示EC单向对齐和CE单向对齐均有对齐,如:
EC单向对齐结果:aerocraft[45,53]=> 飞行器[13-15]
CE单向 对齐结果:飞行器[13,15]=> aerocraft[45-53]
合并译项:aerocraft[45,53]=> 飞行器[13-15]LEVEL:2
(2)若英文的起始位置一样,原节点的结束位置比新节点的结束位置要大,则保存CE中的对齐结果,如:
EC单向对齐结果:OrbitalModule[23,36]=> 轨道舱[15-17]
CE 单向对齐结果:轨道[15,16]=> Orbital[23-29]
保存全部译项: OrbitalModule[23,36]=> 轨道舱[15-17]LEVEL:2
Orbital[23,29]=> 轨道[15-16]LEVEL:2
(3)新节点的开始位置比原节点的开始位置要大,直接保存CE中的对齐结果。
2.4 双向对齐结果的融合处理
对双向合并对齐结果进行融合处理,融合策略如下:
(1)英文节点相同、中文位置相交的情况,采取最大匹配的原则,选择中文译项最长的对齐结果消解冲突,如:
infrastructure[45,58]=> 基础设施[12-15]LEVEL:2
infrastructure[45,58]=> 基础[12-13]LEVEL:2
保留对齐结果:infrastructure[45,58]=> 基础设施[12-15]LEVEL:2
(2)英文节点相同、中文节点开始位置不同的情况:i)若待匹配的英文节点前面存在一个最近有效匹配的英文节点,则记录该英文节点对应的中文译项的开始位置信息;ii)否则,记录后面一个最近有效匹配的英文节点对应的中文译项的开始位置信息。
把上面得到的开始位置信息作为参考点RePoint,计算它与待对齐中文节点之间的相对距离OpDist。算法按照最近原则匹配,保留相对距离最短的对齐结果,如:
chargedparticles[18,34]=> 带电粒子[19-22]LEVEL:2
chargedparticles[18,34]=> 带电粒子[35-38]LEVEL:2
最近有效匹配的对齐:accelerate[7,16]=> 加速[17-18]LEVEL:2
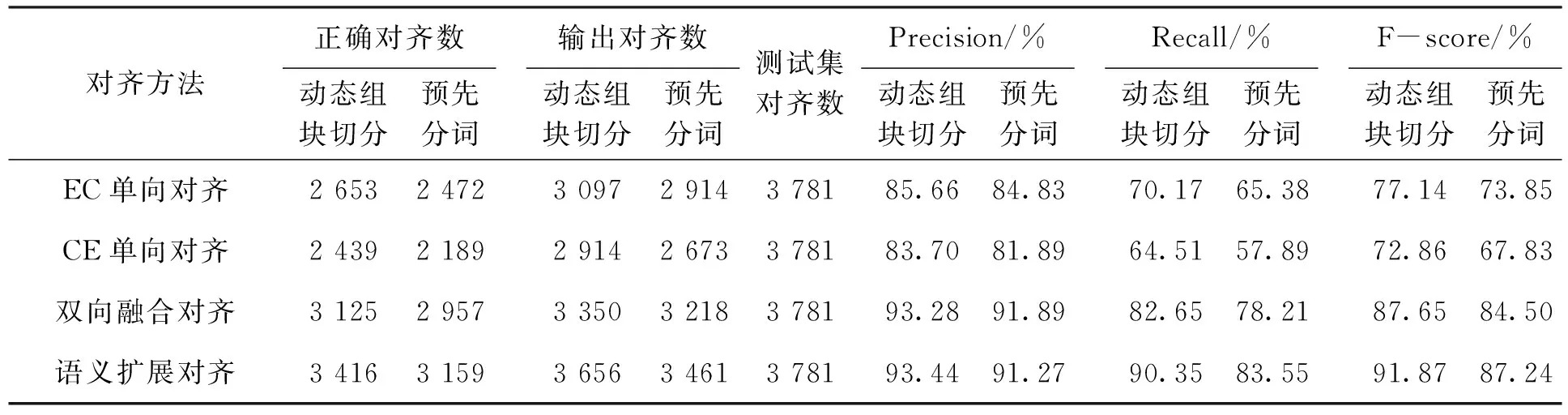
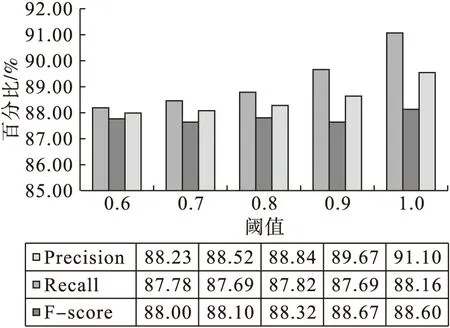
RePoint=17,OpDistA=︱17-19︱ 保留对齐结果:chargedparticles[18,34]=> 带电粒子[19-22]LEVEL:2 (3)匹配某个节点后,对其后续的节点进行剪枝消歧处理:a)舍弃和已匹配的中文译项相同的译项;b)把已匹配的英文开始、结束位置信息作为区间的左、右端点,舍弃子区间对应的所有译项。如: turbinepropulsion[12,29]=> 涡轮推进[1-4]LEVEL:2 turbine[12,18]=> 涡轮[1-2]LEVEL:1 propulsion[20,29]=> 推进[3-4]LEVEL:2 舍弃译项:turbine[12,18]=> 涡轮[1-2]LEVEL:1 propulsion[20,29]=> 推进[3-4]LEVEL:2 2.5 基于语义相似度计算的扩展对齐 我们对翻译公司的调研发现,翻译人员在处理大规模翻译任务时需要多人协作共同完成,不同翻译人员的背景文化和语言习惯是不同的,相同的单词往往会有不同的翻译结果。另外,相同的源语言单词(如:“capsule”)翻译成目标语言时有多种的表达方式(如:“太空舱”、“航天舱”和“密封舱”)。结合实际翻译中语言表达的多样性和翻译的灵活性,词典不可能完全收录词语的解释。针对该问题,算法在进行双向融合处理之后,基于知网对未对齐的组块进行语义层面的相似度扩展对齐,提高了对齐的召回率。 2.5.1 语义相似度计算 知网[14](HowNet)是一个以汉语和英语的词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。 关于词语相似度的计算,文献[15]基于知网的词汇语义相似度计算是这样解释的,对于两个汉语词语W1和W2,如果W1有n个概念:S11,S12,……,S1n,W2有m个概念:S21,S22,……,S2m,则W1和W2的相似度是各个概念的相似度之最大值,如式(1)所示: (1) 这样,两个词语之间的相似度计算就归结到了两个概念之间的相似度计算。知网中的概念是用义原来表示的,所以义原相似度计算是概念相似度计算的前提。 文献[16]从信息论的角度出发,两个事物的相似度不仅与其个性有关,更应与其共性有关。定义义原相似度计算公式如式(2)所示: (2) 其中Depth(p)表示义原p在整体义原层次体系中所处的层数位置,即义原深度。