在线评论信息挖掘分析的数据来源可靠性研究
2015-04-20李金海何有世
李金海+何有世
摘要:通过将研究分解成三个子任务,对网络数据从运用PageRank与TrustRank剔除作弊网页开始;借助结合网页间主题相关度、时间差以及在线评论比例的权重的TCPageRank算法,提炼与产品主题高度相关并包含大量在线评论数据的网页集;最后考虑了网页与产品主题的相似度以及网页的链接增幅对网页权威性的影响,运用改进的HITS算法,确定在线评论分析数据来源的权威网页集;而基于MapReduce的矩阵分块运算,降低了算法时空的复杂度。并通过仿真实验验证了该方法的可行性与准确性。
关键词:在线评论;PageRank;主题漂移;链接增幅
DOI:10.13956/j.ss.1001-8409.2015.04.21
中图分类号:F71355 文献标识码:A 文章编号:1001-8409(2015)04-0094-06
Analysis of Reliability Data Source on Online Reviews Information Mining
LI Jinhai, HE Youshi
(School of Management, Jiangsu University, Zhenjiang 212013
)
Abstract:Through resolve the research into three subtasks, starting from operation PageRank and Trust Rank eliminate cheating page of network. Refining web page of high topic relevance by TCPageRank combined topic relevancy between web pages and weight of time difference and reviews on web page. Finally, thought of similarity between page and topic of product and amplification of page have the influence on the web authority, determine the authority of the web page of online review analysis data source by the improved HITS. The partitioning of matrix operation based on Map Reduce, reduces the time and space complexity of the algorithm. And through the simulation experiments it verifies the feasibility and accuracy of the method.
Key words:online reviews; PageRank; topic drift; amplification of page
引言
据CNNIC报告,2013年我国新增网民5千万人,互联网普及率近46%,处于世界平均水平之上,其中网络购物人数占网民的50%,中国预计将于2015年成为全球最大的网购市场[1]。
网络购物的劣势在于无法亲自感受商品,因此越来越多的网购者通过浏览大量的在线评论来了解产品以及服务的口碑,依此作出可靠的决策[2]。
但是面对海量评论,消费者无法快速辨别和利用有价值的信息来作出正确的决策。因此针对在线评论挖掘的研究被学者们所关注,Senecal等认为在线评论影响消费者的购买决定[3]。Popescuam等将在线评论挖掘细分为4个子任务:特征抽取、观点抽取、极性判断、结果的汇总[4]。廖成林等借助亚马逊商城的样本进行实证研究,分析了在线评论有用性的影响因素以及各影响因素之间的作用机制[5]。龚艳萍基于ELM视角构建了消费者处理在线评论的双重路径模型,并探讨了在线评论的属性对消费者采用新技术产品意愿的影响机理[6]。
目前关于在线评论的研究集中于评论内容挖掘模型以及评论有用性的研究,鲜有学者关注在线评论数据来源可靠性的研究,而可靠数据的获取是研究的基础也是关键的一步。
