个性化推荐系统评测指标与实验方法研究
2015-04-01吴海霞
吴海霞,何 苑,路 璐
(长治学院计算机系,山西长治046011)
(编辑 张 瑛)
1 个性化推荐系统简介
信息技术和互联网技术使我们从信息匮乏的时代发展到信息过载的时代,信息消费者从海量信息中搜索感兴趣的有价值的信息变得十分困难,信息生产者的信息从大量信息库中脱颖而出得到目标用户的关注也非常困难[1].
信息检索、数据挖掘和推荐系统三种技术都可以在一定程度上解决这一矛盾,但三者之间存在着明显不同,表1列出它们的主要区别.传统的搜索引擎技术只在Web海洋的表层页面检索,呈现给所有用户的结果排序及页面没有差别,未针对不同用户兴趣提供相应个性化服务,信息的利用率较低;Web数据挖掘能够自动获取大量的更具价值的深层页面,利用相关规则发现隐藏的规律和模型;个性化推荐系统已成为一种营销模式和手段,给电子商务领域带来巨大的商业利益,不仅能够挖掘出用户感兴趣的部分“暗信息”,还能提高潜在客户的转化率,并有效保持用户的黏着性.

表1 信息检索、数据挖掘、个性化推荐之间的区别
个性化推荐是基于社会计算和集体智慧[2]的一种新的计算模式,PageRank算法[3]、Netflix竞赛、MovieLens[3~4]、Google推荐系统等都是成功的应用.推荐技术是解决信息过载问题,实现信息生产者和信息消费者双方共赢的重要工具.一个完整的推荐系统由三部分组成:收集用户信息的行为记录模块、分析用户喜好的模型分析模块、产生个性化推荐结果的推荐算法模块,其中,推荐算法模块是推荐系统中最为核心的部分[5~6].对推荐结果的质量和性能进行评测则是优化推荐算法,提升推荐系统效能的重要途径.
传统的个性化推荐包括基于手工决策规则、协同过滤、基于内容、基于人口统计、基于效用、基于知识的推荐等方法.基于Web挖掘的个性化推荐方法有聚类分析、关联规则、序列模式方法、语义Web挖掘、统计学技术等[7~9],包含数据输入、数据预处理、模式发现和分析、信息推荐一系列流程.近年来出现了许多新的推荐算法在特定方面表现出突出优势,如基于图模型、基于概率、基于语义、上下文情境、mahout二部图推荐及混合推荐等等.
2 推荐系统的评价指标体系
推荐评价是推荐领域的一个重要问题.推荐系统具有三个必要的参与主体:网站、用户、物品(内容)提供者,在评测推荐系统和推荐算法时必须考虑三方利益.好的推荐系统的理想目标是达到多方共赢,在不同应用场景中选择哪种评价指标更为客观合理具有指导意义.业界研究人员尚未形成一致的科学标准体系,但公认的重要指标已被广泛使用.下面给出主流的通用评测指标和新的评测指标.有些基于推荐算法,有些独立于推荐算法;有的从系统角度评价,有的从用户角度评价;部分为定性评价,部分为定量评价.理想的推荐系统应该准确、高效、多样、新颖、透明、稳定、覆盖广、获得用户满意和信任.
2.1 推荐准确度
准确度(Accuracy)是最重要的评价指标,即推荐系统预测评分(或排名)与用户实际打分(或排名)间的相似度和吻合度,分为预测准确度、分类准确度、排序准确度[6].预测准确度用来度量推荐算法预测用户行为的能力,一般用MAE、MSE、NMAE、RMSE等指标,适于离线评测;分类准确度判定用户是否喜欢推荐物品正确的比例,常用准确率、召回率、F指标和ROC指标,适用二值选择的推荐系统.排序准确度指推荐列表与用户排序间的吻合度,适用于对顺序敏感的系统.
不同准确度的量化计算方法不尽相同,表2给出常用计算指标及特点.约定:n为用户评分的项目数,p为预测评分值,r为用户对项目的评分,rmax和rmin分别为用户评分最大和最小值,di为观测值与真值的偏差,表明样本离散程度,对一组测量中的特大或特小误差反映敏感,因此能较好反映测量精度.

表2 多种准确度计算指标的比较
在指标对照表中,前三个准确率指标的值越大,精度越高,推荐质量越好;后四个误差指标的值越小,预测精度越高,推荐质量越好.但有时会出现矛盾的情形,比如召回率与准确率往往不能同时达到很高,若召回率达100%,则准确率会很低,若准确率达100%,则召回率会很低.这两个指标虽然没有必然关系,但在大规模数据集中,二者却相互制约.
