基于改进K-medoids算法的科技文献特征选择方法
2015-03-22李俊州
李俊州, 武 莹
(1.开封大学 艺术设计学院, 河南 开封 475004; 2.开封大学 软件职业技术学院, 河南 开封475004)
基于改进K-medoids算法的科技文献特征选择方法
李俊州1*, 武 莹2
(1.开封大学 艺术设计学院, 河南 开封 475004; 2.开封大学 软件职业技术学院, 河南 开封475004)
根据科技文献的结构特点搭建了一个四层挖掘模式,并结合K-medoids算法提出了一个特征选择方法.该选择方法首先依据科技文献的结构将其分为4个层次,然后通过K-medoids算法聚类对前3层逐层实现特征词提取,紧接着再使用Aprori算法找出第4层的最大频繁项集,并作为第4层的特征词集合.同时,由于K-medoids算法的精度受初始中心点影响较大,为了改善该算法在特征选择中的效果,论文又对K-medoids算法的初始中心点选择进行优化.实验结果表明,结合优化K-medoids的四层挖掘模式在科技文献分类方面有较高的准确率.
文本分类; 特征选择;K-medoids算法
随着文献检索能力的提高,越来越多的用户习惯于从中国知网和数字图书馆进行快速检索,获取所需的文献资料.但是在知识更新不断加快的今天,新主题、新事物、新学科大量涌现,信息种类和数量激增.使得科技文献的数量每年近似指数的速度增长,如此海量的科技文献,往往需要消耗读者大量的时间,如何对其进行高效组织,满足广大读者的需求,已经成为该领域的一个研究热点.
文本特征向量的高维性是文本分类的瓶颈,特征选择是文本特征向量降维的一种方式,它是实现文本高效分类前提,是文本自动分类的一个重要环节,特征选择算法的性能将直接影响分类系统的最终效果.目前用于文本特征选择的方法主要由以下几种:互信息方法(Mutual Information)[1],信息增益方法(Information Gain)[2],x2统计量方法[3],期望交叉熵方法(Expected Cross Entropy)[3],文档频次方法(Document Frequency)[4].
科技文献主要以文本的形式存在,由标题、摘要,关键字,正文等组成,其中最能代表文章主题的是标题和关键字,其次是摘要部分,再次是正文的引言和总结部分,最后是正文的其他部分.为了更加精准的提取特征词,本文组建四层挖掘模式,逐层对科技文献进行特征选择.本文首先对K-medoids算法进行改进,然后结合改进后的K-medoids算法和Apriori算法提出一种新的文本特征选择方法,来对科技文献进行分类处理.
1 相关基础知识
1.1 K-medoids算法
K-medoids算法是聚类分析常用的一种方法,其基本思想[5]是:随机选择K个初始聚类中心点,其余数据点根据其与中心点的距离将其分配给最近的代表的簇,反复从聚类的非代表样本中选取数据点来代替原质点,如果某数据点成为质点后,绝对误差能小于原质点所造成的绝对误差,那么该数据点可取代原质点,绝对误差最小的数据样本将成为簇中心点.算法描述:
输入:K为初始中心点个数,D为包含N个对象的数据集合.
输出:K个结果簇.
Step1:从D中选出K个初始中心点;
Step2:将其余对象依据距离分配到与其最近的中心点;
Step3:随机选择一个非中心点Oi;
Step4:计算用Oi代替原中心点Oj所造成的绝对误差;
Step5:计算Oi造成的绝对误差与原中心点Oj造成的绝对误差的差值,当新中心点的造成的绝对误差小于原中心点时,Oi替换Oj,形成新的K个代表对象集合;
Step6:转向step3,直至算法收敛;
Step7:结束,得到K个结果簇.
1.2 Apriori算法
Apriori算法是一种逐层迭代挖掘关联规则的频繁项集算法,其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来寻找数据项之间的关联关系[6].Apriori算法使用如下性质来找到K维最大频繁项集:
性质1XK是K维频繁项集,若所有K-1维频繁项集集合XK-1中包含XK的K-1维子项集的个数小于K,那么XK不可能为K维最大频繁项集.
K的值每增加1就需要扫描一次数据库,为了提高频繁项集的搜索效率,Apriori算法使用下述性质用于压缩搜索空间:
性质2若K维数据项集XK中有一K-1维子集不是频繁项集,那么X不是频繁项集.
