基于上下文的话题演化和话题关系抽取研究
2015-04-21章建,李芳
章 建,李 芳
(上海交通大学 计算机科学与工程系,上海 200240)
基于上下文的话题演化和话题关系抽取研究
章 建,李 芳
(上海交通大学 计算机科学与工程系,上海 200240)
自动挖掘大规模语料中的语义信息以及演化关系近年来已受到广大专家学者的关注。话题被认为是文档集合中的潜在语义信息,话题演化用于研究话题内容随时间的变化。该文提出了一种基于上下文的话题演化和话题关系抽取方法。分析发现,一个话题常和某些其他话题共现在多篇文档中,话题间的这种共现信息被称为话题的上下文。上下文信息可以用于计算同时间段话题间的语义关系以及识别不同时间段中具有相同语义的话题。该文对2008年~2012年两会报告以及2007年~2011年NIPS科技文献进行实验,通过人工分析,利用话题的上下文信息,不但可以提高话题演化的正确率,而且还能挖掘话题之间的语义关系,在话题演化的基础上,显示话题关系的演化。
话题;话题上下文;话题演化;话题关系
当今社会,信息即是财富,如何高效获取信息以及信息动态的变化趋势,是一个值得关注的问题。信息变化趋势可以反映科技领域的发展、新闻事件的变化以及其他任何人们关注的焦点问题的发展。话题[1-3]被认为是普遍关注的信息焦点,例如,“医疗改革”、“行政体制改革”等出现在“全国两会”新闻语料的典型话题。然而话题在不同时间段内可以具有不同的内容,例如,“住房”话题,2011年主要体现“房价上涨和土地供应”,2012年则转变为“保障性住房和房价调控”。因此,话题本身会随着时间发生变化,研究话题随时间的变化具有很重要的现实意义和实际应用背景。如何对话题内容的变化进行描述和分析,是本文话题演化研究的目的。
另一方面,话题之间也存在某种关系,如在2011年两会报告中,“财政预算”和“三公支出”会在多篇文档中同时被讨论,“司法”和“违法犯罪”也是如此。话题间的这种关系,可以通过它们在文档中共现信息表现出来。共现越频繁的话题,其语义关系也就越强。本文将某话题与其他话题的共现信息,称为该话题的上下文。利用话题的上下文,可以挖掘出同时间段中不同话题间的语义关系,让读者了解到不同信息之间是如何关联的。同时,话题的上下文还可以改进话题演化的结果。
话题内容不但随着时间变化,而且话题之间的关系也随着时间变化,如2010年两会中“教育”与“学术行政化”“大学生就业”“青少年心理健康”等关系较强,而2011年“教育”则与“人才培养”“高考”“财政预算”等关系较强。话题间的关系随时间的变化,能够让读者从更广泛的视角掌握信息的动态趋势。如何挖掘话题关系随时间的变化,是本文话题关系演化研究需要解决的问题。
本文的组织结构如下: 第一部分主要介绍相关工作;第二部分是研究方法的描述;第三部分是试验结果和分析;第四部分是结论和展望。
1 相关工作
基于话题模型的话题演化研究已得到了广泛的应用[4]。对多个时间段的文档集合进行话题演化分析时,主要包括两个步骤,即从每个时间段的文档集合中抽取出话题信息以及将各个时间段具有相同语义的话题进行关联。
话题的抽取,即从文档集合中挖掘潜在的语义信息,常用的方法是采用话题模型。目前,已有多种形式的概率话题模型[1],如PLSI模型[2],LDA模型[3]等,它们在建模过程中引入了潜在的随机变量—话题。近年来,考虑到文档集合自身的特点,很多研究工作对LDA模型进行扩展,以便模型更好地描述文档的生成过程,如ATM模型[5]引入文档的作者信息,DTM模型[6]引入文档的时间戳信息,STMS模型[7]同时引入文档的作者和时间信息,JST模型[8]引入情感标签,文献[9]中的模型引入文档间的引用信息等。
话题的关联,即将不同时间段中具有相同语义的话题对应起来。实现话题间的对应关系,一般可以采用两种方法,一是在话题建模时直接考虑话题间的对应关系(即前一时间段的话题影响后一时间段的话题),从而在话题抽取的同时也将话题间的对应关系挖掘出来,如DTM模型[6],CTDTM模型[10],文献[11];二是利用关联函数计算不同时间段中话题间的关联度,当两个话题的关联度满足相关阈值时,认为这两个话题具有相同语义,如文献[12-13]。方法一的缺点是,各个时间段的话题数量必须相同且话题间只具有一一对应的关系,其优点是可以在话题建模的过程中直接挖掘出话题间的对应关系;方法二的缺点是,关联函数的选择以及阈值的确定较为复杂,优点是各时间段的话题数量可以根据文档集合的大小进行调整,话题间允许一对多、多对一以及多对多的复杂关联关系。
除了通过话题模型来抽取话题外,还可以采用其它方式,如文献[14]通过文档的新颖性和重要度来判断是否有新话题的产生。而对于话题的关联,文献[14]则基于话题成员文档集合间的交叉引用数量来判断两个话题是否关联。
上述方法都认为同时间段的话题是互相独立,不存在任何关系。然而,现实世界话题之间是存在关系的,某个话题与其它话题在文档集合中存在共现,该共现信息可以作为话题的上下文。在词义消歧方法中,上下文信息可以识别该词汇的语义信息,解决词汇的一词多义问题;命名实体的指代消歧研究中,上下文信息可以用来识别同一命名实体[15-16],解决命名实体的指代,信息合并等问题。借鉴上述研究领域的思想,在已有工作基础上[13],本文提出了话题的上下文信息,既可以加强和识别话题本身的语义,有助于话题演化研究,同时,又能揭示同时间段中话题之间的语义关系。
2 研究方法
话题的上下文信息刻画了话题出现的语义环境。如果两个不同时间段中的话题具有相同语义,那么它们的上下文也应具有一定的相似性;相反,如果两个话题的上下文差异明显,那么它们具有相同语义的可能性较小。另一方面共现越频繁的话题,其语义关系越强。因此,本文提出的话题关联方法不仅仅考虑两个话题本身的内容,而且还依据上下文信息。有些话题在内容上较为接近(即在词汇分布上很相似),但实际上并不具有相同的语义,如表1所示的两个话题。