1可靠在线评论数据源的挖掘流程
若要在海量的网络数据中获得可靠的评论数据,除了优秀的网页采集工具外,确定所要采集的数据来源是关键。传统的用于在线评论分析的数据大多数来自购物网站,这些数据来源的优势在于分类明确、内容精简。这些评论数据可以应付简单的在线评论的特征挖掘,但是短文本的劣势在于句式不完整,缺乏作者主观情感的表达,不利于评论的情感分析,而在线评论信息的有效挖掘不仅是对产品特征的提取,更是对作者情感倾向的分析,缺乏情感表达的在线评论对于消费者的购买决策不能产生决定性的影响。
因此挖掘网络中除了购物平台之外的在线评论具有必要性,使对在线评论研究的数据源不再局限于购物平台,扩大在线评论领域的研究边界。也可以为其他领域研究的数据来源确定提供可行的思路。
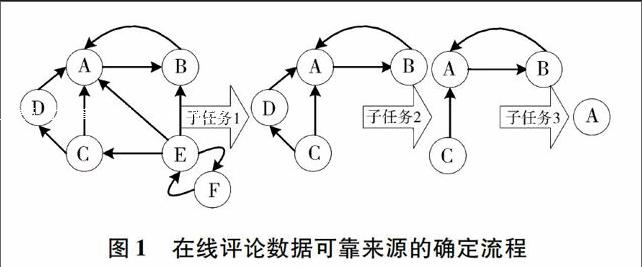
本文将从海量网络数据中确定的可靠的在线评论数据来源分为三个子任务,如图1所示,其中A、B、C是与产品主题相关的网页集合,首先辨别可靠网站A、B、C、D,其次从可靠的网站中提炼出与所需分析产品相关的主题网站A、B、C,最后从主题网站中确定当中的权威网站A作为在线评论分析的数据来源。
任务1需要使用的算法是PageRank,任务2需要使用的算法是TCPageRank,任务3使用的算法是HITS。
2关键算法的流程
21PageRank算法及改进
PageRank算法是谷歌搜索取得成功的关键技术,是对网页重要性进行排序的一种方法[7]。但是在经济利益的驱使下,作弊者基于链接作弊等手段欺骗PageRank以改变作弊网站的重要性,使得通过传统PageRank并不能得到满意结果。PageRank表示如下:
v′=βMv+(1-β)e/n(1)
将PageRank以向量的形式表示,利于海量节点数的网页的PR值计算,其中β(0<β<1)为阻尼系数,通常取值085,M为转移矩阵,v为本次迭代中所有节点的PR值组成的向量,n为所有节点的总量,e为n维单位列向量。
为了解决链接作弊,辨别网络中的可靠网站,在任务1中引入TrustRank对PageRank加以改进,TrustRank是面向主题的PageRank的变形,这里的“主题”不是网页内容主题,而是一个可靠的网页集。TrustRank可以避免链接作弊的思想,作弊网页可以自动链向可靠网页,但是可靠网页不会链向作弊网页,因此算法迭代的第一步设定随机跳转集合时需选择一个可靠的网页集。
改进的PageRank的流程是:①计算传统的PR值r;②计算TR值t;③设定一个阀值。
l1=(r-t)/rl1>05作弊网页l1≤05正常网页 (2)
l1表达的是网页PR值中属于垃圾的比例。这样就可以在任务1中去掉那些具有较高垃圾质量的作弊网页。
22TCPageRank算法及改进
从式(1)中看出,由于PageRank仅利用网络的链接结构进行排序,使得该算法存在主题漂移以及偏重旧网页的缺点[8]。因此任务1中得到的网页集虽然很大程度上排除了作弊网页,但总量仍然过大,且存在大量非相关的网页,产品的更新换代对评论的新鲜度提出了要求,所以应剔除过时的评论或减少它们的影响。
但并不是所有的网页都含有在线评论的内容,因此还需要辨别网页中含有在线评论的比例,这主要通过衡量网页中产品特征词及情感词占整个网页特征词的比例来赋予网页不同的影响权重。
根据网页主题的相关度来分配权重可以有效解决主题漂移问题[9],网页主题的相关度通过向量空间模型计算,设网页u和v的文档向量形式:
U=u1,u2,…,um,V=v1,v2,…,vm
其中ui和vi表示特征词i在各自网页中的指标值,通过TF.IDF计算:
w(v,u)=U·VU×V=∑mi=1uivi∑mi=1u2i∑mi=1v2i(3)
并用W(c)表示网页v在网页u所有出链中所占的权重,其中F(u)表示u的所有出链。
W(c)=W(v,u)∑p∈F(u)W(p,u) (4)
针对偏重旧网页的问题,也通过降低权重的思想来降低旧网页的主题相关度,假定网页搜索到的时间t1与其最近一次更新时间t2的差值越大,则网页主题相关度越低,引入时间差的权重函数W(t):
Wt=dt1-t2 (5)
可以看出,时间差与权重成反比,其中d为根据实际产品设定的常数。