算法描述:
Step1:扫描数据库,产生频繁的1-项集;
Step2:由频繁1-项集经过两两结合生成频繁的2-项集;
Step3:通过频繁K-1-项集产生K-项集候选集;
如果在两个频繁的K-1-项集只有最后一个元素不同,其他都相同,那么这两个K-1-项集项集可以“连接”为一个K-项集.如果不能连接,将其舍弃;
Step4:从候选集中剔除非频繁项集;
如果候选集中某个K-项集的子项集不在频繁的K-1-项集中,将其删除;
Step5:计算候选项集的支持度,将其与最小支持度比较,得到K维频繁项集.直至生成最大项集,否则转向Step3;
Step6:结束,获取最大频繁项集.
2 改进的K-medoids算法
K-medoids算法首先要任选K个数值点初始聚类的簇中心,在此基础进行迭代计算.如果初始中心不同,相应的聚类结果就会有差异.在理论上,随机选取初始点最理想情况是选取了K个簇的中心点,此种情况下的聚类效果为最佳,但是也有可能将一簇中的K个元素选为初始点,此时的聚类效果较差,为此,需对初始值的选取应该制定一个标准,使其尽可能地接近各个簇的中心.
设在训练集中特征项ti的权重向量为:wi=(wi1,wi2,…,win),任意两个权重向量差值的模的最大值为:
vi=max|wis-wit|
(s,t=1,2,…,n;s≠t;i=1,2,…,m),
(1)
其中,m为特征个数,n为文本数.
一般情况下,类属性特征词在其所属类别文本中出现的频率高而在其它类别文本中出现的概率较小,而非类属性特征词则不然,因此类属性特征词的vi值大于非类属性特征词的vi值,即vi值较大的特征项对文本类属性的标引能力更强.
改进的K-medoids算法对数据集合进行聚类分析的步骤描述如下:
输入:数据对象集A,聚类种子初始中心点个数K.
输出:K个结果簇,使每个聚类中心点不再发生改变.
Step2:设定划分区间的单位长度p,将区间d=[min{vi},max{vi}]划分为K个小区间,p值的计算公式[8]为:
(2)
其中,K为聚类的簇数;
Step3:判断特征项ti的vi值是否满足vi∈lr,如果满足,则将ti划分为相应的特征子集Sr,lr的计算公式为:
lr=[min{vi}+(r-1)p,min{vi}+rp]
(r=1,2,…,K);
(3)
(4)
则将特征项to作为第o簇的初始值;
Step5:将其余对象依据距离分配到与其最近的中心点;
Step6:随机选择一个非中心点Oi;
Step7:计算用Oi代替原中心点Oj所造成的绝对误差,公式为[9]:
(5)
其中,p为空间中的数据点,Oj为簇Cj的中心点;
Step8:计算Oi造成的绝对误差与原中心点Oj造成的绝对误差的差值,计算公式为:
e=Ei-Ej,
(6)
当e<0时,Oi替换Oj,形成新的K个代表对象集合;
Step9:转向Step6,直到所有类簇的中心点不再发生变化;
Step10:算法结束,得到K结果簇.
此种作为选择聚类初始值的条件具有以下优点:
1)初始值的选取基本上位于或接近位于各个聚类簇的几何中心,这更符合聚类要求;
2)由于本文研究的是文本特征选择,因此这种以vi值的大小为标准的簇初始值选择模式通过聚类得到的位于各个簇的“核心区域”内的那些特征项更具有文本的类别标引能力.
3 结合改进K-medoids和Apriori算法的四层挖掘模式
本文根据科技文献的结构特点提出4层挖掘模式,将K-medoids聚类分析方法应用于该模式的前3层,将Apriori方法应用于第4层,逐层实现特征选择.其基本思想:首先将挖掘过程分为如下4层,标题与关键字为第1层,摘要为第2层,文献引言与总结部分为第3层,正文的其他部分为第四层;然后将第1层的一级特征词的个数来确定K值,依据特征项对文本类属性的标引能力选出初始中心点,将样本集中的样本按照欧式距离原则分配到最邻近的簇中,反复从聚类的非代表样本中选取数据点来代替原质点,如果某数据点成为质点后,绝对误差能小于原质点所造成的绝对误差,新数据点可取代原质点,绝对误差最小的数据样本将成为簇中心点,直到算法收敛,得到K个结果簇;在每个簇中选择一个或多个代表词作为二级特征词,并根据二级特征词的数量来确定第3层K值.步骤相同,待算法收敛时得到三级特征词.正文部分属于四层挖掘模式中的第4层,由于该部分数据量大,且所含有效信息量较少,本文采用Apriori算法对其进频繁项集的挖掘.将提取出的频繁项集和三级特征词进行比较,消除重复词,最终得出特征词集.
