模糊综合评判法在所得税纳税评估中的应用探讨
2015-04-18薄建奎
薄建奎 李 寻
模糊综合评判法在所得税纳税评估中的应用探讨
薄建奎 李 寻
为了进一步深化定性分析模型在所得税纳税评估前期的选案工作,笔者试图通过构建该税纳税评估指标体系并运用模糊综合评判法丰富企业所得税的纳税评估方法,谋求为税务部门的所得税纳税评估工作提供可靠的理论依据,以提高评估选案的准确度。
所得税纳税评估;模糊综合评判法;评估选案
一、引言
随着经济发展方式的日益多样化、复杂化和计算机网络技术的迅速发展,一些发达国家开始致力于征收管理模式的改革,而不同形式实施的纳税评估管理尤为典型。20世纪90年代至今,不管是我国纳税评估工作的实践,还是国人对纳税评估的讨论和研究,都取得了不错的经验,但是跟发达国家相比还存在着较大的差距。主要表现为虽然我国税务机关以“金税工程”为核心,基本完成了涉税信息的搜集与整理工作,但我国税收征管现代化程度依然较低,建立科学的数据处理模型已成为目前税务信息化进程中的“瓶颈”。企业所得税的纳税评估是税源监控的有效手段之一,对提高纳税意识、强化税源管理都具有积极的作用,然而由于种种原因,纳税评估实践中的成效还未能充分发挥,其中最突出的问题是对纳税评估对象确定不够准确。笔者试图通过构建该税纳税评估指标体系并运用模糊综合评判法丰富企业所得税的纳税评估方法,谋求为税务部门的所得税纳税评估工作提供可靠的理论依据,以提高评估选案的准确度。
二、企业所得税纳税评估指标体系的构建
2005年3月国家税务总局颁布的《纳税评估管理办法(试行)》明确指出纳税评估指标是税务机关筛选评估对象、进行重点分析时所选用的主要指标。
笔者在选择纳税评估指标,建立纳税评估指标体系时,考虑到规范、合理、适用、可行与简洁等几个方面的要求,并遵循系统全面性原则、相关性原则、可比性原则、现有条件原则和结构性原则,且结合娄元英(2014)研究分析得出的纳税评估模型研究中使用频率最高的评估指标,选取了20个指标构建企业所得税纳税评估指标体系。该指标体系总共3层:第一层,目标层U(企业所得税纳税评估指标体系U);第二层,要素层Ui(应税收入类评估U1,成本费用类评估U2,计税所得类评估U3,税收负担类评估U4)第三层,指标层Uij(20个指标,具体指标如表1所示)。

表1 所得税纳税评估指标体系表
三、基于模糊(Fuzzy)综合评判法的企业所得税纳税评估评价
模糊综合评价法是一种基于模糊数学的综合评标方法。该综合评价法根据模糊数学的隶属度理论把定性评价转化为定量评价,即用模糊数学对受到多种因素制约的事物或对象做出一个总体的评价。它具有结果清晰,系统性强的特点,能较好地解决模糊的、难以量化的问题,适合各种非确定性问题的解决。
为检测构建的纳税评估指标体系的合理性,本文以X高科技上市公司为例进行说明,步骤如下:
1.确定因素集
所谓因素集,指的就是由影响因素(评价指标)组成的集合,通常用字母U来表示,通常可以分为总目标因素集和子目标因素集。本例中总目标因素集用U=(U1,U2,U3,U4)表示,对构成每一个总目标因素集的因素Ui(i=1,2,3,4)再划分,得到子目标因素集Uij(即二级指标),表示每个因素子集Ui共有5个指标因素,即j=1,2,3,4,5.具体情况如表1所示。
2.建立评语集V
评语级是指对各层次评价因素作出的总评判组成的集合。根据纳税人主观原因可将税收不遵从分为知觉性不遵从和无知性不遵从。一般税收遵从研究是以知觉性不遵从为研究对象,即认为纳税人主观上存在减轻税负动机的逃税行为(具体包括偷税、漏税、欠税、骗税与抗税行为),此次研究的纳税评估正是针对纳税人知觉性不遵从的评判、测算。纳税人的纳税行为遵从程度与纳税人的申报情况真实准确相一致,申报情况越真实可靠,那么表明纳税人的纳税遵从程度就越高,越能够自觉地履行纳税义务。本文在纳税评估中可设定评语集V=(V1,V2,V3,V4,V5),V可表示为{遵从,比较遵从,尚遵从,不太遵从,不遵从}。
3.确定权重
这里的权重表示各个因素在指标体系中的重要程度的集合。根据要素层各项对纳税评估质量的影响程度,本次设定总目标因素集U=(U1,U2,U3,U4)的权重集A=(0.2,0.2,0.3,0.3),根据各指标自身性质及其对相应要素层的影响程度子因素Ak=(Ak1,Ak2,Ak3,Ak4,Ak5)的权重集如下:

4.建立各因素(评价指标)的模糊综合评价矩阵R
其中,Rij表示因素Ui对等级Uij的隶属度,所以矩阵R的第i行Ri=(ri1,ri2,…,rij)为因素Ui的单因素评价。为得出模糊矩阵R,需首先根据待评价的指标数据,对每一个评价指标Ui分别构造出Vd的隶属函数。
(1)根据该公司有关财务报表计算其有关财务指标现时值和历史平均值(这里考虑到该公司处于生命周期的成熟阶段,当然也可以是现时行业平均值),再以历史平均值为依据,分别计算现时值偏离历史平均值10%、20%、30%和40%时的指标值,计算结果如表2所示。
(2)根据表二计算结果,确定各个财务指标Uij于五种评估情况Vd的隶属度rij,确定原则是指标现时值越接近某一偏差率,就赋予越高的权数,即隶属度rij越大,反之就越小。具体方法是:令每一指标的个评估结果的隶属度之和∑rij=1,指标现时值的在某一偏差范围内按接近程度分配给该范围对应的评估结果0.8的权数,剩下的0.2的权数平均分配给相邻的两个评估结果。譬如:评估指标销售毛利率(U21)实际值28.25,历史均值为35.24,偏差-19.84%,近似为20%,故0.8的权值分配给V3,V2和V4分别为0.1;再如净资产报酬率(U32)实际值为11.16,历史均值为24.05,偏差15.15%介于偏差率10%与20%之间,这是按接近程度分配,V2=V3=0.4,V1=V4=0.1。按此方法分别判断各指标对每一评估结果的权值,得到的各子因素(评价指标)的模糊综合评价矩阵Ri(i=1,2,3,4)如表3所示。
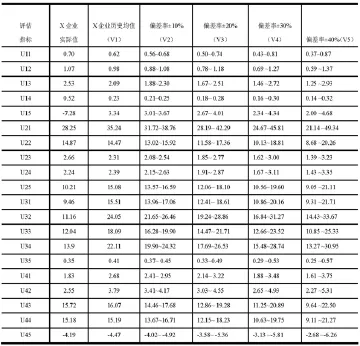
表2 财务指标现时值相对其历史均值偏离率单位:%

表3 模糊综合评价矩阵表
5.得出评价结果S
根据步骤3设定的子因素的权重集Ak与上述得到的子因素模糊综合评价矩阵相乘,算出子评价结果Bi,即Bi=Ak×Ri,得到子评价结果如表4。

表4 子评价结果表
最后,再将步骤3设定的总目标因素的权重集A与上述自评价结果Bi相乘得到综合评价结果,即S=A× Bi,求得最终评价结果向量表示为S=(0.08,0.16,0.198,0.242,0.32)。
上述向量元素分别表示了纳税人的五种纳税行为,即纳税遵从,纳税情况比较遵从,纳税尚遵从,纳税不太遵从和纳税不遵从的隶属度。同时,可将评判集V=(V1,V2,V3,V4,V5)中{遵从,比较遵从,尚遵从,不太遵从,不遵从}设置为分数,设置原则是随着遵从程度的递减而递减,姑且定为(100,80,60,40,20),那么就可以得到该上市公司纳税评估情况总分:
Z=0.08×100+0.16×80+0.198×60+0.242×40+ 0.32×20=48.76
最终的评估结果向量表明,该公司纳税情况隶属不太遵从和不遵从的程度比较大,得到的纳税评估情况的总分显示不及格,因此稽查部门应该重点关注。结合该公司纳税的实际情况(存在的涉嫌骗取高新技术企业资质从而偷逃税款、高管人力费用转嫁操纵利润等违规现象),所建立的指标体系较好的反映了企业的纳税情况,因此,文章所构建的纳税评估指标体系具有一定的合理性和可行性。
我国经济体制改革的进行促使了企业经营方式的日趋多样化,这就对税源专业化管理的有效性提出了更高的要求,而纳税评估作为税源专业化管理的一项重要内容,对纳税评估工作的进行更是提出了巨大的挑战,这就需要大力发掘和倡导当前大数据时代背景下的纳税评估信息采集模式,并构建可以进行分析对比的评估指标体系及其基础上的评估模型。为此,我国所得税纳税评估指标体系和评估模型的建立还需不断发展和完善,在今后的研究中,可以尝试采用实证研究或其他研究方法,对整个纳税评估工作做进一步的研究。
[1]周伍阳.纳税评估模型应用研究[D].湖南大学,2005.
[2]谭光荣.选择纳税评估指标的局限性及应对措施[J].税务研究,2007,02:91-93.
[3]李鹏飞.纳税评估问题研究[D].东北财经大学,2011.
(作者单位:青岛理工大学商学院)
