YHFT-XX芯片中长线延时优化策略*
2015-03-27刘祥远丁艳平
詹 武,刘祥远,郭 阳,丁艳平
(国防科学技术大学计算机学院,湖南 长沙 410073)
YHFT-XX芯片中长线延时优化策略*
詹 武,刘祥远,郭 阳,丁艳平
(国防科学技术大学计算机学院,湖南 长沙 410073)
结合YHFT-XX芯片中存在很多长路径的特点,对物理设计中长线的优化进行了研究,主要研究了三种中继器的插入对延时的影响,得出了不同长线下插入中继器的最优尺寸以及最优延时。结合具体的工程实践,运用得出的结论优化了长路径的延时。通过规整的中继器插入,将长线上中继器单元以及中继器单元间的间距进行优化,使得路径延时更小,通过跨模块的中继器插入优化,采用穿通技术,有效减小了延时,提升了芯片的时序性能。
中继器;长线;优化;延时
1 引言
随着微电子行业的发展,芯片集成度在不断提高,门延时伴随着缩小的工艺尺寸在逐渐降低,互连线延时在总延时中所占的比例大幅增加,进入纳米级工艺之后,互连线的延时已经取代了门延时成为芯片延时的主要部分,其比例大约占至总延时的60%~70%[1]。并且,随着硅技术的继续发展,互连线对集成电路的影响将会更加显著[2]。互连线的本征延时主要受线长、单位电阻和单位电容的影响,在芯片物理设计中主要通过优化线长来减小长线延时。在超大规模、高频率芯片设计中,互连长线严重制约着时序收敛,成为物理设计的难题。
国内外许多研究者投身于延时模型的研究,通过不同的互连模型来减小互连线的延时。文献[3]研究了通过改变线宽和线间距的方法优化互连延时的互连模型。EDA算法方面,文献[4]研究了在设计中存在阻挡模块时,查找更好的中继器插入位置的算法。
当前EDA工具自身的优化能力在很多情况下已经难以满足一些大规模设计的要求[5],单周期内,数据路径上的长距离走线成为时序收敛的瓶颈,寻找好的方式优化长线延时变得尤为重要。中继器插入技术是最常用的能有效减小长线延时的方法,其优化效果根据插入的尺寸和位置不同而不同。所以,在不同的物理设计情境中,中继器单元尺寸、位置以及插入方式的选择对时序有着重大的影响。本文以工程实践为依托,对YHFT-XX芯片中遇到的长线延时问题进行了研究,有效减少了走线延时。第1节为引言;第2节介绍了三种中继器插入的延时对比,通过实验得出了三种中继器插入的最优尺寸与最优延时;第3节利用得出的结论,在工程实践中进行了运用,结合具体情况优化延时,取得了显著的效果;第4节对本文进行了简单的小结。
2 互连长线的优化方法
长互连线用中继器插入的方法可以得到很好的延时优化效果,根据中继器插入的计算公式可以求出最优的中继器尺寸。但是,通过计算得到的中继器的尺寸会很大,高达最小尺寸的400~700倍[6],面积开销过大,所以在长线优化的过程中如何选择驱动倍数适宜的中继器显得尤为重要。物理设计中存在多种类型的中继器,并且每种中继器类型包含不同驱动能力的单元。本节基于40 nm工艺,通过实验研究不同类型、不同驱动能力的中继器,从而达到对线延时的优化目标。
