提升大规模集群上并行计算软件系统可靠性和服务性的方法与实践*
2015-03-27林彦宇韩佳龙媚赖路双
林彦宇,陈 虎,苗 军,韩佳龙媚,赖路双
(华南理工大学软件学院,广东 广州 510006)
提升大规模集群上并行计算软件系统可靠性和服务性的方法与实践*
林彦宇,陈 虎,苗 军,韩佳龙媚,赖路双
(华南理工大学软件学院,广东 广州 510006)
大规模集群上的并行计算软件需要具备处理部分节点、网络等失效的容错能力,也需要具有易于管理、维护、移植和可扩展的服务能力。针对星形计算模型,研究和开发了一套并行计算框架。利用调度节点内部的可变粒度分解器、相关队列等方法,实现了全系统容错,且具有较好的易用性、可移植性和可扩展性。系统目前可以实现300 TFlops计算能力下连续运行超过150 h,而且还具有进一步的可扩展能力。
可靠性;可扩展性;服务性;大规模集群;并行计算软件
1 引言
可靠性(Availability)和服务性(Serviceability)是软件系统的RAS属性中的重要组成部分[1],前者指系统可以正常运行的时间比例,后者指软件使用、维护、改进和升级的难易程度。这两个问题在大规模集群软件系统中显得尤为突出,主要体现在以下几个方面:
(1)大规模集群软硬件结构复杂,包括节点计算机、互连网络、操作系统、协议栈和基础库等内容,而且计算过程中所涉及的节点众多,系统基础平台的整体平均无故障工作时间大大低于一般单机系统;
(2)并行计算软件自身算法复杂,运行时间长,一旦运行过程中失效,重新计算的开销很大;
(3)并行计算软件要能适应不同的节点、互连网络结构和规模的多种大规模集群,对于系统可配置性、可扩展性和可管理性的要求更高。
本文针对大规模集群并行计算软件的上述挑战,介绍了某大规模并行计算软件的计算模型和软件总体结构,重点讨论了提高系统可靠性、增强系统可管理性,以及针对不同集群结构的可配置性和可伸缩性的方法。
2 相关工作
大规模集群并行计算过程中,系统基础平台的整体平均无故障工作时间较低,需要通过改进应用软件的方法提升系统整体可靠性。限于篇幅,这里仅仅讨论MPI(Message Passing Interface)[2]和MapReduce两种并行编程模型下的软件可靠性设计方法。
MPI是当前高性能计算的最主要编程模型。该模型自身并未提供提高系统可靠性的方法,往往采用在检查点将当前运行的现场记录在文件中的方法,如果系统发生故障则从前一个检查点恢复计算现场,从而避免了从头重新计算。检查点又可以分为系统级检查点和用户级检查点两种,前者的典型代表是美国Ohio大学的MVAPICH2系统[3],后者则是由程序员根据算法的特点在合适的地方自行设置和实现。
这两种方法各有利弊,前者对程序员透明,易于编程,但是开销较大;后者需要程序员对已有并行软件进行改造。这两种方法虽然都可以避免从头计算的开销,但是系统的容错能力有限。这是因为MPI编程模型中计算的规模(节点数)预先确定,任何一个节点的失效都会导致整个计算过程中途失败。回退到检查点后,往往需要人工干预、重新调整计算规模或启用新的计算节点。对于大规模、长时间的计算任务而言,将大大增加系统管理难度。
MapReduce[4]是Google公司提出的面向大数据处理的并行架构。它与Hadoop并行文件系统紧密相连,其map任务分解数正比于Hadoop文件系统中的文件分块数。在任务执行前,需要将任务所需要的资源(包括任务执行代码、配置文件、输入文件分段)拷贝到Hadoop文件系统的指定目录中,并在执行过程中由执行代码读取,这将导致大量的文件内容在内部互连网络传输。MapReduce提供了节点失效的自动处理能力,但是在重启计算任务过程中,也需要将输入文件拷贝到新的计算节点上,会造成额外的开销。因此,MapReduce更适合于基于文件的大数据并行处理系统,并不适合于计算密集型应用。
3 一个面向星形计算模型的并行计算框架
高性能计算应用软件体系结构往往与其计算模型密不可分,本文所研究的星形计算模型可以描述为以下三个步骤:
(1)任务分解:计算量为S的作业J分解为N个计算量分别为S1,…,SN的节点任务T1,…,TN;