对科技文献标题、关键字用汉语分词系统进行切分,经去停用词处理,得出一级特征词,获取K值.对文献的摘要部分用汉语分词系统进行分词处理,经过去停用词处理得到文献语料库(一).采用本文提出的改进的K-medoids算法对其进行特征选择,然后对每个簇选择一个或多个代表词作为二级特征词,获取下一次聚类的K值.同样的方法对科技文献的引言和总结部分进行处理,形成文献语料库(二).选择过程同二级特征词选择的方法类似.用相同的方法对正文部分数据处理得到文献语料库(三),由于科技文献的正文部分数据量较大,特征词的密度相对较小.适合采用挖掘布尔关联规则频繁项集的方法进行频繁项的挖掘.最后将选择出的频繁项集和三级特征词进行比较,消除重复词,最终得出特征词集.
下面以二级特征词的选择为例,对其过程进行描述:
Step1:根据一级特征词的数量确定获取二级特征词聚类的K值;
Step2:使用文本分类中常用的tf-idf因子对第i个特征项ti进行赋权.tf-idf的计算公式为:
(7)
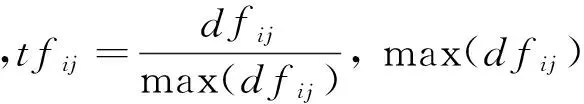
Step3:用本文提出的改进的K-medoids算法获取相应的类簇C1,C2,…,Ck;
Step4:计算类簇C1,C2,…,Ck的簇内向量的算术平均向量(类别中心向量)X1,X2,…,XK;
Step5:计算簇内各特征与类别中心向量的相似度,相似度计算公式:
(8)
其中,w1i,w2i代表两个不同的向量,n为向量内的参数个数.按从大到小的顺序分别取前f个特征值对应的特征,将这f×K个特征项构成特征集S的子集用于文本表示[11].
4 仿真实验与结果
4.1 仿真实验
在中国知网上搜集1 320篇属于计算机行业的科技文献,660篇作为实验数据的训练集,其余作为测试集.其中160篇主题为“离散化”的文献,440篇主题为“绿色网络”的文献,720篇主题为“特征选择”的文献,对660篇训练集均采用以上的方法对其进行特征选择.前三级特征词的数量如表1所示.
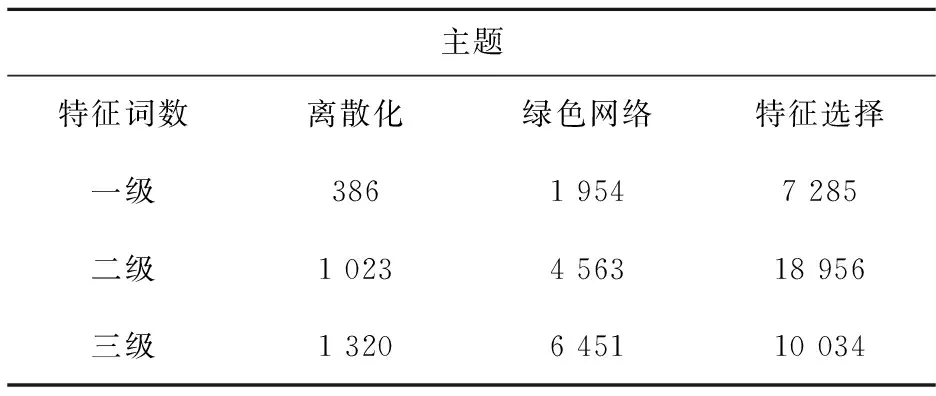
表1 前三级特征词数量Tab.1 The Number of Before Three-Level Feature Words
本文以80篇主题为“离散化”的科技文献作为Apriori算法的实验数据.设最小支持度为40%,文献语料库如表2所示.

表2 文献语料库Tab.2 Literature Corpus
80篇主题为“离散化”的文献,经过Apriori算法处理,最终得到39450维最大频繁项集52组,将52组数据全部组合得到39608个特征词.
4.2 实验结果
本实验采用空间向量模型(VSM)[15]进行文本表示,经过KNN(这里取K=30)文本分类算法的训练,形成文本分类器,以此作为实验测试的工具.
分类评估的效果使用查全率、查准率和F-score值进行刻划:
Recall=正确分类的文本数/应有文本数;
Precision=正确分类的文本数/实际分类的文本数;
F-score=(2*recall*precision)/(recall+precision).
