面向大数据应用的众核处理器缓存结构设计*
2015-03-27徐远超孙凤芸闫俊峰
万 虎,徐远超,2,孙凤芸,闫俊峰
(1.首都师范大学信息工程学院,北京 100048;
2.中国科学院计算技术研究所计算机体系结构国家重点实验室,北京 100190)
面向大数据应用的众核处理器缓存结构设计*
万 虎1,徐远超1,2,孙凤芸1,闫俊峰1
(1.首都师范大学信息工程学院,北京 100048;
2.中国科学院计算技术研究所计算机体系结构国家重点实验室,北京 100190)
大规模数据排序、搜索引擎、流媒体等大数据应用在面向延迟的多核/众核处理器上运行时资源利用率低下,一级缓存命中率高,二级/三级缓存命中率低,LLC容量的增加对IPC的提升并不明显。针对缓存资源利用率低的问题,分析了大数据应用的访存行为特点,提出了针对大数据应用的两种众核处理器缓存结构设计方案,两种结构均只有一级缓存,Share结构为完全共享缓存,Partition结构为部分共享缓存。评估结果表明,两种方案在访存延迟增加不多的前提下能大幅节省芯片面积,其中缓存容量较低时,Partition结构优于Share结构,缓存容量较高时,Share结构要逐渐优于Partition结构。由于众核处理器中分配到每个处理器核的容量有限,因此Partition结构有一定的优势。
众核处理器;大数据应用;缓存设计;访存行为;数据中心
2.State Key Laboratory of Computer Architecture,Institute of Computing Technology,Chinese Academy of Sciences, Beijing 100190,China)
1 引言
处理器是计算机系统的最重要部件之一,对系统的性能和能耗有着重要影响。然而,研究人员发现,在面向社交网络、搜索引擎、网络流媒体等一些大数据应用时[1],传统的多核/众核处理器能效比较低下[2],如处理器核逻辑过于复杂、共享缓存和访存带宽利用率不高等,这是因为传统的多核/众核处理器以提高性能、降低延迟为目标,而目前数据中心的主流应用呈现出小粒度、高并发特征,期望的是更高的吞吐率,而对延迟不是太敏感。因此,传统的多核/众核处理器设计与当前的大数据应用的需求不匹配,导致片内资源利用率低,不仅无法提高应用的性能和吞吐率,也浪费芯片面积和功耗。
本文对数据中心部分应用的访存行为进行了分析,这些应用涵盖了搜索引擎、社会网络、网络流媒体等应用领域,结果发现,这些应用在现有多级缓存结构的处理器上运行时,L1缓存的命中率较高,而L2缓存、L3缓存的命中率相对较低,这意味着缓存容量大小数倍于L1缓存的L2缓存和L3缓存只是将整个缓存的命中率提高了几个百分点,平均访存延迟并没有明显下降。研究人员还发现[3],L3缓存增加到6 MB以上时,IPC不再显著提高。
众核处理器在片内集成了多个简单处理器核,具备强大的线程级并行处理能力,可以同时响应成千上万的高并发用户请求,非常适合大数据应用的高并发请求,是数据中心处理器的理想选择。然而,众核处理器的核数多,如果按照传统的缓存结构设计,缓存资源浪费严重。本文针对缓存利用率低的问题,结合大数据应用的特点设计了两种缓存结构,两种结构均建议将L2缓存和L3缓存去除,其中一种为完全共享(Share)缓存结构,另一种是私有缓存和共享缓存共存的划分(Partition)缓存结构。结果表明,在缓存容量较低时,划分缓存结构的命中率高于共享缓存结构,随着缓存容量的增加,共享缓存结构的命中率要高于划分缓存结构。
2 相关研究
