电阻阵列非均匀性校正实时性改进
2015-03-31张金城廖守亿张作宇苏德伦闫循良
张金城,廖守亿,张作宇,苏德伦,闫循良
电阻阵列非均匀性校正实时性改进
张金城1,廖守亿1,张作宇1,苏德伦2,闫循良1
(1. 第二炮兵工程大学精确制导与仿真实验室,陕西 西安 710025;2. 中国人民解放军96111部队,陕西 韩城 715400)
电阻阵列作为红外景象投射器必须进行非均匀性校正,而校正方法的实时性又必须满足系统帧频要求。通过设计实时性评估软件,对以往耗时较长的CPU数据处理方法进行改进,提出基于CUDA的GPU并行数据处理方法,并应用PBO技术做进一步优化。测试结果表明,该方法能够大幅提升数据处理速度,理想的系统实时性为后续更大规模的电阻阵列数据处理提供了时间余度。
电阻阵列;非均匀性;GPU;CUDA;实时性
0 引言
电阻阵列是一种动态红外景象投射器件,可以用于红外成像制导系统的效能评估。电阻阵列通过控制流经各电阻元的电流实现不同程度的红外辐射[1]。理想情况下,当控制电流相同时,各电阻元红外辐射亮度应该相同。但实际情况是:由于材料特性、加工工艺等差异,电阻元具有不同的响应特性,这种非均匀性成为制约电阻阵列发展使用的难题。国外从20世纪90年代开始研究电阻阵列的非均匀性校正问题,研究成果不断发展并付诸应用,目前校正后残余非均匀性可达到1%左右[2-4]。国内从1994年才开始跟踪电阻阵列技术[5],在电阻阵列非均匀性校正方面更是起步晚,研究单位少[6]。
目前国内较为普遍采用的是基于CPU进行非均匀性校正数据处理的方法[6-9],该方法耗时较长,仅在当前像元规模电阻阵列系统中能勉强满足200Hz帧频要求,且有部分超时帧,制约了系统的发展应用。本文以256×256电阻阵列、200Hz红外图像生成系统为研究对象,分析校正计算过程和实时性影响因素,设计实时性评估软件,着眼更大像元规模、高实时性指标要求,对目前采用的数据处理方法进行改进。
1 计算过程分析
红外景象投射系统的主要过程包括:红外图像的GPU渲染、图像数据处理和图像数据传输。上述3个过程的实时性均表现为是否能在帧频要求下,在规定的时间内完成规定的计算量。
1.1 红外图像的GPU渲染