表1 内容相近的两个话题
2010年话题16涉及“三公支出”,而2011年话题6涉及“官员腐败”,这两个话题本身并不具有相同的语义。但由于这两个话题使用的词语较为接近,如官员、干部、行政等,仅仅通过计算这两个话题内容(即在词汇上的分布)的距离,容易将这两个话题识别为同义性话题。分析发现,话题16的上下文有关财政预算,而话题6的上下文是违法犯罪等法律相关的。因此考虑话题的上下文信息,可以有助于判断这两个话题不具有相同语义。表2和表3分别列出话题16和话题6的上下文信息。

表2 2010年话题16的上下文

表3 2011年话题6的上下文
下面列出本文主要使用的符号(见表4),概念定义以及方法介绍。

表4 本文主要使用的符号
2.1概念定义
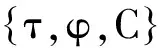
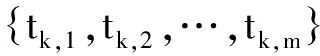
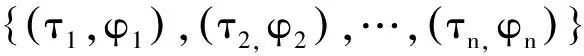
同义性话题: 不同时间段中具有相同语义的话题。如两会报告中2011年的“住房”话题与2011年的“住房”话题,虽然它们侧重的内容有所不同,但它们本质上都是住房相关的,因此它们具有相同的语义。
2.2 话题建模
LDA模型是一个生成概率模型,同时也是三层的变参数贝叶斯模型[17]。首先假设词由话题的概率分布混合产生,而每个话题是在词汇表上的一个多项式分布;其次,假设文档是潜在话题的概率分布的混合;最后,针对每篇文档从Dirichlet分布[18]中抽样产生该文档中的话题比例,结合话题和词的概率分布生成该文档中的每一个词汇。在进行LDA建模时,可以根据文献[19]提出的方法确定话题的个数以及利用GibbsSampling算法[20]对LDA模型的参数进行推导,从而得到每个话题的内容。
首先按照时间划分,然后对不同时间段的文档集合进行LDA建模。在对不同时间段的文集建模时,话题数量可以设置为相同,也可以不同。进行LDA建模后,可以直接得到各个话题的内容,即话题在词汇上的多项式分布,即话题的φ。
2.3 话题上下文抽取
在话题模型中,每篇文档表示为话题的混合分布,其中那些权重高的话题称为文档的显著性话题。如果两个话题同出现在某篇文档的显著性话题中,则称这两个话题存在一次共现。共现次数越多的话题,可以认为它们的语义关系越强。对于某个话题来说,它与同时间段中其他话题的共现信息,称为它的上下文。抽取话题上下文由以下三个步骤完成。
(a) 计算文档的显著性话题
对于每一篇文档,将话题的权重按降序排列,然后取出权重最大的3个话题作为文档的显著性话题。根据实验结果,权重最大的3个话题通常比其他话题的权重明显大,这符合常理。
(b) 计算任意两个话题间的共现次数
对于任意两个话题ti和tj,它们的共现次数可以表示为公式(1)。
(1)
而δ函数可以表示为
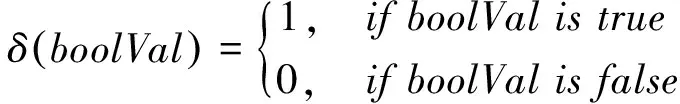
(c) 计算各个话题的上下文
对于任意话题tk,其上下文可以形式化地表示为(其中m为tk上下文中话题的个数)
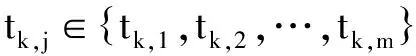
(2)
2.4 话题演化
话题演化需要判断两个不同时间段的话题是否具有相同的语义,即同义性话题。对于两个不同时间段的话题ti和tj,其距离计算公式如式(3)所示。
(3)

(4)

(5)
2.5 话题关系的抽取
事实上,同时间段中不同话题间存在一定的语义关系。借鉴词汇共现与语义关系,共现次数越多的话题,其语义关系也就越强。对于任意两个话题ti和tj,其语义关系强度表示为式(6)
(6)
即关系强度由wi,j和wj,i的调和平均值表示,其中wi,j和wj,i的计算可见公式(2)。
根据公式(6)可以计算出各时间段中话题间的语义关系强度,而根据公式(3)则能获得同义性话题。因此,结合这两者,便可以得到同义性话题与其它话题的关系随时间的变化,即话题关系的演化。
3 实验结果
本文选取的实验数据为两会报告(人大会议和政协会议,2008~2012年)的新闻语料以及NIPS科技文献(2007~2011年)。这是因为两会报告和NIPS科技文献中,很多话题会连续多年被讨论且话题内容随时间变化。选取不同领域、不同特点的语料作为实验对象有利于更全面地对本文提出的话题演化和话题关系抽取方法进行验证。
首先对实验数据进行语料预处理,包括分词,过滤停用词,去除低频词和高频词等,然后再利用LDA模型对各年的两会文集进行话题建模。表5列出实验数据及话题个数设置。实验包括三部分: 1)验证话题上下文信息抽取的精度;2)基于话题上下文的演化对比实验;3)话题关系的抽取结果以及分析。
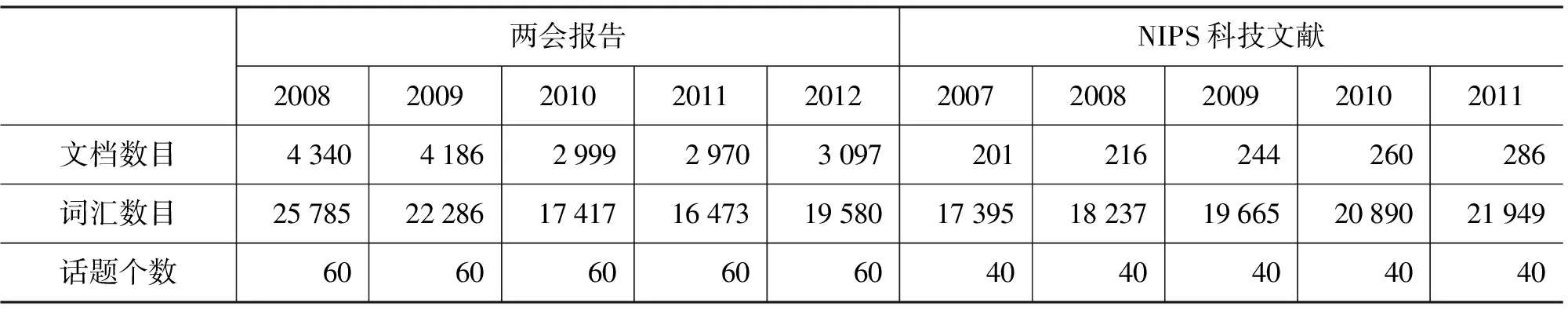
表5 语料信息及话题个数设置
3.1 话题上下文抽取实验
在计算每个话题的上下文之前,需要对建模后的话题进行一定的过滤: 首先通过信息熵过滤那些词汇权重分布均匀的话题,这类话题可解释性较差;其次,过滤高频话题,这类话题出现在很多文档中,语义特征不强。表6列出的是从两会报告和NIPS科技文献中抽取的上下文实验结果。