2.1 反相器插入的延时优化
设计中采用的反相器为INV,小倍数的中继器驱动能力弱,甚至超过分割线段所得到的延时收益,所以在物理设计中优化延时时不使用小倍数的中继器单元,因此我们只对四倍及以上的单元做延时评估。建立实验环境如下:在典型环境条件(工作电压为0.9 V、温度为25℃下),对长度为2 000 μm、1 500 μm(由于设计中存在较多1 500 μm以上的长线,故选用这两种长度作为实验对象)的互连线分别用INVD4、INVD6、INVD8、INVD12、INVD16、INVD18、INVD20、INVD24、INVD32做中继器插入,得到延时结果如图1和图2所示。
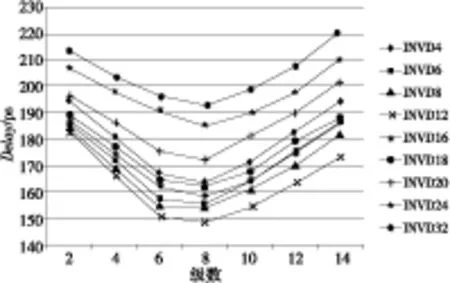
Figure 1 Delay of INV optimize 2 000 microns long term
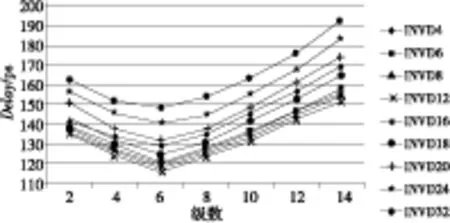
Figure 2 Delay of INV optimize 1 500 microns long term
由图1和图2可以看到:
(1) 整体曲线都呈现先减小后增大的趋势。理论上,插入中继器的延时与级数成对勾函数关系,不论对于哪一个尺寸,当延时值达到最小后,在相应最优级数的左侧,延时值随着级数的增加递减,在相应最优级数的右侧,延时值随着级数的增加递增。对于电路来说,当线长很长、插入的级数很少时,插入中继器所截得的线长依然很长,路径延时还是较大;当插入的中继器数目达到最优效果之后,随着插入的中继器数目继续增加,电路中的单元总延时也会增大,使得优化长线所得到的好处减小,路径的总延时相比于最优值增大。
(2) INVD6、INVD8、INVD12、INVD16的路径延时曲线相对靠近,而INVD24、INVD32的延时值在整体上都比其它单元大得多。当尺寸增大到一定程度后再增加尺寸大小反而会使延时增加,因此在电路的延时优化中不宜使用太大尺寸的INV单元。
(3) 在INV单元中,INVD12能获得最好的延时优化效果,且获得好的延时效果时所截得的线段长在250 μm~300 μm之间。
2.2 缓冲器插入的延时优化
数据路径上常用的缓冲器有BUFF和BUFFX,对长度为2 000 μm、1 500 μm的长线使用这两种不同类型的缓冲器做多级插入,进行延时优化比较。实验在典型环境条件(工作电压为0.9 V、温度为25℃)下进行,得到相应的路径延时结果如图3~图6所示。

Figure 3 Delay of BUFF optimize 2 000 microns long term
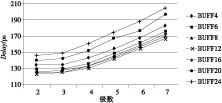
Figure 4 Delay of BUFF optimize 1 500 microns long term
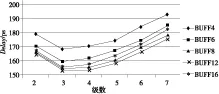
