基于改进多样性密度的性别识别
2015-04-11顾明亮张世形
顾明亮 ,张世形 ,鲍 薇
1.江苏师范大学 物理与电子工程学院,江苏 徐州 221116
2.江苏师范大学 语言科学学院,江苏 徐州 221116
1 引言
20世纪90年代,Dietterich等[1]在对药物活性预测问题的研究中,提出了多示例学习的概念,其目的是通过对已知适合或不适合制药的分子进行分析来构建一个学习系统,以尽可能准确地预测某种分子是否适合制造药物。此后,国内外很多学者对该问题进行了研究,并应用于其他领域:Maron[2]将多示例学习应用于股票投资中的个股选择问题;Ruffo[3]将多示例学习应用于数据挖掘;Andrews[4]、Huang[5]、Yang[6]、Zhang 等[7]分别将多示例学习用于图像检索;Chevaleyre等[8]用多示例学习研究了Mutagenesis问题并取得了理想成果。在多示例学习中,训练样本的歧义性比较特殊,使得多示例学习模型与传统的机器学习模型有很大差别。多示例学习的这种独特性质和良好的应用前景,使得多示例学习被称为与监督学习、非监督学习和强化学习并列的第四种机器学习框架。
多示例学习(multi-instance learning)问题可描述为:假设训练数据集中的每个数据是一个包(bag),每个包是一组示例(instances)集合,有一个训练标记,而包中的示例没有标记。如果一个包被标记为负包(negative bag),即用户不感兴趣的训练样本,则包中的每一个示例为负例;如果包被标记为正包(positive bag),即用户感兴趣的样本,则包中至少一个示例为正例。学习算法通过对多个包组成的训练数据集进行学习,生成一个分类器,以尽可能正确地对训练集外的未知包(unseen bag)进行预测。多示例学习框架可以用图1来表示。
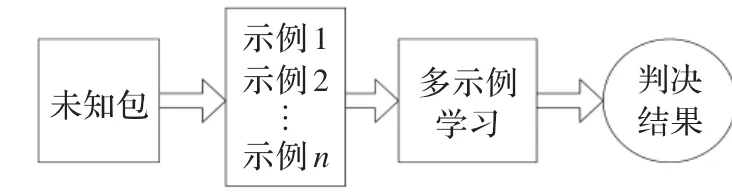
图1 多示例学习框架示意图
多示例学习提出后,国内外很多学者对该问题进行了研究,并提出了很多有效的算法:Maron等[9]提出了多样性密度(Diverse Density,DD)算法;Zhang等[10]将多样性密度算法与EM算法结合起来,提出了EM-DD算法;Ramon等[11]构造了多示例神经网络;Zhou等[12]通过使用特殊的误差函数,提出了BP-MIP算法。
多样性密度算法对后来的研究影响很大,很多学者都在此算法的基础上进行了研究。戴宏斌[13]、王春燕[14]、陈绵书等[15]以及龙哲[16]分别运用多样性密度算法进行了图像检索方法的创新与应用。目前,还没有学者将多样性密度算法应用于语音识别中。本文利用多样性密度算法能够有效发掘语音信号内在规律和分布的特点,并提出Instances-k近邻分类算法,探索了一种语音性别识别的方法。
2 多样性密度算法及其改进
2.1 多样性密度算法
1998年,Maron等[9]提出了多样性密度算法。在该算法中,给出了多样性密度的概念,并规定在属性空间中某点周围出现的正包数越多,且负包示例出现得越远,则该点的多样性密度越大。多样性密度点示意图如图2所示。
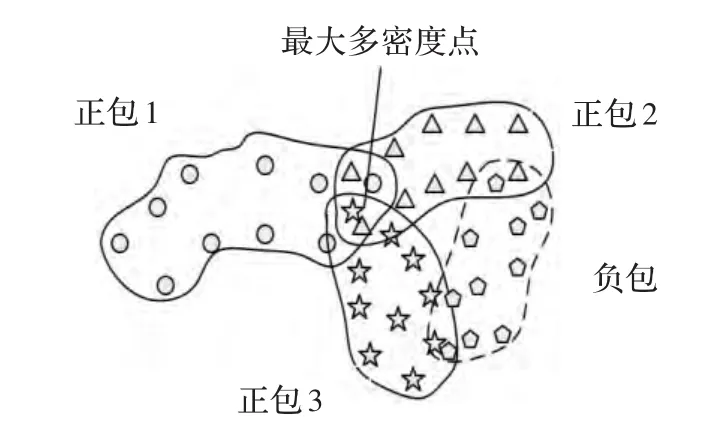
图2 多样性密度点示意图
令代表第i个正包,代表第i个负包,则代表第i个正包中第j个示例的第k个属性,代表第i个负包中第j个示例的第k个属性。对于特征空间内的任一点t,假设目标概念点的概率为:
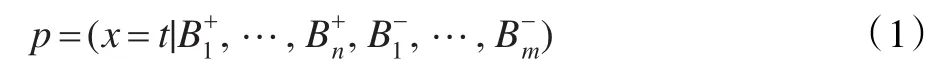
假设各包是条件独立的,根据贝叶斯定理,上式可化为:

在实际应用中,Maron使用了“noisy-or”模型,上式可化为:
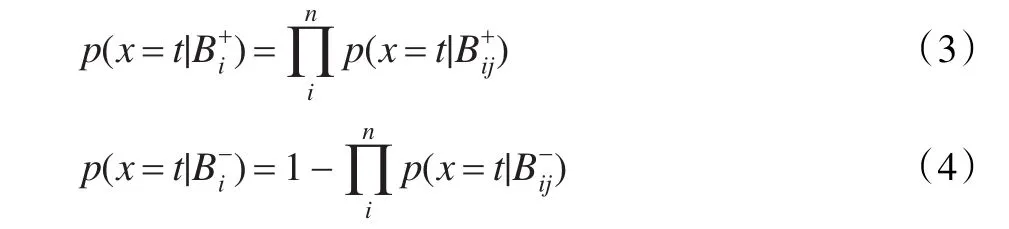
其中:

Zhang和Goldman提出了EM-DD算法[10],他们将DD算法与EM算法相结合来求解目标特征t。EM-DD算法首先假设一个初始目标特征h;然后E步从训练集的每个示例包中选出最靠近h的示例组成一个集合;再在M步中,采用梯度搜索法对E步中获得的集合进行计算,得到一个新的使多样性密度最大的特征点h′,用h′代替h。重复E步和M步到算法收敛为止。由于DD算法要进行多次梯度下降搜索来求解多样性密度点,计算时间比较长,效率不高,而EM-DD算法将多示例转变为单一示例,提高了搜索效率。
2.2 多样性密度算法的改进
2.2.1 双类别多样性密度
双类别多样性密度的定义:在多类别训练样本集合中,将A类训练样本包标记为正,其他类别样本包标记为负,通过EM-DD算法计算,得到A类样本的正最大多样性密度点PA;反之,将A类样本包标记为负,其他类样本包标记为正,则得到A类样本的负最大多样性密度点NA。如果待测未知包为A类样本包,则未知包中包含距离点PA最近和距离点NA最远的示例。
双类别多样性密度的基本思想是对多类别训练样本集进行两类多次标记,以获取训练样本集的内在规律与分布特点。假设样本集合包含A、B、C三类数据,以{A,B,C}样本集合为例,PA、PB、PC分别代表A、B、C的正最大多样性密度点,NA、NB、NC分别代表A、B、C的负最大多样性密度点,则各最大多样性密度点的标记方式如表1。