Spd(p1,p2)、Dsd(p1,p2)分别表示义原p1和p2的重合度、相异度。 知网收录的词语分为虚词和实词两类,由于虚词和实词的不可替换性,因此它们的概念相似度总为0;知网中虚词的描述仅使用了“{句法义原}”或“{关系义原}”,对于虚词之间的相似度只需计算虚词对应的句法义原(关系义原)间的相似度即可。 在知网中,实词概念DEF项的描述分成4个部分:(1)第一基本义原;(2)其他基本义原;(3)关系义原;(4)符号义原。给出任意实词概念S1和S2,其各部分的相似度分别为Sim1(S1,S2)、Sim2(S1,S2)、Sim3(S1,S2)、Sim4(S1,S2),则两个实词的语义相似度如式(3)所示: (S1,S2)Simi(S1,S2) (3) 其中,βi表示可调参数,分别描述了DEF项中各部分的权重,β1+β2+β3+β4=1,β1≥β2≥β3≥β4。式中通过第一部分对其他部分的语义相似度起强制制约作用,突出第一基本义原的重要程度。另外,文献[16]通过对未登录词(知网中以外的词)进行概念切分、组合概念的语义自动生成和相似度计算,解决了未登录词无法参与语义相似度计算的难题,基于知网实现了任意两个汉语词语在语义层面的相似度计算。本文基于上述方法来计算两个汉语词语的语义相似度,参数设置:β1=0.5,β2=0.2,β3=0.17,β4=0.13。 2.5.2 语义相似度的扩展对齐 在很多情况下,待对齐词语的译项并没有被词典收录,但其对应的译文和词典的译项在语义层面上具有极高的相似性,如表1所示: 表1 词典译项与未登录词的语义相似度 在进行双向融合处理之后,算法基于知网对未对齐的组块进行语义层面的相似度扩展对齐。语义相似度扩展对齐中融入停用词过滤环节,算法仅过滤英文和中文停用词集合中包含的停用词,保留含有停用词的未对齐组块(如:“a series of”、“give rise to”、“预期的”)。英文停用词集合包含“it”、“the”、“at”、“of”等常见的停用词129条;中文停用词集合包含“的”、“着”、“啊”、“也好”等常见的停用词200条。另外,为了解决“24.5±0.9%”、“#0”和英文缩写之类的符号,在2.1节英文句子处理时把所有单词组合强制翻译成本身。 基于知网的语义扩展对齐流程:首先,在双向融合词对齐结果的基础上对双语句对过滤,获得未对齐的英文片段和中文片段;然后,基于英汉词典对未对齐的英文片段进行英文最细化分词、预处理及停用词过滤等环节,基于汉英词典对未对齐的中文片段进行最细化分词处理及停用词过滤处理;最后,基于知网进行语义相似度的扩展对齐,实现模糊匹配(Fuzzy Matching)。 模糊匹配采取最大匹配冲突消解原则和剪枝消歧策略,具体过程如下:(1)将未对齐的英文组块形成的译项集合分别与未对齐的中文组块进行语义相似度计算,满足指定相似度阈值λ(本文中设λ=1.0)则进行对齐,保留满足阈值且最长的英文组块及译文(对齐结果),并过滤已对齐的英文组块及其包含的英文子组块;(2)如果集合元素的每个中文译项与全部中文组块均达不到指定阈值,则删除该英文组块及其对应的所有译项;(3)依次取得下一个英文组块对应的中文译项,循环执行上述步骤,直到未对齐的英文组块形成的译项集合为空集,算法结束。 3.1 评价指标与实验结果 本实验用到的测试语料是一本系统工程(System Engineering)双语书籍[17],共9章,约20万字规模。该批语料的特点是专业术语丰富、内容关联度高、语言规范性强。从文章中随机抽取500个句对作为标准测试集并进行词对齐的人工校对。使用的英汉、汉英词典来自灵格斯中的朗道英汉、朗道汉英词典,分别包含词条数2,410,778条、2,248,593条。对齐结果使用准确率、召回率和F值3个指标进行评价,定义如式(4)、(5)、(6)所示: (4) (5) (6) 本文使用词典驱动的动态组块切分匹配方法,不需要预先对汉语句子进行分词处理,有效避免了汉语分词不当而无法使用词典进行对齐的问题。传统词对齐方法需要对汉语句子进行分词处理之后再进行对齐,把传统词对齐方法作为对比实验来验证预先分词对于词对齐的影响,汉语句子采用中科院分词系统,对齐结果(λ=1.0)如表2所示: 在基于知网的语义扩展对齐中,为了避免过对齐现象,需要对相似度阈值λ进行合理的设置。通过实验验证当阈值λ设定为1.0时,F-score最高,对齐效果最佳,如图5所示: 表2 英汉词对齐结果 图5 不同λ值对词对齐结果的影响 在配置为Win7系统、Intel(R)Core(TM)i3-2350M CPU @ 2.30GHz 2.30GHz、内存2GB的机器上,实验总运行时间为50 566 ms,平均运行时间为101.13 ms/句对。 3.2 实验结果分析 分析表2和表3的实验数据,可以得出: (1)基于词典的词对齐方法,可以获得很高的正确率。