系统采用开放的红外视景仿真软件Vega的Sensor Vision模块,在NVIDIA显卡的GPU中完成红外图像的实时生成。图像渲染计算量主要集中在目标表面红外辐射亮度的计算和目标三维模型的驱动两个方面[10]。红外辐射计算通过对目标三维模型顶点组成的每个面元(多边形)实现,顶点数量决定了模型驱动时的计算量,相应地,多边形的数量也体现了目标三维模型的精细程度。所以,目标三维模型的精细程度是影响图像渲染计算时间的主要因素。
1.2 图像数据处理
数据处理从GPU结束图像渲染开始,包括从GPU的帧缓冲区中取出像素数据、灰度数据转换为辐射亮度数据、非均匀性校正、非线性校正和DA输入量化5个过程。数据处理流程如图1所示。
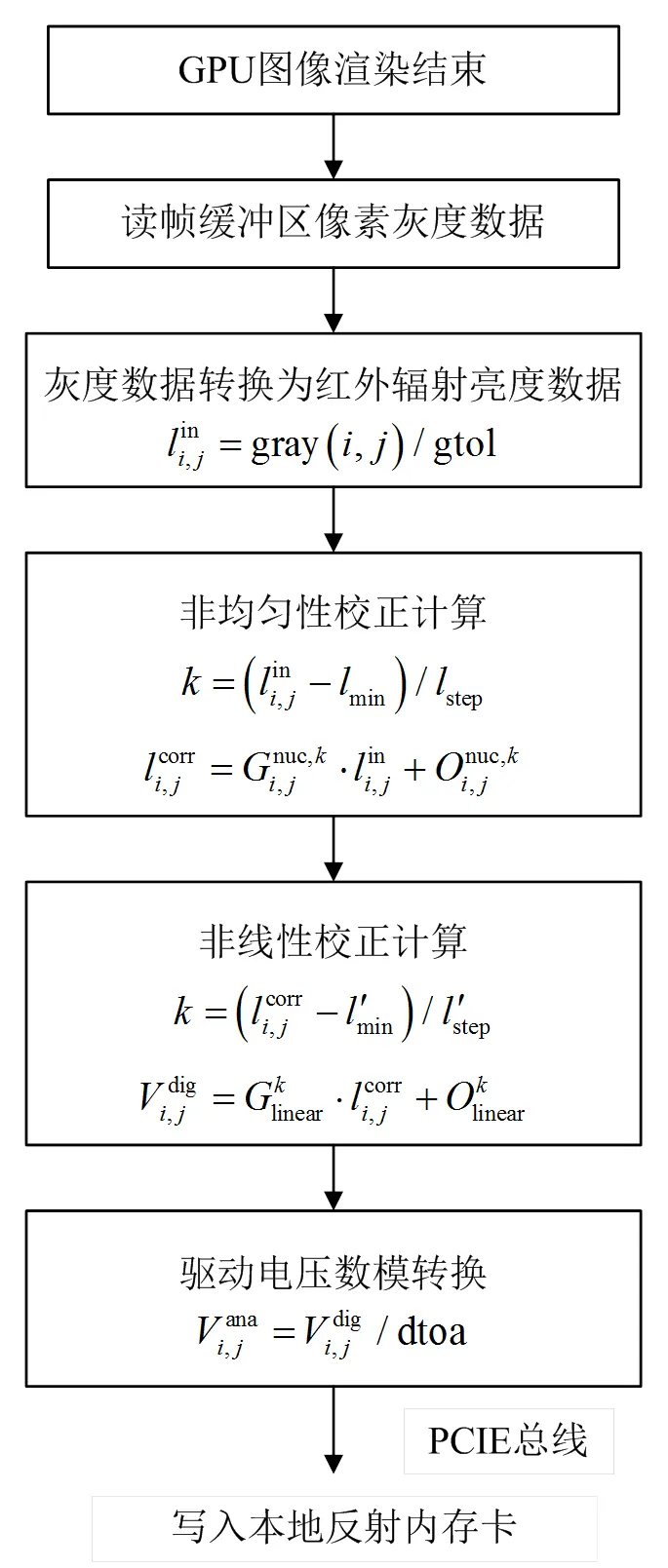
图1 数据处理流程图
1.3 图像数据传输
图像数据传输是指处理后的图像数据通过光纤反射内存网络从图形工作站到电阻阵列驱动控制系统的传输过程,传输路径如图2所示。
由于反射内存节点间为内存实时映射共享机制,相邻节点传输延迟仅为70ns,且光纤带宽可达170MB/s,因此反射内存节点间的数据传输时间可忽略不计,即可认为图形工作站的图像数据通过PCI总线写入本地反射内存节点的同时亦写入驱动控制系统的反射内存节点,则图像数据的发送时间即数据通过PCI总线写入本地反射内存的时间。

图2 图像数据传输路径
2 实时性影响因素分析
图像渲染的速度取决于GPU的加速能力和模型的精细程度,在仿真中采用细节层次技术(Levels Of Detail,LOD),在不影响画面视觉效果的条件下省略不必要的模型细节,可以提高图像渲染的速度。
由图1分析可知,每个像元的数据处理要进行6次浮点数乘加运算,每帧图像要完成256×256×6次乘加运算,且运算量将随像元规模扩大成几何级数增加,所以数据处理是系统主要耗时环节。如果这所有的计算量在CPU中完成,那么数据处理将严重依赖CPU资源。另一方面,由于图像生成系统运行平台为非实时的Windows系统,后台组件对CPU资源的随机抢占势必对数据处理速度造成影响,大幅度超时还会引起丢帧现象,这也对系统实时性带来威胁。
数据传输时间即为PCI总线读写操作时间,相对稳定。
3 评估软件设计