实验中,把本文特征提取方法与文献[1]中的IACA方法作比较,其实验对比结果如表3所示.

表3 各特征提取方法实验对比结果Tab.3 Experiment Comparison Results of Feature Extraction Methods %
通过以上的比较,可以看出本文所提出方法的查全率、查准率都优于IACA方法,说明本文提出的特征选择方法在科技文献特征选择方面有着较好的挖掘性能.
5 结束语
特征选择是特征降维的一种方式,是文本信息处理的核心步骤,本文针对科技文献分类提出一种基于改进K-medoids方法,该方法与四层挖掘模式相结合,不仅解决了K-medoids聚类算法不能自动确定K值的问题,而且避免了初始聚类中心点对算法聚类的影响,使得特征选择的精度有了较为明显的提升.但该方法也受到一定因素的影响,如K-medoids算法对孤立点数据很敏感,孤立点会使聚类中心偏离从而影响聚类结果;由于Apriori算法在计算项集支持度时,需对文献语料库中的数据进行扫描,随着文献语料库记录的增加,这种扫描将使计算机系统的I/O开销呈现出几何级数增加.这些都是进一步研究应该考虑的问题.
[1] 刘海燕, 王 超, 牛军钰. 基于条件互信息的特征选择改进算法[J].计算机工程, 2012, 14(38): 36-42.
[2] 潘 果. 基于正则化互信息改进输入特征选择的分类算法[J].计算机工程与应用, 2014, 50(15): 25-29.
[3] 刘海峰, 苏 展, 刘守生. 一种基于词频信息的改进CHI文本特征选择[J].计算机工程与应用, 2013, 49(22): 110-114.
[4] Orakoglu F E, Ekinci C E. Optimization of constitutive parameters of foundation soilsK-means clustering analysis[J]. Sciences in Cold and Arid Regions, 2013, 5(5) :0626-0636.
[5] Dernoncourt D. Analysis of feature selection stability on high dimension and small sample data[J]. Computational Statistics and Data Analysis, 2014, 71(3):681-693.
[6] SinaT, Parham M, Fardin A. An unsupervised feature selection algorithm based on ant colony optimization[J].Engineering Applications of Artificial intelligence, 2014, 32(6): 112-123.
[7] Salwani A. An exponential Monte-Carlo algorithm for feature selection problems[J]. Computers and Industrial Engineering, 2014, 67(1): 160-167.
[8] Wu X. Online feature selection with streaming features[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(5): 1178-1192.
[9] Han J, Kamber M. Date Mining: Comcepts and Techniques[M]. 北京:机械工程出版社,2001.
[10] 朱颢东, 吴怀广. 基于论域划分的无监督文本特征选择方法[J].科学技术与工程, 2013, 13(7): 1836-1839.
[11] 傅德胜, 周 辰. 基于密度的改进K均值算法及实现[J]. 计算机应用, 2011, 31(2): 432-434.
[12] 刘海峰, 刘守生,张学仁. 聚类模式下一种优化的K-means文本特征选择[J]. 计算机科学, 2011, 38(1):195-197.
Feature selection method of scientific literatures based on optimizedK-medoids algorithm
LI Junzhou1, WU Ying2
(1.College of Art and Design, Kaifeng University, Kaifeng, Henan 475004;2.College of Software Technology, Kaifeng University, Kaifeng, Henan 475004)
According to the structural characteristics of the scientific literature, the paper set up a four-level mining mode, and combinedK-medoids algorithm to propose a feature selection method of scientific literatures.The proposed feature selection method firstly divided scientific literature into four layers according to its structure, and then selected features progressively for the former three layers byK-medoids algorithm, finally found out the maximum frequent itemsets of fourth layer by Aprori algorithm to act as a collection of Features fourth layer. Meanwhile, because the clustering accuracy ofK-medoids algorithm is influenced by the initial centers, in order to improve the effect of feature selection, the paper also optimizedK-medoids algorithm which it firstly used information entropy empower the clustering objects to correct the distance function, and then employed empowerment function value to select the optimal initial clustering center. Experimental results show that the four-level mining mode combined optimizedK-medoids has higher accuracy in scientific literature classification.
text classification; feature selection;K-medoids algorithm
2015-01-17.
1000-1190(2015)04-0541-05
TP392< class="emphasis_bold">文献标识码: A
A
*E-mail: lijunzhou0724@163.com.