缓存是利用局部性原理来缓解处理器和内存之间的速度差异。然而,要利用好缓存需要自顶向下多层次的合理设计,避免抖动,降低干扰。比如,一个访存密集但重用率低的流式应用程序不断将数据带入缓存,替换出其他程序可能重用的数据,后者重用数据时产生的大量访存又和前者竞争带宽资源,从而形成恶性循环,导致两个程序的性能都急剧下降,这就是抖动问题。再如,从数据局部性角度看,不同程序有不同的数据访问模式,共享缓存对同时运行的多道程序的访存不加以区分,就产生了程序间的缓存干扰。
提高缓存利用率的方法很多,比如缓存感知的应用程序设计[4],通过合理布局内存中的数据,提高数据的空间局部性;通过编译器或操作系统分析程序的行为,预测所需要的缓存大小[5];通过剖析(Profiling)[6]每个线程对缓存的空间需求实现缓存的静态划分;通过操作系统预测程序执行过程中的缓存需求实现缓存的动态划分[7]。
以上研究都是在传统多级缓存存储层次结构上为减少线程之间的相互干扰、减少缓存空间的竞争而采取的策略,这些策略也适用于大数据应用环境,但仍然无法从根本上摒除大数据应用环境下使用多级缓存结构存在的资源利用率不高的问题,也就是说,仅从软件层面解决是不够的,必须从结构上进行改进。
众核处理器主要有NVIDIA的Fermi、Intel的Phi处理器、Larrabee、Godson-T、Tilera的TILE,这些处理器均为二级或三级缓存结构,主要用于加速和高性能计算。只有L1缓存、基于ARM的简单处理器核适宜线程级并行,已在数据中心得到了广泛应用,但不属于众核处理器结构,也没有评估私有数据和共享数据的划分问题。Tullsen D M[8]认为在软件线程数少于硬件线程数时L1缓存采取共享方式效果最佳。但是,在高并发的大数据应用环境下,每个硬件线程基本上都处于饱和状态,随着软件线程数的增加,共享缓存的线程间数据干扰加重,吞吐率就会出现波动。
3 大数据应用访存行为分析
3.1 大数据应用的特点
詹剑锋等[9]把数据中心应用分为三大类,分别为数据密集型服务、数据处理应用、交互式实时应用。比如,文本搜索引擎就是服务类应用,流媒体、VoIP等属于实时交互式应用。数据处理应用特指基于MapReduce或Dryad编程模型的松耦合应用,不包括紧耦合数据处理应用。大数据应用有几个明显特征。一是负载特征,服务请求之间、作业任务之间相对独立,没有很强的依赖关系,易于水平扩展(Scale Out)。虽然GPU、MIC等众核处理器的线程级并行度也很高,但线程之间的耦合度很高,都服务于一个特定的任务,单个线程的运行时间影响整体性能,而大数据应用追求高吞吐率,不以提高单个线程的性能为目标。二是体系结构特征,浮点操作少、整型操作比例高,数据通道能力主导,即Load/Store指令所占比例高。
海量数据工作集、高并发、数据离散、访存随机是这些应用的典型特点。比如,微博、推特等社交网站,用户众多且相互交织,组成复杂的图关系。线程内部访问的数据多为非结构化数据,比较离散,随机性强,空间局部性差,数据重用率低。再如,大规模数据排序执行步骤明确,流式特征明显,数据的时间局部性差,导致数据的重用距离超过共享缓存的相联度,造成数据在片内多级缓存之间冗余流动。在类似搜索引擎这样的大数据应用中,并发请求的用户数量大,线程相似度高,但请求的数据几乎完全独立,而单个用户访问的数据局部性相对有限。
传统的以计算为中心的缓存结构延长了数据通路,难以应对大数据应用的访存行为特点。
3.2 缓存容量敏感性分析
处理器进入多核/众核时代后,访存依然是系统性能的瓶颈。为了减少延迟,大部分处理器设计为二级或三级缓存层次结构,L1为私有缓存,最后一级缓存(LLC)为共享缓存,LLC容量通常较大。为了缓解不同缓存(如L1缓存与L2缓存、L2缓存与LLC缓存)之间的延迟差距,有些还装备了缓冲(Buffer)或预取(Prefetch)部件。