试验评估软件运行环境为WindowsXP SP3,开发环境为Visual Studio 2008和Vega SensorVision模块,硬件环境包括一块GE FANUC VMIC PCI- 5565PIORC反射内存卡和相应的驱动软件包,设计流程如图3所示。
由图可知,软件通过对图像渲染、数据处理和数据传输3个过程分别进行时间测试,考量现行投射系统总体设计和数据处理方法是否满足200Hz帧频要求。软件采用对话框形式,界面设计如图4所示。
界面左半部分为绘图区,可进行128×128、256×256和512×512三种像元规模红外图像的实时渲染,右半部分为设置和参数测试区,包括图像格式和运行方式的控制以及时间参数测试的实时显示。

图3 实时性评估软件设计流程
4 实验评估
非均匀性校正过程中,数据处理算法是一致的,都要进行图1所示的6次浮点乘加运算,但不同的硬件平台、数据处理方式将导致不同的实时性效果。根据第2章分析,由于图像渲染时间可以简化、数据传输时间基本稳定,本文中试验评估软件主要对数据处理时间和图像帧周期进行测试,测试样本为5000帧,测试的硬件平台如表1所示。
图4 实时性评估软件界面设计

表1 测试硬件平台配制
4.1 基于CPU进行数据处理的实时性评估
对当前常用的CPU数据处理方法进行实时性测试,测试结果如图5所示。
图5 基于CPU进行数据处理的实时性测试
Fig.5 Real-time estimating of CPU data processing
测试结果的统计数据如表2所示。

表2 基于CPU进行数据处理的实时性测试统计数据
测试结果表明,Windows系统后台组件对CPU资源的随机抢占导致测试结果的剧烈震荡,虽然帧周期大致在3.5ms至4.5ms之间波动,基本满足200Hz帧频要求,但5000帧样本中依然有15帧周期超过5ms,这会在实时仿真中导致丢帧问题,而且随着像元规模向512×512、1024×1024的增大,数据计算量成几何级数增长,帧周期必将大于5ms。
4.2 基于CUDA的GPU数据并行处理改进