在此基础上,添加网页的在线评论比例权重,对网页文档中产品属性特征词的挖掘采用的是Apriori算法,并且结合了依存句法分析来提高挖掘精度;在线评论中情感词往往是对产品属性特征词的评价,本文基于HowNet的情感本体库采用模板和距离的方法来提取网页中评论的情感词,该方法的优势在于:①模板匹配的速度较快;②在线评论的文本不同于企业发布的产品信息,具有不规范性,而该方法对文本的规范化要求较小。
若网页v的文档向量形式是V=v1,v2,…,vm,共有特征词m个,设v经过统计的产品特征词有i个,情感词有j个,则v含有在线评论的权重:
W(v)=i+jm-(i+j)m(6)
W(z)=W(c)∑p∈F(u)W(p) (7)
考虑到每个网页含有的文本内容总量不同,式(6)、式(7)保证了含有大量文本内容同时含有大量在线评论的网页可以获得更高的权重。加入时间差与评论数据比例的权重函数的TCPageRank如下:
v′=βMv×W(c)×W(t)×W(z)+(1-β)e/n(8)
设定阀值l2,网页的TC-PR值大于等于l2的判定为与产品主题高度相关的网页。
23HITS算法及改进
HITS算法与PageRank算法的区别在于,PageRank将网页看成只有一维的重要性,而HITS将网页看成具有二维的重要性。任务3的作用是从已确定的海量主题网站中提取一定量的权威网站作为在线评论数据挖掘的来源。
HITS是WEB结构挖掘算法,通过分析网页间的链接关系,找出其中的权威网页[10]。但在构建WEB邻接图时,根集是与主题相关的,而基集的扩展只考虑了与根集的链接情况,忽略了主题相关性,会引入大量与主题相关度不大的网页,这样最后得到的权威网页并不是需要的。基于TC-PageRank的思想,在基集扩展过程中加入网页主题的判断,使得选入基集的网页是与主题高度相关的。
考虑到网购产品更新换代较快,关于产品的在线评论相应地也需要最新的。但是新的在线评论网页与其他网页之间的链接较少,使得权威值较小。本文认为权威网页的确定不仅需要考虑链接数量,也需要考虑网页的链接增幅情况,若一个网页的链接数快速增长,说明它具有一定的参考性。基于上述两点改进,提出一种混合页面相似度和链接增幅的HITS算法。
将产品主题和网页内容用向量表示,产品主题t=t1,t2,…,tn。改进后的HITS在选取以及扩展根集R时,除了考虑网页之间的链接关系,还要将网页p与产品主题进行相似度计算,若相似度小于阀值l3,过滤网页p;在此基础上,计算权威值。
相似度的计算是把每个网页p表示成向量形式:
其中λ、μ是权重因子,用于平衡网页主题相关性和网页链接增幅对网页的影响,LT是链接矩阵L的转置矩阵,即若存在网页j到i的链接,则LTij=1,否则LTij=0,设定阀值l4,权威值a≥l4的网页确定为与产品主题相关的权威网页。
3实验仿真
本文以百度搜索引擎作为实验数据来源,以手机、电脑、笔记本、相机作为产品主题,通过运用上述方法确定用于在线评论信息挖掘分析的可靠数据来源。
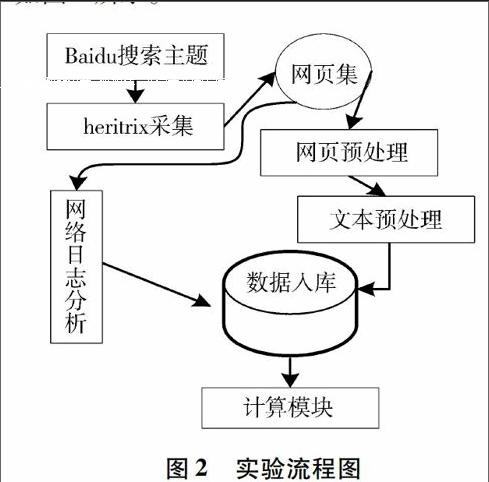
用网络爬虫在百度上采集实验设定产品主题的网页,以采集到10万个网页为停止条件。数据采集完后,进行网页预处理、文本预处理等操作后,将所需数据输入计算模块。如图2所示。
31实验数据预处理
实验网页集是在百度搜索引擎上基于产品主题采集来的,其中包括百度推广、广告等大量的噪声信息,网页预处理用于清洗此类网页,清洗后的网页数为9万个;而文本预处理是为了建立网页的特征词向量,以及通过网络日志,记录下网页被搜索到的时间t1与其最近一次被更新时间t2的差值及两次搜索间网页链接的增幅情况等。
网页预处理的下一步是统计网页的前向与后向链接,建立转移矩阵M,维数为90000×90000,部分转移矩阵:
32基于MapReduce的矩阵计算
实验中的矩阵计算选择MapReduce[11],是因为PageRank等算法的迭代次数较多,时空复杂度较大,而基于MapReduce的矩阵运算,可以通过矩阵分块,减少迭代次数,从时间与空间上都能得到性能的提升。
针对式(1),向量v表示所有网页的PR值,本次实验中v的维数只有9万,但是系统的实现是在整个WEB环境下的,这时v的维数是数以亿计的,向量v是无法直接放入内存的,而且基于效率考虑,转移矩阵M按列存储,M的每一列都会与v′的每一分量有关,这时当向v′的某一分量添加某一项时,v′的分量未存储在内存中,导致添加某一项时需要将页面转换到内存之后才能完成,这就造成了内存抖动使计算时间呈数量级的增长。
