槽填充中抽取模式的优化方法
2015-04-21沈晓卫李培峰朱巧明
沈晓卫,李培峰,朱巧明
(苏州大学 计算机科学与技术学院,江苏省计算机信息处理技术重点实验室,江苏 苏州 215006)
槽填充中抽取模式的优化方法
沈晓卫,李培峰,朱巧明
(苏州大学 计算机科学与技术学院,江苏省计算机信息处理技术重点实验室,江苏 苏州 215006)
在传统的信息抽取中,模式匹配已经被证实为简便而有效的方法,而依存路径也是最为常用的模式之一。在槽填充任务中就有众多的参与者引入了以依存路径为基础的模式匹配方法;该文就针对该方法中存在的包括模式平衡性,模式抽取方式和模式筛选策略等方面的问题,提出了模式裁剪、模式转置、模式扩展和模式语义定义等主要的优化方法并实现了相关系统,在TAC-KBP2010的目标语料上进行了测试。该文提出的方法F值为20.8%,比基准系统的14.3%提高了6.5%。
槽填充;模式优化;信息抽取
1 前言
传统的信息抽取评测如MUC和ACE主要还是关注在个别文档和领域限定文档上进行的相关抽取;但在实际中,很多的应用需要从开放的,规模较为庞大的数据源里抽取信息,进而用抽取到的信息实现对现有知识库(Knowledge Base, KB)的补充和扩展。这就需要系统能够正确辨别出数据源与知识库里已知实体间的一一对应关系,并能抽取出这些实体的相关信息。针对这样的需求,TAC于2009年提出了知识库填充任务(Knowledge Base Population, KBP),槽填充(Slot Filling, SF)是它的第二个子任务。
到2011年底TAC-KBP已经成功举办了三届,有众多的小组参与了其中的槽填充任务,提出了一些具有针对性的做法。这些做法主要可以分为两种,第一种是以传统的信息抽取方法为主体实现槽填充;另外一种则是以问答系统(Question Answering, QA)为基础,把每一个槽(SF中把实体的属性或信息称为槽,Slot)解析为对应的问题集合来实现任务。在第一种做法中,基于依存路径的模式匹配方法被较多的参与者所使用。本文即以该方法为基础,提出了方法中部分具有代表性的问题,并针对每一种问题提出了相应的优化策略,使得系统的综合表现相对基准系统有了比较可观的提高。这不仅说明了基准系统中确实存在着此类亟待解决的问题,也说明了本文探讨的部分优化方法是切实可行的。
文章的结构安排如下,第2节介绍了TAC-KBP槽填充任务的定义和相关工作;第3节主要描述了基准系统的实现过程;第4节探讨了系统中的一些问题和优化策略;第5节给出了加入相应的优化策略后系统的表现和对结果的分析;最后对全文进行了总结。
2 任务定义和相关工作
槽填充任务主要涉及到两个数据集,一个是已知的知识库(KB),它是由一个个独立的节点(node)组成的XML文件,每一个节点包含一个从维基百科(Wikipedia*http://www.wikipedia.org/)里获取到的实体和一段对该实体进行介绍的文本;另一个是数据源(Source Corpora, SC),是由新闻、博客、对话、录音等网络文本组成的(TAC-KBP的数据源共包含1 777 888份文档),用
来作为目标语料的文档集。
槽填充中目标实体分为PER和ORG两种类型,分别包含了26和16种预定义的槽。槽有单值和多值之分,单值槽如“per:date_of_birth”只有一个可能的值;多值槽如“per:siblings”有多个可能的值。槽的具体数据表现类型有Name,Value和String三种。Name表示一个实体名称或是一个专有名词,如John、IBM等; Value表示一个具体的数值,如时间、年龄等;String表示一个可陈述的事实(通常是一个短语),如死亡原因等。