我们首先分析了大数据应用对LLC容量的敏感程度,通过将访存trace输入到缓存模拟器中,调整LLC的容量,得到的结果如图1所示,说明这些应用对LLC容量并不敏感,当容量超过4 MB以上时,对命中率的提高几乎没有贡献。
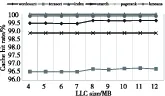
Figure 1 Cache hit rate sensitivity to LLC capacity for some big data applications
文献[3]将数据中心的大数据应用与访存密集型的桌面应用(如SPECInt mcf)进行了比较,实验结果显示数据中心的大数据应用对LLC大小的敏感度在 4 MB~6 MB,随着LLC容量的增大,IPC并没有显著变化。
传统缓存结构设计以减小延迟为目标,层次多、容量大,这种结构适用于数据的时间和空间局部性都非常好的应用。对于大数据应用而言,处理
的对象多为半结构或非结构化数据,数据离散、访存随机、数据集大。在一个时间区间内,工作集大小往往达百MB以上,而缓存容量通常只有几MB大小,整个程序工作集无法全部放到缓存中,需要反复替换,数据重用率低,不仅发挥不出缓存的作用,还增加了功耗。
3.3 缓存命中率分析
我们测试了部分大数据应用的缓存命中率,在数据集均为2 GB、线程数为8(kmeans和pagerank无法设定线程数)时,实验结果如图2所示。
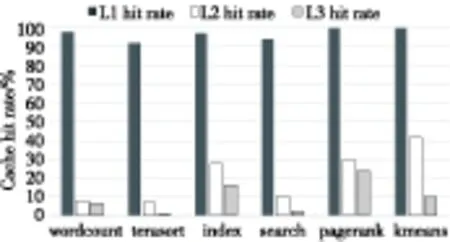
Figure 2 Three levels cache hit rates of some big data applications
随着线程数量的变化,各级Cache缺失率会略有不同,但并没有改变L1缓存命中率高、L2/LLC缓存命中率低的现象,以wordcount和terasort为例,表1显示的是线程数增加时的缓存命中率。
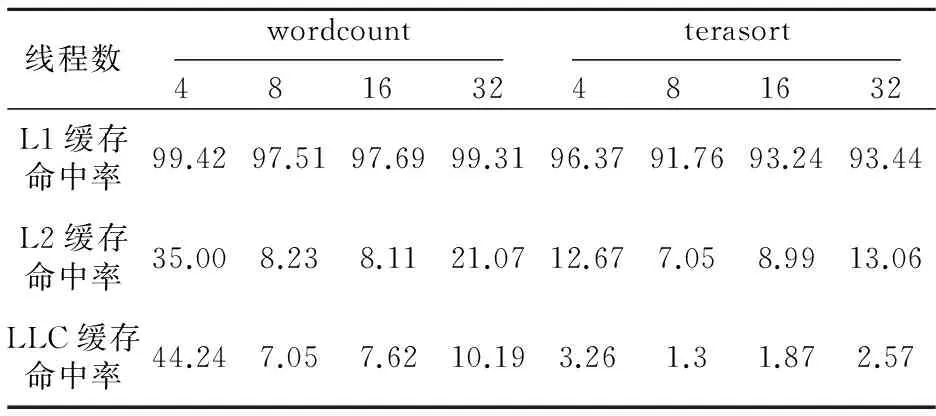
Table 1 Cache hit rate over the number of threads
大数据应用处理的数据集巨大,为此,我们评估了数据集大小对缓存命中率的影响,结果如图3所示。
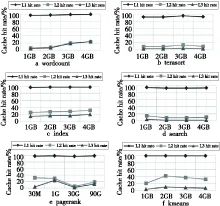
Figure 3 Data sets size’s impact on cache hit rate
以上实验结果说明,导致L1缓存命中率高、L2/LLC缓存命中率相对较低的根源不是线程之间的相互干扰,也不是处理的数据集大小,而是程序的访存行为本身。
在一个时间区间内,如果一个线程的工作集可以完全放在L1缓存中且存在一定的空间或时间局部性,则显示出L1缓存的命中率高而LLC的命中率低。如果在一个时间区间内一个线程的工作集远大于LLC且时间和空间局部性差,则所有层级的缓存命中率将很低,因为一个线程的数据在重用时已经被其它线程替换出去了,需要重新访存。通过实验结果可以预测,虽然整个程序的工作集很大,但一段时间内每个线程的工作集较小,可以完全放在L1缓存中,因此L1缓存命中率高,当这些数据集处理完毕后,重新访问新的数据,原来的数据即使缓存在L2或LLC中,也几乎不再访问,因此多级缓存结构的作用并没有发挥出来。
为了比较大数据应用缓存命中率与其他应用的不同,我们从PARSEC[10]测试集中随意选择了几个程序,测量结果如图4所示。可以看出,从PARSEC中选择的六个测试程序中有四个表现出每级缓存命中率都很高的现象,说明大部分这类应用所处理的数据局部性好,线程之间数据的耦合度高。