CUDA(Compute Unified Device Architecture,统一计算设备架构)是由NVIDIA(显卡厂商)推出的通用并行计算架构,通过在显卡设备硬件平台上提供软件开发环境,可将高度并行的数据处理过程分发到GPU的众多内核中,实现单指令多线程(Single Instruction Multi Thread,SIMT)的并行计算。由于红外图像各像元数据处理算法完全相同,具有高度并行特征,所以系统对像元数据进行GPU并行加速处理。
GPU硬件上的大规模并行是通过重复设置多个相同的通用构件块——流多处理器(Stream Multiprocessor,SM)实现的,GPU的硬件结构如图6所示。
并行算法的每个计算分支被CUDA定义为一个线程(thread),SM通过调度器控制其多个计算核心(Core)执行相同的指令,每个计算核心可以处理不同的数据,以此实现多线程并行数据处理。
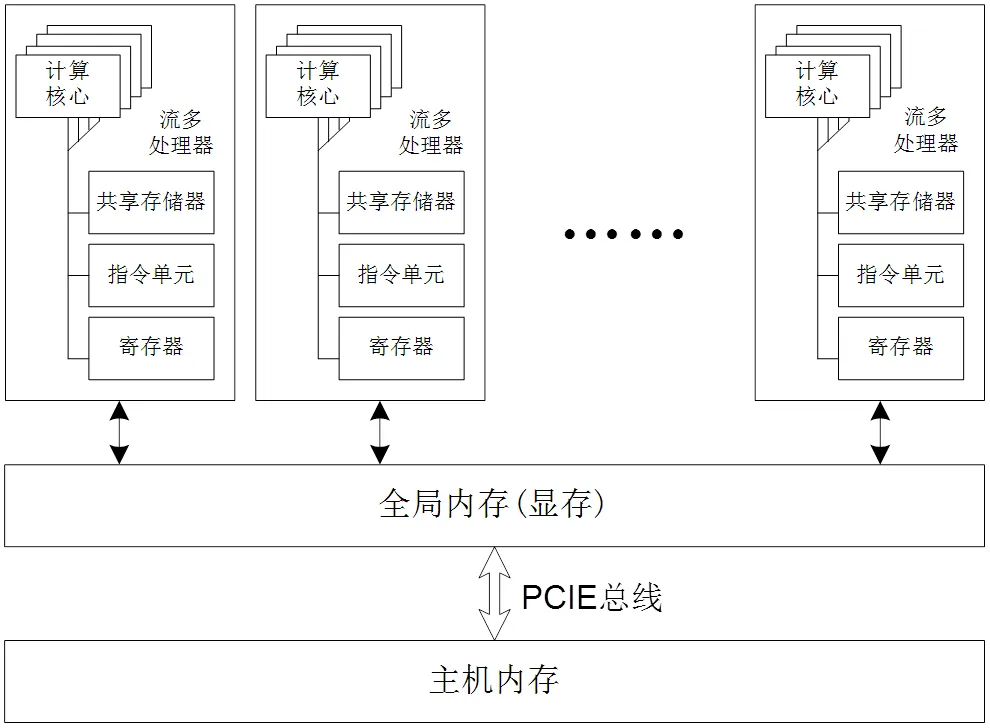
图6 GPU硬件结构图
CUDA软件模型中根据并行算法的线程总数,将所有线程组织成网格(Grid)和线程块(Block)两级封装结构,每个线程块里的所有线程在同一个SM内执行,一个SM可被调度执行一个或多个线程块,因此可通过SM内的共享内存实现高速的数据交互。本系统对256×256个数据线程的并行架构配置如图7所示。
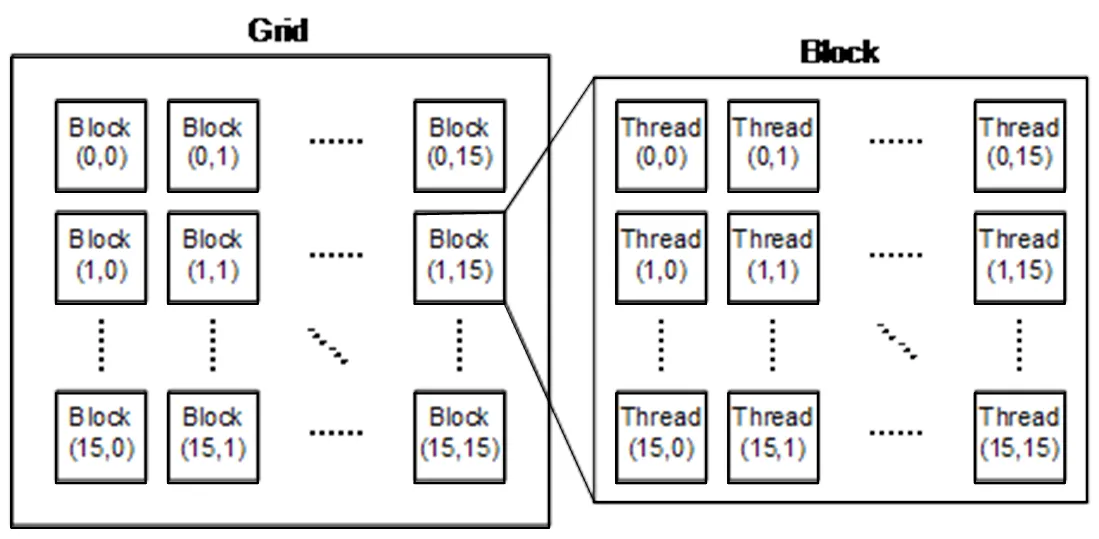
图7 GPU数据处理的并行架构配置
为便于图像数据处理,Block和Grid的配置全部为16×16二维形式,每个线程通过坐标索引与像元Pixel(,)形成一一对应关系。
编译环境方面,CUDA提供了NVCC编译器,在Windows下,NVCC支持VC++8.0及以后版本编译器,本系统基于Visual Studio 2008编译环境开发CUDA并行计算的数据处理软件。
数据传输流程如图8所示,从GPU的帧缓存中读取的灰度数据不再由CPU计算,而是再次传送到GPU中进行并行处理,最终量化DA电压值通过PCIE总线回传至系统内存。测试结果如图9所示。
测试结果的统计数据如表3所示。
与CPU数据处理相比,均值和标准差的大幅降低表明GPU数据并行处理的速度和时间稳定性都得到良好改善,然而仍存在一个超时帧,这是数据处理的随机超时导致的。
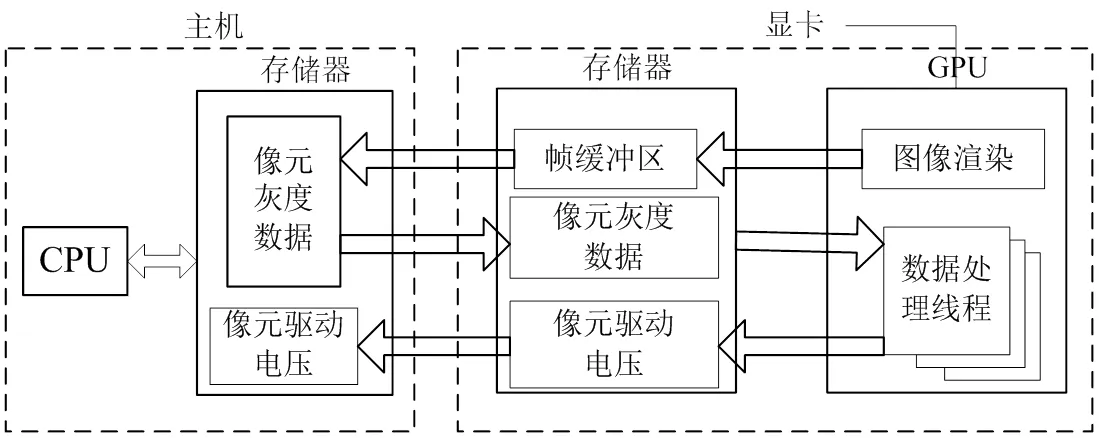
图8 数据传输流程
图9 基于CUDA的GPU数据并行处理实时性测试