Figure 5 Delay of BUFFX optimize 2 000 microns long term
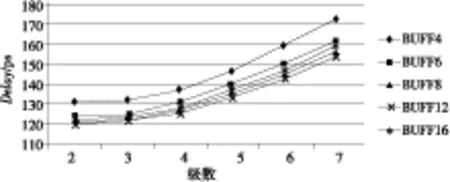
Figure 6 Delay of BUFFX optimize 1 500 microns long term
通过分析可以得出:
(1)在相同的驱动能力下,使用BUFFX单元做中继器的优化效果比BUFF单元的优化效果好。
(2)在BUFF单元中,BUFFD12的延时优化效果最好;在BUFFX单元中,BUFFXD12的延时优化效果最好。
(3)获得好的延时优化效果时它们所截得的线段长为600 μm~750 μm。
2.3 反相器和缓冲器延时优化效果的比较
从前面两小节可知,在反相器中使用INVD12做中继器能获得较好的延时优化效果,在缓冲器中使用BUFFXD12做中继器获得了较好的延时优化效果。INVD12和BUFFX12优化不同线长获得的最小路径延时如图7所示,可以看出INVD12的延时优化效果较好。

Figure 7 Optimized delay comparison between INV12 and BUFFX12
3 YHFT-XX芯片中互连长线的优化
3.1 规整的中继器插入优化
如图8所示的路径,在寄存器Q_reg_79与硬宏模块Mem_Bank1的D_Writ[453]端口之间存在长线互连,在工具自动对其优化时,其路径上的中继器单元尺寸和位置都比较杂乱,如图8a所示。路径延时如表1所示,通过11级中继器单元来优化延时。为对这条路径进行更好的优化,以满足时序要求,对其进行了合理的规划,如图8b。由于单元密度不大,通过中继器单元替换和位置的优化,在尽量直的路径上,以较优的延时优化间隔插入,根据前一节中继器插入的实验结果,将路径上的中继器单元用INVD12替换,并且保证不产生逻辑反相。优化后的路径延时如表2所示。

Figure 8 Messy repeater insertion and regular repeater insertion
表1中杂乱的中继器插入的总路径延时为0.806 ns。表2规整的中继器插入以10级INVD12单元替换了规整前的11级中继器单元,路径总延时为0.725 ns。与规整前的路径相比,延时减小了0.081 ns。
3.2 跨模块的中继器插入优化
在YHFT-XX芯片中,由于IP核的大量使用,
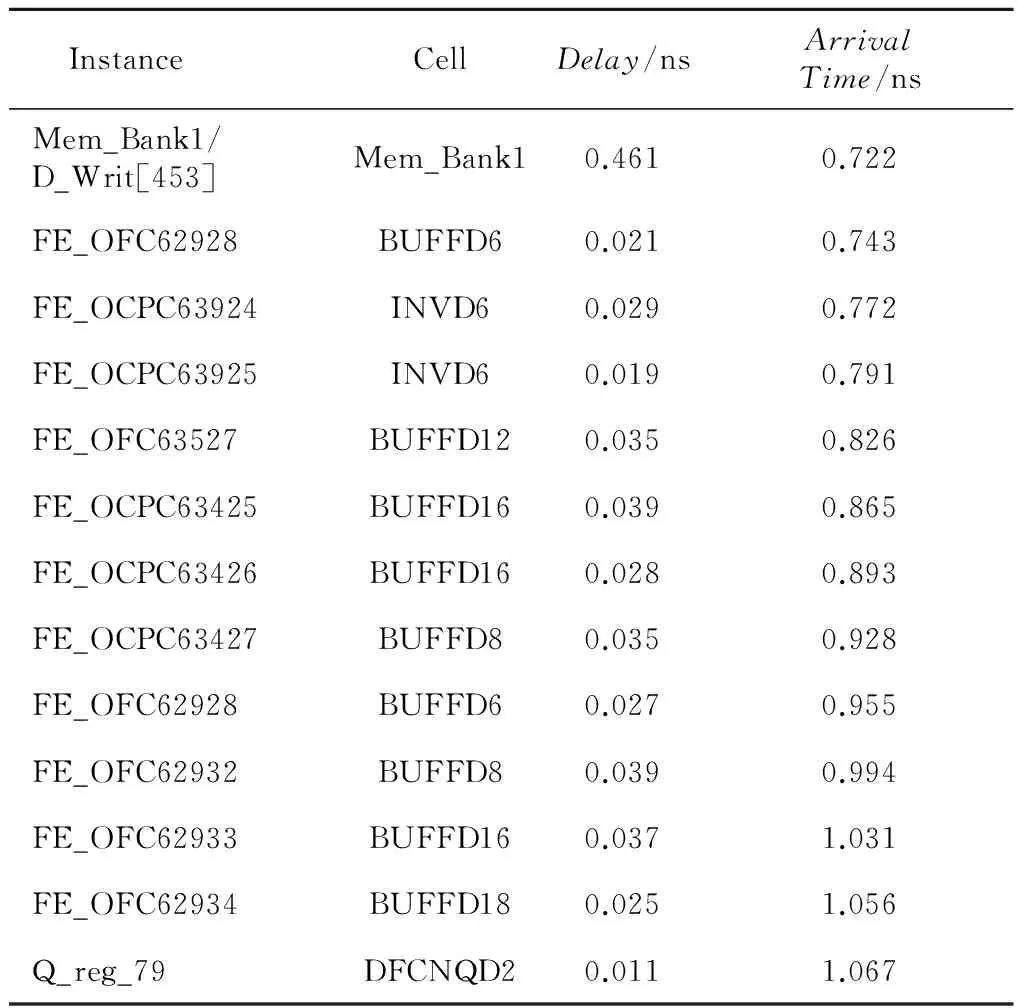
Table 1 Path delay of messy repeater insertion

Table 2 Path delay of regular repeater insertion
以及层次化物理设计的实施,后端物理设计中存在不少跨模块的长互连线,EDA工具自身无法很好地优化这些长线,造成了时序的违反。