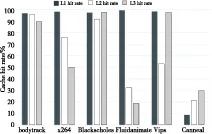
Figure 4 Three levels cache hit rates of several PARSEC benchmark applications
4 众核处理器缓存结构设计
4.1 基于SMT的缓存结构设计
众核集成了成百上千个处理器核,每个处理器核分配的资源极其有限。本文依托的众核处理器已确定为采用同时多线程(SMT)流水线设计,每个硬件线程运行一个软件线程,取指模块每拍切换一个线程,线程发生缓存失效时让出流水线上的所有共享资源,进入等待状态,不再参与调度,直到获取到需要的访存内容。SMT采取的是硬件支持的快速线程切换机制,可以有效隐藏延迟,与操作系统级线程切换相比,几乎可以做到“零时间开销”。这种设计可以让众核处理器在单位时间内产生更多的访存请求,从而充分利用内存控制器的访存带宽。
首先,我们根据测量的缓存命中率实验数据和实验平台Intel Xeon E5645的延迟参数(表2),计算线程数为8时,相对三级缓存结构而言,只有一级缓存结构的平均访存延迟如表3所示。
其中“命中时平均延迟”是指CPU发出请求后到从该级缓存中获取数据的延迟,L1缓存“缺失时平均延迟”通过式(1)计算得到,L2缓存“缺失时平均延迟”通过式(2)计算得到。
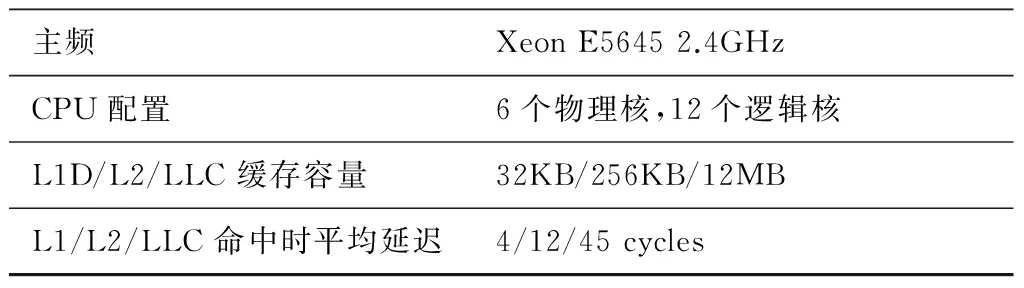
Table 2 Hardware experimental platform
L1_miss_latency=L2_Hit_Rate*12+
(1-L2_Hit_Rate)*L2_miss_latency
(1)
L2_miss_Latency=L3_Hit_Rate*
45+(1-L3_Hit_Rate)*200
(2)
忽略传输延迟,CPU发出请求后到从L1缓存取得数据是四个cycles,主要是查找。查找L2缓存的延迟是八个cycles,查找L3缓存的延迟是33个cycles,向内存控制器发出访存请求到取回数据的时间延迟是155个cycles,LLC缺失时的平均延迟由各级缓存查找延迟和访存延迟构成,共200cycles。
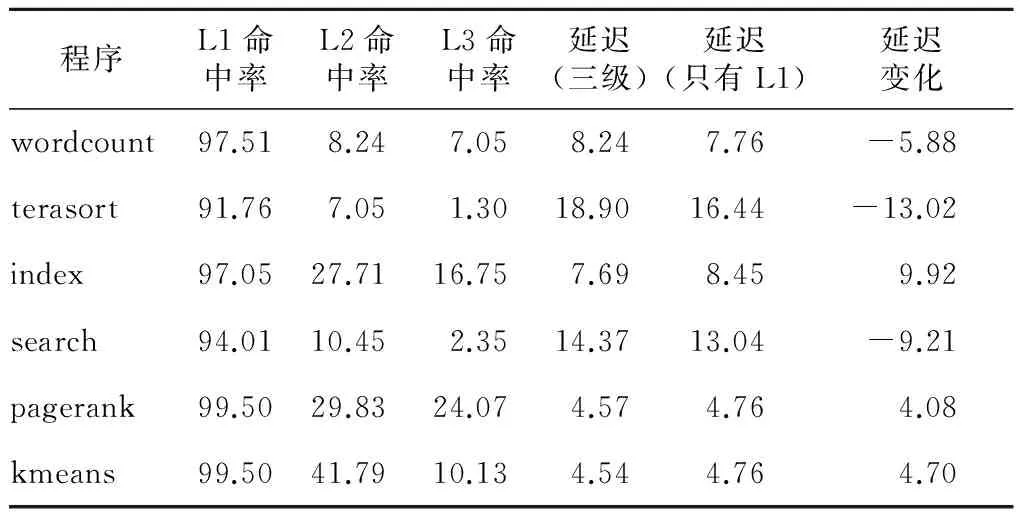
Table 3 Cache hierarchy impact on memory access latency
从表3看出,L2/LLC缓存去掉以后,wordcount、terasort、index、search、pagerank、kmeans的访存延迟分别下降5.88%、下降13.02%、增加9.92%、下降9.21%、增加4.08%、增加4.70%。可见,平均访存延迟并没有明显增加,部分程序甚至还略有下降,原因在于减少了很多无效的缓存查找,缩短了访存路径。大容量的LLC去掉以后,节省的芯片面积可用于部署更多的处理器核以提高线程级并行度。延迟往往影响单个线程的性能,但大数据应用追求的是整体吞吐率的提升,不仅如此,缓存层次的减少避免了很多无效的缓存查找开销,缩短了访存路径。
经过以上分析,我们设计了两种缓存结构,两种结构均设计为只有一级缓存。结构1为完全共享缓存结构(图5a),以下简称为Share。结构2为私有缓存和共享缓存共存的划分缓存结构(图5b),以下简称为Partition。Partition结构的设计依据是,大数据应用处理的数据共享度低,为避免各线程之间的数据互相干扰,为各线程分配独立的缓存以存放私有数据,将线程间少量的共享数据存放到共享缓存中。