2.2 推荐覆盖率
覆盖率(Coverage)包括种类覆盖率和用户覆盖率,前者指推荐出来的物品占所有物品集的比例,后者指获得推荐结果的用户占全体用户集的比例.一般情况下,覆盖率指种类覆盖率,物品(或内容)的提供商比较关注这一重要指标.推荐列表中物品出现次数的分布越平,表明推荐系统的覆盖率越高,推荐系统挖掘长尾的能力越强;相反,分布越陡,表明覆盖率越低,系统挖掘长尾能力越弱.
覆盖率的常用计算方法:C=|∪u∈UR(u)|/|I|,其中U为用户集合,I为物品集合,R(u)为系统为某用户推荐的物品列表.此外,还可用信息熵和基尼系数两个指标来度量[1]:信息熵表示为 H=-∑[p(i)logp(i)],其中p(i)指物品i的流行度除以所有物品流行度之和;基尼系数表示为G=(∑(2j-n-1)p(ij))/(n-1),其中j指物品流行度升序列表中的第j个物品.
2.3 推荐多样性
多样性(Diversity)衡量系统给用户或群体推荐内容的差异程度.推荐结果呈现多样化,其覆盖的兴趣点就多,用户找到满意物品的概率就大.
假设推荐系统中用户集合为U,两个物品i与j间的相似度为s(i,j),系统为某用户u推荐的列表记为L(u),列表长度 l=|L(u)|,则这一推荐列表的多样性可表示为 D(L(u))=1–(∑s(i,j))/(l(l-1)/2).
推荐系统的整体多样性可表示为D=∑D(L(u))/|U|,即所有用户推荐列表的多样性的均值.
2.4 推荐新鲜度
新鲜度(Novelty)指系统为用户推荐其从未见过但感兴趣物品的能力.好的推荐列表应该是用户之前未听过和见过的、没有打分和浏览记录的、有价值的新颖物品.否则,用户对推荐的内容很熟悉,则认为推荐效果不佳.
这一指标的度量可借助物品的平均流行度来定性计算,推荐物品的流行度越低则认为越新颖.但由于不同用户所不熟悉的物品各异,此方法过于简单而不可靠,因此通过用户调查来进行新颖度的准确统计.
2.5 用户满意度
用户满意度(Satisfaction)是评价推荐系统的重要指标,不能离线计算,只可通过在线实验统计用户的行为或通过问卷调查的反馈情况分析用户感受的方法获得.满意度分为多个层次,因此在设计问卷和反馈界面时应该从不同方面和角度设置不同层次的问题和选项.另外,用户在页面的停留时间、对网页的点击率、物品购买数量和频次、顾客转化率等都是度量满意度的重要指标.
2.6 鲁棒性
也称健壮性(Robustness),衡量推荐系统抗击作弊和攻击的能力.部分恶意用户或商家会为个人利益和商业利益而故意作弊或攻击系统,达成破坏评分系统、改变推荐结果、降低推荐准确度等不良动机.
推荐系统的鲁棒性可考虑三种方法:(1)在系统工作之前先对数据进行攻击检测和清理;(2)推荐策略中除了使用浏览和点击等简单的用户行为,还应运用购买和评价等相对复杂且成本代价较高的用户行为,有效降低被攻击的风险;(3)选择健壮性高的算法,防止被恶意破坏和攻击;(4)采用模拟攻击的方法,针对特定的数据集和推荐算法给用户生成推荐列表,向数据集注入噪声数据,再用该推荐算法生成新的推荐列表,比较两个列表的相似度,相似度高表明健壮性强,差别较大表明不够健壮.
2.7 其他指标
产品流行性(Popularity)不同的产品都有流行的时期和阶段,推荐产品的流行性也决定着推荐质量的高低和用户满意度.如电影拍摄时间、服装生产时间、图书出版时间、教学资源适用时间、网页更新时间、新闻发布时间等.
惊喜度(Serendipity)即意外性,指推荐结果与用户之前喜欢的物品不相似但用户非常满意的推荐.提高推荐惊喜度需要降低推荐结果与用户历史兴趣的相似度.惊喜度不同于新鲜度,像基于内容的推荐算法会产生新鲜的物品而非意外物品.
实时性(Real-time),实际应用对推荐系统的实时性要求越来越高,在线计算时间决定着推荐性能的优劣,反映出推荐的效率和性能.
