大数据关键技术在数字文化资源统一揭示与服务平台中的应用
2015-03-14薛尧予国家图书馆北京100081
●薛尧予(国家图书馆,北京100081)
大数据关键技术在数字文化资源统一揭示与服务平台中的应用
●薛尧予(国家图书馆,北京100081)
[关键词]大数据;分布式处理;数据挖掘;非结构化数据
[摘要]针对目前主流的大数据处理技术进行分析,研究其在数字资源揭示与服务平台中的应用方法,分析和构建了Hadoop、Memcached、Cassandra、协同过滤等技术在数字文化资源统一揭示与服务平台中的应用模式,以期为相关研究提供参考。
随着大数据时代的来临,我们所创造和产生数据的急速增长,数据量之巨大已经远超我们想象。一方面,现有的工具逐渐显露出结构的局限性;另一方面,大数据所带来的不可估量的价值引领我们重新认识这个世界。
数字图书馆作为数字信息和知识的保存及服务中心,本身就拥有大量的数据库、电子书、纸质图书转换的数字图书,以及各种音视频等数字文化资源,且随着数字图书馆建设的进一步开展,将会生产和保存更多的数据。如,2013年国家图书馆已拥有874.5TB的数字资源,资源检索与揭示系统(国图使用文津搜索系统)中目前已整合超过2亿条元数据。此外,国家图书馆各业务系统和读者服务系统中每天都产生大量的系统日志和读者行为等数据。如何对数字图书馆的大量数字资源进行整合分析,并使其得到合理、深度揭示和服务已经成为摆在我们面前的一项重要课题。
本文依托于数字文化资源统一揭示与服务平台,对大数据关键技术进行研究,构建合理的应用模式,通过分布式处理技术实现数据从原始状态到可用状态的处理与准备,并建立可靠的分布式缓存系统,提高检索效率。对检索到的资源进行详情展示,同时基于大规模数据挖掘与推荐技术的实现对资源关联及用户行为中的隐含信息加以合理利用,提高平台的使用体验。
1大数据关键技术
1.1 Hadoop分布式处理技术
Hadoop是目前应用最为广泛的分布式系统基础架构,其技术框架中主要包含了MapReduce编程模型和HDFS文件系统,二者紧密集成并构成Hadoop分布式计算的理论基石,[1]该架构主要用在基于计算机集群环境的大规模数据分布式处理。同时,Hadoop分布式处理技术在实现层面不同于传统的并行计算,对于开发人员没有很高的技术要求,只要熟悉Hadoop所定义的模型结构及实现方法,即可进行大规模数据并行处理的开发。Memcached分布式内存对象缓存技术可在动态应用中将数据库负载大幅度降低,合理分配资源,加快访问速度,[2]常与Hadoop架构配合,共同构建大规模、高吞吐量的数据处理系统。
以Hadoop为核心的分布式系统架构,具有可靠性高、效率高、扩展性好等优势。首先,在HDFS系统中对数据会保留多个副本,当数据在处理或者存储过程中出现损失或者丢失,因其他副本的存在,系统会针对丢失数据的分布情况进行重新部署,从而实现高可靠性。其次,架构中的MapReduce模型可以通过并行方式保证系统的运算速度,从而实现高效率。此外,由于这种架构对集群中单台计算机性能没有太大要求,较底端的服务器或者普通PC即可满足其计算要求,因此是分布式数据处理平台的优选架构。
1.2非结构化数据库技术
随着各种数据种类和数据量的急剧增长,数据的非结构化也逐渐成为我们面临的重大挑战,单纯使用关系型数据库已经无法满足实际业务中出现的越来越多的非结构化、半结构化数据,这就催生了MongoDB、Cassandra、Hbase等非关系型数据库技术。
