智能航运数据库群及交换技术研究
2015-04-29陈尚新叶建锋
陈尚新 叶建锋

摘 要: 船联网项目涉及到全国范围的内河航运数据,需要连通所有省级航运数据中心并接入数据,因此需要具备可扩展性强的航运数据群及交换共享体系。针对船联网项目中智能航运数据交换共享场景,参考国内外成熟的理论基础,提出一种星型模式的航运数据部署模式。这种模式可以完成海量航运数据的处理任务,满足上层航运信息服务的需求,并适应今后不断增长的航运数据交换共享需求。
关键词: 内河航运; 星型模式; 航运数据库群; 航运数据交换共享
中图分类号:TP399 文献标志码:A 文章编号:1006-8228(2015)12-18-04
Research on the database group and exchange technology for intelligent shipping
Chen Shangxin1, Ye Jianfeng2
(1. The Information Center of Zhejiang Provincial Transport Department, Hangzhou, Zhejiang 310009, China;
2. Zhejiang Collaboration Data System CO., LTD)
Abstract: The project of "Internet of Ships" involves nationwide inland river shipping data, needs to connect all provincial shipping data centers and access data, so it is needed to have a strong scalability of shipping data base as well as an exchange and share system. According to the exchanged and shared scene of intelligent shipping data in the Internet of Ships, and referencing to domestic and foreign mature theories, a star-like shipping data deployment mode is put forward in this paper. This mode can perform processing tasks of massive shipping data, meet the shipping information service needs, and meet the needs of the growing shipping data exchange and share in the future.
Key words: inland river shipping; star-like mode; shipping database group; shipping data exchanging and sharing
0 引言
船聯网跨区域智能航运数据库群及交换平台的开发,涉及面向海量数据的船联网数据资源库群部署交换模式,交换模式的研究对于后期船联网落地工程的具体架构及实施方案有重要意义。该项研究必须要通过理论与实践结合的研究思路,确定一种科学、稳定的数据库群及交换技术。我们通过大量的研究及实践,最终确定船联网跨区域智能航运数据的部署及交换采用星型模式[1]。