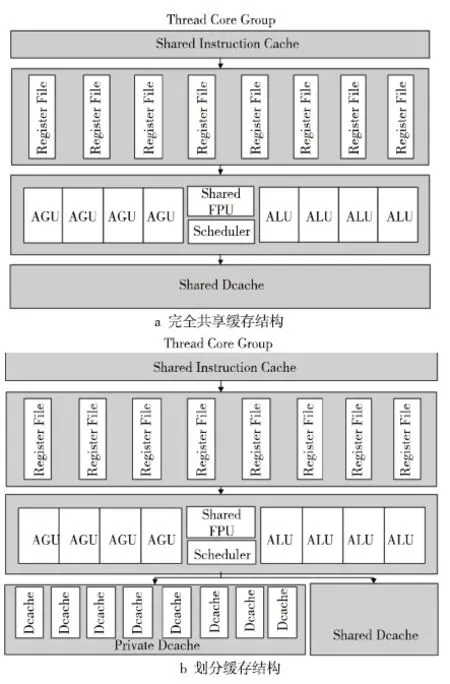
Figure 5 SMT-based processor core structure
4.2 读写策略与缓存一致性
Share结构缓存同一个处理器核的所有数据,读写策略、替换算法与传统结构相同。Partition结构将同一级缓存划分为私有和共享两部分,在缓存查找时需要区分数据类型,是线程私有数据还是线程间共享数据。为此,我们在地址前面加了一个标志位(shared_flag),根据shared_flag判断地址指向的区域是私有数据区域还是共享数据区域,如图6所示,当shared_flag=1时表示私有数据区域,此时访问对应的硬件线程的私有缓存,当shared_flag=0时表示共享数据区域,此时,无论线程运行在哪个硬件线程上,都访问共享缓存。本文定义的缓存不同于传统意义上的一级私有缓存和LLC共享缓存,本文定义的私有缓存和共享缓存位于同一级,因此,在查找上没有先后,而是同时进行的。CPU究竟使用物理地址还是虚拟地址查找缓存与缓存的具体实现相关,无论采取什么地址,用于区分私有数据和共享数据的标志位都存在于TLB中,访问缓存时,需要先查询TLB。当CPU访问私有缓存时,如果是读不命中,则直接访问片外主存,将取出的数据回填到私有缓存中;如果是写命中,可以设计为写回(Write Back)或写穿透(Write Through)策略;如果写不命中,可以设计为写分配(Write Allocate)或非写分配(Not-Write allocate)策略。由于只有一级缓存,无论采取什么算法,相对于多级缓存结构都要简单很多。当访问共享缓存不命中时,采取与私有缓存同样的方法处理。
众核的缓存一致性是一个经典问题,由于处理器核众多,缓存分布较广,一致性维护的开销很大。对于Partition结构而言,省掉了维护私有缓存一致性的开销,只需要维护共享缓存一致性。我们设计的众核处理器划分了多个分区,每一个分区对应一个内存控制器,只需要维护单个分区的缓存一致性,不需要维护整个众核处理器的缓存一致性,从而将维护缓存一致性的空间开销和时间开销降低了一个数量级,更细节的内容超出了本文的范围。
4.3 共享数据的识别
识别一个数据是私有数据还是共享数据,是Partition结构的关键。陈渝等人[11]通过在缓存行(Cache Line)中引入处理器核标识符来判别是否为共享数据,即,当一个处理器核访问某一个缓存行时,在缓存行中记录该处理器核的标识,如果之后被另一个处理器核访问,说明此数据被两个处理器核同时访问,即认为是共享数据。这种通过学习来识别共享数据的方法适用于运行时间较长的大规模程序,不适用于本文所针对的高并发、运行时间相对较短的轻量级线程和本文设计的Partition缓存结构。

Figure 7 Using ignored bits in page table entry to differentiate shared or private data
本文采用编译制导语句对多线程程序中的共享数据和私有数据进行手工标识,结合操作系统分页机制,最终将线程私有数据存放在每一个线程独占的页框中,将属于线程间共享数据存放在线程共享的页框中。操作系统分配内存空间是以页为单位的,页框的基地址写在页表项中,为了对页框指向的是私有数据区域还是共享数据区域,在页表项的保留位(如图7所示的第9~14位)中定义一个标志位,如果是私有数据区域,标志位置1,如果是共享数据区域,标志位置0。为了减小维护缓存一致性的开销,众核运行时系统(Runtime System)将同一个应用的多个线程尽量聚合到同一个处理器核上,避免过于分散。这种编译制导的方法在Godson-T众核处理器中已得到运用。