MongoDB虽然是为了处理半结构化数据而产生的,但是,其查询功能几乎可以和关系型数据库相媲美,同时,数据库结构又较关系型数据库松散,可以看做一个将非关系型和关系型数据库特性结合的较为完美的数据库。Cassandra是典型的分布式非关系型数据库,具有很强的扩展性和读写性,与MongoDB一样都是目前较为流行的数据库。HBase也是Hadoop家族中的一员,是基于HDFS的分布式数据库,在高性能读写大规模数据方面具有优势。
2数字文化资源统一揭示与服务平台
数字文化资源统一揭示与服务平台是一个综合性平台,运行各类应用系统,并通过平台融合为一个整体。它是资源的汇集地、检索的门户、服务的调度站。[3]平台汇集各类文化资源元数据共1000万条,分别由6家单位提供,这些资源涉及城市文化、历史文化、戏曲、舞蹈、旅游等,包括图书、期刊、图片、视频、静态三维及活态三维等多种类型。[4]平台搜索引擎可以支持各种不同类型的文化资源元数据,按照分布式集群架构搭建系统运行环境,根据元数据的数量实现系统规模的动态伸缩,从而实现对文化资源的统一揭示和服务。不同类型的文化资源元数据可以根据语义、分类、主题等进行数据关联和调用,打通不同类型数字资源的信息孤岛,实现文化资源的深度揭示。通过平台导引系统的调度功能,对分布在不同物理区域的文化资源数字对象进行展示。依托数字文化资源统一揭示与服务平台,将建立贯通各类文化机构的多种类型文化资源的数字化应用示范,打造基于互联网、数字电视平台、移动终端的数字文化资源应用展示,实现各类文化资源的集中管理、深度揭示、统一检索和联合展示,为用户获取各类文化资源提供新的服务模式。数字文化资源统一揭示与服务平台的搭建过程中,需要完成四个关键环节:数据收集与处理、分布式检索、元数据调用及展示、用户行为信息挖掘与利用。
3大数据关键技术在平台的应用
数据处理能力、检索的效率是评价一个资源揭示与服务平台的重要指标。以往的资源揭示与服务系统,多是基于关系型数据库进行数据处理与检索,非常适用于点查询以及小部分数据的分析处理,对数据的结构有严格要求。在大数据环境下,这样的系统结构显然已经无法满足大批量数据处理与检索的需求,因此,我们考虑采用分布式处理技术搭建平台的数据处理与检索支撑部分,将多种类型、结构各异的数据存放于分布式系统中,以便进行大批量的、涵盖整个数据集的分析与处理,同时利用分布式缓存技术构建索引,提升检索效率。
平台索引项的建立通过分布式缓存系统实现,但是对于资源详情数据、书评、书封等项的展示来说,并不需要大量的计算,因此并没有纳入分布式计算体系中,而是采用非结构化数据库实现,一方面减少分布式体系的计算压力,另一方面可以使得资源展示更加丰富。
用户通过平台进行资源检索时,如果系统能够通过对用户及资源数据进行分析,利用数据挖掘方法,将隐含在用户信息、资源关联、用户访问日志等数据中的信息挖掘出来,并根据这些信息向用户推荐其最需要的资源,将在很大程度上提升用户体验。
3.1基于Hadoop的分布式数据处理
采用Hadoop结构构建分布式计算集群,完成数字资源重要性计算、索引构建、数据挖掘等大规模计算,进行数据处理,提高检索质量。Hadoop框架中分布式计算通过MapReduce过程实现(见图1)。
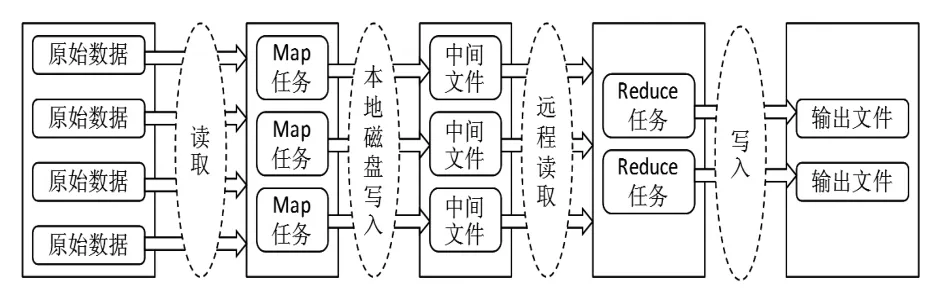
图1 MapReduce执行过程
首先,系统将原始数据集读取后进行分割,其中若有单个数据文件较大,尤其是大到影响检索效率时,也会将其分割成较小文件,每个被分割的数据文件会对应一个Map操作。程序运行时,多个副本按照Master-Worker结构启动,一个Master程序对应多个Worker程序,由Master为Worker分配Map或者Reduce操作任务。分配到任务的子程序将自动读取分割后的文件,并对该文件执行预先定义好的、与文件对应的Map操作(在Hadoop框架中有一个已经封装好的Mapper类,通过它来实现Map操作过程的定义),从而对数据进行分析处理,生成键值对并存至内存。