1 研究方法
跨区域航运数据资源库群的设计首先需要考虑数据库群在区域间的部署模式[2]。目前主流的面向共享的数据资源库群部署采用两种部署模式。
⑴ 网状数据资源库群模式,数据资源点对点进行共享。
⑵ 星型数据资源库群模式,数据资源通过中心节点进行共享。
我们采用对比法对两种部署模式的优缺点进行了总结,最终的对比分析结果如表1所示。
从表1可以看出我们的结论:星型结构比网状结构更加适合于船联网数据资源库群部署。
2013年,我们采用该模式对航运数据库群部署进行了实际部署测试。2014年,又采用了点对点的模式进行航运数据库群部署的试验。通过实际的部署对比和总结,确认星型模式具有结构清晰,实施简易,技术先进,可扩展性强等优点。因此我们认为,星型模式更加适合于航运数据库群部署。
经过实践和总结,确定了航运数据的交换与共享采用一个主控节点即中心节点,多个分节点的模式,即星型模式。以长三角地区两省一市为例,整个航运数据库群设置一个中心节点作为主控节点,各省/市的航运数据不直接进行数据交换,而是通过中心节点进行统一的数据接收与分发。每个省市均通过设置前置机实现与中心节点的数据交换。不同省份的数据,则通过内网由下属各地方海事局,港航管理局等,推送到前置机上。在中心节点上部署交换服务器,通过数据交换平台实现与前置机的数据交换,详情如图1所示。
主控节点即中心节点数据库存储并管理以基础数据和业务数据为核心的两类航运主数据。主要存储不同分节点上传的数据,并通过部署在中心节点的数据交换平台,对不同的航运数据作如下处理。
⑴ 对所有接收到的航运数据进行存储,中心节点将作为航运数据资源库的核心存储地,汇总各区域上传的数据。
⑵ 对于接收到的数据进行分类处理。如接收到一条江苏开往浙江船舶的报港签证信息,则将该信息实时的发送到浙江节点,以便浙江节点能够及时收到最新的航运数据。
⑶ 在每个省份的交通厅部署前置机,该前置机作为分节点与中心节点的数据交换中转站,同时作为不同网络连接的连接点。该前置机上将部署mysql,作为航运交换数据库,用以存储本省需要共享给其他省份的数据,以及存储中心节点推送的其他省份共享到本省的数据。
在前置机上,将会建立航运数据表。对每个相同业务信息会建立两个表,分别存储本省共享的数据和外省共享过来的数据。比如船舶基本信息表(CB01_JBXX),这两张表字段完全相同、字段格式完全相同。
船舶基本信息表(CB01_JBXX)——用以存储其他省份交换共享到本省的数据。
船舶基本信息表(BD_CB01_JBXX)——用以存储本省份交换共享到外省的数据。
在这两张表中,CB01_JBXX的数据是通过中心节点推送过来的,对于推送过来的数据,各省港航管理局将定时从该表获取到这些其他省份共享过来的数据,并将这些数据获取到其本地数据中心加以利用。而BD_CB01_JBXX表的数据,则是由各省港航管理局将共享的船舶信息定时推送到该表,由中心节点的数据交换平台进行统一的采集。根据业务逻辑,这些信息在中心节点存储后被分发到各省市前置机。
3 应用场景
3.1 船舶报港签证数据交换场景
以下讲述船联网两级分布式计算框架的应用场景,以及在各个场景下集群的计算扩展能力。
以一个典型的数据交换共享场景为例子,来说明航运数据如何在跨区域之间进行交换共享。
