基于两重误差重构的显著性区域检测算法
2015-03-31范明喆王鲁平张路平
范明喆,王鲁平,张路平
基于两重误差重构的显著性区域检测算法
范明喆1,2,王鲁平1,张路平1
(1. 国防科技大学 ATR国家重点实验室,湖南 长沙 410073;2. 武警韶关支队,广东 韶关 512000)
通过SLIC分割算法将图像分成多个超像素区域后,利用重构误差进行视觉显著性检测。首先提取图像边缘的超像素区域作为背景模板,然后利用这些模板构建两重外观模型:稀疏外观模型及稠密外观模型。对于每一块图像区域,首先计算稠密重构误差及稀疏重构误差,然后利用均值聚类方法得到的上下文对重构误差进行传播,再利用贝叶斯准则融合稀疏型检测结果及稠密型检测结果,最后通过综合多尺度重构误差信息及修正的目标基高斯模型信息实现像素级显著性检测。
超像素;稠密重构误差;稀疏重构误差;显著性检测
0 引言
稠密外观模[1-2]型将每一个数据点建模为特征空间中的多元高斯分布,在采样数量有限的条件下,很难捕获到多重离散模式,因而在进行显著性度量时,精度不高,即使是对背景区域建模也有可能得到较大的重构误差。由于稀疏重构误差可以较好地抑制背景,故检测结果中背景干扰小,效果较好。
虽然稀疏重构误差检测结果在某些场景下优于稠密重构误差检测结果,但在进行显著性度量时也存在一些不足之处[3-6]。例如,当目标出现在图像边界时,就会把前景分割结果当成是背景模板,当用这些含有前景目标的模板对目标进行稀疏表示时,由于稀疏重构误差较小,边界处目标区域的显著性度量值将接近于0,从而将该区域检出为背景。此外,由于误将前景分割结果当成是部分稀疏基函数,对其他区域进行显著性度量时,精度会下降。相比而言,稀疏外观模型则不受此影响,当误将前景分割区域当成是背景模板时,利用从稠密外观模型中提取出的主成分来描述这些前景区域时有效性会降低[7-13]。如图3中第3行所示,部分前景目标区域位于图像边界,利用稀疏重构误差度量将不能检出该区域,而稠密重构误差度量则能较好的检出该区域。由此可知,稀疏重构误差能够处理复杂背景中的显著性目标检测,而稠密重构误差可以较好地解决位于图像边界处目标的分割,故二者可以互补,共同作用可以大幅提高显著性度量精度,以此思想提出本文算法。
1 SLIC(Simple Linear Iterative Clustering)像素分割
许多有关目标分割、检测、识别、跟踪等算法都是在像素级上进行操作,在进行逐像素处理时,存在两方面问题:一是往往只关注图像中部分有用信息,若对所有像素都进行处理,不仅计算量大,且有可能耗费大量资源计算无关像素信息;二是单一像素点包含的信息量少,仅用这些孤立的像素点信息无法给出一个对感兴趣区域的完整描述、缺乏整体性。在进行显著性目标检测时,对人眼视觉感官系统而言,能引起视觉注意的恰恰不是这些单个像素点,而是由许多具有相似属性的单像素点组成的集合,该集合就称为一个超像素区域,该区域不仅包含了纯像素点所具有的相近的色度、位置信息,而且还包含了只有这些单像素点组合在一起时才表现出的轮廓、边界等信息。利用超像素分割技术可将图像分割为多个具有相似颜色、纹理等信息的小区域,每个区域具有相似属性,故在一定程度上能够较好地保持图像中目标的边界信息。