固定时间间隔后,内存中的结果集被分割成多个子集,由系统将这些子集写入系统硬盘形成中间文件,并在Master程序中记录子集所写入的位置。接下来,分配到Reduce操作的Worker程序会按照操作指示读取(往往是远程的)对应的中间文件,并在读取后由该Worker程序对结果集执行排序操作,如果结果集太大,排序可通过另外的排序程序实现。执行Reduce操作的Worker程序会对排序后的结果进行遍历,并对来自相同键值的执行结果合并,并最终形成输出结果。当所有被分配任务(Map操作和Reduce操作)的Worker程序执行完后,Master程序会将结果返回系统主程序,进而执行其他操作。
3.2基于Memcached的分布式缓存
Memcached常被用来加速应用程序。对一个web应用来说,很多情况下返回的信息都是相同的,从数据源(数据库或文件系统)重复加载十分低效。在介绍分布式缓存系统前,有必要简要介绍一下平台的搜索集群结构。集群采用文档分布式策略,每台索引服务器的行为类似于整个文档集的一小部分数据的搜索引擎,根节点通过父节点把查询消息的拷贝发送到每台核心搜索集群中的服务器,每台搜索服务器返回检索结果及相应分数,通过父节点和根节点归并和排序,最后由根节点合并为一个相关排序表,返还给前端展示页面。

图2分布式缓存系统结构
平台的缓存服务采用的是Memcached分布式缓存集群系统,在各个层面均有构建。在父节点和根节点层面,缓存的是相关排序表;在搜索核心集群上,缓存的是倒排表。在大规模语料库中,使用密集计算来处理查询,相关排序表被计算出来后,通过缓存可提高整个系统的性能。根服务器会根据图书馆标准的类别体系对检索结果进行分类,根服务器、父节点和搜索核心节点通过统一的名字服务器管理各自的地址信息,采用ZooKeeper实现同步服务、配置维护和命名服务等分布式应用(见图2)。
3.3基于Cassandra的资源详情展示
平台的资源详情显示功能基于Cassandra结构实现,Cassandra数据结构中主要有:Column、SuperColumn、ColumnFamily、Keyspaces、Row,其中Keyspace 是ColumnFamily的容器。一个Keyspace相当于关系型数据库中的一个数据库,ColumnFamily相当于关系型数据库中的表,每个ColumnFamily包含许多Row,每个Row包含Key及其关联的一系列Column。Column 是Cassandra中最小的数据单元,是三元的数据类型,包含:name,value和timestamp。SuperColumn可以想象成Column的数组,包含一个name以及一系列相应的Column。
平台前端显示资源详细信息所用的元数据保存在Cassandra,如果前端从Cassandra读取数据失败,会尝试从Hbase中进行读取。多媒体数据和书评数据也保存在Cassandra中,如前端显示书封的图片和书评时可直接从Cassandra中获取。
平台中Cassandra设计了两个数据中心,其目的是为了让另外一个数据中心有一套完整的数据备份,当一个数据中心无法正常工作时候,第二个数据中心可以顶替,并帮助损坏的数据中心恢复数据。
3.4基于协同过滤的资源推荐
目前,许多网站都已经使用了协同过滤推荐技术,如Amazon、Google等。不同的协同过滤之间有很大的不同,笔者在选取协同过滤算法时,综合考虑了基于用户协同过滤算法[5]和基于项目协同过滤算法[6]的优缺点,形成基于用户和项目相结合的协同过滤算法。