表1 A、B、C的双类别多样性密度点的标记方式
假设男性最大正、负多样性密度点为PM、NM,女性最大正、负多样性密度点为PF、NF,则男、女信号的最大正、负多样性密度点通过图3表示方式得到。
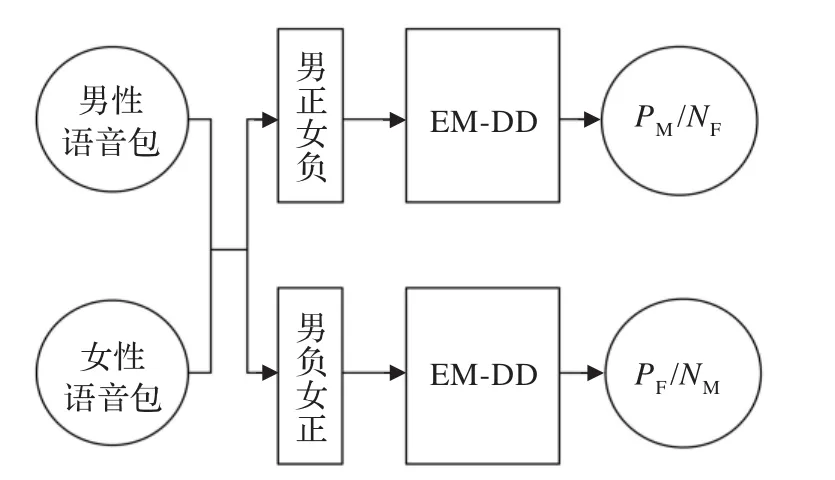
图3 男、女信号的最大正、负多样性密度点
语音信号中只包含男、女两类信号,男性信号的最大正多样性密度点PM也是女性信号的最大负多样性密度点NF,同样,点PF和点NM也为同一点。在语音识别技术中提取的语音特征往往是多维的:如32维、64维甚至是128维,因此很难在平面上描绘出样本数据在空间中的具体分布。为了既形象又简便地描绘多样性密度算法原理,本文在绘图时将多维数据“降维”至二维数据,此时在样本空间中点PM和点PF组成的双点语言模型如图4。

图4 双点模型下的分类判决
需要说明的是:在实际样本空间中,图4中虚线圆并不是一个平面圆,而是一个多属性球,属性数与提取的语音特征的维数相同。图5和图6采用同样的描述方式。

图5 k近邻分类算法

图6 Instance-k近邻分类算法
在传统的单点模型中,对未知包进行分类判决时,首先需要大量计算示例空间中最近示例到多样性密度点的距离作为参考数据,然后人为地设置阈值θ。假设未知包中示例到男性样本的多样性密度点的最小Hausdorff距离为distance1,则判决公式如下:

在双点模型下进行分类判决时,首先计算出示例空间中未知包中示例到两类别多样性密度点的最小Hausdorff距离distance1、distance2,然后比较距离的大小关系,具体判决准则如下:

双点模型下的判决不需要进行大量实验来人为设置阈值θ,减小了系统的运算次数,节省了时间,提高了系统的效率。
2.2.2 Instance-k近邻分类算法
Instance-k近邻算法的思想来自于理论上比较成熟的k近邻分类算法。在k近邻分类算法中,如果一个样本在特征空间中的k个最邻近样本中的大多数属于某一类别,则该样本也属于这个类别。图5为k近邻分类算法示意图。
Instance-k近邻分类算法:在示例空间中,选取未知包中距离各多样性密度点最近的k个示例,计算这k个示例到各点的Hausdorff距离并求和,未知包属于Hausdorff距离之和最小的那一类。图6为Instance-k近邻分类算法示意图。
假设示例空间中存在三个多样性密度点Pa、Pb、Pc,未知包中最近k个示例到各多样性密度点的距离表示如下:

未知包类别属于距离最小的多样性密度点所属类别:

当Instance-k近邻分类算法中k=1时,其实就是示例最近邻分类算法。由图5可以知道,在示例空间中,如果未知包中存在野点示例,最近邻分类算法会受到野点示例的影响而错误分类。Instance-k近邻分类算法可以有效地减小示例野点对分类判决的影响,从而尽可能正确地对未知包进行预测。
3 实验设计与分析
本实验语音全部采用国际标准OGI(Oregon Graduate Institute)语音数据库。OGI语音数据库包含11种国家的语言,每种语言都包含男女语音信号,本实验只选取普通话。训练集共80人,其中男性42人,女性38人;训练语音时长约3 840 s,其中男性约1 920 s,女性1 920 s;测试集时长约500 s,男女性各250 s。训练集和测试集不交叉,采样频率为8 kHz,量化比为16 bit。训练集用于多样性密度点的训练,测试集用于系统的测试。
3.1 语音包的生成
在多示例学习中,包的生成至关重要,本文语音包的生成分为三个步骤:首先,计算机读取语音信号后进行预处理和特征提取;然后将特征集均匀切分为n段,其中n即为包的个数;最后,采用k-means算法将每段特征向量集聚类为k个特征向量作为包中示例,k即为包中示例个数。图7是包生成的原理框图。
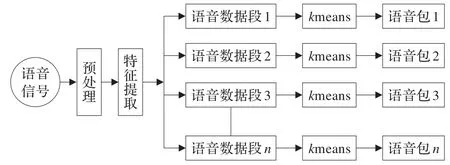
图7 包生成原理图
其中,预处理中所用的预加重滤波器为1-0.95z-1,窗函数为Hamming窗,语音信号帧长取256点,帧移为128点;由于MFCC特征是性别分类中最具区别性的参数之一,特征提取时提取语音信号的42维MFCC特征,包括对数能量、倒谱系数、一阶差分系数和二阶差分。训练包集由所有训练语音连接组成,包的最优个数n和包中示例数k将通过实验进行选择;每一测试包由持续时长2.5 s的测试语音生成,示例数与训练包中的示例数相等。
3.2 实验结果与分析
在寻找最优数量的包数和示例数时,首先固定示例为32,比较不同包数对性别识别系统的影响。图8表明当训练包的数目不足200时,同一类别的最大多样性密度点不容易被发现,识别率不高;当训练包数为200时,识别率最高,分别为男性93%、女性94%;当训练包数大于200时,系统识别精度略有下降且趋于稳定。综合考虑计算成本与识别率,训练包数目设为200。

图8 包数对性别识别系统的影响
考察示例数对性别识别系统的影响时,固定包数为200,改变示例的数量。观察图9可以知道,随着示例数的增加,识别率会先提高后下降,且系统对示例数非常敏感。当示例数设为32时,系统的平均识别率最高。
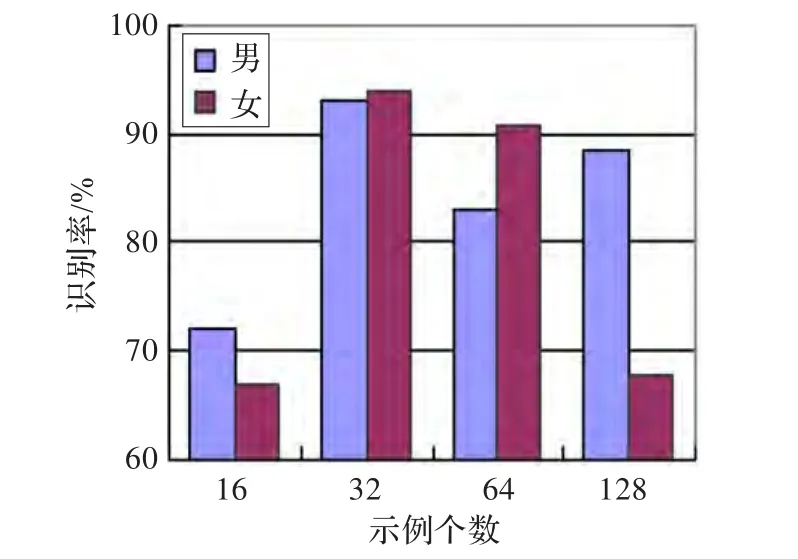
图9 示例数对性别识别系统的影响
确定了训练包数目为200,示例数为32后,考察Instance-k近邻分类算法中k的选择对系统的影响。从图10可以看出,随着k的增加,识别率先提高后下降。当k等于3时,系统识别率达到最高值:男性97%,女性98%,提高了系统的识别率。但是,随着k值的增加,识别率也在不断下降。