表6 话题上下文实验结果
正确的上下文表明话题上下文中的所有话题与该话题都具有明显的语义关系(通过人工分析);部分正确的上下文则表明话题上下文中存在部分话题与该话题有明显的语义关系,而另一部分则没有;错误的上下文则表明话题上下文中的话题都与该话题没有明显的语义关系。表7和表8列出的分别是从2011年两会报告和从2011年NIPS科技文献中抽取的正确、部分正确以及错误上下文的实例。

表7 2011年两会报告中上下文实例

表8 2011年NIPS科技文献中上下文实例
实验结果表明上下文话题中部分正确的所占比例较大,这主要与显著性话题选取的阈值有关,有些文档显著性话题会少于3个,而选取权重最大的前3个话题作为显著性话题则会引入误差。但总体上话题的上下文能够反映出话题之间的语义相关性,例如对于表7中话题9,其上下文中的话题59和话题8的权重分别为0.863和0.137。因此,根据实验结果,结合权重,话题的上下文能够描述与该话题的语义关系。
3.2 话题演化实验
本文在进行话题演化时,计算话题词汇分布差异的距离函数DistanceT以及计算话题上下文差异的函数DistanceM都采用KL距离函数,同时选择因子β设为0.7,关联阈值γ设为2.0(即两话题的距离小于2.0时,认为具有相同的语义)。
作为本文话题演化对比的方法一(简称基准一),在计算两话题的距离时,仅仅利用两话题间的词汇分布差异,不考虑话题上下文,计算两话题的距离公式为(7)。
(7)
同样,基准一中DistanceT采用KL距离函数,话题间的关联阈值设为2.0。
作为本文话题演化对比的方法二,则为DTM话题模型[6],该模型以前一时间段的分布参数作为后一时间段正态分布的先验, 在建模过程中直接挖
掘不同时间段的同义性话题。DTM代码实现来自网页信息*http://code.google.com/p/princeton-statistical-learning/downloads/detail?name=dtm_release-0.8.tgz。
表9是基准一方法,DTM方法和本文方法得到的话题演化对比结果。
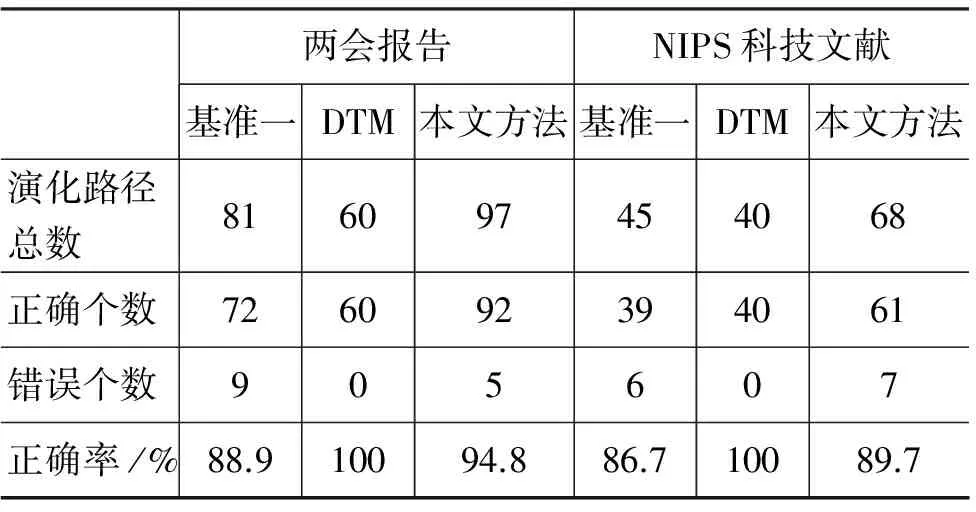
表9 话题演化实验结果对比
实验结果表明,DTM模型得到的演化路径都是正确的,话题一一对应,但不能很好地刻画话题内容随时间的变化(见下文演化实例)。而本文方法比基准一方法不但能找到更多的演化结果,而且提高了精度。例如,对于2010年的话题8{教育 教师 学生 纲要 人才 学校 培养 高考 公平 考试 资源},通过基准一和本文方法计算2011年中的同义性话题,如表10所示。