基于用户的协同过滤算法,首先,要对用户属性进行分类,进而根据结果寻找最接近的用户,也就是寻找最近“邻居”,最终根据“邻居”属性集合对用户进行推荐。在评分过程中,评价依据来自于两方面:对用户基本信息进行评价,即显性评价;对用户浏览、检索、评论等行为信息进行评价,即隐性评价。计算近邻时,较常用的算法是相似性算法。基于项目的协同过滤算法,以预推荐的项目为基础,这些项目集合由系统预先分为若干类别,然后计算出与用户经常使用的项目相近的项目集合,向用户进行推荐。项目集合的类别往往是由上至下的倒树型结构,大类别在上,细分类别在下。在计算相似性时,同类项目之间相似度加权高于类间项目相似度加权。
利用基于用户的协同过滤算法进行资源推荐时,需要分析用户对于资源的使用情况,得到能代表用户使用偏好的属性集合,这一过程往往决定于系统对用户行为信息的收集程度,这使得推荐结果具有较大随机性。而基于项目的协同过滤,由于推荐来自于资源本身的特性,结果较为精确,较容易准确把握用户需求,但不利于发掘一些隐含于相似用户属性中信息,范围较窄。将两种算法进行结合会得到更好的推荐效果。如:一位用户为化学专业学生,当他检索“高等数学”时,通过基于项目的协同过滤,系统将会推荐《高等数学概论》《高等数学名师指点》等与高等数学相关的一些资料。如果结合基于用户的协同过滤,系统就会将另外一些化学专业学生检索过的《化工原理》《高分子化学》等资源推荐出来,推荐的结果集将更契合用户需求。
多数大数据处理技术都是在原有数据处理技术基础上结合了新的应用场景和应用方法。同时,云计算技术近几年的兴起和成熟,也为大数据处理技术的发展奠定了坚实的理论基础。研究这些技术在数字资源揭示与服务方面的应用,能够提高数字资源管理效率,使数字资源的组织模式更为有序,从而支撑数字资源更为深层、全面地揭示,使读者得到更高效的数字资源检索、展示服务。
[参考文献]
[1]The Hadoop Distributed File System:Architecture and Design[EB/OL].[2013-10-29].http://hadoop. apache.org/docs/r0.18.0/hdfs_design.pdf.
[2]Memcached website[EB/OL].[2013-10-29].http: //memcached.org/.
[3]魏大威.数字文化资源统一揭示与服务平台架构研究[J].图书馆学研究,2014(5):56-62.
[4]梁蕙玮,萨蕾.国家数字文化资源统一揭示与服务平台的资源整合研究[J].图书馆学研究,2014(2):54-58.
[5]Sarwar B, et al. Analysis of recommendation algorithms for E-commerce[C].Proceedings of the 2nd ACM Conferenceon Electronic Commerce,New York,ACM Press,2000:158-167.
[6]Sarwar B,etal.Item-basedcollaborativefilteringrecommendation algorithms[C]// Proceedings of the 10th International World Wide Web Conference.Hong Kong: ACMPress,2001:285-295.
[收稿日期]2015-02-02[责任编辑]刘丹
[作者简介]薛尧予(1982-),男,高级工程师,研究方向:数字图书馆,图书馆大数据研究。
[基金项目]本文系国家科技支撑计划项目“文化资源数字化关键技术及应用示范”(项目编号:2012BAH01F01)的研究成果。
[文章编号]1005-8214(2015)12-0096-04
[文献标志码]A
[中图分类号]G250.73