从2009到2011平均每年都有20个以上的小组参与TAC-KBP相关的评测,其中对槽填充的两种系统实现方法中,主要以信息抽取方法居多;按照具体做法的不同,又可以分为基于模式匹配的方法和基于分类器的方法。绝大部分的系统都是以其中的某一种方法为主,但也有如CUNY[1]这样,综合使用了上述全部三种方法,而在最后对多个方法并行得到的备选答案进行排序和选择。相关系统的具体实现方法分类如表1[2]。
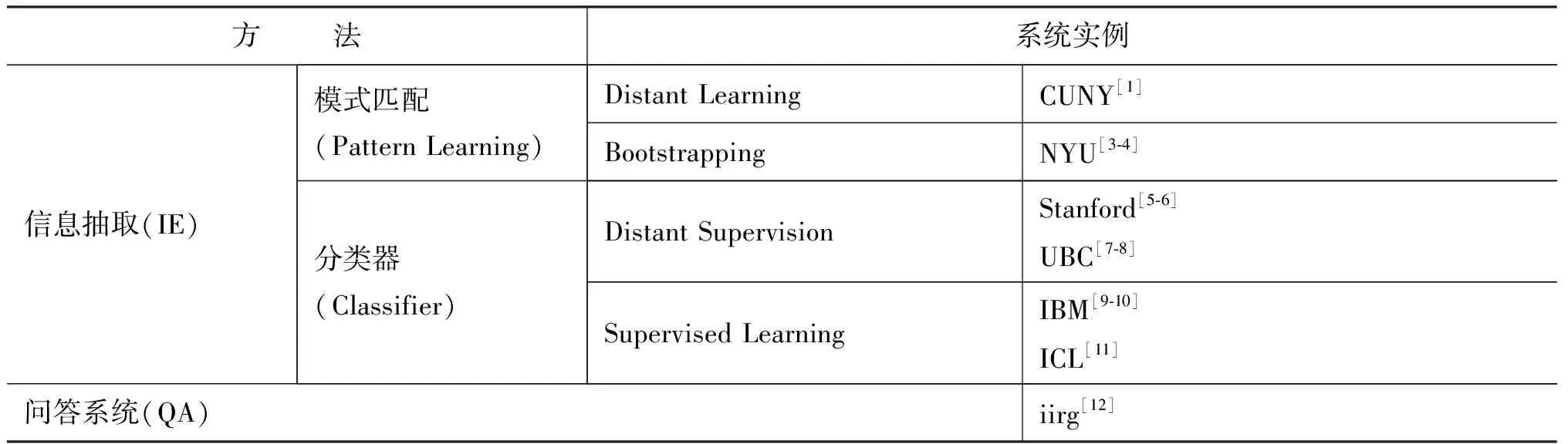
表1 系统实现方法
槽填充任务的评测指标不是很理想;Stanford[5]在以知识库的2/3为训练数据,1/3为测试数据时F值达到了56.7%,但其在官方评测上的F值却只有14.12%。虽然评测中作为TopSystem的IBM[9]系统的F值有28.2%,但多数系统的表现还是集中在10%~20%之间;如果不引入web知识库(如Wikipedia)或者语料库(如Freebase*http://www.freebase.com/, DBpedia*http://blog.dbpedia.org/),F值通常在15%。而IBM相对出色的表现则主要归功于他对于基础组件性能的提升,例如,IBM就针对槽填充任务扩展了与ACE并不兼容的命名实体类型,重新训练了实体探测器并且引入了DBpedia以获得更多的训练数据,才最终取得了比较优异的性能。这也间接表明传统的在正规或限定领域的新闻语料里训练出来的抽取组件在噪音较大的web数据上遭遇了很大的困境。而对TAC-KBP2010的训练数据的分析显示只有60.4%[2]的情况实体和槽是在同一个句子里出现的,22.8%[2]的情况下需要句子间的共指消解,其余的还包括句子间的推理,关系的传递和世界知识的辅助。
3 基准系统
本文参照了目前常用的一些做法, 实现了一个相对简单的基准系统(这里只选择了对两种目标实体中PER类型实体的抽取)。训练阶段的第一步是对知识库的处理,通过计算不同代词的个数确定性别并把对应的代词替换为实体名称,标示出每一个句子中实体的所有出现(由于做了替换,一个句子里同一个实体的名称可能会多次出现)和槽的第一次出现;第二步是从同时存在实体标示和槽标示的句子中抽取和选择出实体到槽合适的依存路径完成模式库的生成工作。测试阶段就是依据得到的模式库对测试数据进行抽取并给出相应的实验结果,基准系统结构如图1所示。

图1 基准系统结构图
(1) 模式库的生成
Stanford*http://nlp.stanford.edu/index.shtml总共定义了53种基本的依存关系,不同的依存关系在模式中的作用也是不一样的,有些表现为冗余成分, 有些则还会降低模式的有效性
而带来错误,所以抽取之前要对依存关系进行筛选,具体的筛选方法见表2,表中未列出的依存关系表示不做筛选,全部保留。

表2 依存关系筛选方法
模式具体表示为一条从实体到槽的依存路径,它是一个由词汇节点和依存关系节点组成的字符串,如从“per:spouse”的例句
中得到模式
nsubj_R
其中每一个节点结尾的“_L”和“_R”表示依存关系的中心词是在左边还是右边,模式最后的“
(2) 目标语料上的测试
对于槽候选项类型的定义采用命名实体和WordNet*http://wordnet.princeton.edu/相结合的方法(具体见表3);由于词汇存在多义现象,WordNet用编号(如country, SID-08426193-N)表示某一种明确的语义。具体的测试实现过程可以分为如下的几个步骤:
1) 候选文档的检索。以目标实体名称为检索关键字通过Lucene*http://lucene.apache.org/从目标语料(SC)里获取候选文档集;对于Lucene检索打分相同的文档优先选择文本长度更长者,以期待获取更多的信息。
2) 文档解析。用Stanford对候选文档进行句法, 依存和指代的解析并在每一个解析后的文档里
标示出指向目标实体的指代关系。
3) 预抽取。对“per:title”、“per: origin”和“per:religion”三种槽进行预抽取;如: 目标实体和“the driver”之间存在指代关系,而“driver”又符合“per:title”候选项类型的定义,那么“driver”就是“per:title”的一个备选答案。
4) 模式抽取和匹配。以目标实体的每一个指代项作为一个出现抽取出模式,进行匹配。对于名词和动词匹配同义和子义关系,对于形容词和副词,匹配同义,其它诸如冠词,数词等只匹配词性。
5) 备选答案选择。这里借用IBM[9]的打分方法,单值槽选择得分最高的一个,多值槽选择分数排名前三的(少于三个的则全部选择),具体的评分计算方法如下:
Score(Si) = count(Si) + 1/n * docCount(Si)
其中count(Si)表示备选答案Si的出现次数,docCount(Si)表示包含Si的文档的出现次数,n则表示所有备选答案的个数。

表3 候选项的实体类型和抽象语义
4 存在的问题和优化方法
上述的基准系统并不是很理想,F值14.3%也只勉强达到了现有系统的平均水平;通过细致的对比观察发现有些种类槽的模式库正确率比较低,这种情况的出现主要和模式生成的基础理论Distant Supervision[13]有关,Distant Supervision只在相对比较苛刻的条件下才能有良好的表现。例如,在一个人和他的出生时间这样比较单一的关系里Distant
Supervision就会有很优异的表现,但是在另外一种情况下,如一个人和他的出生地之间就可能包含多种的关系,他可能在那里上学、工作、结婚等等。所以在使用Distant Supervision时要对不同的槽附加相应的限制条件,除此之外训练数据和测试数据之间的平衡性、模式的裁剪和泛化等问题也同样急需解决。
(1) 模式的裁剪
模式库部分的模式里包含有一些对抽取没有贡献,但是却严重降低了模式覆盖率的词汇和依存关系,例如从句子:
得到一条“per:children”的模式:
nsubj_R
在这样的模式中

表4 裁剪方法
(2) 模式的转置
训练数据都来自知识库,而知识库和测试语料在表达上还是有很大区别的,这就带来了平衡性的问题。例如,知识库里在论述一个人父母的时候,大都会是: “他的父亲/母亲是谁”,这样实体在前槽在后的形式,而很少出现槽在实体前面的句子。但测试数据可以认为基本是平衡的,也就是说可能会有一半的情况是槽出现在实体前面,这就是一个显而易见的平衡性问题之一。模式的转置操作就是解决这个问题一种快速简单的方法;例如,抽取父母的模式,把头尾调转,就变成了抽取子女的模式,而如配偶这样的对等关系,转置后就可以直接作为本身的模式,具体的转置关系如表5所示。

表5 转置关系
转置的具体做法是这样的,例如对于模式
nsubj_R
首先把
dobj_R
(3) 模式的语义定义