在进行操作处理时,可将超像素当成是单个像素点来处理,这不仅有助于简化计算降低计算量,而且还可避免由纯像素级运算而陷入的局部最优。此外,相对于显著区域来说,图像中的非显著区域可认为是图像中的冗余信息,将不同区域聚类为超像素并对最有意义的超像素区域进行操作,从效果上讲相当于对图像中的冗余信息进行过滤。用图像区域中的超像素替代单个像素点参与运算,具有表示高效、运算快捷的优势,且超像素比单像素更符合人眼的视觉感知特性[14-15]。本文在计算图像的显著性获取显著图时,是在超像素级上进行处理,以超像素区域为最小处理单元。
由于SLIC(Simple Linear Iterative Clustering)算法相对成熟,本文不再详细介绍。图1给出了两组超像素分割结果,第一列为原图,第二、三、四列为超像素数分别为=50,=200,=400时的SLIC分割结果,由对比可知,超像素数越多,分割得到的超像素紧凑性就越好,分割区域就能更为完整地保留图像中目标的边缘信息,分割后的结果更有利于完整的提取出图像中的显著性目标。SLIC超像素分割是本文实现显著性目标检测的基础。
2 背景模板的提取
本文通过利用背景模板构建由稠密及稀疏表示的图像区域实现对视觉信息的充分利用,其中每一块图像区域的显著性用背景模板构建的重构误差进行度量。将图像边界视为可能的背景区域,并从这些区域中提取背景模板,利用这些模板构建稀疏及稠密外观模型,通过重构误差对图像中的显著性区域进行指示。

图1 SLIC超像素分割结果
为了更好地捕获图像区域的结构信息,首先利用SLIC算法产生超像素区域,将输入图像分割成多个均匀紧凑的区域。文献[16-17]指出,同时使用Lab颜色空间及RGB颜色空间可以得到高精度的显著图。本文利用每一个超像素区域的颜色特征均值及坐标对其进行描述,即={,,,,,,,},则整个图像可以表示为=[1,2, …,x]ÎR*,其中为每一个特征的维数,为分割区域总数。一般的检测方法认为图像边界蕴含大量的视觉背景信息,可用于检测显著性目标。此外,这些方法还假定具有视觉显著特性的目标最有可能出现在场景的中间部分,然而这种假定未必时刻都成立。尽管如此,这些方法仍可以提供有用的视觉信息用以检测显著性目标。据此,本文提取每一个边界区域的维特征,并利用这些特征构建背景模板集=[1,1, …,b]ÎR*,其中为图像边界分割区域总数。
3 两重重构误差的构建
3.1 稠密重构误差
用背景模板集表示某个分割区域时,若得到的重构误差较大,则该区域极有可能是前景目标。基于该事实,每一个图像区域的重构误差可利用稠密外观模型计算得出,而该外观模型可以通过对背景模板集进行主成分分析得到。假定计算的PCA基可得到特征矢量U=[1,1,…u],它对应的归一化方差矩阵中最大的个特征值。利用PCA基U可以计算出任意一个分割区域x(Î[1,])的重构系数,即:
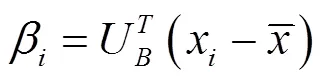
第块分割区域对应的稠密重构误差为:
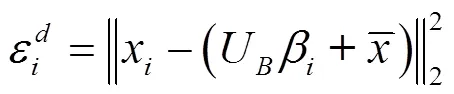
3.2 稀疏重构误差
将背景模板集看成是稀疏表示的基,将第块分割区域编码为:
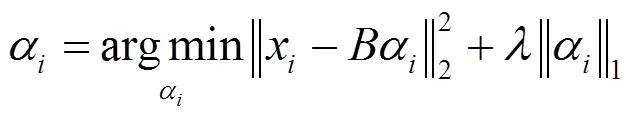
稀疏重构误差为:
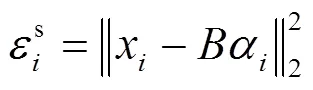
4 基于上下文的重构误差传播

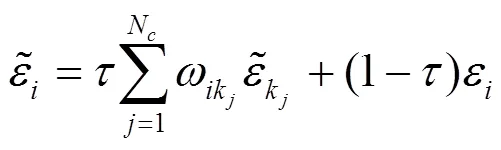
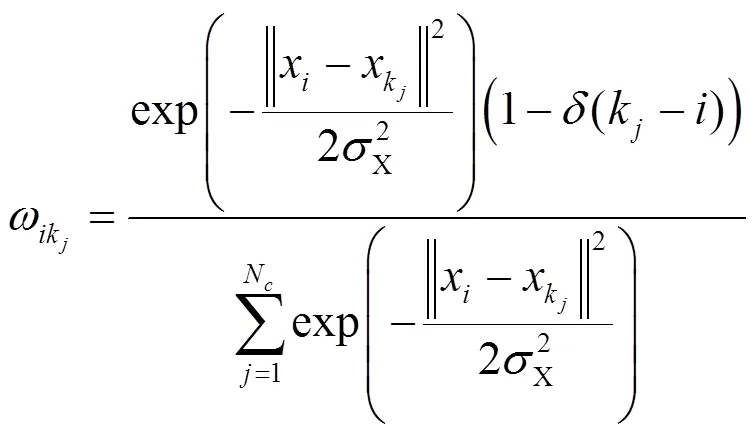
图2给出了两组运用上下文传播机制对重构误差进行平滑的例子,并与利用原始重构误差检测的结果进行对比,由对比可知,通过误差传播,图像中检出的显著性目标区域的灰度更均匀更明亮。第二行给出了一个目标处于图像边缘的例子,在该例子中,许多位于目标上的分割区域都被错误的当成是背景模板,因而它们不能被稠密及稀疏外观模型正确辨识,然而利用其周围上下文区域并根据(5)式对其重构误差进行修正后得到的检测结果则能较好的将显著性目标检测出来。

(a) 原图;(b) 稠密重构误差检测结果;(c) 稠密重构误差上下文传播检测结果;(d) 稀疏重构误差检测结果;(e) 稀疏重构误差上下文传播检测结果
5 像素级显著性检测
对于一幅高分辨率的显著性图像,需要对每个像素都赋予一个显著性度量值,而该度量值是在得到修正的目标基高斯模型后,融合多尺度重构误差结果得到的,下面将分别介绍多尺度重构误差融合及目标基高斯模型修正。
5.1 多尺度重构误差融合
为了处理尺度问题,在N个不同尺度上生成超像素区域。对每一个尺度都计算并传播稠密重构误差及稀疏重构误差,最后融合多尺度重构误差以计算出像素级重构误差,即:
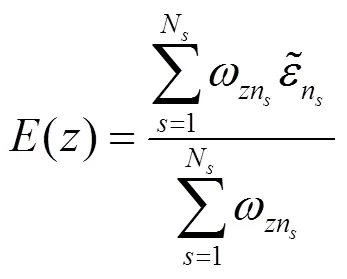

式中:f表示位于点处的像素的维特征矢量;n为分割区域标记,它表征了尺度为时该区域中包含了像素点。
利用像素点与其对应的分割n间的相似性作为权重以求取多尺度重构误差的均值。通过多尺度重构误差融合,可以更为准确地检测出显著性目标,这就意味着利用多尺度融合机制能更有效地对显著性进行度量。
5.2 基于目标基的高斯模型修正
一般的显著性检测方法认为目标位于图像中心并将其作为已知的先验信息应用到高斯建模过程中,即:
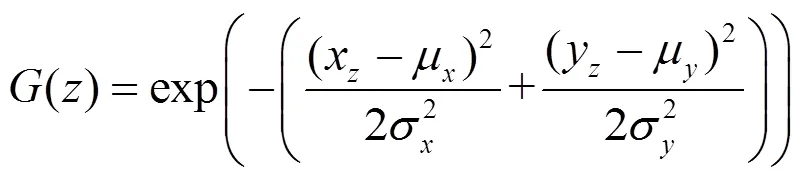
式中:=c,=c,表示图像中心点坐标;x,z表示像素点的坐标。由于具有视觉显著性的目标并非总是出现在图像的中间部分,此时中心基高斯模型就不再适宜描述这种情形,因为它有可能包含背景像素或丢失前景区域。为此,本文用目标基G替代中心基,它更能反映出真实的目标区域分布,在目标基中=x,=y,其中x,y为目标中心,它可以利用式(7)中的像素误差导出,即:
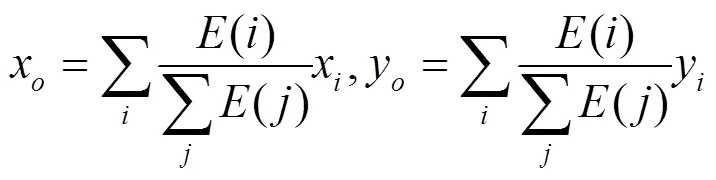
令=0.25,=0.25,其中,分别表示输入图像的宽与高。利用目标基高斯模型,位于出的像素点的显著性度量值可以通过下式计算得到:
()=o()() (11)
图3给出了一个处于图像边界的目标,分别用目标基与中心基对由重构误差得到的显著图修正后得到的显著性检测结果,由对比可知,目标基高斯模型得到的目标中心精度更高,周围物体干扰更小,因而能更好地修正显著性检测结果。
6 基于贝叶斯准则的显著图融合
利用稠密重构误差及稀疏重构误差在对显著性进行度量时可以实现优势互补,本文利用贝叶斯定理实现这两种显著性度量结果的融合。贝叶斯准则通过传递后验概率实现显著性度量,计算公式如下:
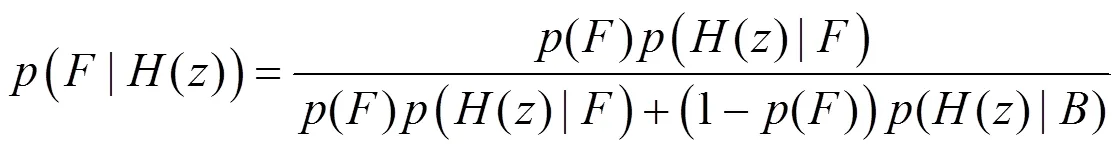
式中:先验概率()为均匀分布;()为点像素的特征矢量。似然概率计算式如下:
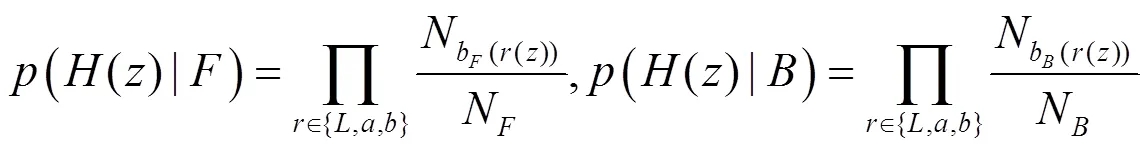

假定由稠密重构误差及稀疏重构误差得到的显著图为1,2,任选其中的一类显著图作为先验信息S(={1,2}),用另一类显著图S(≠={1,2})来计算似然值,二者融合过程如图4所示。首先计算显著图S的均值,并用将该均值作为阈值对S进行分割,以获取前景区域F及背景区域B,然后根据像素点在前景及背景中所处的划分区间对S与S进行比较以计算出该区域的似然值,即:
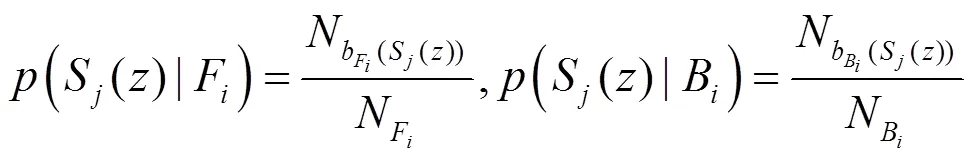
因此,在得到先验信息S的条件下,后验概率的计算公式为:
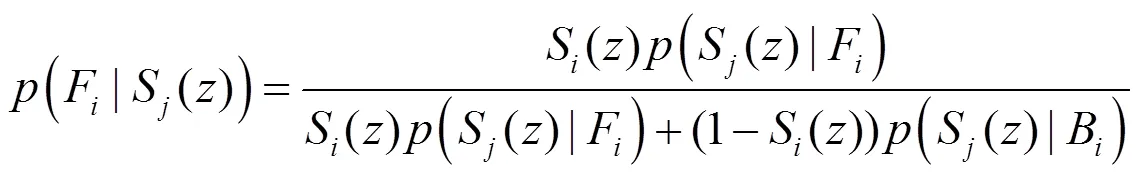
类似可计算出S的后验显著性。在得到两类后验概率后,就能在贝叶斯框架下对二者进行融合以计算出最终的显著图S(1(),1()),即:
上述融合方法必须将其中的一类显著图当成先验信息,并与另一类显著图有效配合,才能得到灰度均匀明亮的显著性目标。
7 实验仿真
参数设定:在稠密误差重构对背景模板进行主成分分析时,取占总能量95%的主成分所对应的特征向量作为基来计算重构系数。稀疏误差重构时,令误差项系数=0.01;利用上下文传递重构误差时,令均值聚类类别数为8,最大迭代次数为200,权重因子=0.5;在8组不同尺度上对重构误差进行融合;利用目标基对误差重构显著图修正时,令=0.25;在进行贝叶斯融合时,令颜色划分区间数为60,颜色直方图平滑系数为0.02。

图3 目标基与中心基修正显著图结果对比
图5给出3组显著性检测实验结果。
图5(a)为3组红外图像,图5(b)~图5(h)分别为稀疏误差重构显著性检测结果、稀疏重构误差传递检测结果、稀疏重构误差目标基修正结果、稠密误差重构显著性检测结果、稠密重构误差传递检测结果、稠密重构误差目标基修正结果及贝叶斯显著图融合结果。
在第一组图像中,目标较亮、周围背景灰度较暗,它们都具有视觉显著性,因而基于误差重构出的检测结果二者都包含其中,如图5(d)所示,虽然稀疏重构误差目标基修正结果背景杂物干扰小,但部分显著目标灰度值较小,容易丢失,这意味着该方法虽然虚警率低,但它是以牺牲检测概率为代价换取的。利用稠密重构检测结果中,如图5(g)所示,虽然检出结果中包含待识别的目标,但周围干扰物较多,说明该类方法是以增加虚警率为代价而获得较高的检测概率,将二者进行贝叶斯融合,可结合二者优势,有效降低干扰,同时又不丢失待检出的对象,如图5(h)所示。同理,在第二、三组图像中,待检测目标周围干扰较小,稀疏误差重构方法易降低显著性目标灰度,而稠密误差重构方法虽然能够凸显显著目标灰度,但也容易将与目标灰度相近的背景当成显著性目标检出。将两种方法检测结果融合,可保证或获取的目标灰度值不明显降低,同时排除部分背景干扰,检出效果较为理想。

图4 基于贝叶斯准则的显著图融合流程
[1] 王芸. 基于HITS的图像显著性检测算法[D]. 大连: 大连理工大学, 2013.