信任度(Trust),用户信任推荐系统,无疑会增加互动行为,从而获得更好的个性化推荐.增加信任的方法往往是提供推荐解释[10],系统产生推荐的原因和方式越合理透明,用户对推荐系统的信心越强.
隐私保护程度(Privacy),隐私信息越来越受个人和群体用户的重视,隐私保护程度直接影响用户对推荐系统的信任度、满意度、忠诚度和黏着性.
扩展性(Scalability),推荐算法的扩展性能即适应系统规模不断扩大的问题,这是制约系统实现的重要因素.研究增量算法的实现有利于提高算法效率和系统的扩展性能.
普适性(Ubiquitous),针对不同的数据集和不同的应用场景,不同的推荐方法也会表现出不同的效果.推荐算法的普适性成为一个新的评价方面.
3 推荐系统的评测实验方法
个性化推荐的结果和性能由系统运行环境、数据集、市场行情、舆论导向、社交特征、用户群体、时间与情绪等诸多内外因素综合作用.如评分矩阵和实验数据的稀疏等级、近期特殊的新闻事件和用户最近的动态行为特征等都直接影响着推荐的质量和用户的评分及选择.一般采用离线或在线的方式对推荐结果的准确性、覆盖性、新颖性及用户满意度等指标进行测评.
3.1 推荐性能评测方法
推荐系统的性能和效果评价有多种方法.离线实验基于数据集进行,无需真实用户和实际系统即可方便快捷测试多种算法,无法计算转化率和点击率等商业相关指标,其准确度和满意度也存在一定差距.在线实验根据用户实时反馈衡量系统性能,即时响应和用户交互性强,但时间开销和用户参与成本高.AB测试即为一种在线实验方法,通过一定的规则把用户随机划分成组,对不同组别用户采用不同的推荐算法,相对公平地获取不同算法在实际在线时的一些性能指标.缺点是周期较长,需要长期的实验才能得到可靠的结果.用户调查也是系统评测的重要方法和工具,通过让真实用户参与任务,分析测试行为,但需要事先设计“双盲实验”,避免参与者受主观因素影响,确保实验结果更加客观、严谨、准确和科学.表3分别列出了三种评测方法的优缺点.

表3 推荐算法的性能评测方法对比
3.2 评测指标的实验方式
有的评测指标可以定量计算,有的只能定性评价,表4对主要评测指标的获得进行对比.
3.3 评测指标的制约和优化
有些评价指标可以在离线实验中得到优化,如限定覆盖率、新鲜度和多样性的阈值,追求更高的准确度.但在推荐系统中追求所有指标达到最优完全不现实.推荐算法的综合评价应该是在一定场景和应用环境中的权衡,强化重要指标,弱化次要指标.推荐准确性和物品多样性相结合、推荐准确度与物品覆盖率相结合,达到准确率高、覆盖率高的合理目标.物品流行度和新鲜度、推荐物品的意外性与用户对系统的信心之间、推荐精度和多样性之间、推荐精度与新颖度之间都存在着矛盾.如果牺牲推荐精度而提高多样性和新颖性比较容易,但在不牺牲精度的前提下提高多样性和新颖性较为困难.