(2)并行计算:P个计算节点并行完成计算任务T1,…,TN,并得到对应的计算结果R1,…,RN;
(3)结果合并:系统的最终结果R取决于R1,…,RN。
节点任务T1,…,TN都是计算密集型任务,执行过程之间没有相关性,也不进行相互通信。最后的结果合并过程非常简单,计算量仅为O(N)。虽然星形计算模型非常简单,但是应用非常广泛,例如大空间的并行搜索、动漫渲染中对多个文件的并行渲染等。
为了实现星形计算模型,系统包含了管理节点、调度节点和计算节点三个主要部分,如图1所示。其中管理节点负责整个系统的管理和监控,提供用户添加、删除、查询作业等操作界面,同时向用户反馈作业的执行情况。调度节点主要负责将作业分解为适合于节点计算的任务,并将任务分配到相应的计算节点上。计算节点负责完成调度节点发出的节点任务。
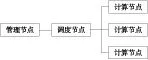
Figure 1 System structure
调度节点是整个系统的核心,其软件总体结构如图2所示。

Figure 2 Software structure of scheduling nodes
调度节点中的核心是作业分解器(Decomposer),其任务是将计算量为S的作业J分解为N个计算量分别为S1,…,SN的节点任务T1,…,TN。该通用计算模型中,分解器应可以事先设定目标计算粒度Starget,使得任务平均计算粒度S/N尽量接近于它。在实际的分解器中,往往很难做到每个节点任务的粒度都等于目标计算粒度,但应该满足min(S1,…,SN)>(1/λ)Starget和max(S1,…,SN)<λStarget,其中λ一般不超过3。本系统中使用的分解器主要是对字符空间进行分解。分解器通过预设的计算粒度将字符空间分解成相互独立的子空间。用户可以通过自定义分解器替换本系统已有的字符空间分解器来实现对新类型的分解。
调度节点中还包含了三个队列:全局队列gq(GlobalQueue)、完成队列dq(DoneQueue)和任务队列jq(JobQueue)。其中全局队列gq用于存储已经被分解的但尚未投入计算节点的任务,完成队列dq存储所有已经发给计算节点但尚未返回结果的任务,任务队列jq则用于存储尚未进行分解的作业。同时,每个计算节点都有一个与之对应的节点队列NodeQueue用于存储分配到该计算节点、但尚未发送给该计算节点的计算任务。
调度节点中有六个线程并行工作,其中最主要的线程为周期性执行的(周期一般设定为10 s)Dispatcher线程,其核心算法为:
(1)如果分解器已分解完当前作业,则从作业队列中重新取一个作业,并调用分解器;
(2)将作业分解为若干计算任务(任务分解数由gq队列的空闲长度决定),并插入gq队列中;
(3)根据一定的分派算法将gq中的任务分派到计算节点队列NodeQueue上,同时将此任务也插入到dq队列,并记录插入dq队列的时间Tdq。
(4)检查所有dq队列中的任务t,如果当前时间T和Tdq大于阈值Tretry,则将此任务从dq中删除,并重新加入gq队列。
Result线程将监听计算节点返回的结果,根据结果中包含的全局唯一任务号在完成队列dq中查找,如果找到则将其从dq队列中删除;Task线程监听管理节点的TCP连接,并负责接收管理节点发出的新建作业命令,并将该作业插入到作业队列jq中;Sender线程负责将Dispatcher分派到NodeQueue的任务通过UDP连接发送到相应的计算节点上;Status线程负责将系统状态信息周期性反馈给管理节点;Command线程主要监听管理节点TCP连接,并处理管理节点发送过来的控制命令。
计算节点在接收到调度节点发来的任务后,将任务记录在一个队列中。如果计算节点有K个计算部件,则可以同时执行K个任务。任务计算结束后,将计算结果通过UDP协议发送回调度节点,由Result线程处理计算结果。当计算节点的队列将满时,将向调度节点发送减速命令;队列将空时,发送加速命令,从而保证计算节点的队列长度处于合适大小。
4 容错性设计方法
在上述系统中,为了提高系统的可靠性,使得系统具有一定的容错能力,我们使用了以下具体方法。