5 实验与分析
5.1 实验平台
缓存缺失率由Intel开发的Vtune工具采集相关事件后计算得到的,这些事件都是与体系结构相关的。为了对缓存结构进行评估,开发了一个基于trace驱动的缓存模拟器,访存trace作为输入,命中率作为输出。为了抓取访存trace,基于Pin[12]工具编写了一个支持多线程的PinTool,可以得到每个线程的访存行为。
由于缓存设计空间巨大,根据现有处理器的典型配置,选取了几组参数,首先是缓存行大小,评估了64 B和32 B两种大小,实验结果显示,在同等容量下,64 B行大小要优于32 B行大小。容量一定时,行的数量与行大小成反比,行数越少,冲突失效的可能性越大,因此行大小也不能太大。
为了确定私有缓存和共享缓存的比例,我们对选取的几个大数据应用的线程间共享访存情况进行了统计,分别截取了几个GB大小的trace,得到的数据如表4所示,每个程序共享访存比例不尽相同,但普遍不高,没有超过20%,为此,我们将私有缓存和共享缓存的大小比例粗略定义为4∶1。
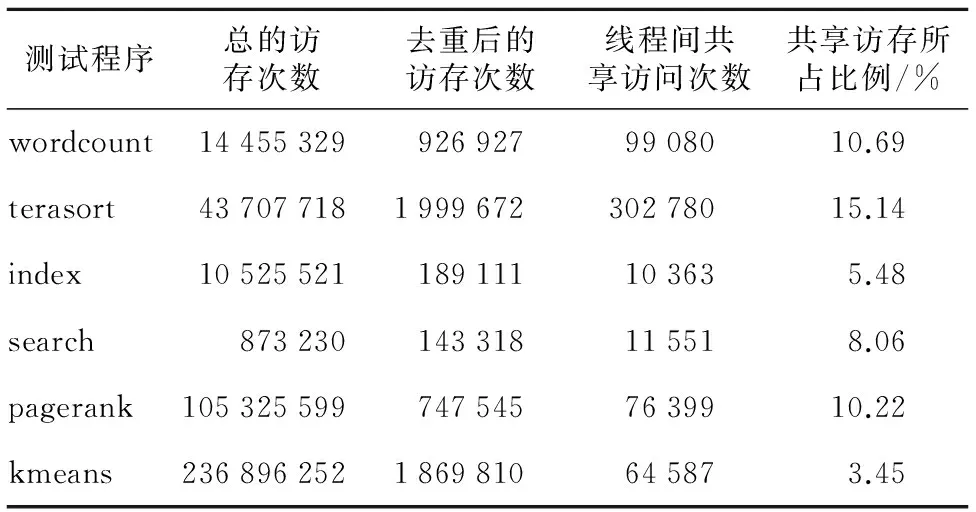
Table 4 Percentage of inter-thread shared memory address access
5.2 实验结果
将二级、三级缓存去掉以后,带来的直接变化是缓存所占芯片面积大幅减小,以本文硬件实验平台Intel Xeon E5645为例,如果只保留L1缓存,则芯片面积减少为原来的1/73,即32 KB*6/(32 KB*6+256 KB*6+12 MB),而访存延迟并没有显著增加(见表3)。
通过自主开发的缓存模拟器,我们评估了硬件线程数为8的SMT众核处理器核五种缓存容量大小下的缓存命中率,分别为8 KB、16 KB、32 KB、64 KB和128 KB。
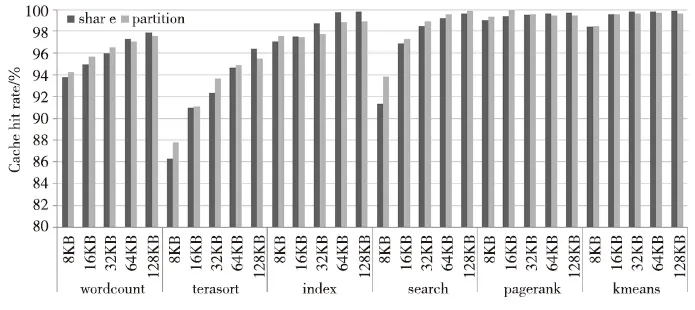
Figure 8 Comparison of cache hit rate under five cache capacities between Share and Partition
从图8可以看到,当缓存容量为8 KB时,Partition结构的缓存命中率普遍好于Share结构,由于一级缓存命中率大多都在90%以上,继续提高的幅度有限。当缓存容量逐渐增大时,Partition结构的优势不再明显,甚至要差于Share结构。原因在于,缓存容量增大后,冲突失效减少,线程间发生数据替换的概率降低,而Partition结构中的私有缓存空间无法得到充分利用,因为它是线程私有的。
通过实验发现,在缓存空间较小时,Partition结构下的缓存命中率比Share结构都有不同程度的提高。这对于众核处理器设计来讲非常重要,因为片内集成了上千个处理器核,而缓存在芯片面积中的比重较大,每一个处理器核不可能分配太大的缓存空间。
5.3 分析讨论
大数据应用种类繁多,本文只选择了其中几个有代表性的应用,包含了CloudSuite[3]中所叙述的主要程序类型和文献[6]中所定义的全部三类应用。虽然无法确定是否所有的大数据应用都具有这样的访存行为,但基本可以肯定有不小比例的应用具有这样的访存行为,很多数据中心(如Google)往往提供相对单一的服务,如搜索引擎,在能效的驱动下,处理器设计正在从通用转向专用。
另外,本文提出的两种缓存结构只是一种建议方案,并非唯一方案。虽然延迟略有增加,但节省的晶体管可以部署更多的处理器核,1 MB的LLC相当于四个cortex-A8处理器核所占面积[2],这对于高并发、高吞吐的大数据应用尤为重要。