表10 2011年中与2010年话题8关联的话题
从上面的结果中可以看到,2011年中的话题15和话题30都涉及到教育,因此它们同2010年的话题8是具有相同语义,建立了演化关系。同时,增加上下文信息后,距离公式更加精确,例如,话题19、话题15和话题30距离有所减小(基准一方法中,这三者的距离分别为1.636、2.154、2.236)。因此,引入上下文后,使得同义性话题的计算受不同时间段词汇变化的影响减小,同时受阈值γ的影响变小。
图1是分别采用本文方法、基准一方法和DTM模型得到与教育相关的话题演化实例。DTM模型得到的演化路径{47, 47,47, 47, 47}中各话题是一一对应,没有话题分裂和合并;本文方法和基准一方法均获得演化路径{17, 20, 8, 19, 38}(学生教育话题的演化),和演化路径{17, 22, 39, 58, 44}(学生就业话题的演化)。本文方法还能得到演化路径{17, 20, 8, 30, 47}(与学生考试相关)和演化路径{17, 20, 0, 15, 16}(与人才培养相关),反映话题在更细粒度上的分裂与合并关系(话题内容见表11与表12)。
图2是分别采用本文方法、基准一方法和DTM模型得到与神经元相关的话题演化实例,表13和表14显示了各个话题的内容。DTM得到一条话题内容非常相似的演化路径,基准一方法同样得到一条演化路径,可以反映话题内容的演化。本文方法采用上下文,计算出话题37(涉及神经元)和话题16具有相同的语义。
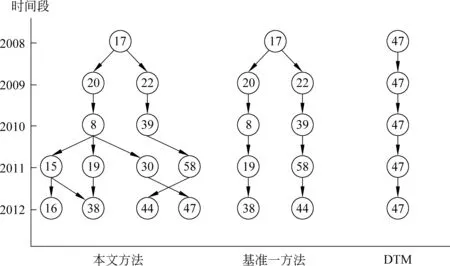
图1 两会报告演化实例
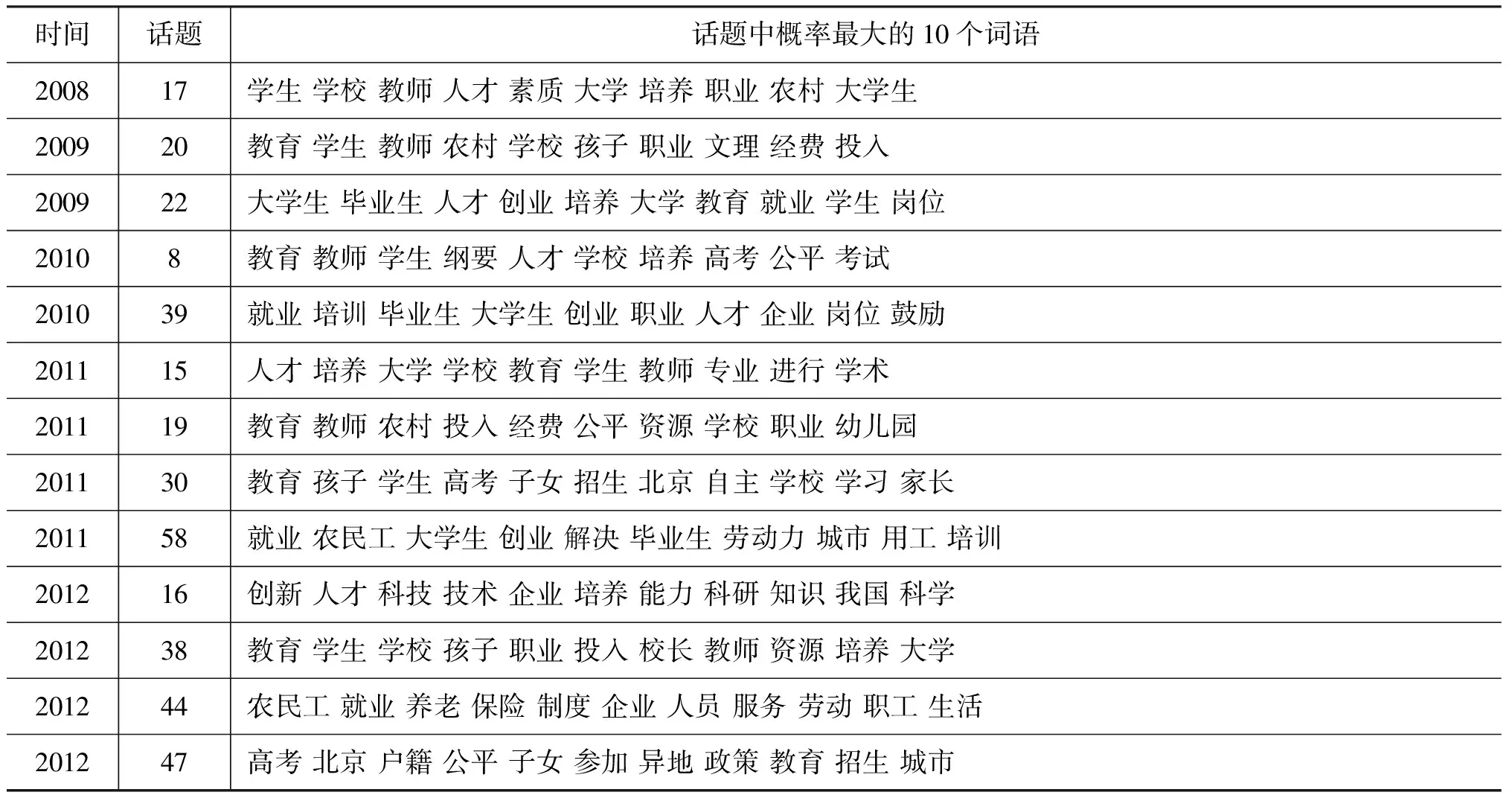
时间话题话题中概率最大的10个词语200817学生学校教师人才素质大学培养职业农村大学生200920教育学生教师农村学校孩子职业文理经费投入200922大学生毕业生人才创业培养大学教育就业学生岗位20108教育教师学生纲要人才学校培养高考公平考试201039就业培训毕业生大学生创业职业人才企业岗位鼓励201115人才培养大学学校教育学生教师专业进行学术201119教育教师农村投入经费公平资源学校职业幼儿园201130教育孩子学生高考子女招生北京自主学校学习家长201158就业农民工大学生创业解决毕业生劳动力城市用工培训201216创新人才科技技术企业培养能力科研知识我国科学201238教育学生学校孩子职业投入校长教师资源培养大学201244农民工就业养老保险制度企业人员服务劳动职工生活201247高考北京户籍公平子女参加异地政策教育招生城市

