一种双向混合查询树防碰撞算法
2015-04-26邓红卫孙艳平廖瑾芸
邓红卫,孙艳平,许 航,廖瑾芸
(衡阳师范学院 计算机科学与技术学院,湖南 衡阳 421002)
RFID技术是物联网应用系统中的核心技术,RFID标签识别是制约RFID技术发展的一项关键技术,标签碰撞大大降低了阅读器对标签的识别速度和识别率。因此,对防碰撞算法的研究是至关重要的[1]。
防碰撞算法主要分为不确定性算法和确定性算法两种类型[2]。不确定性算法随机性大,信道利用率低,会出现“饿死”现象;确定性算法签识别率高,但识别延迟率高。目前,有研究者结合两种算法的特点,探索出一些混合性防碰撞算法[3]。
本文在双向查询树算法基础上,正向根据最高和次高碰撞位的具体信息,动态生成查询前缀,逆向引入碰撞模板,减少标签识别的查询次数和通信量。
1 算法相关理论基础
1.1 查询树算法[4]
查询树算法简称为QT算法。阅读器从查询队列中选择一个查询前缀发送给标签,具有相同前缀的标签响应阅读器,如果只有一个标签响应,则正确识别该标签;如果有多于一个标签响应,则发生了碰撞,阅读器在查询前缀后加0和1,生成新的查询前缀,添加到查询队列中。通过不断地增加查询前缀的长度,直至所有标签都被正确识别。如有4个等待识别的标签ID号:0010、0110、1001和1010,其识别过程如图1所示。

图1 QT算法
1.2 混合查询树算法[5]
混合查询树算法简称为HQT算法,算法原理与QT算法类似,只是在发生碰撞时,阅读器在查询前缀后增加2位二进制数位:00、01、10和11,生成新的查询前缀,添加到查询队列中,通过不断地增加查询前缀的长度,直至所有标签都被正确识别。如有4个等待识别的标签ID号:0010、0110、1001和1010,其识别过程如图2所示。
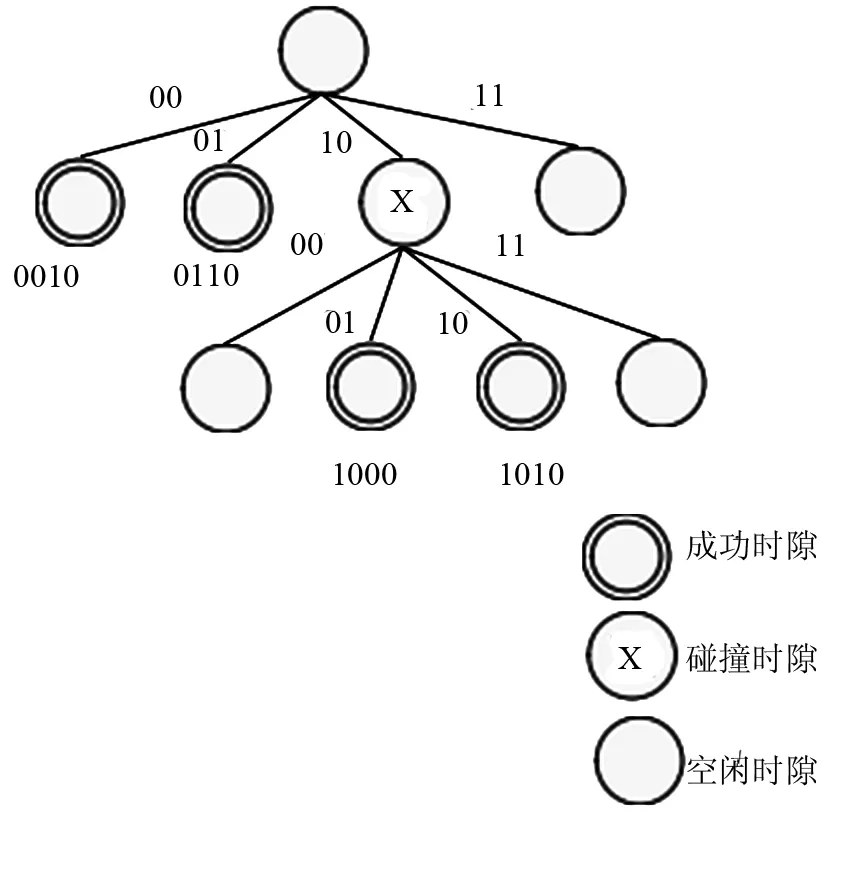
图2 HQT算法
2 双向混合查询树防碰撞算法
2.1 算法指令约定
为了充分利用已得到的碰撞位信息,减少查询次数和通信量,本算法对原有的算法指令进行了如下改进:
(1)碰撞距离(d):发生碰撞的数据位到标签中心位置的相对距离。dH和dL分别定义为高、低位碰撞距离之和,当阅读器收到发生碰撞的数据后,首先对碰撞位进行判别,即比较dH和dL的大小,然后再确定搜索方式。若dH>dL,从高位到低位进行搜索,直到将所有标签识别完毕;反之,即从低位到高位进行搜索。例如,阅读器接收到的数据为1x01x1x0,则各碰撞位所对应的碰撞距离分别为d1=3、d3=1、d6=3,计算出dH=3和dL=4,即dH>dL,采用逆向搜索方式。
(2)查询指令REQUEST。REQUEST指令中的参数设有单参数、双参数和三参数3种形式,分别有 REQUEST(#)、REQUEST(Ht,Hr)和 REQUEST(p,Ht,Hr)3 个 REQUEST 指 令。RE-QUEST(#)为最初查询指令,要求阅读器范围内的所有标签都得响应;REQUEST(Ht,Hr)中的 Ht和Hr是标签响应REQUEST(#)发生碰撞所得到最高碰撞位和次高碰撞位,REQUEST(Ht,Hr)要求标签计算组合HtHr的十进制值并存入自己的累加器C中;REQUEST(p,Ht,Hr)中的p为已知的前缀,Ht和Hr是以p为前缀的标签,p位置之后碰撞位中的最高碰撞位和次高碰撞位。
(3)选择指令SELECT。SELECT(ID)选择编号为ID标签,为读出或写入数据作准备。
(4)读取指令 READ。READ(ID)读出编号为ID标签中的数据。
(5)屏蔽指令 UNSELECT。UNSELECT(ID)让编号为ID标签处于非激活状态,对收到的REQUEST指令不作应答。
(6)碰撞模板CID。与标签ID位数相同,对应碰撞位均置0,其他位置不变。
2.2 算法描述
本算法根据双向混合查询树算法,先计算比较Dh和Dl的大小。若Dh<Dl根据最高碰撞位Ht和次高碰撞位Hr的组合XtXr值,决定标签推迟C个时隙响应阅读器,阅读器端设有两个查询队列Q0和Q1,Q0存放由最高碰撞位Ht和次高碰撞位Hr之间的Xt…Xr值构成新的查询前缀p,Q1存放新的最高碰撞位和次高碰撞位的组合(Ht,Hr),初始值都为空;一个统计Request指令发送次数的累加器k,初始值都为1,直到标签识别结束。若Dh>Dl根据逆向二进制算法碰撞位置0,其余位不变,request根据碰撞模板依次增加1,直到标签识别结束。算法流程如图3所示。