Wang Yun. The detecting algorithm of image saliency based-on HITS[D]. Dalian: Dalian University of Technology, 2013.
[2] 李勇. 基于区域对比度的视觉显著性检测算法[D]. 上海: 上海交通大学, 2013.
Li Yong. The saliency detecting algorithm based on region contrast[D]. Shanghai: Shanghai Jiaotong University, 2013.
[3] Itti L, Koch C, Niebur E. A model of saliency-based visual attention for rapid scene analysis[J]., 1998, 20(11):1254-1259.
[4] Hael J, Koch C, Perona P. Graph-based visual saliency[C]//, USA: MIT Press, 2007: 545-552.
[5] Zhai Y, Shah M. Visual attention detection in video sequences using spatiotemporal cues[C]//14, New York, 2006: 815-824.
[6] Cheng M M, Zhang G X, Mitra N, et al. Global contrast based salient region detection[C]//, USA, 2011: 409-416 (doi: 10.1109/ CVPR. 2011.5995344).
[7] Achanta R, EstradA F, Wils P, et al. Salient region detection and segmentation[C]//, Greece: Springer Berlin/Heidelberg, 2008, 5008: 66-75.
[8] Hou X, Zhang L. Saliency detection: A spectral residual approach[C]//. USA, 2007: 1-8(doi:10.1109/CVPR.2007.383267).
[9] Guo C, Ma Q, Zhang L. Spatio-temporal saliency detection using phase spectrum of quaternion fourier transform[C]//, USA, 2008: 1-8(doi:10.1109/CVPR.2008.4587715).
[10] Rahtu E, Kannala J, Salo M, et al. Segmenting salient objects from images and videos[C]//11, Prague: Springer, 2010: 366-379.
[11] Duan L, Wu C, Miai J, et al. Visual saliency detection by spatially weighted dissimilarity [C]//, USA, 2011: 473-480(doi: 10.1109/ CVPR. 2011.5995676).
[12] Liu T, Zhang N, Ding W, et al. Video attention: Learning to detect a salient object sequence[C]//19, USA:, 2008: 1-4.
[13] Wang M, Konrad J, Ishwar P, et al. Image saliency: From intrinsic to extrinsic context[C]//. USA, 2011: 417-424 (doi: 10.1109/ CVPR. 2011.5995743).
[14] 王飞. 基于上下文和背景的视觉显著性检测[D]. 大连: 大连理工大学, 2013.
Wang Fei. The visual salience detecting based on context and background[D]. Dalian: Dalian University of Technology, 2013.
[15] 谢玉琳. 贝叶斯框架下的图像显著性检测[D]. 大连: 大连理工大学, 2011.
Xie Yulin. The image saliency detecting under bayesian framework[D]. Dalian: Dalian University of Technology, 2011.
[16] Borji A, Itti L. Exploiting local and global patch rarities for saliency detection[C]//, 2012: 478-485.
[17] Li X H, Lu H H, Zhang L H, et al. Saliency detection via dense and sparse reconstruction[C]//, 2013: 2976-2983 (doi:10.1109/ICCV.2013.370).
Regional Detection Algorithm Based on Double Error Reconstruction
FAN Ming-zhe1,2,WANG Lu-ping1,ZHANG Lu-ping1
(1.,,410073,;2.,512000,)
In this paper, the SLIC segmentation algorithm is used to divide an image into several super-pixel areas. Then, the reconstruction error is used in visual saliency detection. Firstly, the proposed algorithm extracts the image edge of super-pixels area as a background template. Then, use these templates to build double appearance model. For each image region, we calculate dense reconstruction error and sparse reconstruction error, then, the context which is the result of the K-means clustering methods is used for the reconstruction error propagation and reuse Bayesian mix dense results and sparse results. Finally, though synthesizing multi-scale reconstruction error information and corrected objective groups Gaussian model information to achieve the objective pixel-level saliency detection.
super-pixels,dense reconstruction error,sparse reconstruction error,visual saliency detection
TN911.73
A
1001-8891(2015)11-0962-08
2015-01-27;
2015-03-17.
范明喆(1982-),男,吉林长春人,硕士研究生,主要方向为光学成像自动目标识别。E-mail:32064283@qq.com。