基准系统只在测试阶段使用了有关语义的比较,实际上在系统的每个阶段都可以引入语义的辅助,特别是在模式库的生成阶段。例如槽“per:place_of_birth”对应的模式库,如果能在其中的一个模式中检测到表示“生育(bear/birth)”语义的词汇,那么这个模式确实能够正确表达槽关系的可能性就非常大了;但对于模式库中的所有模式而言,能够表达这种关系的并不一定都包含表示“生育”语义的词,例如,“John’s birthplace is China”,除却“birthplace”的歧义不谈,这个句子的模式中就没有显式的表示“生育”语义的词汇。另一个比较棘手的问题是并不是每一个槽都可以抽象出一个明确的语义或语义词汇,或者说半数以上的槽都很难用某一个语义囊括全部。例如,槽“per:children”,除了表达“子女(children)”的语义外,“父母(parents)”语义同样可以表达“子女”关系,甚至诸如“领养(adopt)”,“生育(give birth to)”,“怀孕(pregnant)”等也可以表达“子女”关系,但这都是建立在一定的世界知识基础之上的,而对于没有任何世界知识的模式而言,简单而有效的做法就是人为的为他定义一个语义集合。对于“place_of_residence”这样确实很难建立一个语义集合的,可以使用槽之间的语义差集关系来间接完成对语义的限定,即认为不包含“生育(bear/birth)”和“死亡(death)”语义的模式就是表达了“place_of_residence”关系的模式。
由于词汇的多义性,如何判断一个词到底表示哪一个语义又是一个难题,在模式库的生成阶段可以根据WordNet的编号确定一个唯一的语义,即如果模式库里的一个模式包含“bear”这个词,那么就可以把这个词的语义定义为“生育”,它在WordNet里对应一个唯一的编号“SID-00056206-V”,当然这个词也并不一定就表示“出生”,但由于它是出现在实体和槽之间的路径上,这是可能性最大的一个语义。测试阶段的二义性问题就比较难解决,折中的方法就是定义一个“停用词”表,如“have/deliver”也有表示“生育”的意思,但在系统中就可以认为它们是不表示这个语义的,而被标记为“停用词”。于是对于每一个语义都建立这样的一张词汇表最终组成一个“停用词”表。模式的语义定义具体如表6。

表6 模式语义定义
(4) 模式的扩展
在做如“per:children”和“per:parents”等槽的抽取时,从很多能够明显表征关系的句子中却无法得到有效的模式。原因主要是因为一些非主干性的成分不能被有效的捕捉到。基准系统中的模式只表示了实体和槽之间的主干关系,这样虽然可以大大减少无用的附加开销,但是在做如上述的槽抽取时,非主干性的成分也是非常重要的,有时候甚至是决定性的。例如从句子
得到的“per:parents”的模式只是一个简单的并列关系:
conj_and_L
显然这样的一个模式是没有任何的关系表征作用的,这里如果能够进一步地抽取出father和槽之间的“nn”修饰关系,这个模式才可以有更好的表现。具体做法是如果能在实体和槽之间找到表达模式定义的语义词汇,并且这个词汇和实体或是槽之间存在某种依存关系,就做一次模式扩展,那么上面的模式扩展后就变成了下面的:
conj_and_L<@@>nn_L < father[NN]><##>R
其中“<@@>”之后的部分表示是扩展的部分,“<##>”之后的“R”表示是对槽的扩展,相应的对实体的扩展就是“L”。
5 实验结果及分析
运用上述的四种策略对基准系统进行了优化,在模式生成阶段,用人为定义的语义对模式进行了筛选,并对部分种类的依存关系进行了裁剪,对有些种类槽的模式做了扩展和转置。