6 结束语
当前数据中心采用的多核/众核处理器在处理大数据应用时缓存资源利用率不高。通过剖析部分大数据应用的访存行为,发现L1缓存命中率高、L2缓存和LLC命中率低,这是与大数据应用线程间数据共享度低、数据离散、访存随机的特点相关的。本文提出了两种缓存结构设计方案,一种是共享缓存的Share结构,一种是私有缓存和共享缓存分离的Partition结构。实验结果表明,在只有一级缓存的情况下,延迟并没有显著增加,芯片面积大幅减小,当缓存容量较低时,Partition结构要优于Share结构。随着缓存容量的增加Partition结构的优势不再明显,采用Share结构会更好,对于众核处理器来讲,由于核数众多,分配到每个处理器核的缓存容量不会太大,因此,Partition结构在缓存容量较小时有一定优势。
[1] Wang Yuan-zhuo,Jin Xiao-long,Cheng Xue-qi.Network big data:Present and future [J]. Chinese Journal of Computers, 2013, 36(6):1-15.(in Chinese)
[2] Lotfi-Kamran P, Grot B, Ferdman M, et al. Scale-out processors[C]∥Proc of the 39th Annual International Symposium on Computer Architecture, 2012:500-511.
[3] Ferdman M,Adileh A,Kocberber O,et al.Clearing the clouds:A study of emerging scale-out workloads on modern hardware [C]∥Proc of the 17th International Conference on ASPLOS, 2012:37-48.
[4] Chilimbi T M,Hill M D,Larus J R. Cache-conscious structure layout[J].ACM SIGPLAN Notices, 1999, 34(5):1-12.
[5] Ding X,Wang K, Zhang X. ULCC:A user-level facility for optimizing shared cache performance on multicores [C]∥Proc of the 16th ACM Symposium on PPoPP, 2011:103-112.
[6] Jia Y, Wu C, Zhang Z. Programs performance profiling optimization for guiding static cache partitioning[J]. Journal of Computer Research and Development, 2012,49(1):93-102.(in Chinese)
[7] Kim S, Chandra D, Solihin Y. Fair cache sharing and partitioning in a chip multiprocessor architecture [C]∥Proc of the 13th International Conference on PACT, 2004:111-122.