EC单向对齐、CE单向对齐和双向融合3种方法分别取得85.66%、83.70%和93.28%的对齐正确率。归因于词典含有丰富的、高质量的源语言和目标语之间的互译信息; (2)尽管词典规模足够庞大,单向对齐结果的召回率依旧不高。影响召回率偏低的主要因素是系统输出的正确对齐数太少,仅使用单向对齐方法不能得到较好的词对齐效果; (3)双向融合的方法明显提高了对齐的效果,相比EC单向对齐和CE单向对齐F值分别提高了10.51个百分点和14.79个百分点。相比双向融合的方法,基于知网的语义相似度扩展对齐明显提高了对齐的召回率,从82.65%提高到90.35%; (4)本算法平均运行时间为每句对101.13 ms,实现了一种高效、实时性词对齐算法; (5)和传统词对齐方法对比,本文的方法有效避免了汉语分词对词对齐的影响。利用双向融合思想和语义扩展对齐获得了高质量的词对齐资源。 词典含有丰富的、高质量的源语言和目标语言之间的互译信息,是进行双语对齐最直接可靠的资源。针对句子或段落级的实时性对齐需求,本文提出基于双向词典和语义相似度计算的高效词对齐算法,采取词典驱动的动态组块切分和匹配、最大匹配冲突消解原则、最近匹配原则和剪枝消歧策略,基于知网对未对齐的组块进行语义层面的扩展对齐,在不降低对齐正确率的情况下明显提高了对齐的召回率。通过实验验证,该方法可以得到高质量的词对齐资源,既可用于实际工程应用,也为自然语言处理的许多任务提供了基础性、有价值的词对齐资源。此外,相比于基于统计的词对齐方法,该方法在只有小规模语料和实时性对齐等方面具有更好的适用性。 [1]Brown P,Della P S,Della P V,et al.The mathematics of statistical machine translation:parameter estimation[J].Computational Linguistics,1993,19(2):263-311. [2]Nagao M.A framework of a mechanical translation between japanese and english by analogy principle[A].In:A.Elithorn andR.Baneji,editors,Artificial and Human Intelligence,1984:173-180. [3]AI-Onaizan Y,Curin J,Jahr M,et al.Statistical machine translation,final report,JHU workshop[DB/OL].http://www.clsp.jhu.edu/ws99/projects/mt/final_report/mt-final-report.ps,1999. [4]Brown P F,Cocke J,Della-Pietra S A,et al.A statistical approach to machine translation[J].Computational Linguistics,1990,16(2):79-85. [5]Och F J,Ney H.Improved statistical alignment models[C].Proceedings of 38th Annual Meeting of Association for Computational Linguistics.Hong Kong,China,2000:440-447. [6]Och F J,Ney H.A comparison of alignment models for statistical machine translation[C].Proceedings of the 18th International Conference on Computational Linguistics.Saarbrucken,Germany,2000:1086-1090. [7]邓丹,刘群,俞鸿魁.基于双语词典的汉英词对齐算法研究[J].计算机工程,2005,31(16):45-47. [8]张孝飞,陈肇雄,黄河,等.基于锚点词对的双语词对齐算法[J].小型微型计算机系统,2006,27(2):330-334. [9]晋薇,黄河燕,夏云庆.基于语义相似度并运用语言学知识进行双语语句词对齐[J].计算机科学,2002,29(11):44-47. [10]Yang N,Liu S J,Li M,et al.Word alignment modeling with context dependent deep neural network[C].Proceedings of 51th Annual Meeting of Association for Computational Linguistics.Sofia,Bulgaria,2013:166-175. [11]罗维,吉宗诚,吕雅娟,等.