4.1 计算节点失效的处理方法——调度节点的任务重发机制
在大规模集群的长时间计算过程中,难免会出现一个或多个计算节点失效的情况。为了防止计算任务丢失,本系统利用dq队列实现失效计算节点任务的重计算。在Dispatcher分派线程中,当将一个节点任务插入到gq时,也同时会将其插入到dq中,并且记录其加入dq的时间。当要向各个计算节点分派节点任务时,调度节点从gq取出节点任务,但不删除dq中对应的元素。当一个节点任务计算完成时,调度节点会收到来自计算节点的反馈信息,这时调度节点才会把dq中对应的节点任务删除。因此,通常情况下,每一个节点任务只会在dq中驻留一段时间。如果dq中某个任务的驻留时间超过阈值,调度节点认为此节点任务因网络故障或者计算节点失效而不能完成,会把该节点任务重新插入到gq中,重新分配到其他计算节点,从而实现计算节点或互连网络失效时计算任务重发的处理过程。
4.2 调度节点失效的处理方法——定时保存和恢复
在大规模集群中,还可能出现调度节点失效的情况。为了应对这种情况,在调度节点中有一个定时备份线程(周期一般为30 min),定时保存调度节点当前运行状态到特定的现场文件,以便在调度节点失效时恢复。该线程保护的内容主要包括:
(1)当前计算作业信息,包括提交用户、作业名、作业的具体内容、运行状态等。
(2)分解器状态。由于较大的计算作业不可能一次性完全分解,我们所采用的策略是边计算边分解。因此,正在执行的计算作业中,有些任务已经分解完成,有些则处于尚未分解的状态,需要保护当前分解器的这些现场。
(3)调度节点中的gq队列、dq队列和jq队列。
调度节点意外失效后,重启时将检查系统的现场文件,并通过现场文件恢复失效前系统的运行状态。由于定时备份的周期为30 min,因此在计算节点失效时最多可能会浪费30 min的计算能力。
4.3 互连网络失效的处理方法——计算节点失去连接后对调度节点的自动重连
在大规模集群中,可能会有部分互连网络故障(例如某机柜的交换机暂时失效),导致部分计算节点和调度节点的通信中断。为了解决此类问题,系统使用了如下两种方法:
(1)计算节点每隔一定时间间隔会向调度节点发送心跳报文,以通知调度节点该计算节点仍可用。
(2)若计算节点处于空闲状态,则它会统计处于空闲的时间。若该时间超过预先设定的阈值,则认为计算节点可能由于互连网络失效而和调度节点失去连接。此时,计算节点会每隔一定周期就向调度节点发送一个重连报文,以便和调度节点重新建立联系。
5 易用性设计方法
5.1 在线监控
在系统正常运行过程中,调度节点会周期性地统计和输出以下信息,供系统管理员实时监控系统运行状态:
(1)当前每个计算节点的计算能力、系统平均计算能力等信息;
(2)当前周期内计算节点的加速和减速命令个数;
(3)gq队列和dq队列的长度及重发的任务数;
(4)分解器的任务粒度、分解的任务数、任务平均大小等;
(5)当有新的计算节点加入到集群、发送一个节点任务、删除一个节点任务等情况时,调度节点都会显示相应的信息。
计算节点每个周期都会输出一些信息,以方便系统管理员实时了解计算节点的运行状态:
(1)计算节点的配置信息,包括CPU型号、计算加速卡型号和卡数、内存大小等信息;
(2)计算节点中的任务队列长度及各计算加速卡的负载情况;
(3)计算节点的空闲时间。
通过上述信息,系统管理员可以实时了解整个系统的工作状态,并及时发现可能存在的问题。
5.2 离线监控
由于作业的计算时间可能长达一周,系统管理员难以24 h监控系统运行。调度节点会对系统的运行状态进行实时记录,产生基于XML格式的日志文件。系统管理员可以使用离线监控软件对日志文件解析,并实现可视化显示,分析整个运行过程中系统的运行状态。
调度节点实时保存的信息主要分为三类:
(1)计算节点的基本信息,包括计算节点启动时间、日志文件最后保存时间、系统名等;
(2)某时刻系统中的计算节点数;
(3)计算节点上所有任务的运行状态。
在离线管理节点,由C#语言编写的Windows桌面应用程序,使用System.XML命名空间下针对日志文件格式的函数来对日志文件进行读取和解析,并使用WPF开源控件库DynamicDataDisplay将信息可视化显示。图3给出了一个典型日志文件的显示状态。