江苏发生一个船舶出港报港信息,该船舶为A,其目的地为浙江省。当江苏省海事局获取该信息后,发现是一条需要交换共享的数据,苏省海事局需将该船舶的基础信息共享给浙江。为此,江苏海事局可通过各种方式,将该数据按照前置机上BD_CB01_BGXX所规定的数据格式,组装好数据插入到该表即可。后续的船联网统一的数据交换平台会定时扫描该表并将该条数据抓取到中心节点,并将该条数据共享到最终目的地即浙江省前置机上的表CB01_BGXX。浙江省港航局可通过相应的方式,定时扫描CB01_BGXX表获取数据。
从上述流程中可知:
⑴ 对省节点和中心节点之间的数据交换共享,由船联网统一的数据交换平台负责;
⑵ 对省节点和各海事局、港航局之间的数据交换共享,由各区域自行负责实现。
3.2 签证流向动态总览
签证数据是船联网示范应用的核心数据。从某种程度上来说,船联网的核心业务需求即在于,浙江、江苏及上海如何更好的预先知道将要进入各自管理区域范围内的船舶信息,为监管跟踪工作做好准备。
系统的侧重点放在出港签证信息的展示上,在船联网课题8没展开之前,不同区域内发生的出港签证信息,其目的地港口是无法预先知道的。而通过课题8的工作,目前两省一市的船舶签证信息,已经实现实时共享。
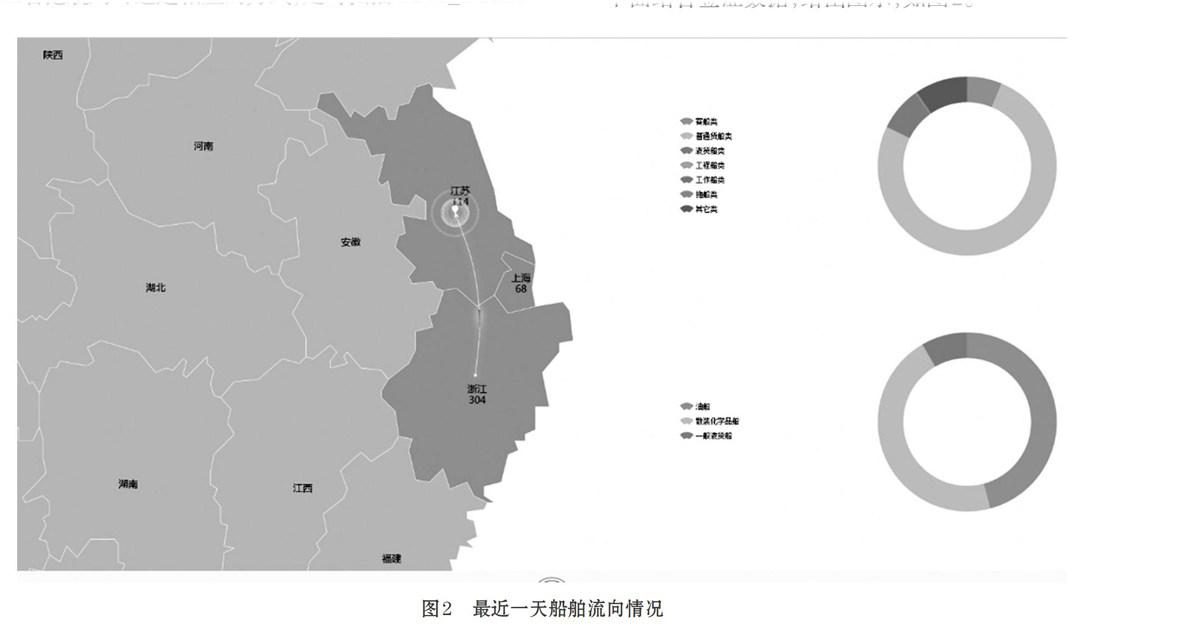
下面结合签证数据,给出图示,如图2。
图2显示了全国特别是长三角地区发生的出港签证动态数据。一旦在某个区域发生了一个出港签证信息,就会在该区域和该签证信息目的港所在的区域画一条动态流向线。表示有一条船发向了目的地。
在图2上重点突出浙江,上海,江苏三个区域的位置,在每个区域上显示一个饼图,每个饼图显示的是当天发生的所有出港签证信息中,目的港为该区域的按船舶类型划分的船舶数量。以浙江省为例,在浙江省所在区域的饼图上,显示当天发生的出港签证信息,目的港为浙江区域内的船舶数量。并且,根据船舶类型来划分饼图。船舶类型主要分为:危险品船(油船、沥青船、化学品船、液化气船)和普通船舶。
该系统界面在左上角提供一个下拉列表,供用户选择统计时间段,用户可以选择当天、最近两天、最近三天、最近五天、最近十天等发生的出港签证情况。
通过船舶报港签证数据的交换共享,准确的获取到不同目的地的船舶基本信息,如船舶是否是危货船舶,船舶的实时位置信息等。帮助相关地区的管理部门提前掌握即将进入其境内的船舶信息,从而提前进行相关的准备工作,加强安全监控。
通过基于GIS的船舶动态位置跟踪系统,任何地区的航运管理部门可实时精确定位到任意船舶的位置,以便在需要进行安全检查和突发事故应对等情况下,能够及时的定位船舶,迅速到達指定船舶位置,开展相关的工作。
4 结束语
基于星型模式部署的航运数据库群,可以在满足当前智能航运数据处理需求的情况下,充分考虑今后航运信息化发展中数据爆炸性增长的情况,以及节点逐步扩大时的数据交换共享要求。由于具备良好的扩展能力,今后的集群扩展成本将非常可控:平台不需要更换升级,只要不断增加节点即可提供不断增长的数据交换处理能力。随着具体航运数据交换共享需求的落地和实现,基于星型模式部署的航运数据库群将为跨区域航运业务数据交换共享提供更好的数据支撑。
参考文献(References):
[1] 江恭和,武友新,李庆华.虚拟数据交换子平台设计与实现[J].
计算机工程与设计,2012.33(10).
[2] 王鹏.关于建立长江航运综合数据仓库模型的探讨[J].信息
通信,2009.3.
[3] 杨成忠.网状数据库的设计与建库[J].计算机应用研究,
1987.1.