如图9a所示,一组信号从模块MM1传输到模块MM3,中间跨过模块MM2,这组信号成为顶层的关键路径。从MM1到MM3的路径,由于MM2的阻挡无法很好地通过中继器插入来优化。如图9所示,若通过绕线路径连接,则会使得路径长度增加2a。通过直线路径连接,在模块间的预留通道内即使使用驱动能力强的BUFFXD12来驱动跨模块的线段,依然不能获得好的时序效果,在这种情况下,采用穿通(feedthrough)技术,将MM1与MM3间的中继器链插入到MM2的内部,使得MM1到MM3间的路径长度最小化,可以更好地优化路径延时。
图9b为顶层使用穿通技术时的连接视图,路径从MM1内输出穿过MM2整个模块进入到MM3,完成整条路径的数据传输。图9c为使用穿通技术在模块MM2内的连接视图,路径在MM2内按直线路径传输。

Figure 9 View of using feedthrough technology on cross-module long-tem
表3为MM1到MM3间的一条路径,分别按直线路径使用穿通技术的中继器插入和按绕线路径通过顶层的中继器插入的路径延时。绕线的情况下,路径中插入了20级反相器;使用穿通技术后,总路径变短,插入的反相器为10级。绕线时反相器链延时为0.526 ns,数据到达时间为1.264 ns,路径总延时为0.851 ns;使用穿通技术后反相器链延时为0.275 ns,数据到达时间为1.014 ns,路径总延时为0.601 ns。与绕线时的路径相比,使用穿通技术后路径上反相器数目减少了10级;反相器链的延时减小了0.251 ns,总的路径延时减小了0.250 ns,反相器链的延时降低了47.7%,路径总延时降低了29.4%。穿通技术的使用有效地优化了长线数据通路的延时,在YHFT-XX芯片跨模块路径的优化中起到了显著的作用。
4 结束语
本文对40 nm工艺不同尺寸、不同线长下的中继器插入的延时优化进行实验,得出了不同类型中继器中延时优化效果较好的单元,并将实验结果结合YHFT-XX芯片的工程进行了灵活运用。在实际示例中,通过规整的中继器插入优化了长线上插入的中继器单元以及单元间的间距,降低了路径上的延时;在跨模块的长线路径优化中,采用feedthrough技术,压缩了路径的长度,有效减少了路径的总延时,加快了芯片在时序上的收敛。
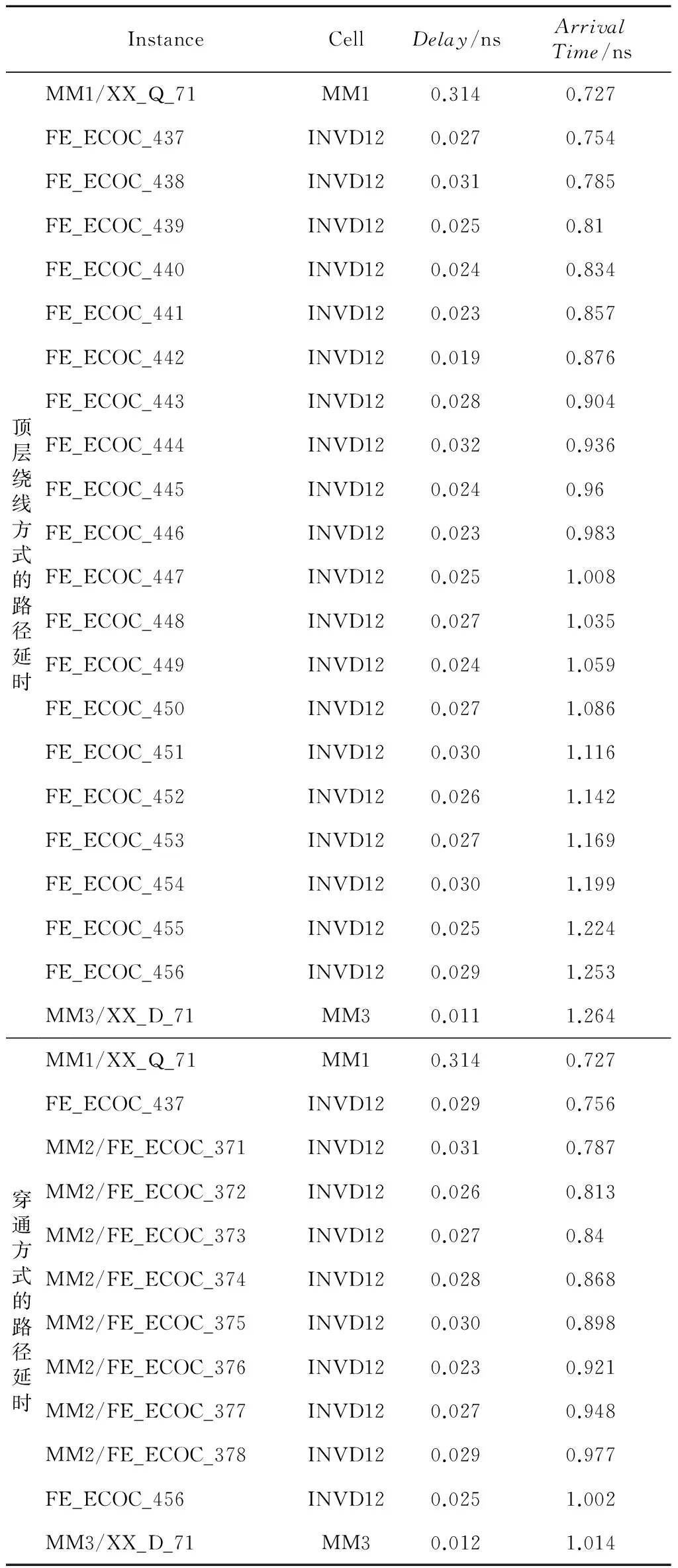
Table 3 Path delay of using feedthrough in long-term optimization
[1] Yamada K, Oda N. Statistical corner conditions and interconnect delay (corner LPE specifications)[C]∥Proc of the 2006 Asia and South Pacific Design Automation Conference, 2006: 706-711.