在测试阶段,对于定义有语义的模式,对语义词要求同基准系统相同的匹配规则,模式其他部分的依存关系和词汇节点,只做词性的匹配。对于没有定义语义的槽则采用和基准系统相同的匹配规则。为了检验方法的效果,在TAC-KBP 2010的数据上进行了测试,得到的结果如表7所示。

表7 实验结果
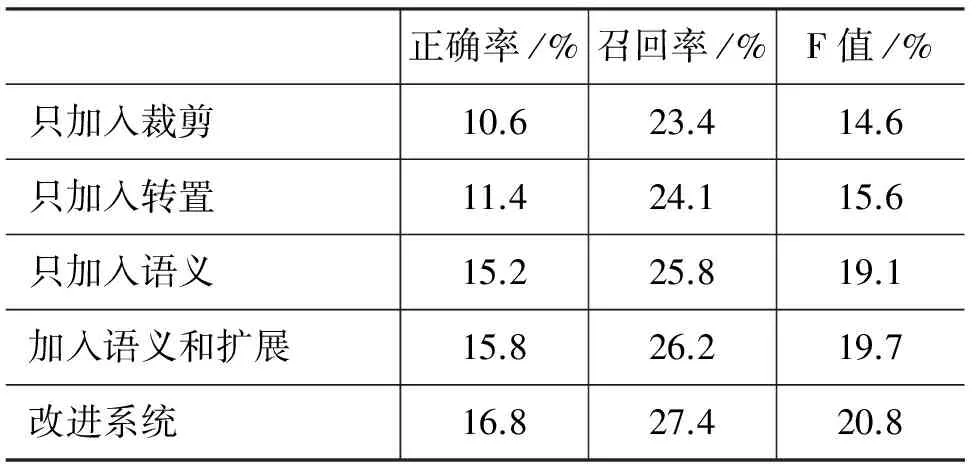
续表
从表中可以看出,每一种方法的加入,都提高了系统的表现。但是除了语义以外,其他三种方法对表现的影响比较小,都在2%以内;转置和扩展都只针对部分种类的槽,而这些槽在TAC-KBP 2010中的总体比重并不是非常大。而且现阶段转置和扩展的程度都比较低,转置仅仅局限于对部分槽人为的定义了对应的倒转关系,而扩展的条件也限制的太过严苛,如句子
中抽取的模式是
conj_and
由于在实体和槽之间没有可供扩展的语义词汇(只有一个“and”),模式无法扩展而被作为噪音丢弃,这就直接导致系统无法从目标语料里类似表达的句子中抽取出有效的信息。但是如果对扩展不加限制,那么对其引入的大量噪音如何消除就是一个严峻的问题,不然最后的结果可能是得不偿失的。
模式语义的加入对系统性能有了相对其他方法都大的提高,首先是它能很有效地对模式进行筛选,并且使模式里的不同节点有了地位高低的区分,而不再是所有的节点都同等对待,例如,“per:children”的一个模式
nsubj_R
在这个模式中只有两个词汇节点,分别是“live”和“child”,但是可以看出这两个词汇的作用差别是很大的,其中“live”几乎可以换成其他任何符合语法的词汇,而“child”则只能限制在它所表征的特定语义范围内。但本文模式语义的定义仍然是最初级的人工定义,而模式中的词汇节点也只是一刀切的分为了语义词和非语义词两类,如何能更好地解决这些问题也是今后工作的内容之一。除去上述的原因之外,基础组件的性能,如句法分析、实体识别等的性能也对系统有着比较大的影响,由于依存路径在很大程度上还是依赖句法分析的结果,如果句法分析有误,那么后面所有的工作都是错误的。实体识别更是如此[14],如果把一个地名识别为一个机构名,结果也是可想而知的。在很多情况下,槽并不能通过直接的模式获得,而是需要不同槽之间的关系传递,例如可能直接抽取一个人的“per:siblings”并不能得到答案,但是通过抽取这个人的“per:parents”的不同于本人的“per:children”槽也可以同样达到这个目的。
6 总结
传统的信息抽取如关系抽取在限定领域中已经有了70%以上的优秀表现,但是在面对开放的如网络文本类型的数据时就有了很大的问题。原因是多方面的,首先是基础抽取组件性能的下降,如在传统新闻语料上训练出来的实体识别组件在网页、博客之类的文本里表现就很大程度的下降了,同时下降的还有句法分析、指代消解等组件的表现。除了基础组件的问题,还有就是抽取方法的问题,在开放的数据源中,除了句法、指代等信息外,语义等信息也应该给予更多的关注。
实验的结果虽然说明我们提出的方法有一定的效果,但是仍然有很多的缺陷,而且这些方法有的只针对部分类型的槽,对其余类型的槽我们仍然没有找到很好的改进方法。
[1] Zheng Chen, Suzanne Tamang, Adam Lee, et al. CUNY-BLENDER TAC-KBP2010 Entity Linking and Slot Filling System Description[C]//Proceedings of Text Analysis Conference (TAC2010), 2010.