表12 图1中DTM模型各话题的内容

表13 图2中本文方法和基准一方法各话题的内容

续表
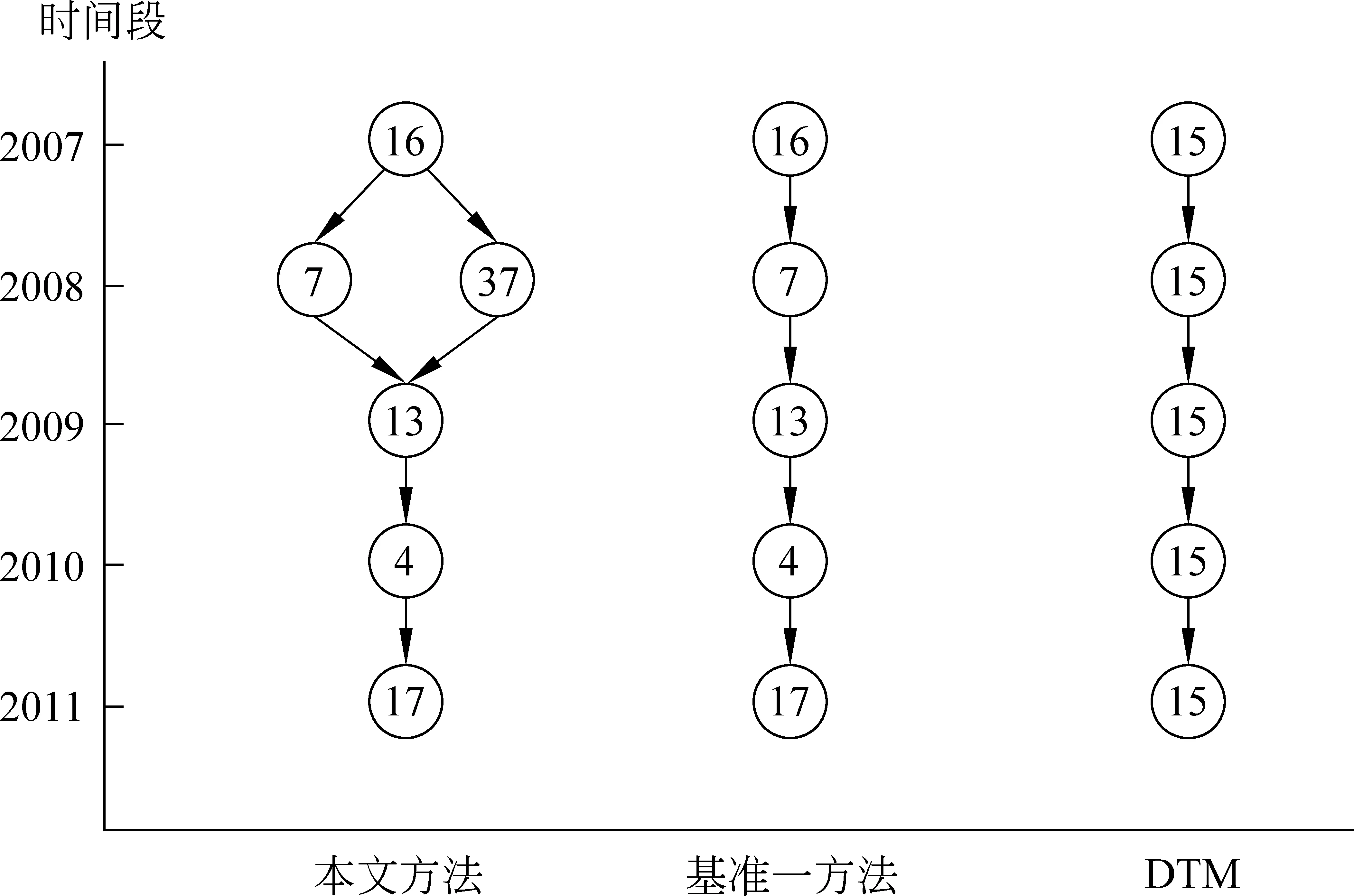
图2 NIPS科技文献演化实例
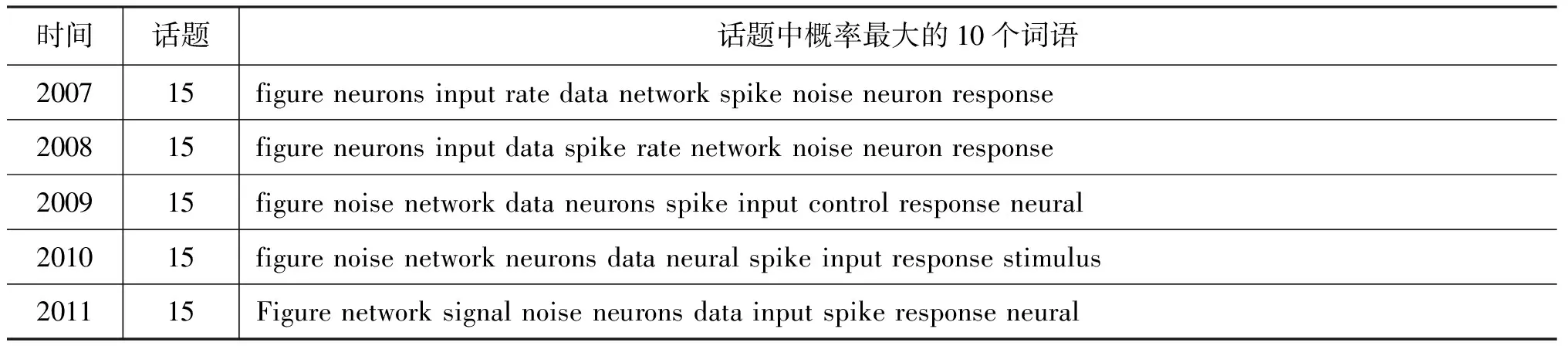
时间话题话题中概率最大的10个词语200715figureneuronsinputratedatanetworkspikenoiseneuronresponse200815figureneuronsinputdataspikeratenetworknoiseneuronresponse200915figurenoisenetworkdataneuronsspikeinputcontrolresponseneural201015figurenoisenetworkneuronsdataneuralspikeinputresponsestimulus201115Figurenetworksignalnoiseneuronsdatainputspikeresponseneural
3.3 话题关系的抽取与演化实验