图3 算法流程图
假设阅读器识别范围内有N个等待识别的标签,阅读器首先发送Request(#),N个标签都响应,根据曼彻斯特编码原理解码生成相应的比特流。计算比较Dh和Dl的大小。
1)Dh<Dl
(1)从中取得最高碰撞位Ht,次高碰撞位Hr,构成一个新查询组合参数(Ht,Hr),插入到Q1队列的尾部。阅读器从Q1队列取出(Ht,Hr)生成查询命令Request(Ht,Hr),发送给标签。标签分别计算其第Ht、Hr碰撞位的组合XtXr对应的十进制值,存放在自身的累加器C中,然后根据自己的C值在对应的时隙中进行响应。
(2)某一个时隙中如果只有一个标签响应,则直接识别该标签,使用READ指令读出该标签中的数据,并使用UNSELECT指令屏蔽该标签。否则,进入第(3)步。
(3)某一个时隙中如果存在多个标签响应,可以推知最高碰撞位Ht和次高碰撞位Hr之间的Xt…Xr值,将它作为一个新的查询前缀p,按时隙顺序依次插入到Q0队列的尾部。同时,同一个时隙内响应的多个标签也会发生碰撞,碰撞位处在原来Hr位之后,从中取得最高碰撞位Ht,次高碰撞位Hr,构成一个新查询组合参数(Ht,Hr),按时隙顺序依次插入到Q1队列的尾部。
(4)阅读器分别从队列Q0和Q1的首部取出查询前缀p和组合参数(Ht,Hr),生成新的查询命令Request(p,Ht,Hr),发送给标签,要求前缀为p的标签响应。前缀为p的标签计算第Ht、Hr碰撞位组合XtXr对应的十进制值,并存入自身的累加器C中,然后根据C值在对应的时隙中进行响应。
(5)当队列Q0和Q1的值为空时,表明N个标签全部识别,算法结束。否则,返回到第(2)步。
2)Dh>Dl
(1)阅读器初始化指令序列号CID为全0。
(2)阅读器接收标签的反馈信息,要么没有碰撞,要么只有一位碰撞,这时,可直接识别。被识别出的标签,阅读器将继续依次发送选择指令、读取指令和去屏蔽指令。
(3)阅读器发送request请求指令之后,指令序列号CID自动累加1,并将作为下次发送request指令的序列号。
(4)当CID重新为全0时,识别结束;否则返回到(2)继续执行。
2.3 算法举例
假设阅读器识别范围内有8个等待识别的标签,标签的ID号为8位,如表1所示。
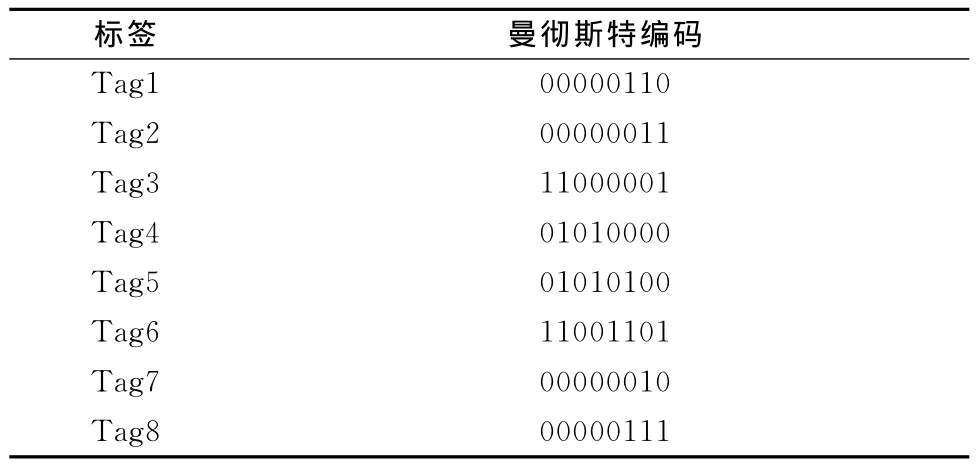
表1 曼彻斯特编码
算法的实现过程如下:
(1)阅读器初始化查询队列Q0和Q1,初值为空;初始化k=1。
(2)阅读器发送Request(#),阅读器识别范围内的所有标签都响应,根据曼彻斯特编码原理得到的解码信息为XX0XXX1X,如表2所示。根据碰撞距离计算Dh、Dl,Dh>Dl即逆向搜索标签。根据CID得到Request(00000010),标签7被识别。碰撞不变,Rwquest(00000011),标签2被识别。碰撞不变Request(00000110),标签1被识别。碰撞不变Request(00000111),标签8被识别。
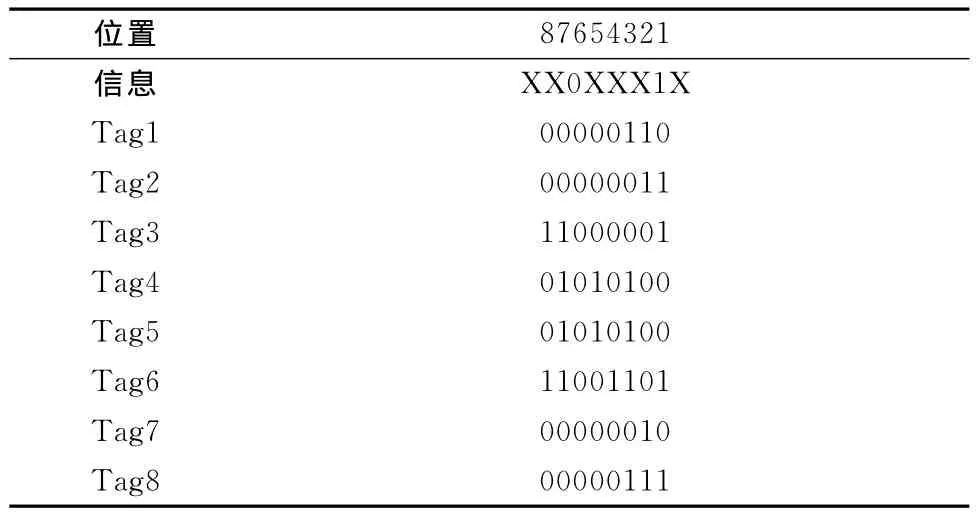
表2 碰撞位信息
(3)碰撞发生改变,剩余标签3、4、5、6碰撞为X10XXX0X,如表3所示。根据碰撞距离计算Dh、Dl,Dh<Dl即正向搜索标签。最高碰撞位为Ht=8,次高碰撞位为 Hr=5,将(Ht,Hr)=(8,5)存入Q1尾部,统计Request指令次数累加器k值为1,阅读器从Q1取出(8,5),生成新的询问命令Request(8,5),发送给标签。同时,k值加1。标签分别计算其最高和次高碰撞位(第8、5位)的组合XtXr对应的十进制值,存放在自身的累加器C中,然后根据C值在对应的时隙中响应阅读器。Tag3、Tag6的XtXr=10对应C=2,Tag4、Tag5的XtXr=01对应C=1,分别在时隙slot2、slot1中响应,都发生碰撞,如表4、5所示。