[2] Ralph Grishman, Heng Ji. Knowledge Base Population: Successful Approaches and Challenges[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics (ACL), 2011: 1148-1158.
[3] Ralph Grishman, Bonan Min. New York University KBP 2010 Slot Filling System[C]//Proceedings of Text Analysis Conference (TAC2010), 2010.
[4] Ang Sun, Ralph Grishman, Wei Xu, et al. New York University 2011 System for KBP Slot Filling[C]//Proceedings of Text Analysis Conference (TAC2011), 2011.
[5] Mihai Surdeanu, David McClosky, Julie Tibshirani, et al. A Simple Distant Supervision Approach for the TAC-KBP Slot Filling Task[C]//Proceedings of Text Analysis Conference (TAC2010), 2010.
[6] Mihai Surdeanu, Sonal Gupta, John Bauer, et al. Stanford’s Distantly-Supervised Slot-Filling System[C]//Proceedings of Text Analysis Conference (TAC2011), 2011.
[7] Ander Intxaurrondo, Oier Lopez de Lacalle, Eneko Agirre. UBC at Slot Filling TAC-KBP 2010[C]//Proceedings of Text Analysis Conference (TAC2010), 2010.
[8] Ander Intxaurrondo, Oier Lopez de Lacalle, Eneko Agirre. UBC at Slot Filling TAC-KBP 2011[C]//Proceedings of Text Analysis Conference (TAC2011), 2011.
[9] Dan Bikel, Vittorio Castelli, Radu Florian, et al. Entity Linking and Slot Filling through Statistical Processing and Inference Rules[C]//Proceedings of Text Analysis Conference (TAC2009), 2009.
[10] Vittorio Castelli, Radu Florian, Ding-jung Han. Slot Filling through Statistical Processing and Inference Rules[C]//Proceedings of Text Analysis Conference (TAC2010), 2010.
[11] Yang Song, Zhengyan He, Houfeng Wang. ICL_KBP Approaches to Knowledge Base Population at TAC2010[C]//Proceedings of Text Analysis Conference (TAC2010), 2010.
[12] Lorna Byrne, John Dunnion. UCD IIRG at TAC 2010 KBP Slot Filling Task[C]//Proceedings of Text Analysis Conference (TAC2010), 2010.
[13] Mike Mintz, Steven Bills, Rion Snow, et al. Distant supervision for relation extraction without labeled data[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, 2009: 1003-1011.
[14] 奚斌, 钱龙华, 周国栋, 等. 语言学组合特征在语义关系抽取中的应用. 中文信息学报, 2008, 22(3): 44-49.
Pattern Optimization for Slot Filling Task
SHEN Xiaowei,LI Peifeng,ZHU Qiaoming
(School of Computer Science and Technology,Soochow University,Suzhou, Jiangsu 215006,China; Key Lab of Computer Information Processing Technology of Jiangsu Province,Suzhou,Jiangsu 215006,China)
Pattern matching has been confirmed to be a simple and effective way in traditional information extraction, and dependency path is one of the most common patterns. There are a large number of researchers apply the pattern matching method based on dependency path in Slot Filling task. Focused on the issues of pattern balance, pattern extraction mode and pattern selection strategy in this task, this paper proposes some optimization strategies of pattern cutting, pattern reversing, pattern expansion and pattern semantic definition, and realizes a complete system. Tested in the TAC-KBP2010 target corpus, the F value of the proposed method achieves 20.8%, leading a 6.5% improvement against the 14.3% of the baseline system.
Slot Filling; pattern optimization; information extraction

沈晓卫(1989—),硕士,助理工程师,主要研究领域为信息抽取。E⁃mail:shenxiaowei@suda.edu.cn李培峰(1971—),博士,副教授,主要研究领域为信息抽取、情感分析和机器学习。E⁃mail:pfli@suda.edu.cn朱巧明(1963—),博士生导师,教授,主要研究领域为中文信息处理和机器学习。E⁃mail:qmzhu@suda.edu.cn
1003-0077(2015)02-0199-08
2012-11-01 定稿日期: 2013-01-09
国家自然科学基金(61070123);江苏省自然科学基金(BK2011282);江苏省高校自然科学重大基础研究项目(11KIJ520003)
TP391
A