由公式(6)可知,本文话题关系的抽取依赖于话题上下文计算的结果。对于某个话题来说,如果它的上下文正确,则形成的话题关系也正确;如果上下文部分正确,得到的话题关系也部分正确;如果上下文错误,得到的话题关系也错误。为了更直观地显示话题关系的抽取结果,这里将正确、部分正确和错误的话题关系分别给予数值1、0.5和0。表15是话题关系抽取的结果(等价正确个数=正确个数+0.5*部分正确个数),话题关系抽取的等价正确率在60% 以上。
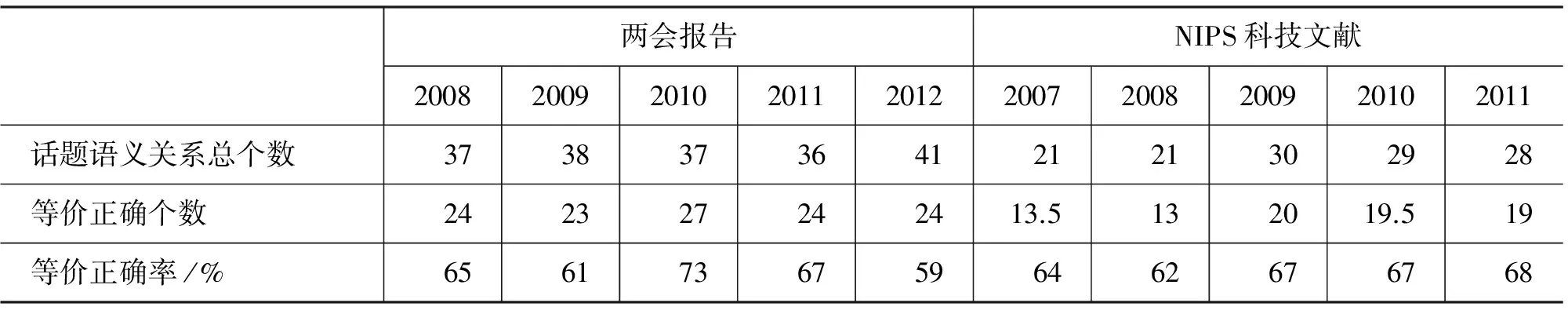
表15 话题关系抽取实验结果
图3所示为2009年两会报告中与话题20有关的语义关系图,话题间连线上的数字代表了关联的强度(公式6)。根据图3,话题20同话题22、48的语义关系最强,与话题12 ,45,31语义关系较弱,各话题内容见表16。
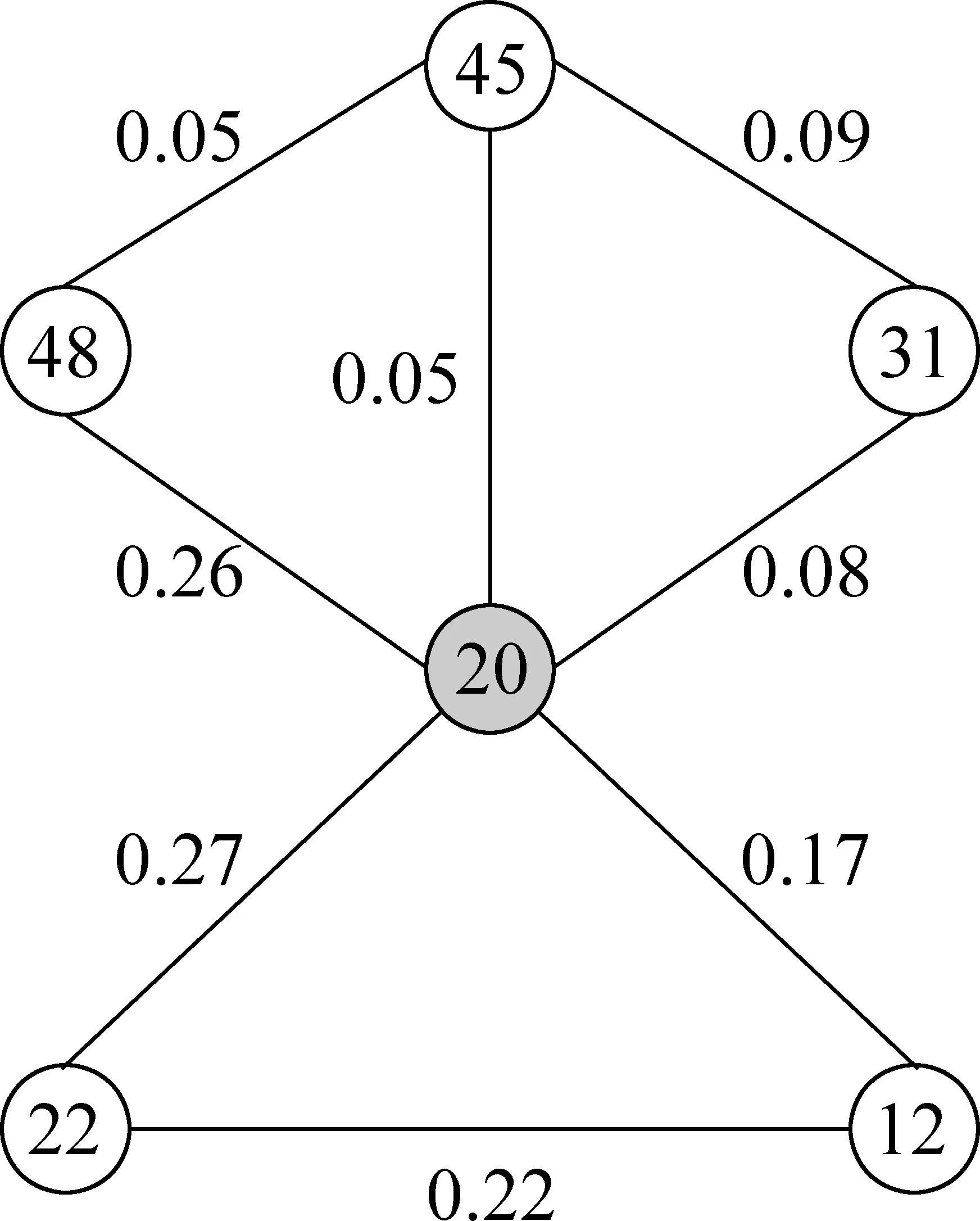
图3 2009年话题20的关系图
话题之间的关系也会随时间发生变化。选取图1中的一条演化路径{17, 20, 8, 19, 38}(有关学生教育),分别计算演化路径中各话题同其他话题的关系,结果见图4,对应话题的内容见表17。2008年,教育话题与话题50(民族艺术)关系相对较强(强度仅为0.14); 2009年,教育话题与话题22(大