[2] Xia Ting-ting. The research and customize of interconnect RC corner [D].Changsha: National University of Defense Technology, 2013. (in Chinese)
[3] Hasani F, Masoumi N. Interconnect sizing and spacing with consideration of buffer insertion for simultaneous crosstalk-delay optimization[C]∥Proc of the 3rd International Conference on Design and Technology of Integrated Systems in Nanoscale Era, 2008:1-6.
[4] Alpert C J, Hrkic M, Quay S T. A fast algorithm for identifying good buffer insertion candidate locations[C]∥Proc of the 2004 International Symposium on Physical Design (ISPD-2004),2004:1.
[5] Liu Zhan-tao. Research and application of incremental interconnect delay optimization method[D].Changsha: National University of Defense Technology, 2012. (in Chinese)
[6] Wong B P, Mittal A, Cao Y, et al. Nano- CMOS circuit and physical design [M]. Xin Wei-ping,Liu Wei-feng,Dai Xian-ying Translation. Beijing:Machinery Industry Press,2011. (in Chinese)
附中文参考文献:
[2] 夏婷婷.互连线RC端角的研究与定制[D].长沙:国防科学技术大学,2013.
[5] 刘战涛.增量式互连线延时优化方法的研究与应用[D].长沙:国防科学技术大学,2012.
[6] Wong B P, Mittal A, Cao Y, et al. 纳米CMOS电路和物理设计[M].辛维平,刘伟峰,戴显英,等译.北京:机械工业出版社,2011.
ZHAN Wu,born in 1989,MS candidate,his research interest includes IC physical design.

刘祥远(1977-),男,江西会昌人,博士,副研究员,研究方向为高性能集成电路电路、设计及自动化。E-mail:liuxy@nudt.edu.cn
LIU Xiang-yuan,born in 1977,PhD,associate research fellow,his research interests include high-performance integrated circuits, and circuit design automation.
Delay optimization for long wire in YHFT-XX chip
ZHAN Wu,LIU Xiang-yuan,GUO Yang,DING Yan-ping
(College of Computer,National University of Defense Technology,Changsha 410073,China)
Aiming at that there are many long paths in YHFT-XX chip, the optimization of long wires in physical design is studied.The effect of three kinds of repeater insertion is studied,and the optimal sizes of repeaters and delays of different long wires after repeater insertion are obtained.Combined with the concrete engineering practice,the obtained results are used to optimize the delay of long paths. Regular repeater insertion is used to optimize the repeaters and the gaps between repeaters for the sake of reducing the path delay.Feedthrough technique is used to optimize the repeater insertion across modules,thus effectively reducing the delay and improving the timing performance of the chip.
repeater;long interconnect;optimization;delay
1007-130X(2015)01-0023-05
2014-08-10;
2014-10-11
TN47
A
10.3969/j.issn.1007-130X.2015.01.004

詹武(1989-),男,湖北黄冈人,硕士生,研究方向为集成电路物理设计。E-mail:zwinchina@163.com
通信地址:410073 湖南省长沙市国防科学技术大学计算机学院学员6队
Address:College of Computer,National University of Defense Technology,Changsha 410073,Hunan,P.R.China