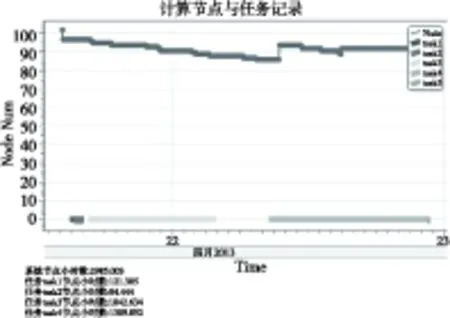
Figure 3 Status of computing nodes on a small-scale test
5.3 作业的不间断运行
在大规模集群中,经常需要提交多个作业。若一次同时提交并执行多个作业,将导致各个作业的完成时间都很长,不利于及时评估任务的执行情况。但是,如果每次仅仅执行一个作业,就需要系统管理员计算好各个作业的运行时间,当估计前一个作业即将完成时,再去提交下一个作业,以防止系统空转,提高系统的利用率。由于作业切换的预期时间有可能会在深夜,这将大大增加系统管理员的工作负担。
为了解决上面提到的问题,使用作业队列jq实现作业的不间断运行。当用户提交一个作业时,该作业一般会先被加入到jq的队尾。若当前系统没有正在运行的作业,则调度节点会取出jq队列头的作业运行。使用jq使得系统一次仅运行一个作业,且保证了每个作业间可以实现自动切换,避免了系统管理员手工提交作业的工作。为了实现高优先级作业的优先运行,系统支持用户将作业插入到jq队列的队头,或者直接将正在运行的作业切换到指定作业。
6 多种平台的支持能力
6.1 针对不同计算节点类型的配置
对于不同的平台,系统中计算节点的计算卡数会各有不同(如“天河一号”系统中,每个计算节点包含一块C2050卡;Mole 8.5系统中,每个计算节点有六块C2050卡)。当系统每次收到计算节点的加速命令或减速命令时,调度节点按照设定的步进值speed_step调整系统对计算节点的计算速度的评估值。在Mole 8.5系统中speed_step设置为6;“天河一号”系统中speed_step设置为1。当接收到计算节点发送一个加速命令时,Mole 8.5系统将按六倍于“天河一号”系统的步进值对计算节点的计算速度进行调整,这使得系统可以更加迅速地响应计算节点的速度变化。
6.2 计算节点和规模的自动适应能力
在一个集群中,各个计算节点间的硬件配置可能不一样,其性能也有所差别,即使是在相同配置的计算节点上,其性能也不完全一样。例如,当出现计算节点上的某些设备突然失效时,该计算节点的计算性能可能会有所下降。系统通过考察64个周期(即640 s)计算节点完成的基准任务数来评估该节点的当前计算能力。在得到各个节点的计算能力后,系统会为每个计算节点分派适当的任务。
当计算节点的队列将满时,会向调度节点发送一个减速命令。当调度节点接收到此命令后,会适当地把对此计算节点的计算能力估计值调低,以降低对该节点的任务发送速度。同理,在计算节点的任务减少到一定程度时,计算节点又会向调度节点发送加速命令,以提高计算节点的计算能力估计值,从而加快节点任务的发送速度。
当新的计算节点刚加入时,通过发送加速命令可以快速地提高调度节点对该节点计算能力的评估值,从而快速达到预期的计算能力。当系统中有计算节点失效或计算节点性能下降时,调度节点会降低对计算节点速度的评估值,从而降低或完全取消对该节点的任务分配。
6.3 系统可扩展能力分析
由于整个系统中仅有一个调度节点,其处理能力和网络传输能力可能会成为系统的瓶颈。系统采用了粒度可配置的作业分解器和基于UDP协议网络传输方法等两种解决方法,以提升调度节点的处理能力。
调度节点中最占用计算资源的是Dispatcher线程,设其每完成一个包的分解、分派和相应的队列操作的时间为Tdispatch(注意:此时间与任务的目标粒度Starget无关),则每秒钟能产生的任务数为1/Tdispatch。
单个计算节点的吞吐率可以描述为(K*C)/Starget个任务/s,其中,K为计算节点中的并行任务处理数,C为单个任务的单位处理速度。P个计算节点的总吞吐率为(K*C)/Starget×P。调度节点的吞吐率需要大于所有计算节点吞吐率之和,即(K*C)/Starget×P<1/Tdispatch,由此可以得到系统最大可以支持的计算节点数P为:
(1)
其中,Ttarget=Starget/C为一个目标大小任务完成所需要的时间。