表16 图3中各话题的内容
学生就业)、话题48(学术腐败)关系较强;2010年,教育话题与话题48(学术行政化)、话题39(大学生就业)关系强度分别为0.44和0.37,体现了很强的关系。根据表17中话题内容可知,2011年教育话题与话题15(人才培养)关联,2012年教育话题和话题47(异地高考)以及话题16(创新人才培养)具有比较强的关联。因此,通过演化路径上话题与其他话题的语义关系,反映了目前大学教育众多相关话题随时间的变化,对比话题的一条演化路径({17, 20, 8, 19, 38}(话题内容见表11),可以传递更多的内容信息。
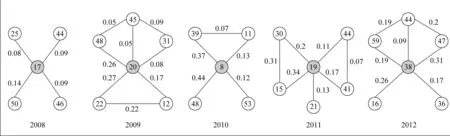
图4 两会报告话题关系演化实例

时间话题话题中概率最大的10个词语200850传统京剧艺术民族作品作家精神语言演出创作201048行政学术行政化级别教授大学学校校长权力认为201039就业培训毕业生大学生创业职业人才企业岗位鼓励201115人才培养大学学校教育学生教师专业进行学术201130教育孩子学生高考子女招生北京自主学校学习201247高考北京户籍公平子女参加异地政策教育招生城市201216创新人才科技技术企业培养能力科研知识我国
同样,在NIPS数据集上,选取图2中的演化路径{16, 7, 13, 4, 17}(有关神经元),分别计算演化路径中各话题同其他话题的关系,可以得到神经元话题同其他话题的语义关系随时间的变化,如图5所示,话题内容见表18。2007年神经元话题同话题34(图像分割)和话题3(脑信号噪声处理)关系较强;2008年,神经元话题同话题37(神经元)和话题11(脑成像)关系较强;2009年,神经元话题同话题31(人类学习记忆)和话题20(神经元模型)关系较强。这些关系体现了有关神经元技术在近几年的发展以及它与图像处理技术,脑信息处理等的关系。
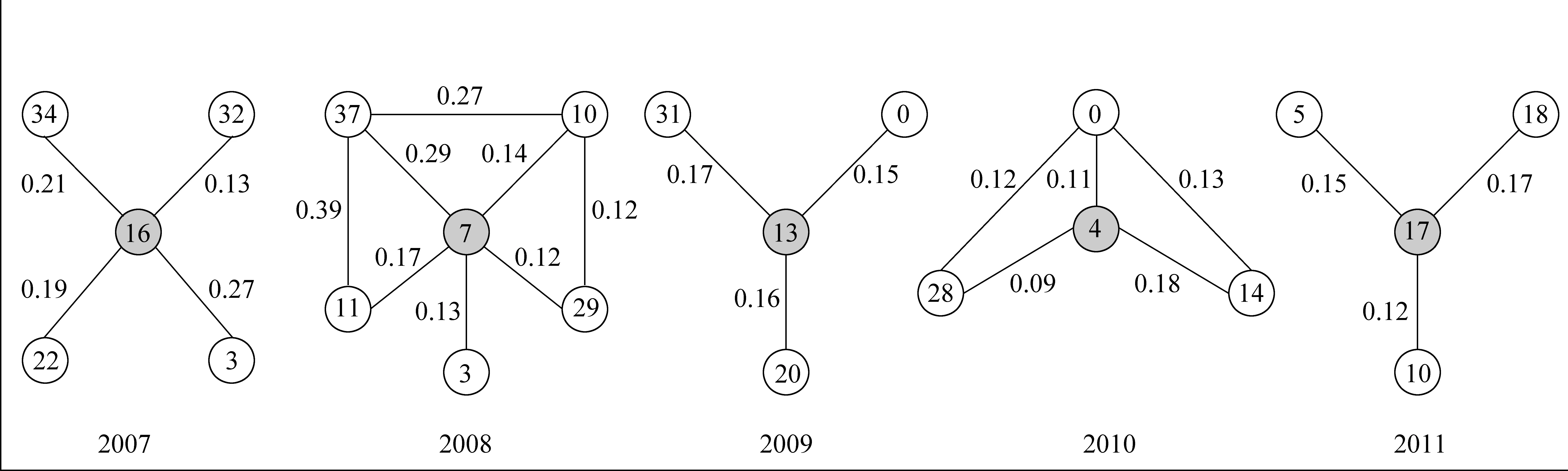
图5 NIPS科技文献话题关系演化实例
4 结论和展望
本文提出了一种基于上下文的话题演化和话题关系抽取的方法。首先利用LDA话题模型对各时间段的文档集合进行建模,挖掘潜在的语义信息,即话题。然后通过话题在文档中的共现关系,找到各个话题的上下文。其次,利用上下文信息改进了不同时间段同义性话题的计算,实现话题演化。最后,利用话题的上下文挖掘不同话题间的语义关系,同时结合话题演化的结果,还能得到话题关系在时间上的演化。
本文对两会报告和NIPS科技文献进行实验,结果表明利用上下文信息计算同义性话题,可以获得比基准一方法更多正确的演化结果,同时还能识别因词语使用接近但并非具有相同语义的话题。而与DTM模型相比,采用本文方法进行话题演化,可以得到话题的分裂、合并等复杂的对应关系,且能够较好地反映出话题内容随时间的变化。同时,利用上下文信息还能够挖掘出同时间段中不同话题间的语义关系,在结合话题演化的情况下,还可得到话题关系随时间的演化。本文的主要贡献是:
1) 提出了文档集合话题的上下文概念,并根据话题在文档中的共现,计算话题的上下文;
2) 利用话题的上下文,正确识别不同时间段同义性话题,从而改进了话题演化的结果;
3) 提出了话题之间计算其语义关系强度的公式,挖掘同时间段中话题间的语义关系。
本文提出方法还存在不足,如文档显著性话题个数的选择,如何动态确定某一文档的显著性话题个数,在引入话题的上下文信息的同时,删除其带来的噪音;另一方面,同义性话题计算方法中阈值的确定,如何更合理地权衡话题本身的语义信息与话题的上下文信息在话题演化中的重要性,还需大量的实验结果进行验证。LDA话题的标签如何自动生成以及演化结果的可视化技术将有助于本文提出方法的广泛应用。
[1] Steyvers M, Griffiths T. Probabilistic Topic Models. In: T. Landauer, D. S. McNamara, S. Dennis, W. Kintsch(Eds.), handbook of Latent Semantic Analysys[M]. Hillsdale, NJ. Erlbaum. 2007.
[2] Thomas H. Probabilistic Latent Semantic Indexing// Proceedings of the 22ndAnnual International ACM SIGIR Conference on Research and Development in Information Retrieval. Berkeley, CA, USA, 1999: 50-57.
[3] David M B, Andrew Y N, Michael I J. Latent Dirichlet Allocation. The Journal of Machine Learning Research, 2003, 3: 993-1022.
[4] 单斌, 李芳. 基于LDA话题演化研究方法综述. 中文信息学报, 2010,24(6):43-49.
[5] Michal R Z, Thomas G, Mark S, et al. The Author Topic Model for Authors and Documents[C]//Proceedings of the 20thConference on Uncertainty in Artificial Intelligence. Banff, Canada,2005.
[6] David M B, John D L. Dynamic Topic Models[C]//Proceedings of the 23rdInternational Conference on Machine Learning, Pittsburgh, Pennsylvania, 2006: 113-120.
[7] Ali D, Li Juanzi, Zhou Lizhu, et al. A Generalized Topic Modeling Approach for Maven Search. APWeb/WAIM 2009, LNCS 5446, 2009: 138-149.
[8] Chenghua Lin, Yulan He. Joint Sentiment/Topic Model for Sentiment Analysis[C]//Proceedings of the CIKM’09, Hong Kong, China, 2009.
[9] R. Nallapati, A Ahmed, E P Xing. Joint Latent Topic Models for Text and Citations[C]//Proceedings of the 14thACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Las Vegas, Nevada, USA, 2008: 542-550.