一种改进词对齐的新方法[C].第五届全国青年计算语言学研讨会.2010:292-298. [12]沈世奇,刘洋,孙茂松.基于对偶分解的词对齐搜索算法[J].中文信息学报,2013,27(4):9-15. [13]梁华参,赵铁军.统计机器翻译中双语语料的过滤及词对齐的改进[J].智能计算机与应用,2013,3(4):10-14. [14]董振东,董强.《知网》[DB/OL].下载地址:http://www.keenage.com,1999. [15]刘群,李素建.基于知网的词汇语义相似度计算[C].第三届汉语词汇语义学研讨会,2002:59-76. [16]夏天.汉语词语语义相似度计算研究[J].计算机工程,2007,33(6):191-194. [17]张新国.系统工程手册[M].北京:机械工业出版社,2013:2-10. (责任编辑:刘划 英文审校:刘红江) Word-alignment algorithm combined with bidirectional dictionary and semantic similarity calculation YIN Bao-sheng,YANG Yang (Research Center for Human-Computer Interaction,Shenyang Aerospace University,Shenyang 110136,China) Word-alignment based on statistical method requiresa large-scale bilingual corpus as input,soit is difficult to avoid the problem of data sparse and the algorithmtime overhead.This paper presents anefficient word-alignment algorithm based on bidirectional dictionary and semantic similarity calculation to satisfy the demand for real-time alignment of sentence or paragraph level.The approximate translation of word-alignment problem due to the flexibility and diversity of translation can beeffectively solved by taking dynamic block segmentation and matching,semantic similarity calculation based on the HowNet,the conflict resolution based on the maximum matching and the pruning disambiguation.Compared with the standard algorithm,the experimental results show that the accuracy rate and recall ratecan be effectively improved bythis alignment method on a small-scalebilingual corpus and real-timealignment with better adaptability. word-alignment;bidirectional dictionary;dynamic block segmentation and matching;semantic similarity calculation 2014-10-08 辽宁省百千万人才基金项目(项目编号:04021401) 尹宝生(1975-),男,辽宁沈阳人,副教授,主要研究方向:知识管理和机器翻译,E-mail:ybs@ge-soft.com。 2095-1248(2015)02-0067-08 TP391 A 10.3969/j.issn.2095-1248.2015.02.014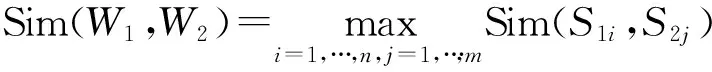
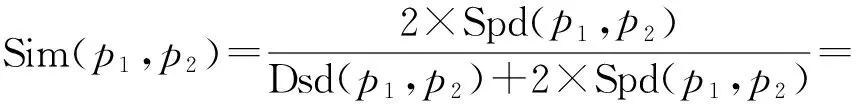

3 实验与分析
4 结语