基于此,本文将转移矩阵M分为k2块,向量v分为k块,分块方法如图3所示。
图3矩阵分块示意图
依据M的分块数,设定k2个Map任务,每个Map任务处理转移矩阵M中的一块Mij与向量v的一块vj,其中v的每块vj输入给k个不同的处理Mij(i=1,2,…,k)的Map任务,在处理Mij时将vj与vj′保留在内存中,Mij与vj生产的所有项只用于vj′的计算。因此v会在算法中输入k次,M中的每块只输入一次,而向量v相对于转移矩阵M的大小是可以忽略不计的,这极大地降低了算法的复杂度。而且由于Map任务进行了多次组合操作,Map任务输出给Reduce任务的数据规模也被缩减了。
33实验仿真步骤与结果
采用10台Intel酷睿i5四核,内存4G的PC通过100M/s交换机互联,搭建分布式环境。其中设定迭代收敛的条件为某节点的PR值之差小于等于10-6。设定任务1中检测作弊网页的阀值l1=05,初始化向量v=(1,1,…,1)T,即迭代开始时每个网页的PageRank值为1;任务2中判定与产品主题相关的阀值l2=2;任务3中权重因子λ=08、μ=02,构建WEB邻接图时的阀值l3=01,用于确定权威网页的阀值l4=4。
为了验证本文所提改进方法的有效性,先对改进算法精确度进行验证,通过实验网页集经过传统的PageRank计算得到的PR值和经过改进的PageRank计算得到的PR值,分别与Google给出的PR值进行比较,如图4所示,横坐标表示9万个网页在经过传统和改进的PageRank计算得到的PR值与Google 的PR值的差值,纵坐标则表示网页个数。
由图4可以看出,经改进的PageRank计算得到的PR值较传统PageRank计算得到的PR值更加接近权威的Google PR值,其中PR值相同或较接近的网页中,改进的PageRank的网页明显多于传统PageRank的网页;PR值相差较大的网页中,传统PageRank明显多于改进的PageRank;并且经过传统PageRank计算的9万个网页的PR值与Google PR值的平均差值为309,而经过改进的PageRank计算的PR值与Google PR值的平均差值只有125,误差减小了595%。
再进行时间复杂度的对比分析,三个子任务中都包含矩阵的计算,其中以任务2涉及的矩阵运算最多,以改进的TC-PageRank在传统的运算与基于MapReduce的矩阵运算条件下,根据既定的迭代收敛条件,在不同的网页集数量下,验证两运算的执行时间,并对比分析传统环境下整体挖掘算法消耗时间与基于MapReduce的矩阵运算所消耗的时间,结果如图5所示。
由图5可以看出,无论是运算单个任务,还是运算整体挖掘算法,基于MapReduce的矩阵运算执行时间都小于传统运算所消耗的时间,并发现随着网页的增加,基于MapReduce的矩阵运算执行时间的增加速率也较小,说明基于MapReduce的矩阵运算具有较低时间复杂度的优势。
在分析比较了算法的有效性、准确性及基于MapReduce的矩阵运算的及时性之后,下面将基于百度采集的网页集进行仿真实验。流程如下:
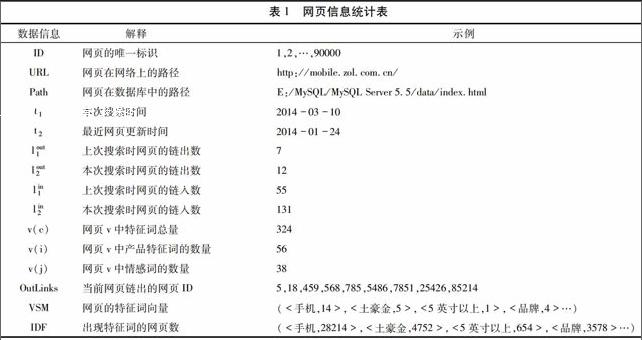
(1)利用表1中的lout2和lin2统计出所有网页的前向与后向链接,建立转移矩阵M ,运用式(1)、式(2)去掉具有较高垃圾质量的作弊网页,依据PR值得到实验中采集到的网页集中的可靠网页集:
P=5,13,15,18,…,2568,…,35841,…,89994
(集合中的数字是网页的标识ID)。
(2)利用表1中的VSM和IDF,运用式(3)计算出网页间主题的相关度w(u,v),根据式(4)计算网页v在网页u中所有出链中所占的权重W(c)。利用表1中的t1和t2,运用式(5)计算网页更新时间差的权重W(t),利用表1中的v(c)、v(i)及v(j)计算评论数据占网页比例的权重W(z),结合式(8),找出可靠网页集中与产品主题高度相关且较新的在线评论网页集:
P=5,13,18,…,2568,…,89994
(3)利用表1中的VSM,结合式(9)计算网页与产品主题的相似度s,利用表1中lout1、lout2、lin1、lin2结合式(10)、式(11)计算网页p的链出增幅lout、链入增幅lin,再运算式(12)和式(13)算出网页集的权威值a以及导航值h,依据权威值a确定权威网页集A=5,18,…,2568,…,最后通过表1中的ID、URL、Path三项,找出网页集A代表的网页作为在线评论分析的可靠数据来源。本实验确定的部分可靠数据来源如表2所示。