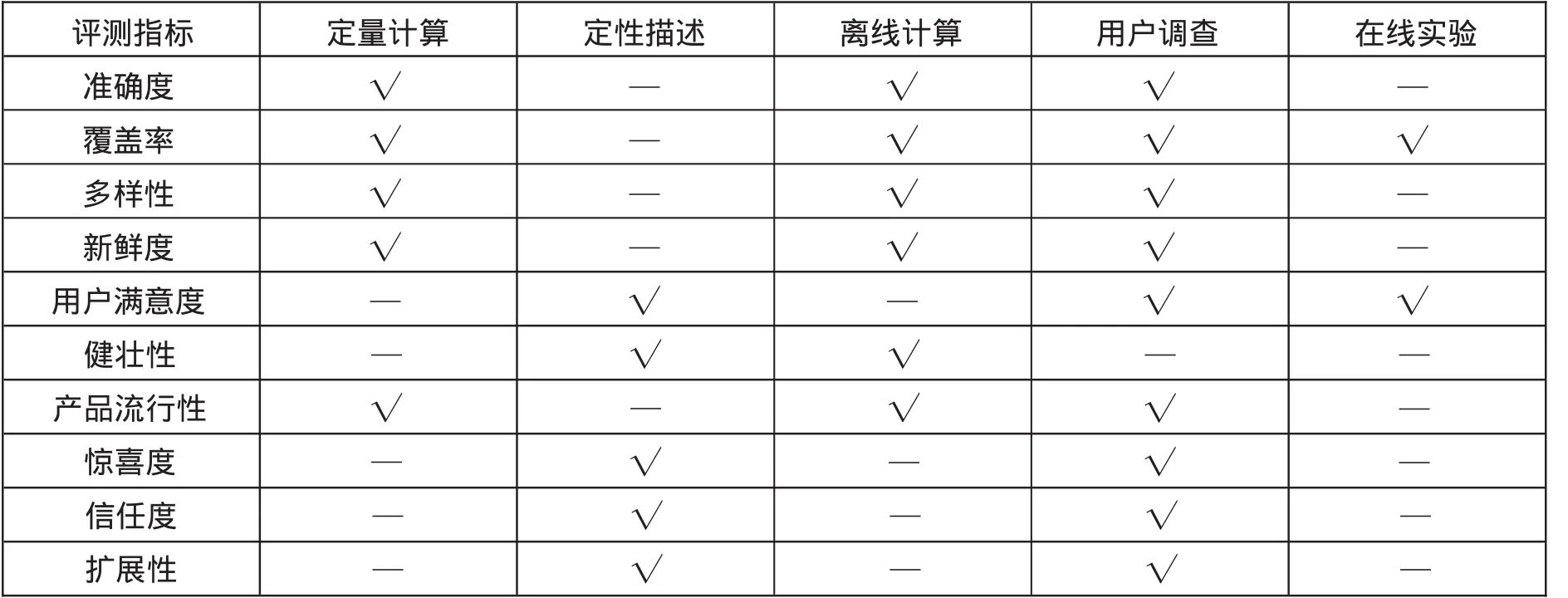
表4 推荐系统评测指标的获得方式
4 小结
个性化推荐系统在社会经济中具有重要的应用价值,现已应用于诸多领域,如音乐和影视推荐、图书和商品推荐、广告和资讯推荐、朋友或团体等社交推荐、新闻和微博等媒体推荐、学习视频和教育资源等教育推荐.有效评价推荐算法和系统优劣具有很大困难和挑战,主要体现为:由于数据集不同,推荐方法策略不同,算法表现出来的性能难于直接评价;推荐系统任务不同,评价动机和目的各异,指标体系不易确定.
在未来的研究中应主要考虑这几个方面:首先,如何将不同指标加以组合形成综合评价;其次,重视错误推荐在评价系统中起着重大作用,有利于推荐结果的分析和优化;第三,个体与群体推荐相结合,在单一客户推荐的同时支持客户群推荐,能展示出推荐系统的强大优势,为商家提供产品定价、产品促销、交叉销售、优惠券设计等决策,为客户提供产品亲和力、一对一促销、优惠券使用方案等服务;最后,要科学量化用户体验,优秀的推荐系统应该以用户的体验和反馈为核心,在推荐物品之前先预测用户对物品的熟悉程度,以提高新颖度和惊喜度;根据不同场景和任务,向用户推荐熟悉程度不同的物品,可增强物品多样性和覆盖性,增强用户满意度.但如何科学量化用户体验和反馈有待进一步研究.总之,构建科学完善的综合评测体系仍是推荐系统未来研究的重要课题和方向.
[1]项亮.推荐系统实践[M].北京:人民邮电出版社,2012.
[2]Toby Segaran.Programming Collective Intelligence:Building Smart Web 2.0 Applications[M].New York:O’Reilly Media,Inc.,2007.
[3]Anand Rajaraman,Jerey D.Ullman.Miningof Massive Datasets[M].Cambridge:Cambridge University Press,2011.
[4]D.Jannach,M.Zanker,et al.Recommender Systems:An Introduction[M].Cambridge:Cambridge University Press,2010.
[5]刘建国,周涛,汪秉宏,等.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1~15.
[6]刘建国,周涛,郭强,等.个性化推荐系统评价方法综述[J].复杂系统与复杂性科学,2009,6(3):1~10.
[7]易明.基于Web挖掘的个性化信息推荐[M].北京:科学出版社,2012.
[8]马刚.基于语义的Web数据挖掘[M].大连:东北财经大学出版社,2014.
[9]邵峰晶,于忠清,王金龙,等.数据挖掘原理与算法[M].北京:科学出版社,2009.
[10]朱郁筱,吕琳媛.推荐系统评价指标综述[J].电子科技大学学报,2012,41(2):164~175.