图10 k值对性别识别系统的影响
Instance-k近邻分类算法的作用是减小野点示例对分类判决的影响,但随着k值的增加,即参与计算的示例数增加,与多示例学习中利用未知包中单一示例进行判决的差异性变大,判决结果可能会出现错误,图10证明了这一点。
4 结束语
利用双类别多样性密度算法构造了一个双点语言模型,并在分类阶段提出了Instance-k近邻分类算法,进行了语音性别识别。实验结果表明:采用改进多样性密度算法的多示例学习在语音性别识别上是可行的,系统的平均识别率最终达到了97%。
另外,在多示例学习问题中,包的生成方法非常关键,将直接影响学习算法的分类结果。因此,在今后的研究学习中,将继续探究语音信号的包生成问题,将作为多示例学习应用于其他语音信号处理中。
[1]Dietterich T G,Lathrop R H,Lozano P T.Solving the multiple-instance problem with axisparallel rectangles[J].Artificial Intelligence,1997,89(1/2):31-71.
[2]Maron O,Ratan A L.Multiple-instance learning for natural scene classification[C]//Proceedings of ICML,Madison,USA,1998:341-349.
[3]Ruffo G.Learning single and multiple instance decision tree for computer security applications[D].Torino:University of Turin,2000.
[4]Andrews S,Hofman T,Tsochantaridis I.Multiple instance learning with generalized support vector machines[C]//ProceedingsofAAAI/IAAI,Edmonton,Canada,2002:943-944.
[5]Huang X,Chen S C,Shy M L,et al.User concept pattern discovery using relevance feedback and multiple instance learning for content-based image retrieval[C]//Proceedings of MDM/KDD2002 Workshop,Edmomton,Canada,2002:100-108.
[6]Yang C,Lozano P T.Image database retrieval with multipleinstance learning techniques[C]//Proceedings of ICDE,San Diego,USA,2000:233-243.
[7]Zhang Q,Goldman S A,Yu W,et al.Content-based image retirveal using multiple-instance learning[C]//Proceedings of ICML,Sydney,Australian,2002:682-689.
[8]Chevaleyre Y,Zucker J D.Solving multiple-instance and multiple-part learning problems with decision trees and decision rules:application to the mutagenesis problem[C]//Proceedings of LNAI,Berlin,German,2001:204-214.
[9]Maron O,Ratan A L.A framework for multiple-instance learning[C]//Proceedings of NIPS,Cambridge,USA,1998:570-576.
[10]Zhang Q,Goldman S A.EM-DD:an improved multipleinstance learning technique[C]//Proceedings ofNIPS,Cambridge,USA,2001:1073-1080.
[11]Ramon J,Raedt L D.Multi-instance neural networks[C]//Proceedings of ICML,Stanford,USA,2000:53-60.
[12]Zhou Z H,Zhang M L.Neural networks for multi-instance learning[C]//Proceedings of ICIIT,Beijing,2002:455-459.
[13]戴宏斌,张灵敏,周志华.一种基于多示例学习的图像检索方法[J].模式识别与人工智能,2006,19(2):179-185.
[14]王春燕,袁津生.一种结合多示例学习的图像检索方法[J].计算机系统应用,2010,19(6):212-215.
[15]陈绵书,杨树媛,赵志杰,等.多点多样性密度算法及其在图像检索中的应用[J].吉林大学学报:工学版,2011(5):1456-1460.
[16]龙哲.基于多样性密度的多示例学习方法[J].工业控制计算机,2012,25(7):73-74.