根据我们的实际测试,对于字符空间的分解而言,Tdispatch大约为6 ms左右。目前系统设定适当的任务粒度Starget,使得Ttarget为8 s。“天河一号”超级计算机系统中每个计算节点包含一块C2050计算卡(K=1),Mole 8.5系统中每个节点则包含六块C2050计算卡(K=6),则本系统在“天河一号”和Mole 8.5系统上所能支持的最大计算节点数分别为1 328个和221个。
由式(1)可以看出,可以通过增加目标分解粒度的方法来增加系统的计算节点数。当然,如果增加目标分解粒度,系统的任务重发时间Tre_compute(一般为Ttarget的10倍)将随之增大,使得系统发现失效节点的能力下降。对于“天河二号”而言,每个计算节点有三块MIC加速卡(K=3),如果峰值性能要求达到10 PFlops,需要支持3 333个节点,由式(1)可以计算得出Ttarget应为60.2 s,Tre_compute为600 s,依然处于可以接受的范围之内。通过Ttarget可以计算出合理的任务粒度Starget,使其与并行计算的规模相适应。
由于在调度节点和计算节点之间采用UDP协议传输任务内容和计算结果,其传输包数量仅仅为任务数量的两倍,且有效地避免了调度节点用于TCP协议的处理开销以及额外的网络传输开销。每个任务描述和结果包大小一般不超过1 500 B,实际测试表明,调度节点的网络负载仅为系统的5%以下。
从上述分析可以看出,虽然系统中仅仅只有一个调度节点,但是借助于调整作业分解器粒度和基于UDP协议的传输依然可以有效地扩展系统的计算能力,达到10 PFlops的计算能力。
7 结束语
图3所示为某次较小规模测试的计算节点运行情况。开始时系统共有102个计算节点,但由于计算节点故障和网络失效等原因,有一小部分计算节点先后与系统失去联系。在4月22日9时左右,由于网络恢复,大部分节点都重新与系统取得联系,并较平稳地运行直至计算任务完成。
为了测试本系统的可靠性、容错能力。我们先后在广州超级计算中心先导系统和Mole 8.5上分别进行了大规模测试。在广州超级计算中心先导系统上,使用300个节点(峰值计算能力达到150 TFlops),连续运行177 h,总计算能力达到53 100卡*h。在过程所的Mole 8.5系统上,使用100个节点(峰值计算能力达到300 TFlops),连续运行169 h,总计算能力达到101 400卡*h。
该并行计算框架已经在某专业计算软件中得到使用,并且实现了较好的容错性、可移植性和可扩展性。但是,随着“天河二号”等新一代超级计算机的出现,用户对系统又提出了更高的可扩展性要求,并且在软件的友好性、方便性等方面提出了进一步的要求。
致谢 本文得到广州市科技计划项目(2012Y2-00032,2013Y2-00055,201200000034)的资助,并得到广州超级计算中心先导系统、中国科学院过程工程研究所、国家超级计算天津中心的大力支持。欧彦麟、陈海欧等同学对本文亦有贡献。
[1] Hwang K. Distributed and cloud computing:From parallel Processing to the Internet of Things[M]San Francisco:Morgan Kaufmann, 2011.
[2] MPI standard[EB/OL].[2013-07-15].http://www.mcs.anl.gov/research/projects/mpi/.
[3] MVAPICH and MVAPICH2 project[EB/OL].[2013-07-15].http://mvapich.cse.ohio-state.edu/overview/mvapich2/.
[4] White T. Hadoop:The definitive guide[M]. California:O’Reilly Media Inc, 2008.
LIN Yan-yu,born in 1989,MS,his research interest includes high performance computing.