[10] Chong Wang, David M, David H. Continuous Time Dynamic Topic Models[C]//Proceedings of the 23rdConference on Uncertainty in Artificial Intelligence, 2008.
[11] Andre G, Alexander H. Topic evolution in a stream of documents[C]//Proceedings of the Ninth SIAM International Conference on Data Mining, 2009: 859-870.
[12] Mei Qiaozhu, Zhai Chengxiang. Discovering Evolutionary Theme Patterns from Text—An Exploration of Temporal Text Mining[C]//Proceedings of the KDD’05, Chicago, Illinois, USA,2005.
[13] 楚克明, 李芳. 基于LDA话题关联的话题演化.交大学报,2010:11:1496-1500.
[14] Jo Y Y, John E H, Carl L. The Web of Topics: Discovering the Topology of Evolution in a Corpus[C]//Proceedings of the WWW 2011, Hyderabad, India 2011.
[15] Xianpei Han, Le Sun. A Generative Entity-Mention Model for Linking Entities with Knowledge Base[C]//Proceedings of the ACL 2011. 2011: 945-954.
[16] Xianpei Han, Jun Zhao. Structural Semantic Relatedness: A Knowledge-Based Method to Named Entity Disambiguation[C]//Proceedings of the 48th Annual Meeting of the Association of Computational Linguistics, 2010: 50-59.
[17] Blei D, Jordan M, Ng A. Hierarchical Bayesian Models for Applications in Information Retrieval. In Bayesian Statistics, 2003,7: 25-44.
[18] Antoniak C. Mixtures of Dirichlet Processes with Applications to Bayesian Nonparametric Problems. Annals of Statistics, 1974,2(6): 1152-1174.
[19] Thomas L. G., Mark S. Finding Scientific Topics[C]//Proceedings of the National Academic of Science of United States of America, 2004.
[20] Ian P, David N, Alexander I. Fast Collapsed Gibbs Sampling For Latent Dirichlet Allocation. KDD’08, Las Vegas, Nevada, USA 2008.
Context-based Topic Evolution and Topic Relations Extraction
ZHANG Jian, LI Fang
(Department of Computer Science and Engineering, Shanghai Jiao Tong University, Shanghai 200240, China)
Automatic extraction of semantic information and its evolution from large-scale corpus has appealed to many experts and scholars in recent years. Topics are regarded as the latent semantic meanings underlying the document collectionand the topic evolution describes the contents of topics changing over time. This paper proposes a novel extraction method for the topics evolution and the topic relations based on the topic context. Since a topic often co-occurs with other topics in the same document, the co-occurrence information is defined as the context of a topic. Topics with its context are used not only to calculate the semantic relations among topics in the same period, but also to identify the same topics across different time periods. The experiments on NPC&CPPCC news reports from 2008 to 2012 and NIPS scientific literature from 2007 to 2011 have shown that the method has not only improved the results of topic evolution but also mined semantic relations among topics.
topic; topic context; topic evolution; topic relations evolution

章建(1987—),硕士,主要研究领域为话题探测与话题演化。E⁃mail:iamorchid@hotmail.com李芳(1963—),博士,副教授,主要研究领域为自然语言处理,信息检索与抽取。E⁃mail:fli@sjtu.edu.cn
1003-0077(2015)02-0179-11
2013-03-18 定稿日期: 2014-04-21
国家自然科学基金(60873134)
TP391
A