Fig.9 Real-time testing of GPU data processing collaterally based on CUDA
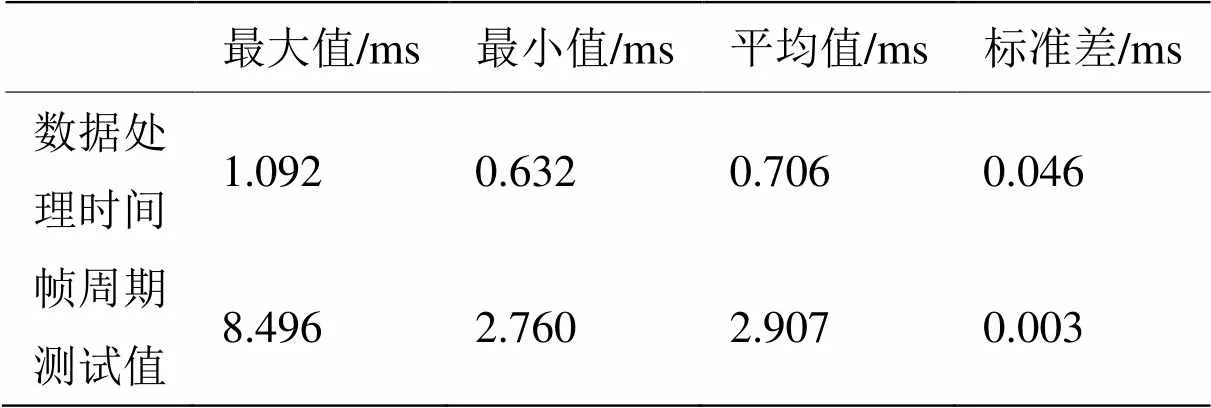
表3 基于CUDA的GPU数据并行处理测试结果统计
4.3 基于PBO技术的进一步改进
由图8分析可知,采用GPU并行处理图像数据时,主机和显卡设备间要进行三次数据传输,这主要是PCIE总线对显卡帧缓存和显存的读写操作,而几乎所有的CUDA并行计算都会受到存储带宽限制,不难预测,尽量减少主机和设备间的数据传输,可以进一步提高数据处理速度。
灰度数据通过OpenGL接口实现显卡帧缓存到主机内存之间的传递,而OpenGL提供的像素缓冲对象(Pixel Buffer Object,PBO)技术,可以实现数据在设备内部的交互,其过程如图10所示。
系统采用PBO技术做进一步改进,将数据处理始终放在设备内部运行,最终量化DA数据传输到主机内存。这样,一帧图像数据处理只需进行一次PCIE总线数据传输,测试结果如图11所示。
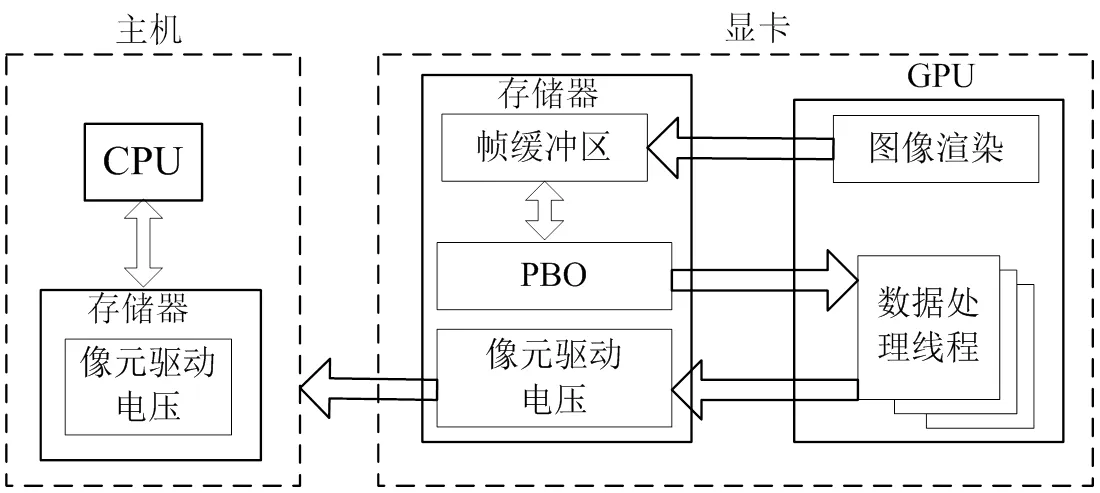
图10 基于PBO的设备内部数据读取
图11 基于PBO的实时性测试结果
Fig.11 Real-time testing data based on PBO
测试结果统计数据如表4所示。
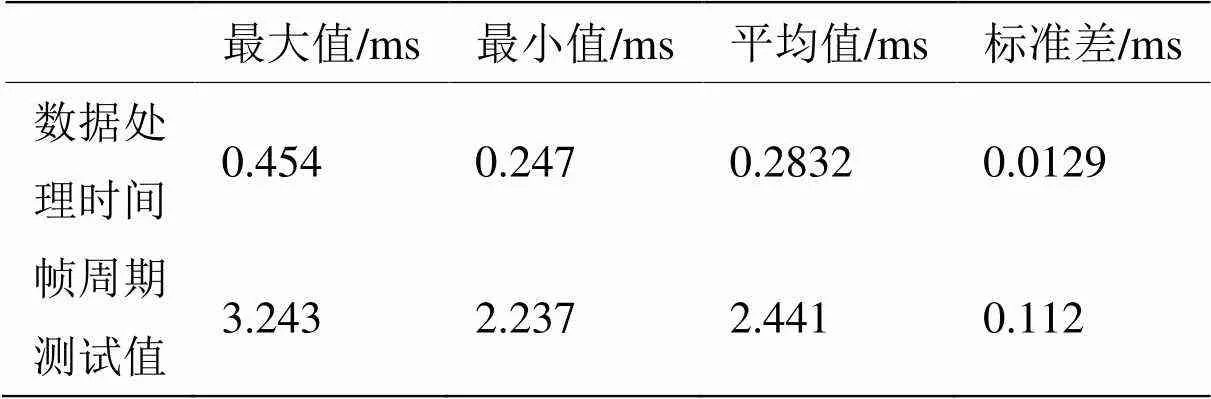
表4 基于PBO技术的数据并行处理测试结果统计
测试结果验证了改进方案的可行性,数据处理时间和帧周期得到进一步改善,帧周期最大值仅为3.216ms,很好地满足了5ms的系统帧频要求。
5 结论
对红外图像生成系统的计算过程分析表明,数据处理是主要耗时环节。通过设计实时性评估软件,针对基于CPU进行数据处理耗时长的不足,提出基于CUDA的GPU数据并行处理和应用PBO技术的改进思路。测试结果表明,改进方案较为理想地满足了系统200Hz帧频要求,为后续更大规模电阻阵列的投入使用提供了时间余度。