通过对实验得到的数据进行分析,发现权威值a较大的网页一般集中在中关村在线、太平洋电脑网以及百度贴吧等国内具有影响力的专业性论坛上,这是由于这些网页时刻保持更新状态,并且以本实验中的产品主题进行采集时,它们处于根集位置。另外有些购物平台对百度搜索引擎采取了屏蔽措施,这就需要对这类的网站采用其他网页采集方法以弥补在线评论数据的不全面问题。
4结论与展望
在线评论作为产品口碑传播的一种新形式,对消费者网购的抉择起着重要的影响,但其中大量的良莠不齐的评论也影响了消费者对可靠信息的获取。本文从目前在线评论数据挖掘存在的实际需求出发,将在线评论数据获取分成三个子任务,从辨别作弊网页获取可靠网页,到提炼出与产品主题高度相关的网页,最后从相关网页中确定其中的权威网页作为在线评论分析的数据来源,三个任务循序渐进地进行,保证了获取的网页集不仅是与产品主题密切相关,而是也保证了数据的权威性,对消费者网购决策具有重要的指导意义。
在获取了可靠的用于在线评论信息挖掘分析的数据源之后,下一步研究工作就是对这些在线评论数据集进行产品特征的提取以及消费者情感倾向的分析,以更加直观的形式呈现给潜在消费者,避免了其搜寻阅读大量在线评论的不必要性,辅助其快速做出决策,并帮助企业理解消费者对产品质量与服务的感知,为企业改进产品质量与服务以及制定更加有效的营销策略提供支持。
但是由于学术界目前缺乏可靠数据源挖掘这方面的研究,因此对实验仿真的准确性并没有可靠的评判标准,只能通过人工排查来检验结果的准确度,实验中数据规模较小,依靠人力尚能检验完,但若是放在系统中基于整个WEB环境,那通过人工检验结果的准确度是不可能完成的,借助简单的检测方法是完善实验的重点。
参考文献:
[1]CNNIC.2014年第33次中国互联网络发展状况统计报告[R].北京:中国互联网络信息中心,2014.
[2]李实,叶强,李一军,等. 挖掘中文网络客户评论的产品特征及情感倾向[J].计算机应用研究,2010,27(8):3016-3019.
[3]Senecal S, Nantel J. The Influence of Online Product Recommendations on Consumers Online Choices [J]. Journal of Retailing,2004,80:159-169.
[4]Ghose A, P Ipeirotis, A Sundararajan. The Dimensions of Reputation in Electronic Markets [J]. Working Paper, NewYork University,2005(12) :2.
[5]廖成林,蔡春江,李忆.电子商务中在线评论有用性影响因素实证研究[J].软科学,2013,27(5):46-50.
[6]龚艳萍,梁树霖. 在线评论对新技术产品消费者采用意愿的影响研究[J].软科学,2014,28(2):96-105.
[7]Bu Yiming, Huang Tingzhu. An Adaptive Reordered Method for Computing PageRank[J]. Journal of Applied Mathematics, 2013,1-6.
[8]Halu Arda, Mondragon Raul J, Panzarasa, et al. Multiplex PageRank [J]. PLOS ONE,2013,8(10):1-10.
[9]Havelieala T H.Topicsensitive PageRank[C].Proceedings of the 11th International World Wide Web Conference,Hawaii,2002.517-526.
[10]常庆,周明全,耿国华.基于PageRank和HITS的Web搜索[J].计算机技术与发展,2007,18(7):77-79.
[11]刘义,景宁,陈荦,等.MapReduce框架下基于R_树的k_近邻连接算法[J].软件学报,2013,24(8):1836-1851.
(责任编辑:秦颖)