[8] Tullsen D M, Eggers S J, Levy H M. Simultaneous multithreading:Maximizing on-chip parallelism [C]∥Proc of the 22nd Annual International Symposium on Computer Architecture,1995:533-544.
[9] Zhan J,Zhang L,Sun N,et al.High volume throughput computing:Identifying and characterizing throughput oriented workloads in data centers[C]∥Proc of the IEEE 26th International Parallel and Distributed Processing Symposium Workshops & PhD Forum, 2012:1712-1721.
[10] Bienia C, Kumar S. The PARSEC benchmark suite:Characterization and architectural implications[C]∥Proc of the 17th ACM International Conference on Parallel Architectures and Compilation Techniques, 2008:1-22.
[11] Chen Y, Li W, Kim C, et al. Efficient shared Cache management through sharing-aware replacement and streaming-aware insertion policy [C]∥Proc of IEEE International Parallel & Distributed Processing Symposium, 2009:1-11.
[12] Luk C K, Cohn R, Muth R, et al, Pin:Building customized program analysis tools with dynamic instrumentation [C]∥Proc of the 2005 ACM SIGPLAN Conference on PLDI,2005:190-200.
附中文参考文献:
[1] 王元卓,靳小龙,程学旗. 网络大数据:现状与展望 [J].计算机学报, 2013,36(6):1-15.
[6] 贾耀仓,武成岗,张兆庆. 指导Cache静态划分的程序性能profiling优化技术[J]. 计算机研究与发展,2012,49(1):93-102.
WAN Hu,born in 1991,MS candidate,CCF member(E200041112G),his research interest includes computer architecture for big data.

徐远超(1975-),男,湖北武汉人,博士,讲师,CCF会员(E200007824M),研究方向为面向大数据的计算机体系结构。E-mail:xuyuanchao@ict.ac.cn
XU Yuan-chao,born in 1975,PhD,lecturer,CCF member(E200007824M),his research interest includes computer architecture for big data.

孙凤芸(1989-),女,河南新乡人,硕士生,CCF会员(E200041151G),研究方向为面向大数据的计算机体系结构。E-mail:kycg2012@126.com
SUN Feng-yun,born in 1989,MS candidate,CCF member(E200041151G),her research interest includes computer architecture for big data.

闫俊峰(1991-),女,山东潍坊人,硕士生,研究方向为面向大数据的计算机体系结构。E-mail:1256834897@qq.com
YAN Jun-feng,born in 1991,MS candidate,her research interest includes computer architecture for big data.
Cache structure design for big data oriented many-core processor
WAN Hu1,XU Yuan-chao1,2,SUN Feng-yun1,YAN Jun-feng1
(1.College of Information Engineering,Capital Normal University,Beijing 100048;
Some big data applications such as data sorting, search engine, streaming media running on the traditional latency-oriented multi/many-core processor are inefficiency. The hit rate of L1 Cache is high while that of L2/L3 Cache is relative low and IPC is not sensitive to LLC capacity. To address the low utilization issue of cache resources, we analyze the memory access patterns of big data applications, and then propose an optimization method of cache structure for many-core processor. Both the two structures only have L1 cache, while one is fully shared cache structure, and the other is partly shared cache partition structure. The evaluation results show that these two schemes can significantly save chip area at the cost of slightly increase of memory access. When cache capacity is low, the partition structure is superior to the share structure. As cache capacity increases, the share structure will gradually become superior to the partition structure. For many-core processors, the capacity assigned to each processor is limited, thus the partition structure has certain advantages.
many-core processor;big data application;cache design;memory access behavior;data center
1007-130X(2015)01-0028-08
2014-05-17;
2014-10-20基金项目:北京市自然科学基金资助项目(4143060);北京市教委科技发展面上资助项目(KM201210028004);计算机体系结构国家重点实验室开放课题(CARCH201203);“高可靠嵌入式系统技术”北京市工程研究中心;北京市属高等学校人才强教项目-国外访学(135300100)
TP316
A
10.3969/j.issn.1007-130X.2015.01.005

万虎(1991-),男,安徽宿州人,硕士生,CCF会员(E200041112G),研究方向为面向大数据的计算机体系结构。E-mail:wanhu@cnu.edu.cn
通信地址:100048 北京市海淀区西三环北路56号首都师范大学信息工程学院
Address:College of Information & Engineering,Capital Normal University,56 Xisanhuan North Rd,Haidian District,Beijing 100048,P.R.China