陈虎(1974-),男,江苏南京人,博士,副教授,研究方向为高性能计算。E-mail:chenhu@scut.edu.cn
CHEN Hu,born in 1974,PhD,associate professor,his research interest includes high performance computing.

苗军(1989-),男,安徽阜阳人,硕士,研究方向为高性能计算。E-mail:527361274@qq.com
MIAO Jun,born in 1989,MS,his research interest includes high performance computing.

韩佳龙媚(1991-),女,陕西西安人,硕士,研究方向为高性能计算。E-mail:664291895@qq.com
HAN Jia-long-mei,born in 1991,MS,her research interest includes high performance computing.

赖路双(1988-),男,广东梅州人,硕士,研究方向为高性能计算。E-mail:563662346@qq.com
LAI Lu-shuang,born in 1988,MS,his research interest includes high performance computing.
Methods to enhance reliability and serviceability of parallel computing software on large scale clusters
LIN Yan-yu,CHEN Hu,MIAO Jun,HAN Jia-long-mei,LAI Lu-shuang
(School of Software,South China University of Technology,Guangzhou 510006,China)
Parallel computing software on large-scale clusters requires not only fault tolerance against local nodes or network failure,but also manageability,maintainability,portability and scalability. Based on the star model,we design a parallel computing framework and achieve system-wide fault tolerance, usability,portability and scalability,using methods such as the variable granularity decomposer and associated queue on the scheduling nodes.Our system can continuously run over 150 hours with 300 TFlops computational capability.Besides,the system is scalable.
availability;scalability;serviceability;large scale cluster;parallel computing software
1007-130X(2015)01-0001-06
2013-09-24;
2013-12-18
TP393
A
10.3969/j.issn.1007-130X.2015.01.001

林彦宇(1989-),男,广东陆丰人,硕士,研究方向为高性能计算。E-mail:446260133@qq.com
通信地址:510006 广东省广州市华南理工大学软件学院
Address:School of Software, South China University of Technology, Guangzhou 510006,Guangdong,P.R.China