表3 碰撞位信息

表4 标签响应时隙
(4)表4表明Tag4、Tag5在时隙slot1中响应,Tag3、Tag6在时隙slot2中响应。Tag4、Tag5在时隙slot1中响应第3位置发生碰撞,碰撞位信息如表5所示。阅读器生成新的询问命令Request(01010,3),并发送给标签,标签4、5分别被识别。Tag3和Tag6在时隙slot2中响应,在第4和3位置发生碰撞,碰撞位信息如表5所示。
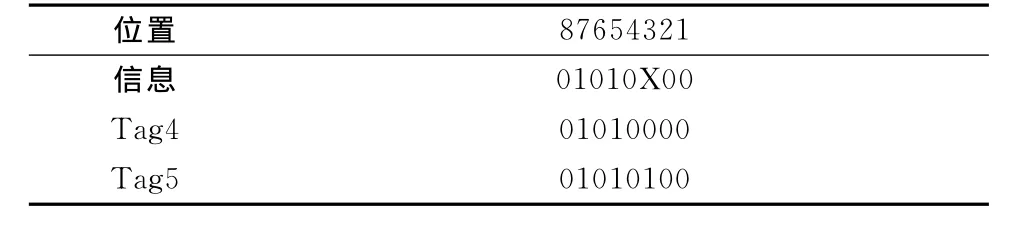
表5 标签碰撞信息

表6 标签碰撞位信息
(5)最高碰撞位为Ht=4,次高碰撞位为Hr=3,阅读器生成新的询问命令 Request(1100,4,3),并发送给标签,要求前四位(第8、7、6、5位)为1100的标签响应。Tag3和Tag6分别计算第4、3碰撞位组合XtXr对应的十进制值存放在自身的累加器C中,标签根据C值在对应的时隙中进行响应。Tag3的XtXr=00对应C=0,Tag6的XtXr=01对应C=1,分别在时隙slot0和slot1中响应并被识别,识别过程如表7所示。

表7 标签响应时隙
上述8个标签的识别过程与QT算法、HQT算法相比,减少了查询次数和系统通信量,算法效率明显提高。
3 算法仿真验证
本文使用Matlab仿真工具对该算法进行仿真验证。仿真结果在相同实验条件下,在识别次数和传输数据量等方面,将此算法与QT算法、HQT算法相比,在识别次数和传输数据量等性能有明显改善。如图4所示。

图4 BHQT、QT和HQT算法比较
4 结束语
本文在混合查询树防碰撞算法的基础上,提出了一种改进的算法,该算法比较碰撞距离之和的大小,正向根据最高和次高碰撞位的具体信息,动态生成查询前缀,充分利用已知位的信息,基本采用四叉树,逆向搜索方式利用基本二进制算法减少交互次数,标签识别的查询次数和通信量明显减少。仿真结果表明,该算法与基本二进制算法、动态二进制数算法、基本查询树算法、混合查询树算法相比,性能方面明显提高。
[1]杨晓娇,闫斌,谢光斌.一种改进的二进制防碰撞算法[J].计算机应用与软件,2013,30(10):312-316.
[2]米志强.射频识别(RFID)技术与应用[M].北京:电子工业出版社,2011.
[3]王春华,许静,彭关超,等.改进的RFID标签识别防冲突算法[J].计算机工程与应用,2011,47(31):104-107.
[4]Choi J H,Lee D,Lee H.Bi-Slotted tree based anti-collision protocols for fast tag identification inRFID systems[C].IEEE Communications Letters,2006:861-863.AND Feng Bo,Li Jintao,Guo Junbo,etal.ID-Binary tree stack anti-collision algorithm for RFID[C].Proceedings of the 11th IEEE Symposium on Computers and Communications(2006ISCC’06),2006:207-212.
[5]李秉璋,景征骏,罗烨.基于后退式二进制的RFID防碰撞搜索算法[J].计算机应用与软件,2009,26(12):96-98.
[6]Myung J,Lee W.An adaptive memory less tag anti-collision protocol for RFID networks[C].IEEEICC,2005:32-26.
[7]Hsu C H,Chia-Hao Yu,Yi Pin Huang,etal.An enhanced query tree(EQT)protocol for memorylesstag anti-collision in RFID systems [J].Second International Conference on Future Generation Communication and Networking FGCN ’08,2008:427-432.
[8]Ryu J,Lee Hojin,Seok Y,et al.A Hybrid Query Tree Protocol for Tag Collision Arbitration in RFID System[C]//Proceedings of the IEEE international conference on communications.Glasgow:IEEE,2007:5981-5986.