由于图像生成系统运行在非实时的Windows系统,且实时性评估软件采用CPU计数器测时,后台组件对CPU资源的随机抢占直接导致测试结果剧烈震荡、标准差较大,下一步将考虑采用Linux等实时性好的操作系统,进一步提高系统的实时性和测试结果的置信度。
[1] 李守荣, 梁平治, 屈新萍. 红外微辐射源的研制[J]. 红外与毫米波学报, 2003, 22(4): 277-280.
[2] Leszek Swierkowski, Williams O M. Advanced flood nonuniformity correction for emitter array infrared projectors[C]//, 2002, 4717: 108-119.
[3] Leszek Swierkowski, Robert A J, Williams O M. Rsistor array infrared projector nonuniformity correction: search for performance improvement IV[C]//, 2009, 7301: 73010M.
[4] 李艳, 孟庆虎, 吴永刚. 国外电阻阵列非均匀性校正技术概述[J]. 红外技术, 2010, 32(8): 453-456.
[5] 肖云鹏, 马斌, 梁平治. 国产电阻阵列动态红外景象投射器研制进展[J]. 红外技术, 2006, 28(5): 266-270.
[6] 苏德伦, 廖守亿, 张金生, 等. 电阻阵列红外景象投射器非均匀性实时校正[J]. 红外技术, 2014, 36(7): 521-526.
[7] 苏德伦, 廖守亿, 张金生, 等. 电阻阵列非均匀性校正[J]. 红外与激光工程, 2009, 38(增刊): 311-315.
[8] 苏德伦, 廖守亿, 张金生, 等. 电阻阵列非均匀性校正算法实时性研究[J]. 红外技术, 2009, 31(11): 634-638.
[9] 吴永刚, 王旌, 周博. 电阻阵红外景象投影仪非均匀性校正方法学[J]. 航空兵器, 2010(6): 63-66.
[10] 苏德伦, 王仕成, 廖守亿, 等. 基于CIG的动态红外图像实时生成系统[J]. 红外技术, 2009, 31(9): 549-552.
Real-time Improvement for Resistor Array Nonuniformity Correction
ZHANG Jin-cheng1,LIAO Shou-yi1,ZHANG Zuo-yu1,SU De-lun2,YAN Xun-liang1
(1.,’710025,; 2. 96111,715400,)
The nonuniformity of resistor array must be corrected in the infrared scene projecting, besides, the real-time of correction methods must satisfy the frame frequency index. By means of designing real-time estimating software, the previous time-consuming data processing method based on CPU was improved, and the GPU collateral data processing method based on CUDA was proposed, meanwhile, the PBO technology was applied for further optimizing. Testing results indicate that the improved method can substantially advance the data processing speed, and the ideal real-time provides time redundancy for the larger resistor array follow-up.
resistor array,nonuniformity,GPU,CUDA,real-time
TN216
A
1001-8891(2015)11-0921-05
2015-07-22;
2015-09-11.
张金城(1990-),男,河北沧州人,硕士研究生,研究方向为导航、制导与仿真。
中国博士后科学基金项目,编号:2013M532125、2014T70974。
